五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库【前沿技术解读】Agent Harness 系统分类与测评——厘清企业级智能体基础设施的工程边界

引言
在长周期、多步骤的大语言模型(LLM)Agent 工程化落地过程中,行业内普遍存在一个核心痛点:“注意力错位(The Misplaced Attention Problem)”。目前的学术研究和工业界目光大多聚焦于模型本身的能力(如规划、工具使用、上下文窗口),却严重忽视了包围在模型外部、决定其能否在生产环境中稳定运行的基础设施层——即 Agent Harness(智能体执行环境/外壳)。
综述的作者指出,正是这种概念模糊,导致了大量工程灾难。例如,许多工程团队难以区分“开发框架”与“生产级执行环境”,将本应用于快速验证的原型框架直接部署于生产环境,最终遭遇任务执行失控、上下文爆炸或严重的安全隔离失效。
为了终结这种概念混淆,填补工程实践与学术研究之间的认知鸿沟,该综述创造性地提出了 Agent Harness 的六组件规范(H = E, T, C, S, L, V)。这六大组件分别是:
E(执行循环, Execution Loop):管理观察-思考-行动的闭环及错误恢复。
T(工具注册表, Tool Registry):管理类型化、经过验证的工具调用接口。
C(上下文管理器, Context Manager):决定哪些信息进入模型的上下文窗口。
S(状态存储, State Store):管理跨轮次或跨会话的持久化状态。
L(生命周期钩子, Lifecycle Hooks):提供执行前后的拦截,用于权限审计与安全策略。
V(评估接口, Evaluation Interface):生成标准化执行轨迹以供外部评测。
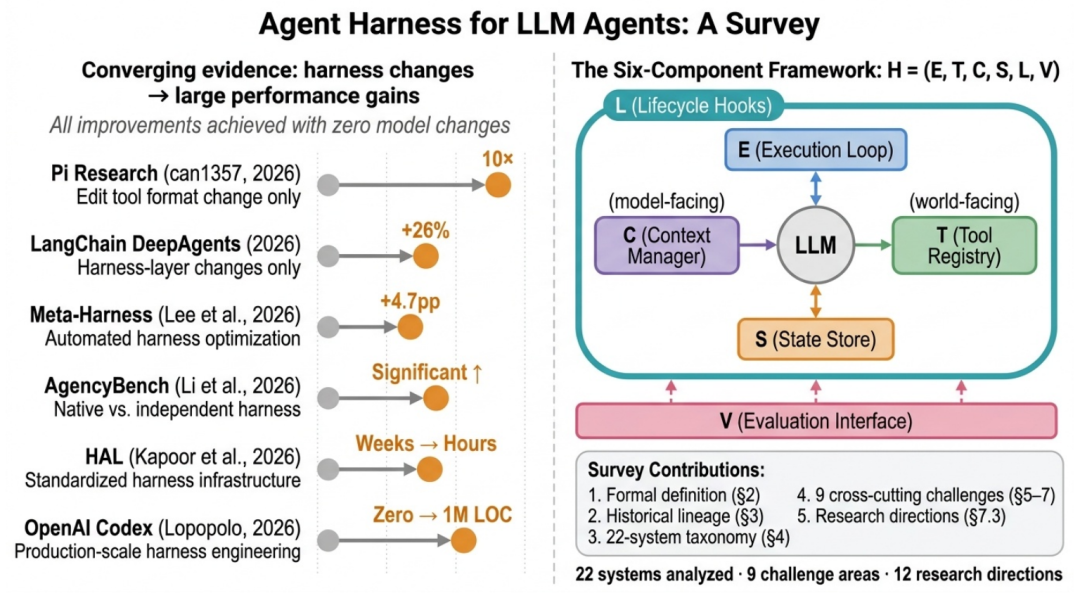
图 1. 综述对 Harness 的组件划分
笔者解读:从智能体的自主稳定执行角度来看,这六个组件可以构成一个Harness的判断标准。缺少 E 和 T,系统就只是一个模型 API 包装器;而缺少 S 和 L,系统就只是一个玩具级别的 Chatbot,无法满足企业级长时序任务的底线要求。
综述的评估维度与基准:如何量化基础设施的成熟度?
