 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库腾讯混元大模型重建第一步,用Hy3 preview验证自己的AI节奏

文|晓静
编辑|徐青阳
4月23日,腾讯发布并开源混元 Hy3 preview。这是一款快慢思考融合的MoE架构语言模型,总参数295B、激活参数21B,256K上下文。这也是混元迄今最智能的模型,主打全面实用性,Agent能力大幅提升。
这次发布距离腾讯2026年2月重建预训练和强化学习基础设施,只过去了不到三个月。Hy3 preview是混元团队重组之后正式发布的第一个新模型。
腾讯首席AI科学家姚顺雨将它定义为“混元大模型重建的第一步”,并表示:“我们正在持续扩大预训练和强化学习的规模来提升智能上限,通过和腾讯众多产品的深入 Co-Design来持续全面提升模型性能,并探索非同质化的模型能力。”
这句话勾勒出三层目标:继续把规模和智能上限往前推;不把模型当成孤立产品,与腾讯自有的产品体系联合设计;不走同质化路线。结合管理层近期在财报电话会和公开演讲中的表态,在模型之外,Hy3 preview 要验证的是一条追求“全面实用性”的路线,打好生态与工程地基,把 AI 真正放进真实业务场景里去跑。

01
为什么是 295B?
Hy3 preview 选择总参数 295B、激活参数 21B 的规格,相比较近期发布的动辄万亿参数的模型,单从总参数量来看确实并不突出,但是这背后是对于“实用性”的理解。
在能力上,复杂推理、长上下文理解、指令遵循等能力在300B量级已经能够充分释放。
在成本上,300B与1T+模型之间隔着一道工程鸿沟。300B级别的MoE模型经过量化后可实现单机部署;而 1T+ 模型无论架构如何都必须跨节点。一旦涉及多机通信,延迟、吞吐、运维复杂度都显著提升,而推理单价则可达数倍之差。
