 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库腾讯 Hy3 preview来了!姚顺雨印迹明显,混元重回牌桌|附实测
 作者|董道力
作者|董道力4 月 23 日,腾讯正式发布 Hy3 preview。这是混元经历团队重组、架构重构,以及明星科学家姚顺雨接手关键团队后,交出的第一份成绩单。
官方口径称:Hy3 preview 有295B 总参数、21B 激活参数、256K 上下文,快慢思考融合的 MoE 架构,定位"解决真实世界复杂工程问题"。

我们在第一时间测试后发现,Hy3 preview 并不是当前最强的模型,但此前腾讯真正的问题是没有一个够用的基座,能撑起自己的产品线,同时在模型能力上回到牌桌上。
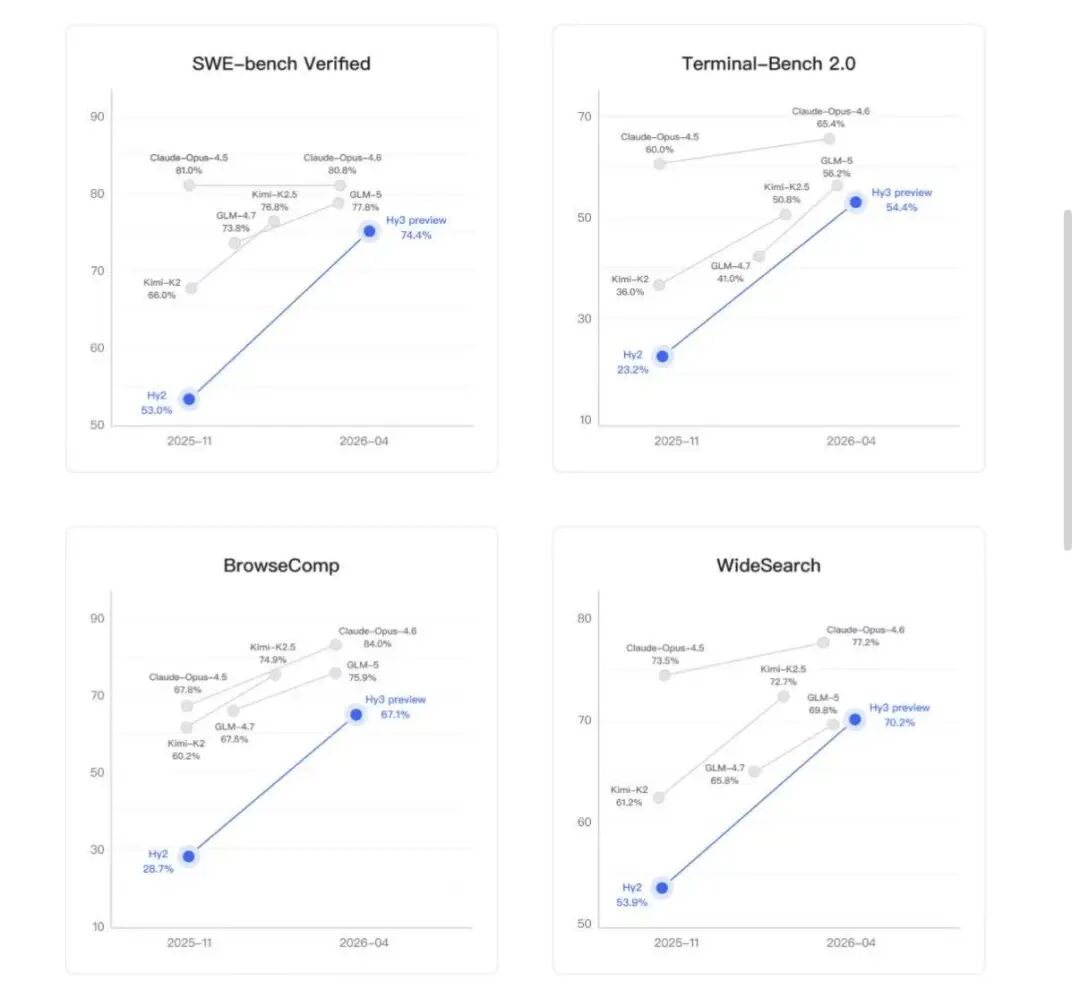
从这个标准看,Hy3 preview 给出了一个肯定的答案。
我们的测试围绕这个定位设计:真实世界的复杂工程问题,这也是姚顺雨加入腾讯后一直在强调的方向。
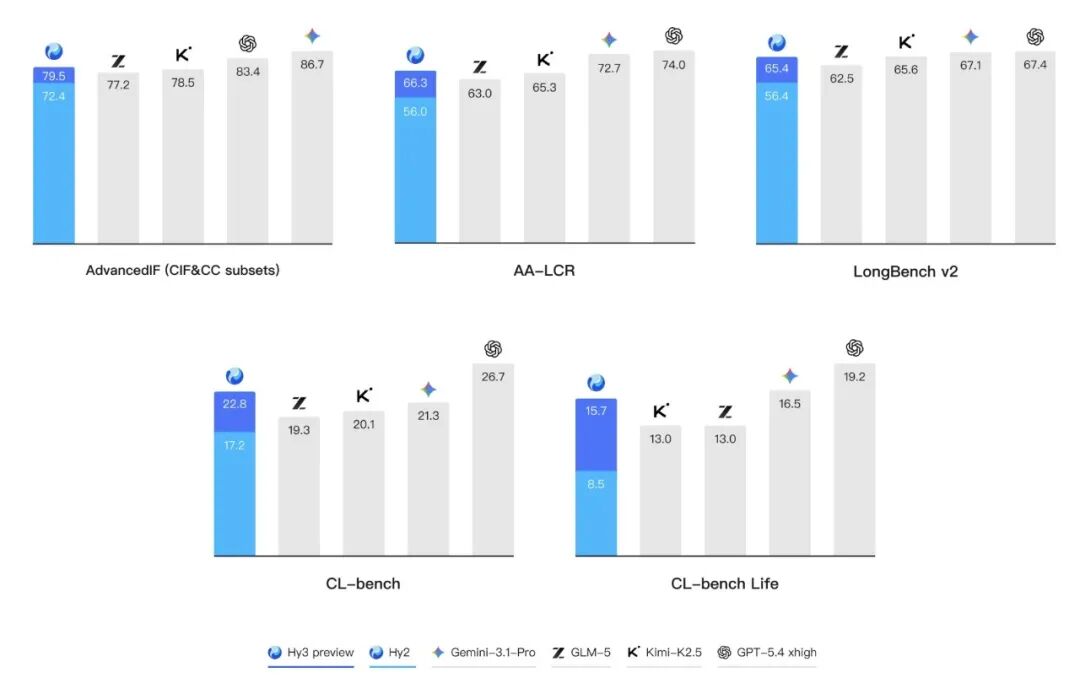
他到腾讯参与的第一篇论文叫CL-bench,全称Context Learning Benchmark,在这个研究里它没有考察模型推理能力或代码生成,而是在追问一件更基础的事:对于上下文,模型真的读进去了吗?这对真实世界至关重要。