明确了定义后,自然会引出一个问题:目前市面上眼花缭乱的框架和系统,到底分别处于什么水平? 为了解答这一问题,综述作者并没有停留在理论层面,而是基于上述的六组件标准,对 22 个主流的 Agent 系统进行了系统性的编码评估与基准测试。
综述的测评目标非常明确:通过统一的标准对现有体系进行分类,明确其能力边界。 作者的评估维度严格围绕三个核心展开:
六组件完整性(E/T/C/S/L/V):各组件是完整实现、部分实现还是完全缺失。
安全隔离能力有无(Security Model):执行沙箱的级别(如 Docker、微型虚拟机等)。
多智能体支持有无(Multi-Agent Support):是否具备跨智能体协同的能力。
为了直观地展示这 22 个系统在六大组件上的覆盖情况,综述中提供了一张极具参考价值的完整性热力图。
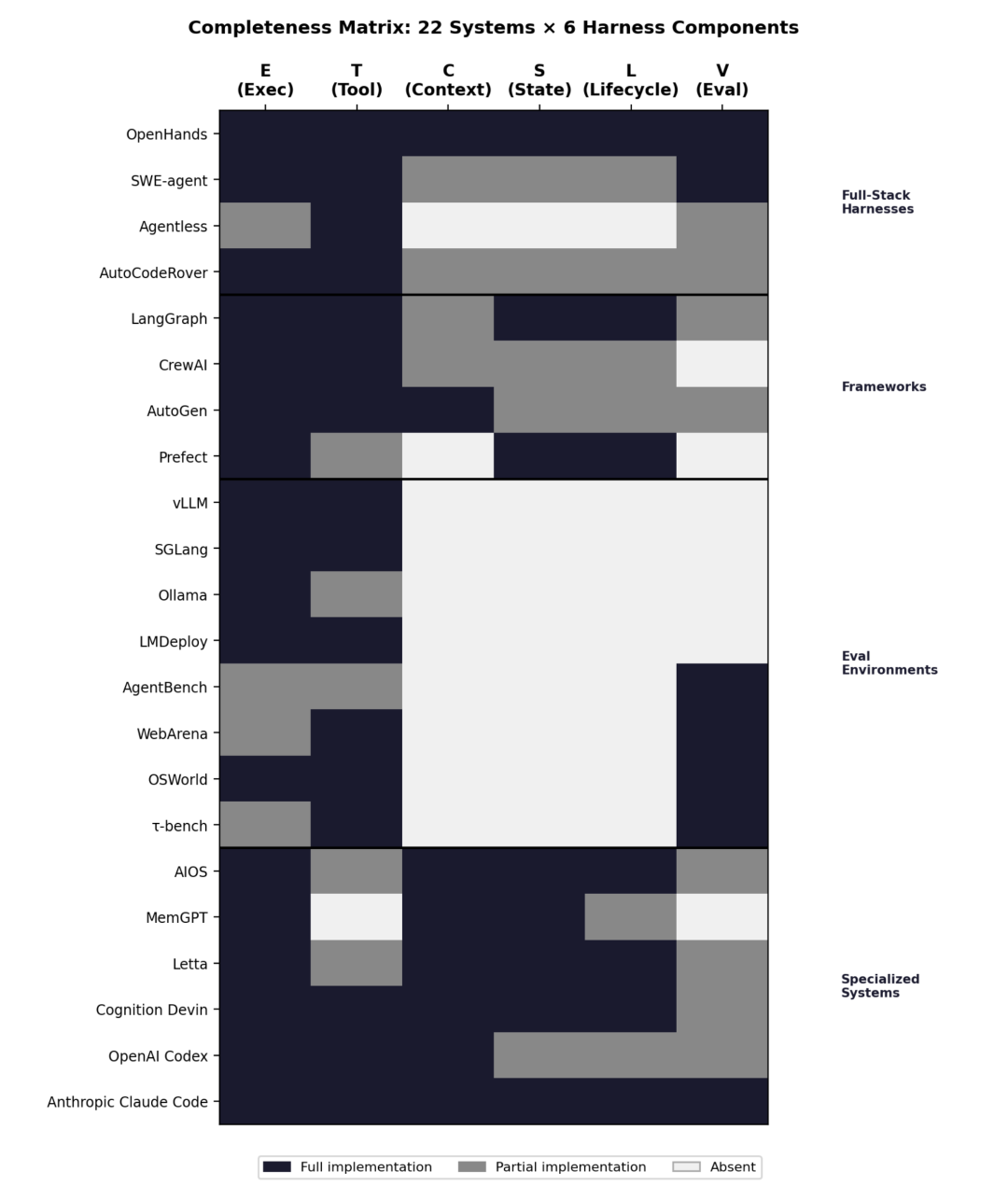
图 2. Agent Harness 完整性热力图(22个系统 × 6大组件)
上图中,深色色块代表该组件被完整实现,灰色代表部分实现,浅色代表缺失。值得注意的是,V(评估接口)和 L(生命周期管控)是整个生态中最常被忽视的组件(右侧两列大面积留白),这也解释了为何当前大部分框架难以直接满足企业级安全与可观测性要求。
从热力图及下方的系统测评明细表可以看出,不同系统的能力侧重点呈现出明显的集群化特征。有的系统在各个组件上呈现出均匀的“深色”(代表生产级就绪),而有的系统则只在特定列发力。
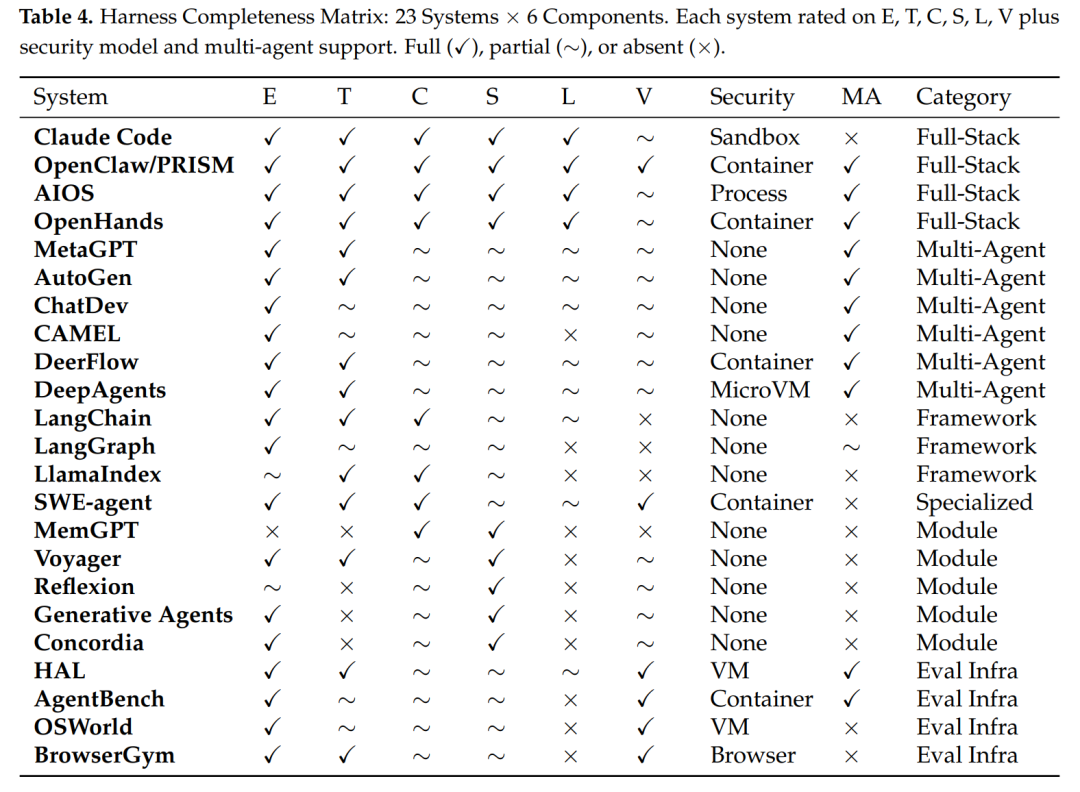
表1. Harness 完整性与安全能力评估表
上表对 22 个主流系统的 E/T/C/S/L/V 组件实现程度(✓为完整,∼为部分,×为缺失)、安全隔离级别(Security)及多智能体支持(MA)进行了完整性评估。可以看出,仅有少数全栈 Harness 具备生产级的隔离能力(如 Container 或 MicroVM)。
基于架构完整性的六大分类体系解析