在落地上,在大多数应用场景中可以通过 RAG、Agent等工程手段有效缩小与使用顶级大模型的差距;量化后的推理成本和微调门槛足够低,让私有化部署和行业适配更切实可行。
不在所有单项上和头部模型死磕,选择在一个可交付、可运营、可被产品吸收的尺寸上把实用能力做扎实。
性价比在实用性的语境下也变成一个可量化的变量。腾讯云公开的 API 价格为输入最低1.2 元/百万 tokens,输入命中缓存价格0.4元/百万tokens,输出最低4 元/百万 tokens;同步推出的Hy3 preview Token Plan 个人版定价最低28 元/月。
这个定价在“同尺寸旗舰开源 MoE 模型”赛道里属于最低价梯队,输出价尤其具备显著竞争力;28 元/月的个人套餐定位在入门与专业订阅之间。
支撑这一定价的是 AI Infra 推理团队的一轮全栈优化,得益于模型和推理框架上的深度协同,以及在推理框架、算子性能、量化算法等全方面优化,整体推理效率提升40%,Hy3 preview的成本相比上一代模型大幅下降。
Hy3 preview 也已在 OpenRouter 等海外 API 聚合平台、OpenClaw 等智能体开发套件上架,支持主流硬件推理平台的适配。
02
基本功:Hy3 preview的技术特点
Hy3 preview 的能力在四个方向全面提升,不推崇“偏科”,即使是代码智能体的单一应用,也涉及推理、长文、指令、对话、代码、工具等多种能力的深度协同。这也是模型能达到实用性的重要前提。
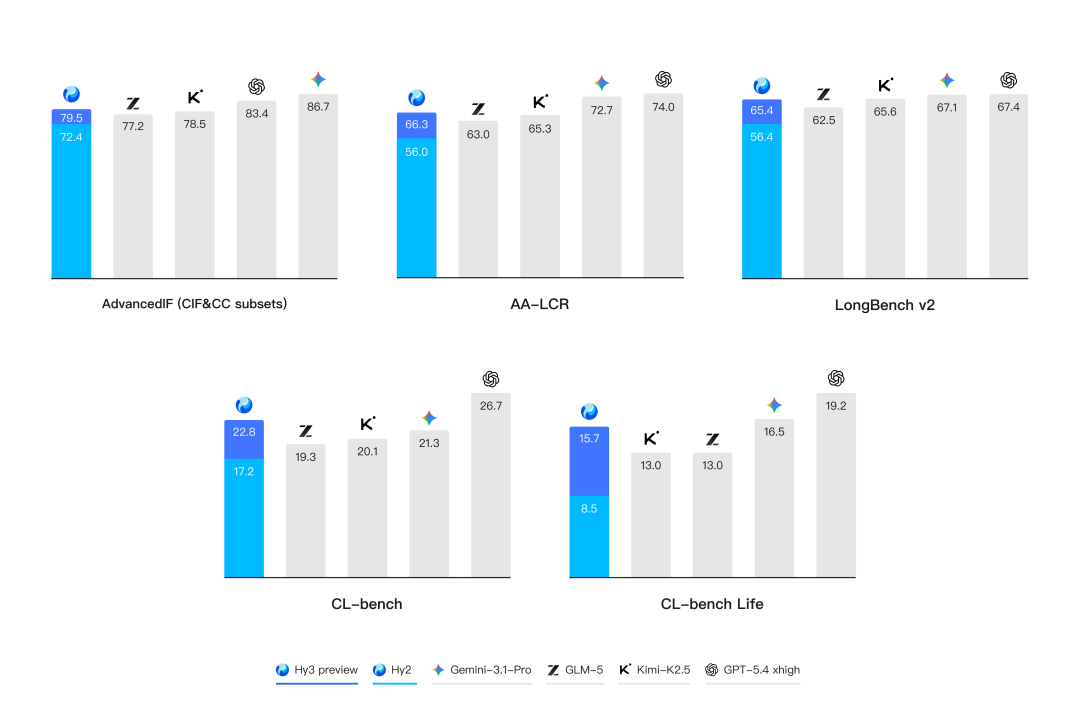