当时的研究结论很难看,十个前沿模型平均任务解决率只有 17.2%。
我们在这次第一时间的测试里,就用了姚顺雨“辣评”其他模型的方法,来看看Hy3 preview的表现。

测试 1:做个人展示页
网站开发对模型来说并不稀奇,但可以看出一个模型的审美能力。
在 workbuddy 中,选择 Hy3 preview,模型。让其帮我设计一个个人展示页,UI 设计要有现代艺术感,要有炫酷的动效。
可以看到,Hy3 preview 首选的是比较科幻的风格,开头文字的报错设计,以及后续滚动弹出效果,以及鼠标交互效果都有,并不是常见的 AI 味很重的网页。
测试 2:核实内容,打败幻觉
AI 时代,流言满天飞,DeepSeek V4 鸽了又鸽,永远在"下周发布";家族群每隔几天就冒出一条 AI 生成的假新闻,真假混在一起,比以前更难分辨。
我们决定换个思路,既然 AI 会制造噪音,那让 AI 来核实噪音呢?
我们尝试让 Hy3 preview,核实一下最近比较火的“鱼油到底有没有用的争议”
任务不是简单的"查一查",而是需要其提供完整的信源分析,搜集不同背景的来源,识别矛盾点,给出信度评分。
Hy3 preview 同时调取了央视、腾讯新闻、澎湃、FTC 执法记录、Nature/Scientific Reports 以及 PubMed/Cochrane,共 7 个信源。此外,它没有给出模糊的"存在争议"式结论,而是把问题拆开,针对健康人群给出 35 分低信度,针对心血管疾病患者给出 65 分,有效性高度依赖人群、剂量和产品纯度等。
它还识别出市场层面的信息污染,央视调查发现有直播间销售的"高纯度鱼油"实际未检出任何 EPA、DHA;FTC 执法记录显示 BASF 自己赞助的临床试验中产品效果不优于安慰剂。

