 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库让 Claude Code 成本爆降 89%,这个开源工具有点猛...
用 Claude Code 写代码,经常遇到会话莫名其妙地变短,明明才刚开始,对话就断了。
原因其实很简单。
每次 AI Agent 在终端跑命令,输出结果会直接塞进上下文窗口。
上下文窗口,就是 AI 每次能记住的内容上限,满了就断。
跑一次 cargo test,光是测试日志就能吃掉 4000+ token。跑几次 git diff,再 grep 一下,上下文就满了。
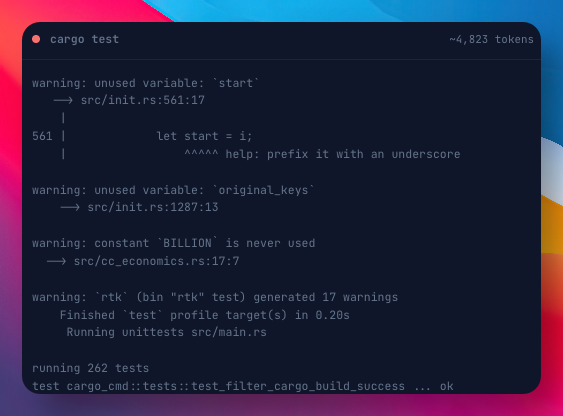
说白了,就是 AI 的「工作记忆」很容易被终端里垃圾信息撑爆。
留给真正有用的代码逻辑的空间,越来越少。
最近我发现了一个叫 RTK 的开源工具,专门来解决这个问题。

RTK 的全称为 Rust Token Killer,一个用 Rust 写的 CLI 代理层。
所做的事情很简单:在终端命令的输出结果到达 AI 之前,先帮忙过一遍,把噪音删掉,只留关键信息。
就像给 AI 装了一个「过滤器」,脏水不进去,只喝干净的。
有位开发者使用 RTK 几周后,输出一份统计报告,节省了 88.9% token。
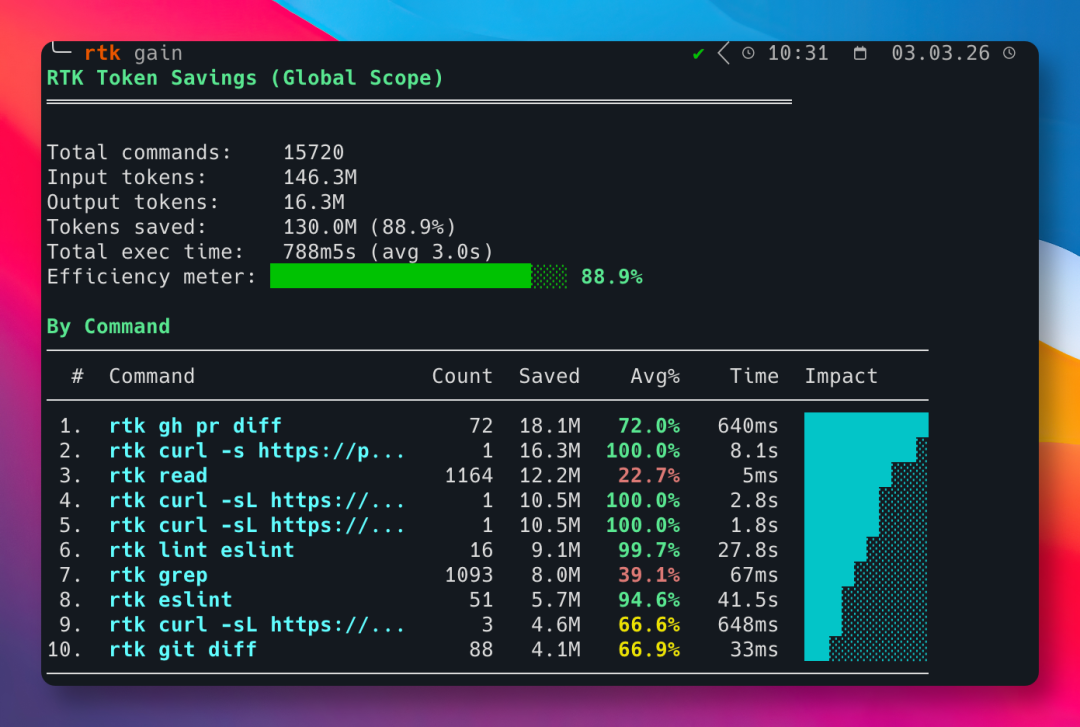
压缩效果有多夸张
官网给了一份对比数据,来自 2900+ 次真实命令的统计。
以 cargo test 为例,原始输出大概 4823 个 token,经过 RTK 处理后,只剩 11 个 token,压缩了 99%。