指令遵循与长上下文构成实用性的底盘。在各种真实的生产与生活场景,理解杂乱冗长的上下文并遵从复杂多变的规则是模型的首要挑战。基于腾讯业务场景的灵感,腾讯混元提出了 CL-bench和 CL-bench-Life 来创新性地评估模型的上下文学习能力,并在 Hy3 preview 显著地提升了模型上下文学习和指令遵循能力。
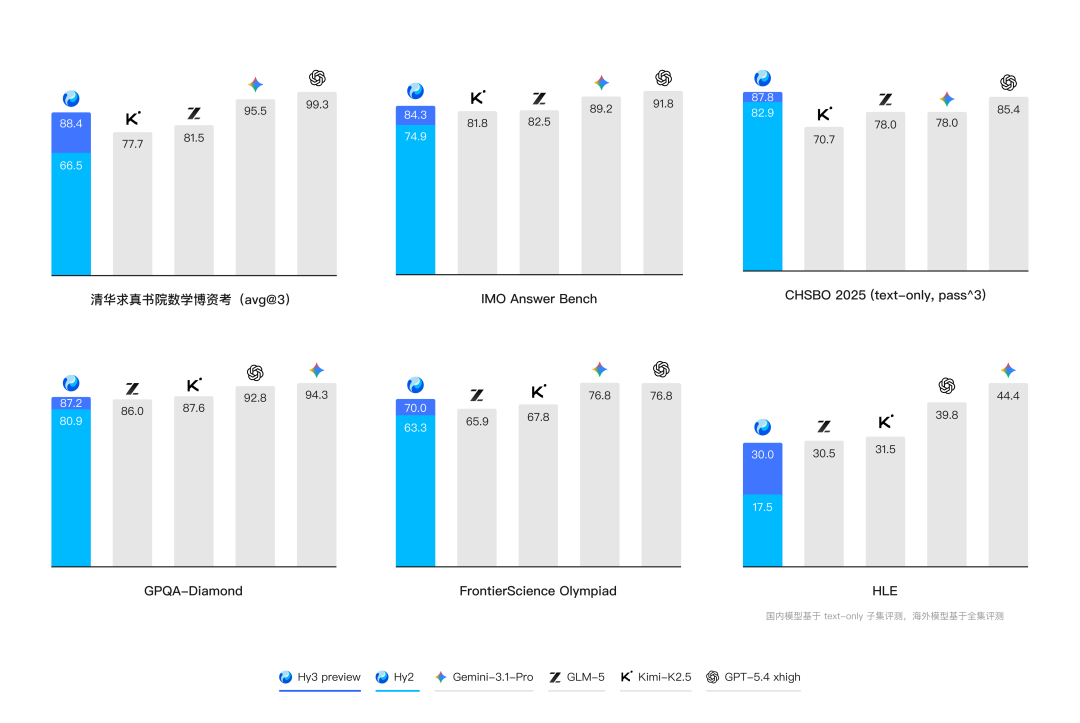
复杂推理能力是模型解决各种问题的基础。Hy3 preview 在 FrontierScience-Olympiad、IMOAnswerBench 等高难度理工科推理任务中表现突出,并在最新的清华大学求真书院数学博资考(26春)和 全国中学生生物学联赛(CHSBO 2025) 中取得优异成绩,展现了可泛化的强推理能力。
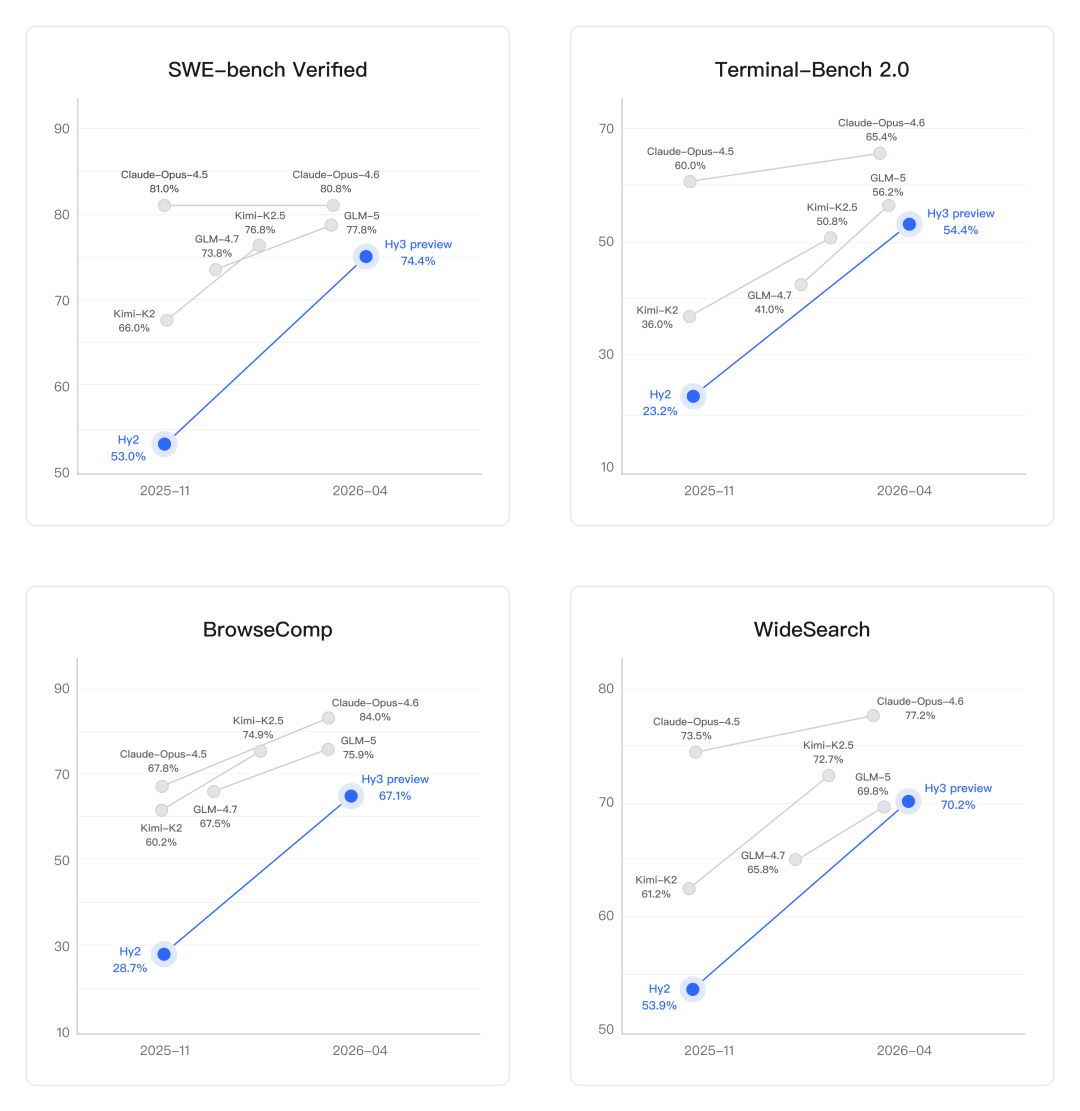
代码和智能体是Hy3 preview 提升最为显著的方向。得益于预训练及强化学习框架的重建和强化学习任务规模的提升,腾讯混元以较快的速度在 SWE-Bench Verified、Terminal-Bench 2.0 等主流代码智能体基准以及 BrowseComp、WideSearch 等主流搜索智能体基准中取得了有竞争力的结果。
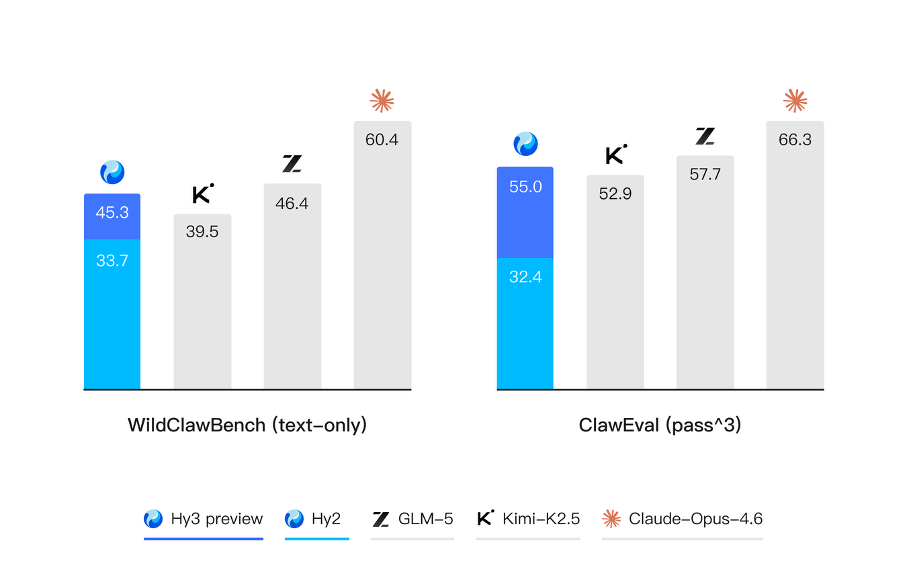
在数字世界中,代码关注的是模型在开发环境中的执行能力,搜索则聚焦于开放信息空间中的检索、筛选与整合能力,两者共同决定了模型在复杂智能体场景(例如 OpenClaw)中是否真正具备可用性。Hy3 preview 在 ClawEval 和 WildClawBench 等评测中表现突出,表明我们的智能体能力正在稳步走向全面与实用。