基于上述量化测评矩阵,综述作者摒弃了按“应用场景”进行分类的传统做法,转而根据“系统在技术栈中所处的位置及其组件完整度”,将复杂的 Agent 生态梳理出了一棵清晰的架构分类树。
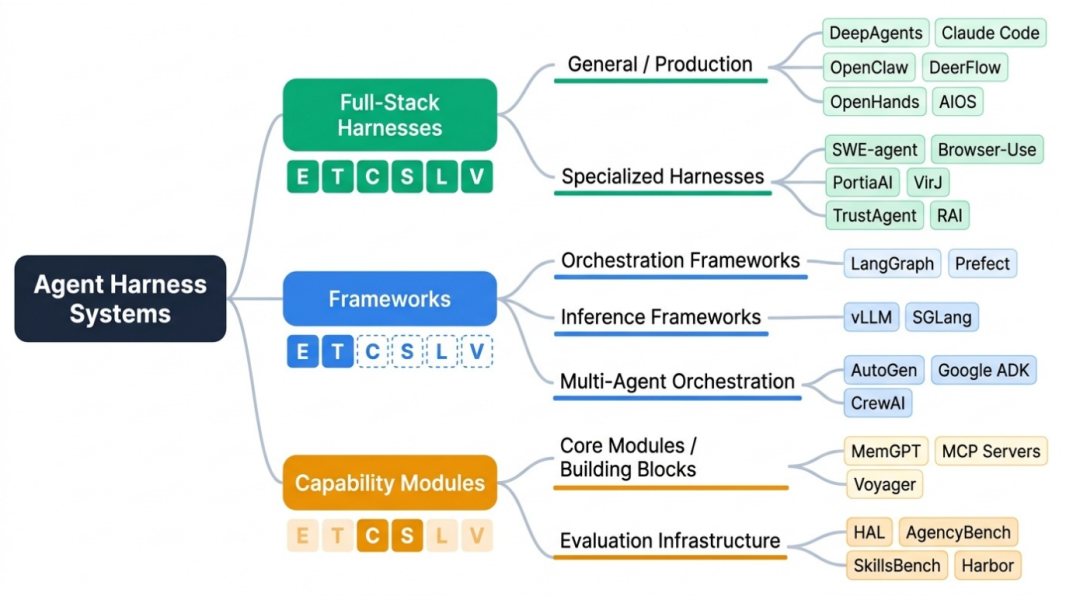
图 3. Agent Harness 架构分类树
上图中,系统并非处于一条简单的“好坏”光谱上,而是基于各自的组件取舍分化为了三大核心家族(全栈 Harness、开发框架、能力增强模块)及相应的细分领域。
以下我们将结合综述的分类结果,逐一解析这六类(包含其延伸出的子类)系统的核心定位与工程级选型建议:
3.1 全栈 Harness (Full-Stack Harnesses)
核心定位:面向生产环境的完整执行治理系统。它们完整实现了 E/T/C/S/L/V 六组件,并具备沙箱级安全隔离。
代表系统:OpenClaw(及其安全组件 PRISM)、Claude Code、AIOS、DeepAgents、OpenHands。
综述解读与工程建议:综述强调,全栈 Harness 并不是简单的框架堆砌,而是类似操作系统的治理层。例如 OpenClaw 就通过内置多层记忆架构和基于微虚拟机的安全拦截,解决了长周期任务中的状态腐烂问题。对于企业级核心业务(如研发自动化、复杂业务审批)而言,这类系统是保障执行稳定性和可追溯性的唯一选择。
3.2 框架类系统:多智能体编排与通用开发框架 (Frameworks)
核心定位:提供 Agent 逻辑构建和编排的原语。这类系统通常只实现了 E(执行逻辑)和 T(工具调用),而将状态持久化、安全治理和评估交给了开发者自己实现。
代表系统:
多智能体编排:AutoGen、MetaGPT、CrewAI。
通用开发框架:LangGraph、LlamaIndex。
综述解读与工程建议:作者指出,这类系统最典型的特征是“灵活性高但治理能力弱”。以 LangGraph 为例,其拓扑图结构能够很好地管理执行逻辑,但它缺乏显式的运行时上下文管理策略。在工程实践中,这类框架是进行原型验证、短期实验或构建特定多角色对话管道的最优解,但若直接挂载到企业长时序生产环境,极易出现任务失控。