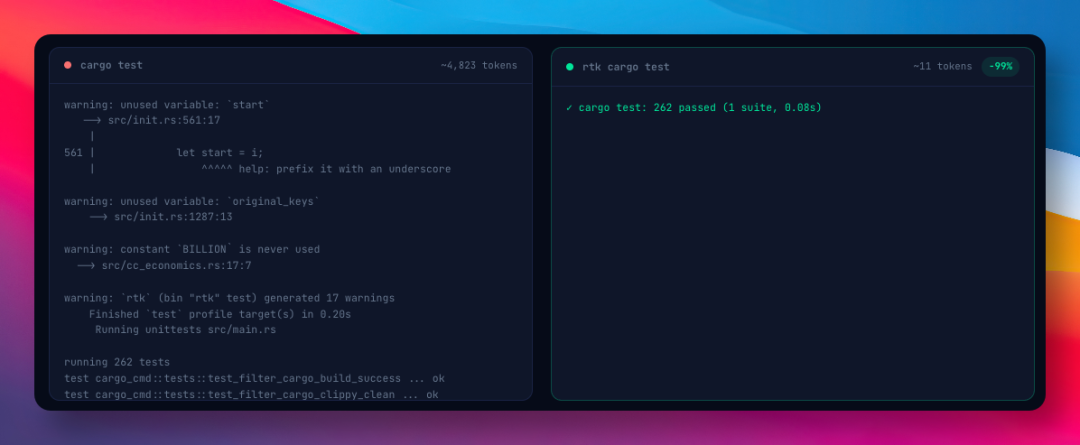
那些测试日志、警告信息、进度条,全砍掉,只告诉 AI 结论。
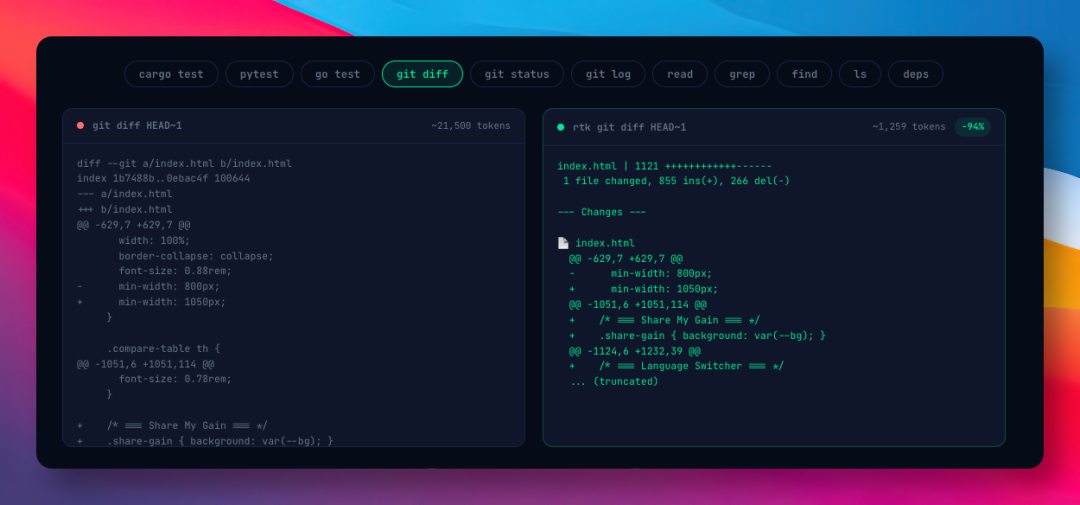
git diff 同理,2 万多 token 的原始 diff,处理后压到 1200 token 左右,缩减 94%。
git status 从 120 token 压到 30 token,grep 结果从 2000 token 压到 940 token。
它是怎么做到的
RTK 内部用了四种策略,组合使用:
智能过滤:把注释、空白行、样板代码这类对 AI 没用的内容直接删掉。
分组聚合:把类似的内容合并展示。比如 grep 搜出来的结果,会按文件分组,同一个文件的匹配行合并在一起,而不是把所有匹配行铺开一行一行展示。
智能截断:保留最有价值的上下文,删掉重复冗余的部分。
去重合并:日志里反复出现的相同行,合并成一条,附带出现次数。
这四种策略组合起来,基本覆盖了开发过程中最常见的「废话场景」。
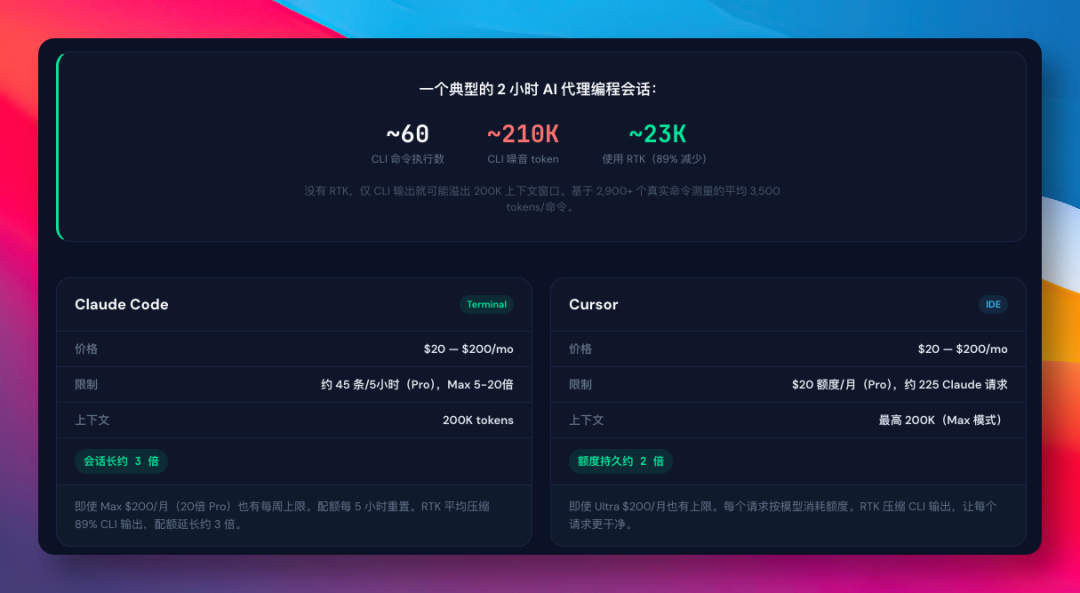
三步装好,轻松上手
RTK 是单一二进制文件,零依赖,支持 Claude Code、Cursor、Codex、Gemini CLI 等主流 AI 编码工具。
安装也非常简单,以 Claude Code 为例,三步装好:
macOS 用户直接用 Homebrew:
brew install rtk
Linux 用一键脚本:
curl-fsSL https://raw.githubusercontent.com/rtk-ai/rtk/refs/heads/master/install.sh | sh
Windows 目前没有自动安装脚本,需要去 GitHub Releases 页面手动下载对应的二进制文件。
装好之后,运行一条命令开启自动 hook:
rtk init --global
这一步会在 Claude Code 里装上一个拦截机制,每次 AI 准备执行终端命令时,RTK 会先接管处理,自动压缩输出。
不需要手动在每条命令前加 rtk。重启 Claude Code 后就生效了。
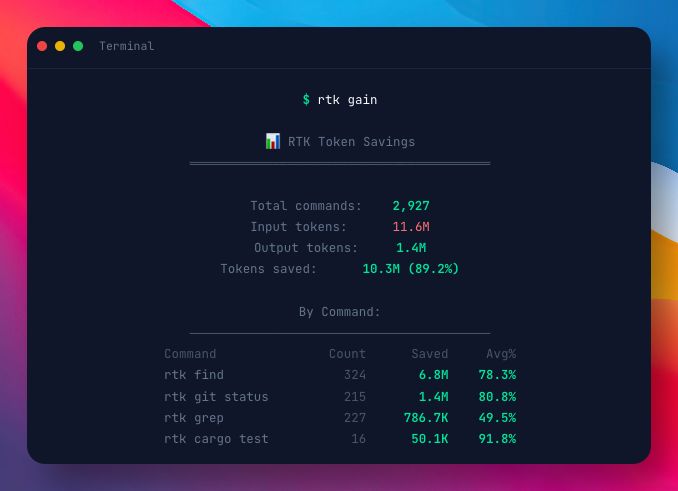
如果想要查看具体省了多少 token,可以运行下面这条命令:
rtk gain
会输出一份统计报告,显示总共处理了多少命令、节省了多少 token、各命令的平均压缩率。
写在最后
AI 编码工具这两年进化飞快,从代码补全到 Agent 自主写代码,能力边界一直在扩张。
但有一个问题始终没被正面解决:上下文窗口的利用率。
虽然模型越来越大,窗口也越来越长,但塞进去的内容,有相当一部分是终端输出的噪音。
这是一种隐性的浪费,既消耗配额,也干扰推理质量。给 AI 送进去的每一个 token,都应有价值。
这次 RTK 切入的角度就对了,不是让模型变得更聪明,而是让进入模型的信息,变得更干净一点。
装上它之后,AI 的每一次思考,都能用在真正该用的地方。
GitHub 项目地址:https://github.com/rtk-ai/rtk
今天的分享到此结束,感谢大家抽空阅读,我们下期再见,Respect!