除了公开榜单,腾讯混元还进一步构建了多个内部的评测集,对模型在真实开发场景中的表现进行评估。结果表明,无论是在后端工程任务集 Hy-Backend,贴近真实用户开发交互的 Hy-Vibe Bench,还是高难度软件工程开发任务集 Hy-SWE Max 上,Hy3 preview 均体现出了强竞争力。
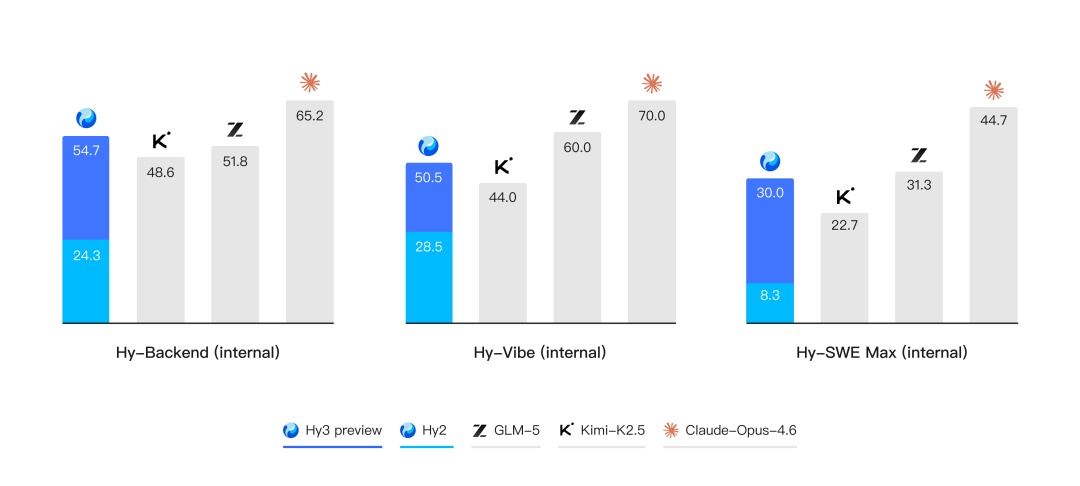
比较各个开源模型的大小与智能体综合表现,Hy3 preview展现出高性价比。
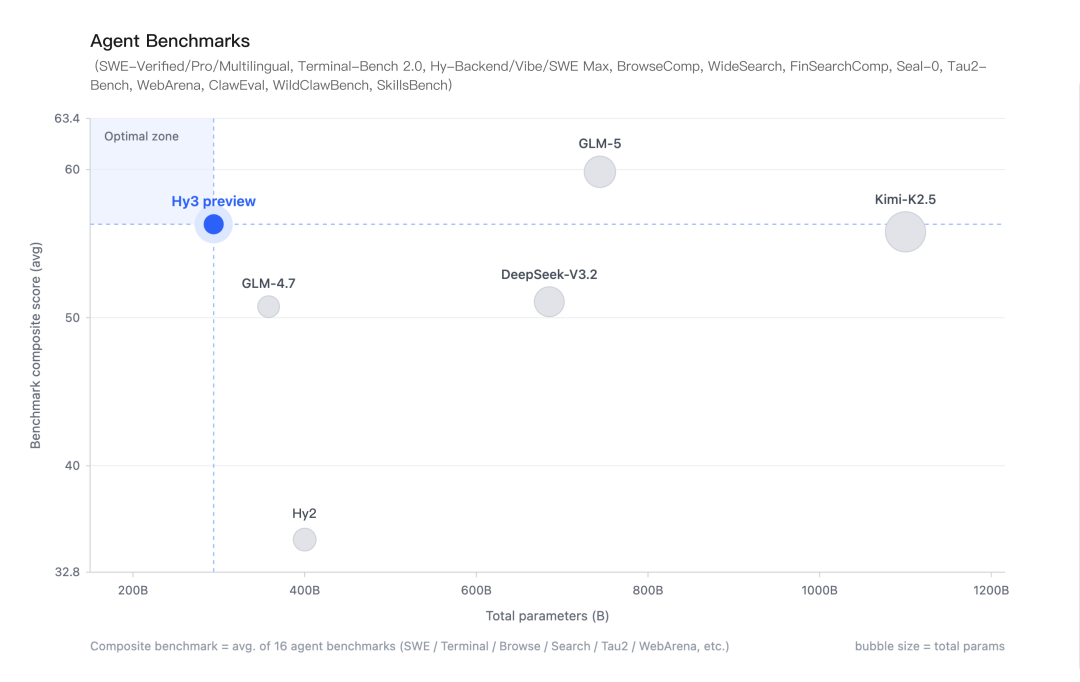
03
“一模千面”,与产品的Co-Design
如何评估模型的真实能力?混元团队的判断是,不能仅仅通过Benchmark的分数体现。Benchmark衡量能力上限,用户感知的可能是能力下限;而工程集成,包括RAG、system prompt、工具调用等,会进一步改变模型的真实表现。在实际业务场景中的实用性落地,才能看出模型最真实的能力。
Hy3 preview已同步上线腾讯内部多个产品,并且适配每个产品,跑出了不同的“模型感觉”。
腾讯新闻在较真AI项目已接入Hy3 Preview进行测试,Hy3 no-think模式效果基本对齐原链路的深度思考模式,平均响应时间仅为1/5。在新闻相关agent 场景的应用测试中,Hy3指令遵循能力比Hy2.0提升明显。
在元宝中,Hy3 preview主打“人味儿”,能善解人意地针对不同场景,给出不同语境的回答。写段子、撒娇、一本正经写个请假邮件,都挺对味儿。
在ima的知识库问答和通用问答场景下,Hy3 preview 处理长文的能力突出,回答的信息覆盖度和全面性明显提升。ima正持续向Agent方向升级;Hy3 preview 的长文能力让 ima 能够支撑图文报告、播客、PPT、互动测验等更重的内容形态生成。