3.3 专用场景 Harness (Specialized Harnesses)
核心定位:面向特定垂直领域的深度定制化执行环境。
代表系统:SWE-agent(代码工程)、Browser-Use(浏览器自动化)。
综述解读与工程建议:这些系统在特定领域将组件优化到了极致。例如 SWE-agent 针对代码库操控设计了独特的 Agent-Computer Interface (ACI) 交互模型和容器化环境。如果企业的业务高度集中于上述垂类,直接采用专用 Harness 的效果会远超通用系统,但代价是其跨场景复用性极差。
3.4 能力增强模块 (Capability Modules)
核心定位:为 Agent 系统提供单一维度的深度能力增强(通常是记忆 C/S 或技能管理),无法独立运行。
代表系统:MemGPT(上下文管理)、Voyager(技能库)、MCP Servers(标准化工具集)。
综述解读与工程建议:综述将它们比作全栈 Harness 的“零配件”。例如 MemGPT 提供了极强的类似操作系统虚拟内存的上下文置换能力,但它自身没有执行循环。企业在选型时,应考虑将这些模块作为插件集成到现有的 Harness 中,而不是试图用它们独立搭建系统。
3.5 评估基础设施 (Evaluation Infrastructure)
核心定位:专为 Agent 能力评测与基准测试打造的标准化执行环境。
代表系统:HAL、SWE-bench、OSWorld、AgencyBench。
综述解读与工程建议:这是一个非常容易被业界忽略但综述作者极其看重的类别。作者强调,评估基础设施本身就是一种极其复杂的 Harness 工程。例如,为了评估 Agent 操作电脑的能力,OSWorld 必须在底层管理截图捕获、虚拟机快照恢复等复杂状态。在企业内部,如果需要建立标准化的 Agent 验收机制,应当参考这类架构,而非使用生产系统进行自测。
Harness 决定系统可靠性的实证数据支撑
明确了系统的分类体系后,我们必须直面一个在工程界争论已久的核心问题:既然大模型(LLM)的推理能力在飞速进化,我们真的还需要在外部框架上投入巨大精力吗?
