 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库刚刚!DeepSeek开源高性能GPU算子库TileKernels
几个小时前,DeepSeek开源了一个新项目——TileKernels。
一个高性能GPU算子库,基于TileLang构建,一共包含44个生产级GPU算子,覆盖MoE路由、FP8量化、Engram条件记忆、Manifold HyperConnection多个模块。MIT协议。
TileKernels的repo地址:
https://github.com/deepseek-ai/TileKernels
DeepSeek 这几天 GitHub 上的动静,已经不是活跃两个字能概括了。
几小时前,DeepEP(MoE专家并行通信库))也放出了 EPv2 的预告。
https://github.com/deepseek-ai/DeepEP/pull/605
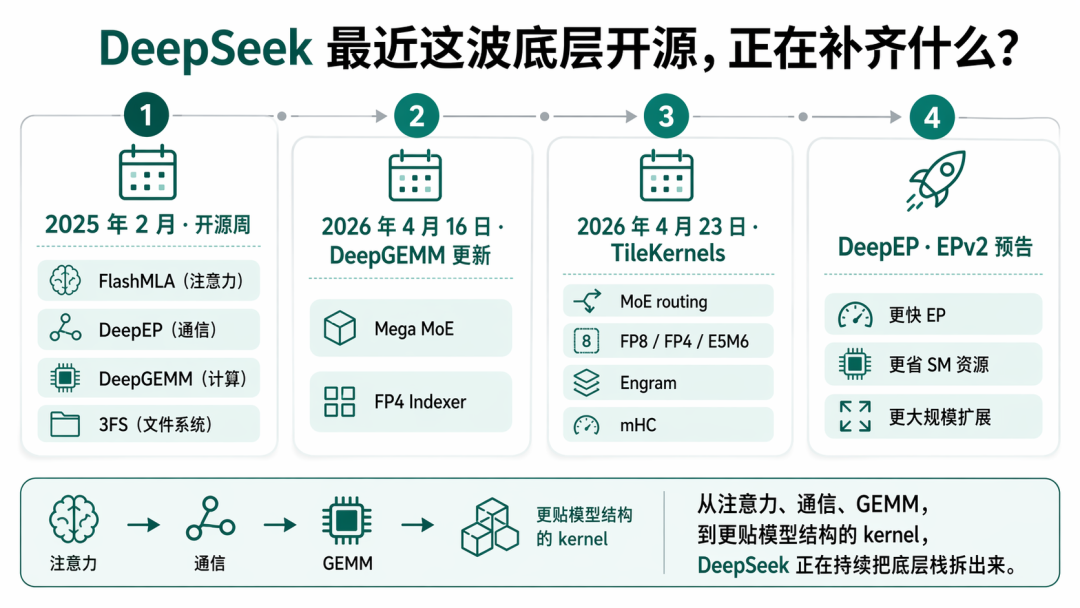
再往前倒几天,还更新过 DeepGEMM (GPU矩阵乘法库),FlashMLA(高效MLA注意力算子)。这几个项目都是去年开源周放出来的LLM基建库,属于通用基础设施,是所有大模型都需要的通用组件。
不同于之前,这次新开源的 TileKernels 定位在架构算子这一层,补足模型结构和 GPU 执行之间那层关键的连接件。
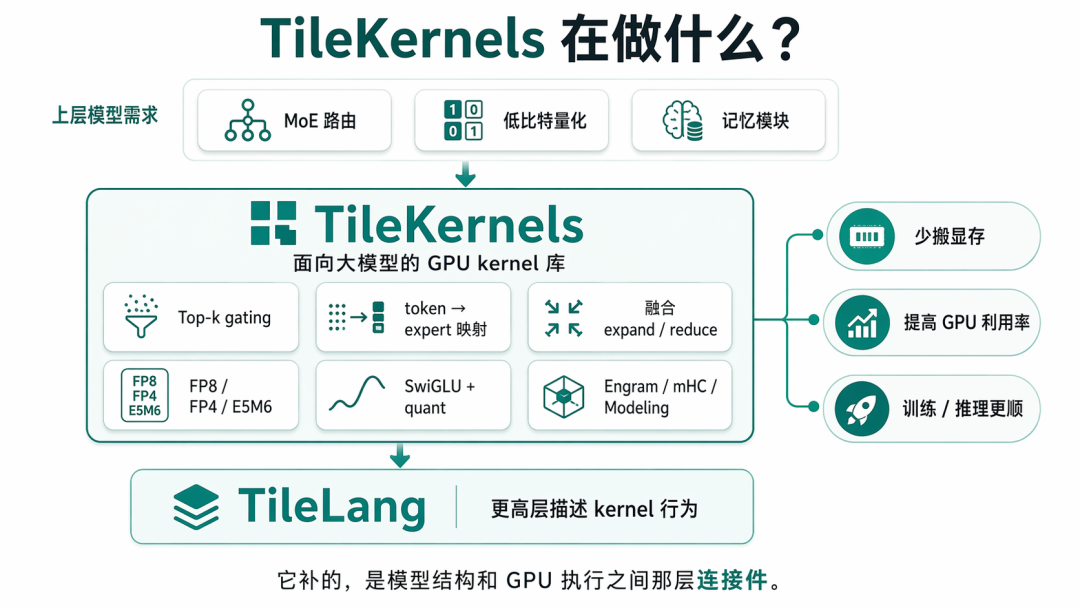
TileKernels开源的是:MoE路由、FP8量化、Engram条件记忆、Manifold HyperConnection。Engram和mHC之前只有论文,这次开源了算子代码。
5个模块,44个算子:
1、 moe/(14个算子)—— MoE路由全流程
DeepSeek V3 用256个专家、每个token只激活8个。路由开销是性能瓶颈。这14个算子覆盖了路由全流程:top-k门控、专家评分、token-to-expert映射、融合expand/reduce、张量并行mask、负载均衡loss计算。
2、 quant/(15个算子)—— 量化与融合激活