在和平精英中,游戏局外的人设扮演场景中,Hy3 preview不仅能够精准理解角色设定,还能针对开放性问题输出高度关联、富有增量价值的内容,带来了更加真实、自然、沉浸的对话体验。
在腾讯文档中,以AIPPT场景为例,Hy3 preview模型较上一版本(Hy2.0)取得了显著进步:生成成功率提升 20%,评测得分提升 10%,同时生成耗时缩短 20%。
整体而言,新模型在评测场景中表现优异,在模版选择,色彩匹配,生成大纲,补充内容多个阶段,均体现出优秀的表现,无幻觉,契合主题,视觉效果好,后续应用值得期待。
此外,腾讯QQ浏览器、腾讯金融自选股、腾讯客服等多个业务也正在接入Hy3 preview模型,通过混元大模型和腾讯产品的深入融合模式,为用户提供更智能的产品体验。
3月上线的 WorkBuddy,特点是长链路任务,比如从微信/企微侧远程调起桌面,读取文档、处理数据、生成报告,考验模型在“上下文保持 + 工具调用 + 长记忆”上的综合表现。Hy3 preview 与国内同尺寸模型的用户盲评胜率达到 56%。腾讯内部曾有超过 2000 名员工参与 WorkBuddy 内测,过去需要几个小时的工作现在 20 分钟内完成,tokens 消耗持续增长。
腾讯科技也在Workbuddy中提前测试了Hy3 preview。
第一个场景是在工作中使用较多的深度调研。
提示词是:基于OpenAI最新发布的image2进行深度研究并形成深度研究报告:为何它能实现如此惊艳逼真的文字渲染?官方是否公开过更多技术细节?它和image1.5有什么本质不同?为何不再以4o、5o的系列名字命名?它和竞品nanobanana的技术架构的不同,为何实现效果又比nanobanana更进一步?输出文字版的调研报告和可视版的html页面。
可视化版本的最终呈现效果如下:
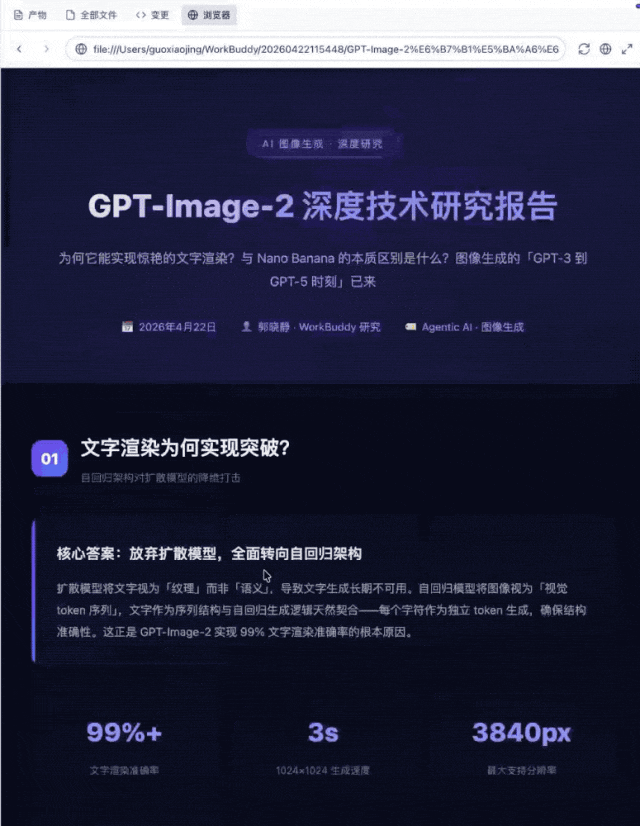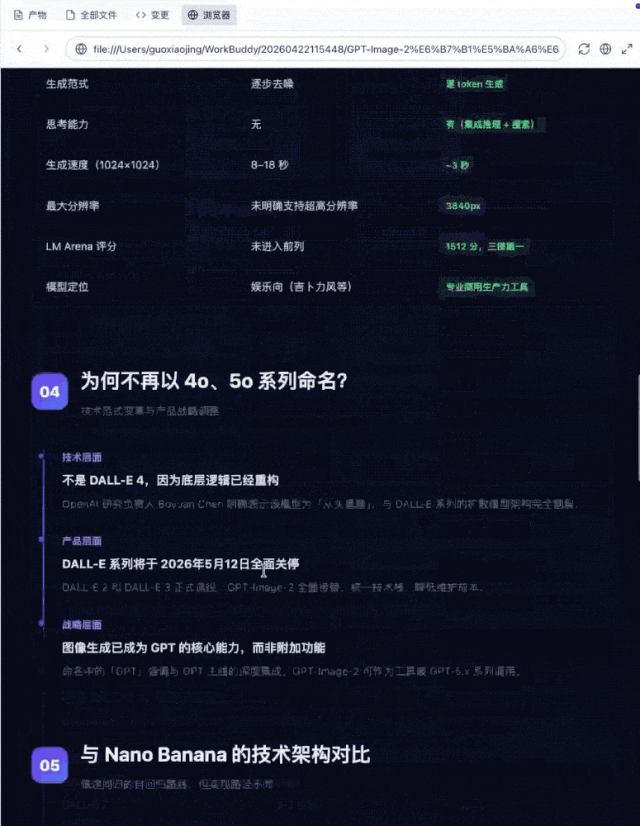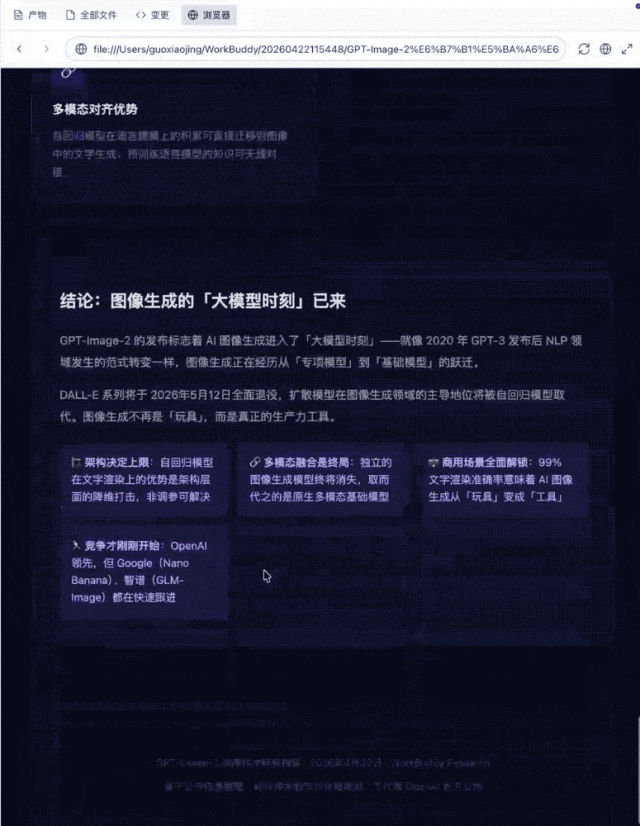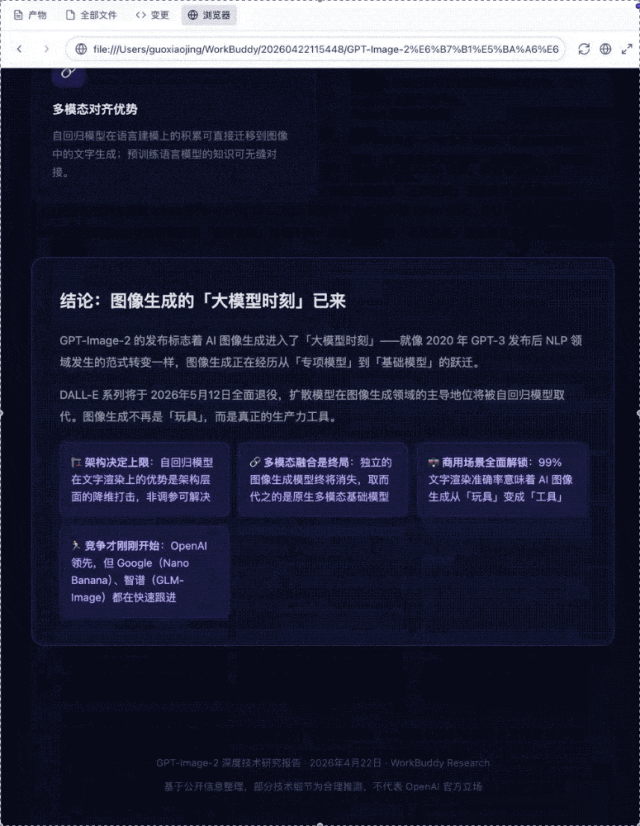
本次任务要求对OpenAI GPT-Image-2进行深度技术研究,涵盖文字渲染原理、技术细节公开情况、版本差异、命名逻辑及竞品对比五个维度。模型首先展现了意图拆解能力,将开放式问题自动拆解为可回答的子问题,无需用户引导;随后调用实时检索能力,多轮搜索并抓取官方及媒体信源;信息整合阶段,模型区分了已公开与未公开信息,对官方未披露的细节明确标注、未做脑补,信息甄别严谨性较好;对比分析方面,主动构建了与前代及竞品的双维度对比;交付阶段生成了HTML可视化版本。
最终的结果对prompt提出的要求都返回了较为清晰的调研结果,唯一短板在于部分信源经重定向后内容提取没有特别完整。竞品对比因公开资料有限相对薄弱一些。整体效果还是很不错的。
我们还测试了另外一个任务:
创建一个单HTML文件的粒子变形动画效果。要求如下:
核心效果:
- 800x800的canvas居中显示,深色背景(#0F0F0F)
- 500个圆形粒子,颜色为亮黄绿色(#C8FC5E),半径3-6px随机,带柔和发光效果(shadowBlur)
- 动画启动时,500个粒子从画布四周随机位置飞入,首先汇聚成第一个图形"I",这是用户看到的第一个画面
- 之后粒子在三个图形之间按固定顺序循环变形:
a. "I"(首个出场)— 一个粗竖条,粒子均匀填充在竖长方形区域内
b. 爱心 ❤️ — 用心形参数方程生成轮廓坐标,粒子均匀分布在轮廓线上