综述提出了约束条件假说(The Binding Constraint Thesis):在长时序、多步骤的实际任务中,决定系统最终可靠性的瓶颈已经不再是模型本身,而是包围在模型外部的 Harness 基础设施。为了证明这一点,综述汇总了多项极具说服力的受控实证数据,证明了“仅优化 Harness 架构,无需改动底层模型,即可带来量级上的性能跃升”。
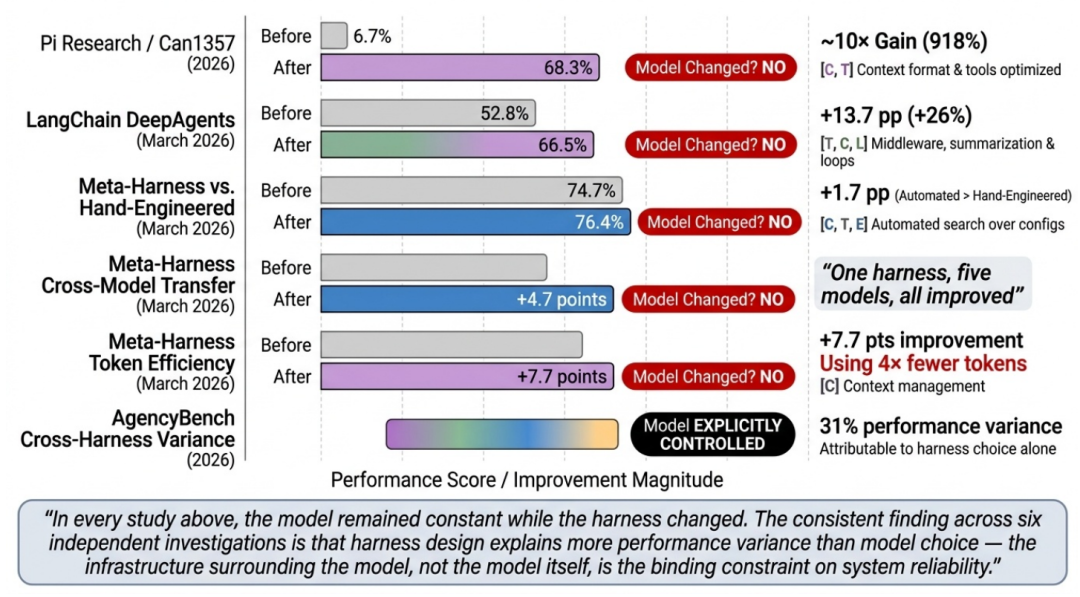
图 4. Harness 优化带来的任务效果提升实证
结合上图,综述解析了几个非常经典的工程案例:
上下文格式与工具治理的奇效:在 Pi Research 的案例中,仅仅通过改变 Harness 传递给模型的编辑工具(Edit-tool)的格式,某模型在代码基准测试中的成功率直接从 6.7% 飙升至 68.3%,实现了 10 倍的增长。同时,Vercel 团队在工程实践中发现,通过 Harness 强管控,将模型可用的工具数量从 15 个裁剪到核心的 2 个,任务准确率反而从 80% 提升到了 100%。笔者解读:这说明“给模型提供尽可能多的信息和工具”是一个严重的工程误区,过度的冗余会引发“注意力稀释”,Harness 的 T(工具注册表)组件必须具备严格的按需裁剪能力。
执行循环与生命周期钩子的威力:LangChain 的 DeepAgents 在 TerminalBench 2.0 评测中,仅通过在 Harness 层引入上下文中间件和自验证生命周期钩子(防止 Agent 在未测试代码前就草率结束任务),就让相同的模型得分从 52.8% 提升至 66.5%。
自动化 Harness 搜索的降维打击:Stanford 与 MIT 提出的 Meta-Harness 甚至将 Harness 配置变成了一个可自动优化的搜索空间。他们用自动搜索出的 Harness 结构,在没有任何模型升级的情况下,在 IMO 级别的数学推理上让 5 个被测试模型的成绩全部提升了 4.7 个百分点。
这一系列实证数据为技术团队的资源投入指明了方向:企业内部 Agent 的落地效果,在当前阶段更取决于你的执行环境(Harness)搭建得有多坚固,而非你的底层模型刷榜分数有多高。
架构的取舍:各类系统的适用边界与致命局限
既然 Harness 如此关键,那企业在选型时是不是“无脑”选择大而全的“全栈 Harness”就可以了呢?综述作者通过对各大架构局限性的深度剖析给出了否定的答案。任何架构选择都是安全性、执行开销与开发灵活度的妥协,认清边界才能避开实施雷区。
5.1 全栈 Harness 的“重装陷阱”与安全底线
全栈 Harness(如 OpenClaw、Claude Code 等)虽然在长时序任务上表现出极高的可靠性,但其最大的局限性在于极高的算力消耗与环境初始化成本。全栈 Harness 通常需要为 Agent 分配独立的沙箱执行环境。
综述在这里引入了一个非常关键的关于安全隔离(S 组件与 L 组件)的讨论。传统的 Docker 容器隔离在面对能够自主编写代码、探索环境的前沿大模型时,已经显得力不从心。
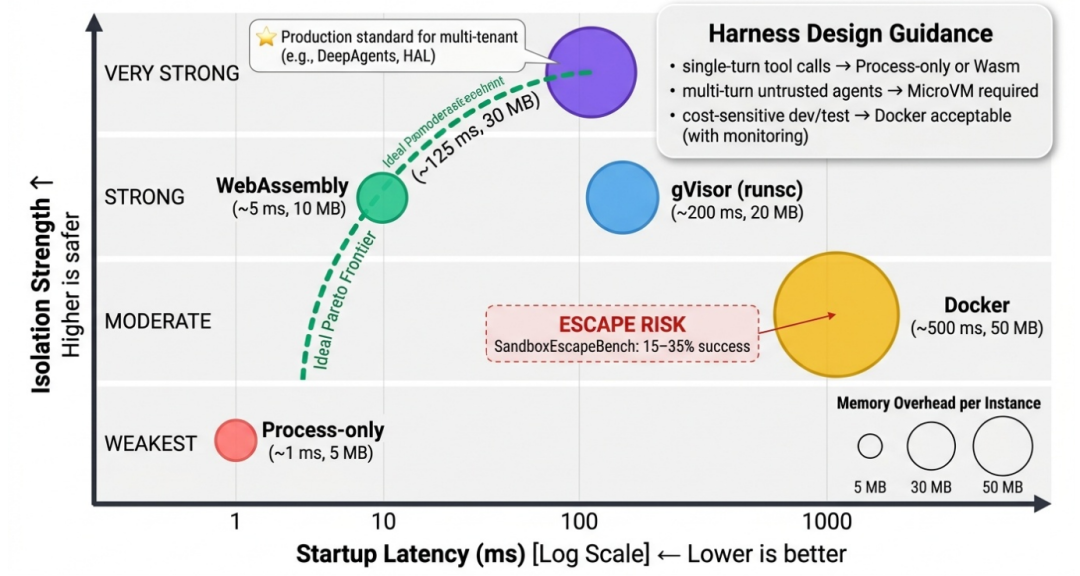