实现DeepSeek首创的FP8混合精度训练策略,DeepSeek在V3就开始用FP8混合精度训练了。TileKernels把量化相关的算子全放出来了,三种粒度都有:per-token、per-block、per-channel。包含一个叫E5M6的自定义浮点格式,专门门给注意力梯度设计的:FP8精度不够会影响训练稳定性,FP16又太浪费显存,E5M6卡在中间。
最值得看的是几个三重融合算子,SwiGLU激活 + FP8量化 + 矩阵转置,一次pass做完。正常分三步做需要三次显存读写,融合之后只要一次。对于MLP层来说,这是实打实的训练加速。
3、engram/(5个算子)—— 条件记忆
Engram是DeepSeek今年1月发的论文,提出了一个新思路:在MoE的条件计算之外,再加一个条件记忆维度。
论文里只有架构描述,现在TileKernels放出了门控算子(融合RMSNorm + signed-sqrt激活)、多头哈希寻址、权重融合和梯度聚合的完整实现。这是Engram第一次有生产级的kernel代码公开。
4、mhc/(10个算子)—— Manifold HyperConnection
同样,这次也是mHC第一次kernel级的开源实现。解决的是一个深层模型的老问题:残差连接导致的信号放大。mHC的做法是用Sinkhorn-Knopp算法把混合矩阵约束到Birkhoff多面体上,训练开销只增加6.7%,但换来的是更稳定的深层训练。
5、transpose/(1个算子)—— 批量转置
量化过程中行主序/列主序转换的基础操作,简单但必要。
一共44个生产及GPU算子,没有一行CUDA C++,全部用TileLang编写——北大团队开发的Python GPU DSL,基于TVM编译器。
DeepSeek从V3.2开始就在用TileLang,TileLang的定位是在Triton和手写CUDA之间找一个平衡点:比Triton控制力更强,比手写CUDA效率高很多。
选TileLang还有一个不容忽视的原因:硬件可移植性。TileLang后端支持NVIDIA、AMD MI300X和华为Ascend。如果未来需要在非NVIDIA硬件上跑这些算子,TileLang的代码不用重写。