c. "HY" — 两个字母并排,H由两竖一横组成,Y由两斜线加一竖组成,粒子均匀分布在笔画线段上
- 播放顺序严格为:I → ❤️ → HY → I → ❤️ → HY → ... 无限循环,组合起来表达 "I ❤️ HY"
初始入场动画:
- 页面加载后,500个粒子从画布边缘外的随机位置出发,以各自独立的速度和曲线路径飞向"I"的目标位置
- 入场过程持续约1.5秒,粒子依次到达(staggered),营造出粒子从虚空中凝聚成形的感觉
- 入场完成后停留展示3秒,再开始后续循环变形
最终呈现效果如下: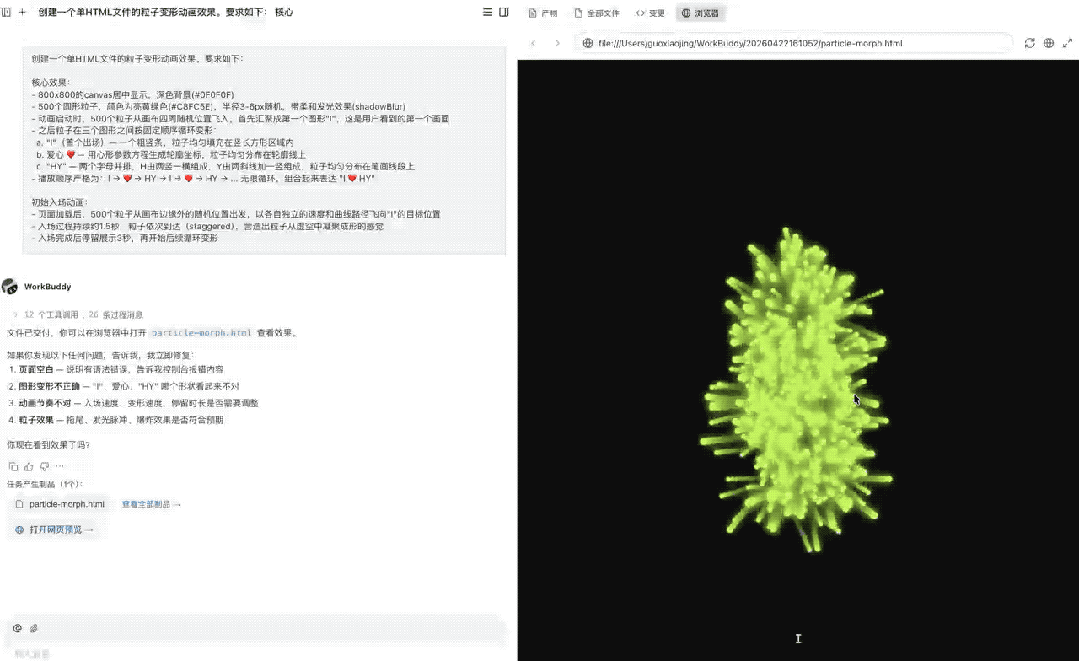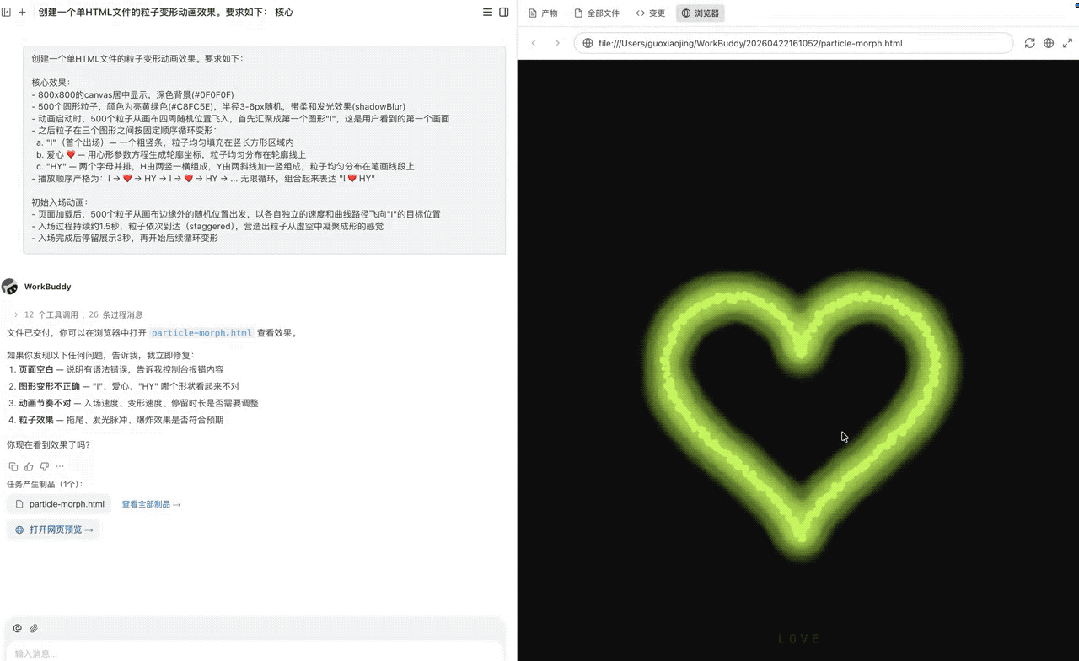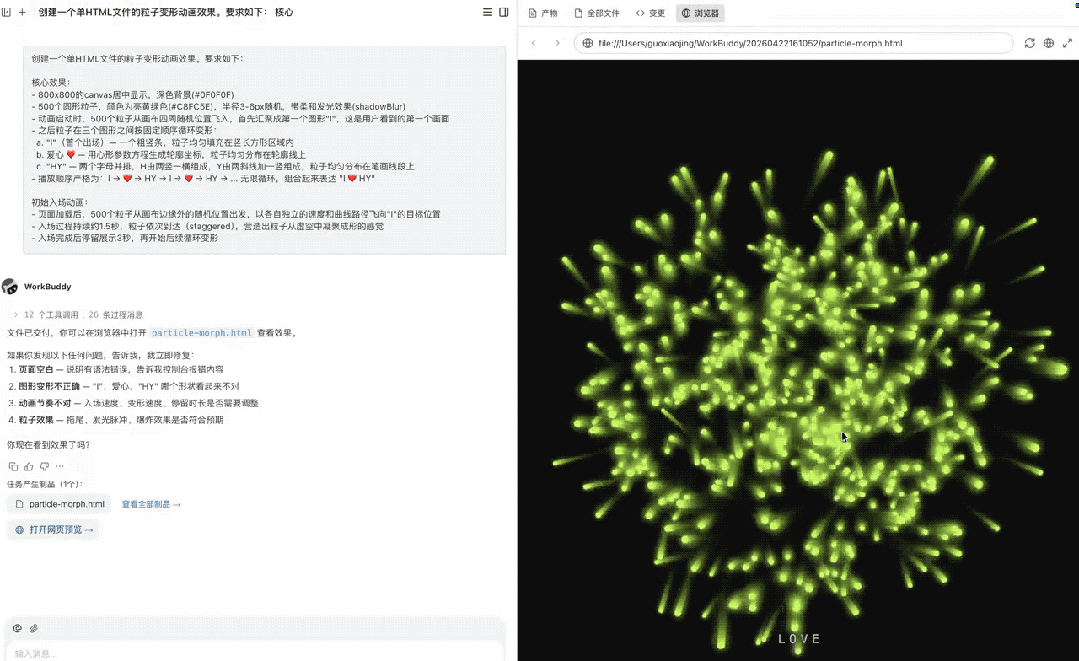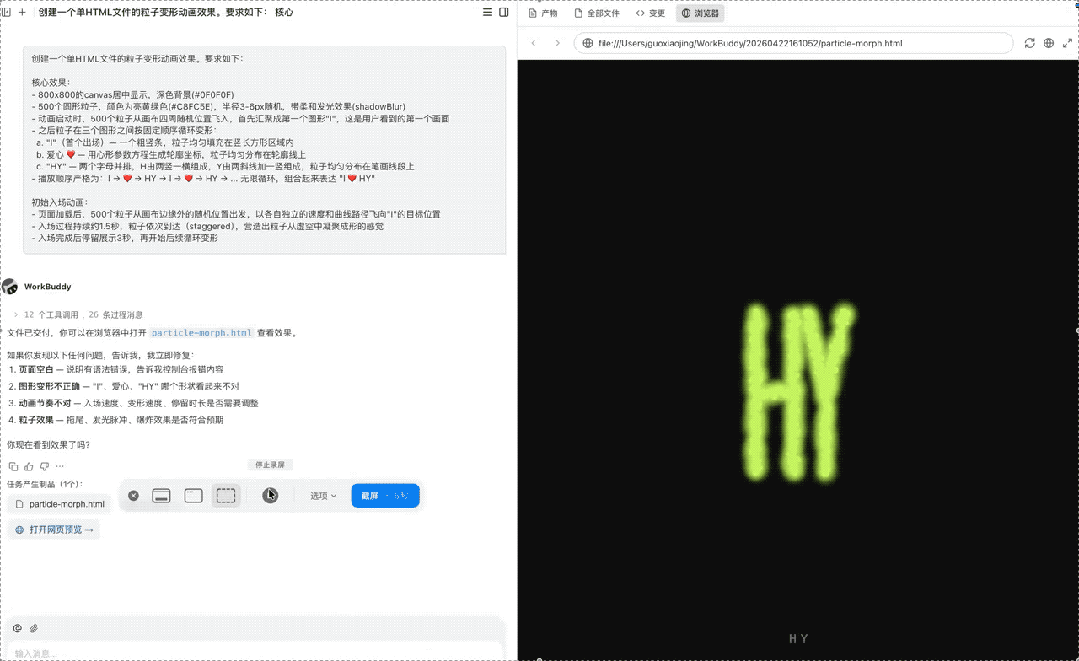
这个任务本质上是在测试模型把复杂创意需求落成可运行前端动画的综合能力,既考验它是否能准确理解并长期保持一长串细节约束,比如单HTML、固定画布尺寸、500个粒子、首屏先出现“I”、再按“I→❤️→HY”无限循环,也考验它能不能把文字描述转成具体的二维几何图形、粒子分布和动画状态机,并处理入场、停留、变形这些时序细节。
最终首屏顺序是对的、三个图形清晰、粒子分布均匀、变形平滑,这是一个综合能力题,说明模型真的具备了比较好的需求理解、空间建模、动画实现和工程收敛能力。
04
AI 是多维度的竞争
适配不同的产品,跑出不同的“模型感觉”,这件事本身比任何单项 benchmark 都更能说明 Hy3 preview 的定位--全面实用性,成为腾讯 AI 产品矩阵中的一个关键齿轮。