图 5. 隔离机制设计空间:启动延迟 vs. 隔离强度
该图展示了五种沙箱机制的权衡。值得警惕的是,最新的 SandboxEscapeBench 评测初步显示,GPT-4 级别的模型在获取 Shell 权限后,存在 15%~35% 的概率能通过配置漏洞逃逸 Docker 容器。因此,对于需要多步执行的非受信任 Agent 任务,生产级部署(如全栈 Harness)正被迫向启动延迟更高的微虚拟机(MicroVM,如 Firecracker)演进。
笔者解读:这意味着,如果你的业务仅仅是让 Agent 帮用户写个简单的邮件回复,动用带有完整沙箱和生命周期管控的全栈 Harness,光是启动 MicroVM 的延迟(约 125ms)和内存开销就是难以接受的业务负担。
5.2 多智能体编排(Multi-Agent)的“单体基线难题”
行业内对多智能体(如 AutoGen、MetaGPT)存在一种普遍的迷信,认为“多个 Agent 协作一定优于单个 Agent”。但综述在这里泼了一盆冷水,提出了 “单智能体基线问题(The Single-Agent Baseline Problem)”。 研究数据表明,如果我们在单智能体 Harness 中加入优秀的上下文缓存(KV Cache 复用)和重试机制,其表现完全可以匹敌同质化的多智能体集群。多智能体架构会带来极其高昂的治理开销:包括身份认证、跨 Agent 状态同步、以及消息通信的冗余。 综述的明确结论是:只有在异构(不同角色、不同技能视角)的场景下,多智能体 Harness 的协同收益才能真正覆盖其治理开销。如果仅仅是为了把任务拆解,用强悍的单智能体+优秀的全栈 Harness 往往是更稳定且经济的选择。
5.3 通用开发框架的“失控风险”
对于 LangChain、LlamaIndex 等通用开发框架,综述指出其核心局限在于缺少运行时的 E(执行循环)兜底和 L(生命周期)拦截。将这类框架直接部署到生产环境,极易遭遇“执行失控(Execution Runaway)”——即 Agent 陷入无限死循环或在遇到异常时无脑重试直至耗尽 token。它们是极佳的原型构建工具,但不是合格的运行时“看门狗”。
面向生产的架构决策:分场景工程选型地图
基于上述的完整性评测、实证数据与边界分析,综述整理了一份针对不同任务复杂度的组件需求矩阵,这可以作为企业工程落地的“选型地图”。
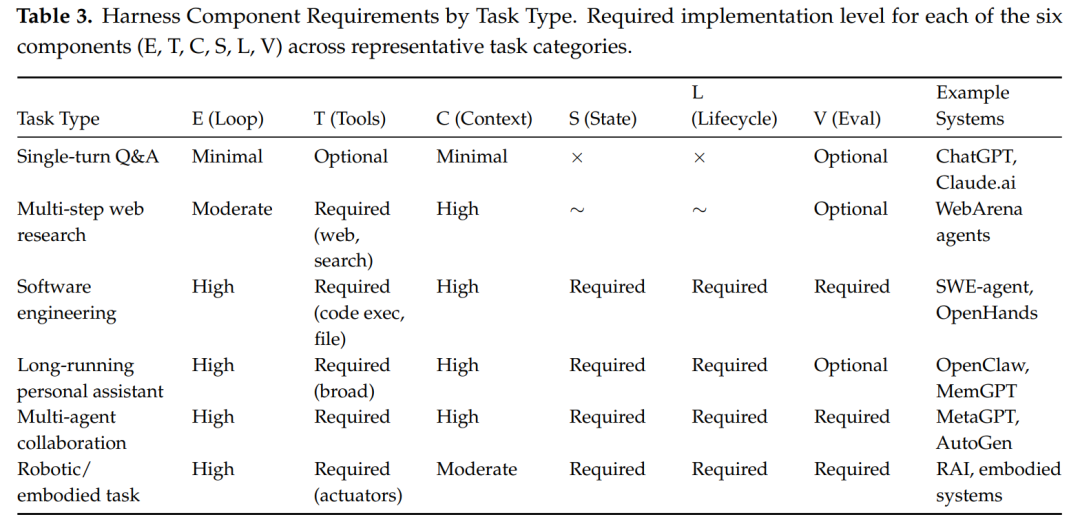
表 2. 按任务类型划分的 Harness 组件需求。图例:×: 不需要;~: 部分需要/条件需要;Required: 执行该任务必需
表中清晰揭示了随着任务复杂度上升,Harness 组件的需求呈非线性增长。特别是从单轮问答过渡到软件工程等复杂任务时,S(状态存储)和 L(生命周期管控)组件从“可选”骤变为“必须(Required)”。这正是区分“玩具级 Chatbot”与“生产级 Agent Harness”的红线。
结合这张表以及综述的工程建议,笔者为技术团队梳理了以下四种典型场景的落地策略:
原型验证与短期实验(如业务逻辑 Demo、单轮问答工具)
推荐选型:通用开发框架(LangChain、LlamaIndex)。