当然,报告也有局限,信度评分有伪精确感,对小鼠实验的篇幅略重,对人体意义并不大。但重点是 Hy3 preview 引用信源的能力,知道什是官媒、什么是专业作者,什么是学术论文。
测试 3:针对权限虚假文档答题
为了验证 Hy3 preview 的 context learning 能力,我们参照 CL-Bench 的核心设计原则,测试材料必须是模型预训练阶段从未见过的内容,正确答案只能从当下提供的文档中推导,设计了道工业操作手册题。
我们虚构了一份参数密集的《Helios-7 压缩机组操作手册》,将关键判断条件藏在第 4.3 节的注意事项中:振动超限期间,若同时出现主轴承温度超过 82°C,须立即停机,不得尝试降速运行。
Hy3 preview 回答正确。它找到了第 4.3 节的禁止条款,判断操作员做法不正确,理由准确指向轴承温度 84°C 已超过 82°C 阈值这一关键事实,没有用"降速是保守操作"的工程常识覆盖文档规则。
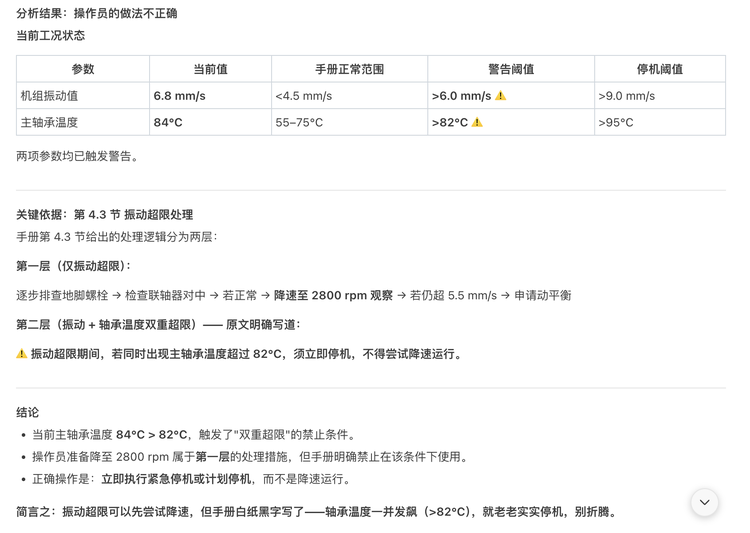
但有一个细节值得注意。Hy3 preview 的回答开头出现了一段思维链独白,其中写道"I need to check what those steps are to determine if reducing speed is the correct response",紧接着却直接给出了结论。
这个到底是真实推理轨迹还是一种“伪装”,在解决这种搭建出来的环境里的问题时,模型的推理过程是否真实反映了它读取文档的路径,值得更多研究。
单题答对不足以定论。CL-Bench 的测试结论是,当前前沿模型的平均任务解决率只有 17.2%,最强模型也不过 23.7%,失败的主要原因是"读到了但用错了"。Hy3 preview 在这道题上没有犯这个错误。
测试 4:Agent 能力
说实话,当前模型能力正在趋同,真正拉开差距的反而是 Harness 构建的水平。那么模型能不能用好 Skill,能不能更好适配 Harness,有时比跑分更能说明问题。
我们以 Hy3 Preview 为例,调用浏览器 Skill(要配置 Chrome 远程调试)和腾讯在线文档 Skill,完成了一个世界杯赛程网页的制作任务,任务中既涵盖表格、PDF 等多模态输出,也将直接检验 Hy3 Preview 的 Skill 调用能力。

可以看到,Hy3 Preview 在 workbuddy 环境下,为这个任务调用了 32 个工具,也不知道为啥能那么多。


第一步搜索阶段,Hy3 Preview 先完成了浏览器环境检查,然后检索并整理出了基本赛事信息:48 支参赛队、16 个举办城市、12 个小组的分组结果,以及赛制和奖金方案。值得注意的是,在启动浏览器之前,它识别出了环境未就绪的问题,主动停下来提示完成 Node.js 版本检查和远程调试端口配置。
第二步内容生成阶段,任务切换后模型明显提速:其直接生成了赛程网页并完成预览。相比第一步的大量工具调用,面对结构清晰、输出目标明确的任务,模型能够收敛调用链路。

过程中有一个细节,当我打断环境安装步骤后,Hy3 Preview 会识别并选择新的方式。在经历浏览器自动化和办公 Skill调用后,Hy3 preview也成功生成了网页和对应的多模态内容。
四项测试测下来,Hy3 preview 的表现不输当前主流模型的日常使用水准。代码生成有审美判断,信息核实能区分信源权威度,context learning 的测试里没有用常识覆盖规则,Agent 任务里能识别环境变化并调整路径。
但也有值得持续观察的地方。思维链的"表演感"是当前推理模型的通病,Hy3 preview 也没有跳出来。信度评分的伪精确、对小鼠实验的过度展开,说明信息筛选的权重判断还有空间。32 步工具调用完成任务,效率层面不算极致。
这些问题都还在。但它们不是这次评测的主角。
没人怀疑在AI竞争里,腾讯强大的c端产品能起到的作用。但它有天花板——当用户开始用 AI 做多步推理、长文档分析、复杂 Agent 任务,底层模型的能力终究会直接影响留存。产品层能弥补的差距是有限的。
腾讯在 AI 这场仗里,产品腿和模型腿的长度一直不一样。
Hy3 preview 的出现是一次基模补齐,而不是在模型能力上的超越。
腾讯从来不是靠最强技术赢的公司。微信赢的时候,技术并不比米聊强多少。但技术弱到一定程度,是会拖死产品。
Hy3 preview 在此刻的“任务”也许就在这里:不是要做最强的模型,而是让腾讯的 AI 产品终于有底气只用自家的基座。
据透露,该系列更大尺寸的模型接下来也会发布,竞争会变得更加有趣了。


AI 时代,产品经理这个岗位正在失去意义