但齿轮要发挥作用,“整机”的运转机制更为重要。在 2025 年第四季度财报电话会上,有分析师直接提问:在大模型领域,美国的经验显示后来者很难追上先行者,腾讯凭什么有信心不会持续落后?
腾讯总裁刘炽平的回答并不回避差距:“如果只是在参与一场单一的比赛,那么想要在这场比赛中追赶上来,确实是很困难的。但如果你把 AI 看作是由许多不同‘比赛’构成的集合,那么新的机会和新的前沿领域其实一直在不断出现。整个 AI 世界的发展仍然处于非常早期的阶段。”
他接着点出腾讯的底牌:“这就是为什么具备一些基本能力非常重要,而我们确实有许多这样的能力:比如在应用层的微信,我们的通信生态、在 PC和移动端的布局、以及我们包括安全、云服务和支付在内的基础设施能力。所有这些要素,都可以在新一轮 AI 竞赛中被重新整合。我并不太担心'进入得晚'这件事;我会担心的是我们是否创新得还不够快。”
如何把“底牌”转化为AI落地能力?腾讯集团高级执行副总裁、云与智慧产业事业群 CEO 汤道生在3月举办的腾讯云上海城市峰会上说,AI 落地“不只是一道算法题,更是一道工程题。
企业的核心需求已经不再是拥有最好的模型,而是如何通过系统工程把模型的能力最大程度发挥出来”。这与备受行业关注的 Harness 工程相互印证:在同样的模型能力下,工具调用、分层上下文工程、长记忆管理、工作流设计等脚手架设计,对实际使用效果和 token 成本影响显著。
Hy3 preview 的发布不会立即改变大模型的竞争格局。在海外厂商的前沿模型仍然占据智能上限的背景下,Hy3 preview 的意义更多在于业务验证,验证“不盲目扩大规模 + 深度 Co-Design + 工程化交付”这条路线能否在真实业务中站得住。

推荐阅读

财报会9天后,腾讯亮出“龙虾闪电战”底牌

鹅厂“养龙虾”全攻略

鹅厂工程师讲透“龙虾”真相:“笨”不是“虾”的错