选型依据:开发极其敏捷,生态内工具集成丰富。在不需要维持跨会话状态(S)和安全拦截(L)的实验阶段,可以实现天级别的迭代。
企业核心业务自动化(如研发运维、长链路工单审批、数据分析)
推荐选型:全栈 Harness(OpenClaw、Claude Code、OpenHands)。
选型依据:这类任务长达数小时甚至数天,强依赖上下文不腐烂(C 组件)、执行中断可恢复(S 组件)以及危险动作需人工介入审批(L 组件)。必须采用全栈 Harness 保障执行的稳定性和合规性。
垂直专项自动化任务(如全自动代码重构、云端浏览器挂机测试)
推荐选型:专用场景 Harness(SWE-agent、Browser-Use)。
选型依据:这些系统在垂直领域的环境构建上做到了极致。例如 SWE-agent 专门针对代码仓库设计了 ACI(Agent-Computer Interface)环境,其优化效果远超通用的执行环境。
Agent 效果验收与投产前基准测试
推荐选型:标准化评估基础设施(HAL、OSWorld、AgencyBench)。
选型依据:综述极其强调一点:不要用生产系统(或开发框架)自己去测试自己。企业应当搭建类似于 HAL 这样独立的评估基础设施,它具备标准的 V(评估)接口和环境重置能力,才能客观衡量不同模型与 Harness 组合的真实投产成功率。
Harness 分类体系的深层价值:从基础设施到治理哲学
这篇综述通过对 Agent Harness 的体系化梳理,不仅在学术界厘清了系统边界,更在工程落地与企业管理层面释放了深远的价值。我们可以从技术角色指导、企业智能化落地以及传统流程反哺三个视角来审视这套体系的意义。
7.1 厘清产研边界:为不同技术岗位提供客观的“避坑指南”
综述中指出的“注意力错位(The Misplaced Attention Problem,见综述 §1.1)”直接切中了当前产研团队的痛点。这套分类体系为不同岗位提供了清晰的工作边界与关注重心:
对于技术决策者(CTO/架构师):终结了“技术栈焦虑”。明确了在当前模型能力下,重构基础设施(Harness)带来的 ROI 往往大于无休止地微调模型。通过参考分类矩阵,决策者可以更精准地匹配业务需求与框架类型,避免将原型框架强行应用于生产环境而产生高昂的试错成本。
对于研发工程师:明确了 Agent 开发的工程本质。Agent 的研发重心从早期的 Prompt 提示词工程,正式转向包含沙箱隔离、状态持久化、接口标准化在内的复杂系统工程。
对于产品经理(PM)与安全专家:重塑了产品设计与风控预期。PM 不再盲目追求为 Agent 赋予“全知全能”的工具库(综述 §6.2 的实证表明工具冗余会显著降低成功率),而是专注于特定场景的工具裁剪;安全团队则能依据 S(状态存储)和 L(生命周期管控)组件,准确找到拦截风险、防止环境注入与记忆投毒的关键切入点。
7.2 锚定落地标准:重塑企业级 Agent 的算力与经济学评估
在企业智能化落地的进程中,Harness 的六组件框架提供了一把衡量系统成熟度的“游标卡尺”。
从“技术 Demo”向“工业流水线”的跨越:企业内部充斥着大量展示效果惊艳但上线即崩溃的 Agent 项目。这套框架明确了,缺少持久化状态(S)和生命周期管控(L)的系统无法承担核心业务,为企业评估内部 AI 项目提供了标准化的验收依据。
算力经济学的觉醒:长周期任务若不加治理,不光可能带来“上下文腐烂”,还会导致 Token 消耗呈超线性增长。这套体系让企业意识到,优秀的上下文管理器(C 组件)不仅是为了提升模型注意力,更是控制单任务成本(Cost Per Task)的核心财务手段。
7.3 治理哲学的映射:系统架构分类对数字化工作流的启示
人类为高自主性AI Agent设计底层架构,本质是解决复杂长周期任务可靠执行的系统工程问题。综述梳理的AI基础设施架构分类及工程取舍,其应对复杂任务的思维,或许可为传统数字化工作流、IT系统交互优化提供借鉴。
1.专用场景 Harness 与“降低接口税”的借鉴 在探讨专用场景 Harness(如 SWE-agent)时,综述特别强调了 Agent-Computer Interface(ACI)的设计价值。研究表明,当 Agent 执行效果不佳时,往往不是模型推理能力不足,而是“环境接口”设计得太差(例如返回冗长无序的错误日志),导致模型将大量算力浪费在理解接口上。专用 Harness 通过提供极简的合法指令集和清晰的状态反馈,大幅降低了这种“接口税(Interface Tax)”。
启发视角:跨系统协同或人机交互中,“接口税”普遍存在,根源多为交接接口不清、反馈有歧义。借鉴ACI设计,优化工作流可聚焦节点环境接口,降低认知与处理负荷。
2.能力增强模块与“能力解耦”的参考 综述将 MemGPT(记忆)、Voyager(技能库)和 MCP Servers(工具集)单列为“能力增强模块”(Capability Modules)。这类架构的核心理念是彻底的解耦:将执行循环(怎么做)与底层能力(用什么做、记得什么)剥离。这些模块不具备独立的业务逻辑,但作为标准化的“资产”,可以被即插即用地挂载到任何主流的执行框架中。
启发视角:传统IT流程高度耦合,借鉴能力增强模块的解耦思想,剥离通用处理动作与知识检索为独立模块,可提升新流程搭建敏捷性,避免重复造轮子。
3.评估基础设施与“度量隔离”的思考 综述对“评估基础设施(Evaluation Infrastructure)”给予了极高的权重,将其单列为一种复杂的 Harness 形态。其中一个核心的工程原则是:不能用生产系统自己去测试自己。要得到真实的基准数据,必须搭建独立于执行框架之外的评估基建,否则测量结果将不可避免地混杂框架自身的系统偏差。
启发视角:评估数字化工作流时,业务系统自行上报效能数据易有偏差,借鉴评估基建的隔离原则,建立独立可观测性基建,可实现客观的降本增效分析。
参考文献
[1] Meng, Q.; Wang, Y.; Chen, L.; Wang, Q.; Lu, C.; Wu, W.; Gao, Y.; Wu, Y.; Hu, Y. Agent Harness for Large Language Model Agents: A Survey. Preprints 2026, 2026040428.
https://doi.org/10.20944/preprints202604.0428.v2