硬件要求是:SM90(Hopper:H100/H800)或SM100(Blackwell:B100/B200),CUDA 13.1+。不支持消费级显卡(RTX 4090是SM89,不够)。
再看 DeepEP,在去年2 月的开源周里,DeepSeek 就已经把 DeepEP 定义成面向 MoE 训练和推理的 EP 通信库,强调高吞吐 all-to-all、低延迟 kernel、NVLink 和 RDMA 支持、以及原生 FP8 dispatch。
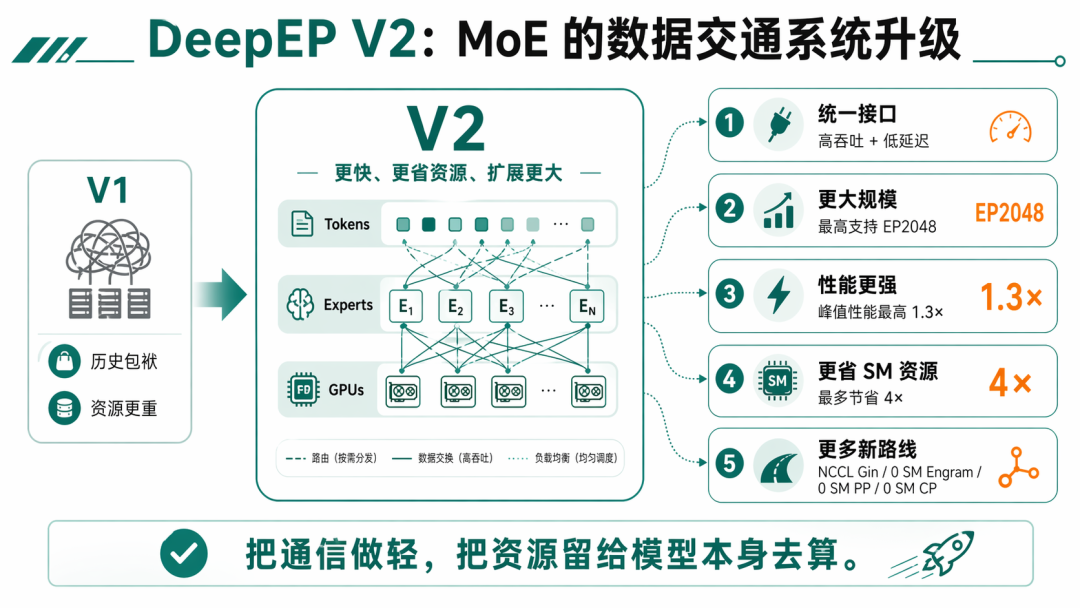
这次 EPv2,DeepSeek 重做了这部分,让它能跑得更快、更省资源、还能支撑更大的扩展规模。
按照 PR 里的说法,V1 已经积累了不少历史包袱和性能问题,所以这次 V2 做了完整重构。官方原话是:V2 相比 V1,最高可以做到 1.3 倍峰值性能,同时最多节省 4 倍 SM 资源占用。
这里面最关键的几个优化点,其实可以压成 3 句:
第一,它把高吞吐和低延迟 API 合成了一个统一接口。过去不同场景下分开的调用方式,现在被收拢了,工程上更整。
第二,它支持更大的扩展规模。PR 里直接写到,新的版本最高支持到 EP2048。
第三,它更省 GPU 资源了。对于类似 DeepSeek-V3 的旧训练任务,SM(敏捷专家)占用可以从 24 个降到 4 到 6 个,同时性能还不掉,甚至更好。
而且这次 V2 里还有几个很有 DeepSeek 风格的点。
比如它把后端从 NVSHMEM 切到了更轻的 NCCL Gin,比如它开始尝试 0 SM 这类极端节省资源的路线,比如它想减少对自动调优的依赖,往更好维护的方向走...
这些东西平时不太上热搜,但特别值钱。
因为模型归模型,真正决定它能不能大规模跑起来的就是下面这套东西。DeepSeek 最近这几次更新,放出来的,就是这一层。
DeepSeek 正在持续把自己内部的大模型底层栈拆出来。
昨天The Information 报道,DeepSeek 的估值可能超过 200 亿美元,但还在谈判,数字可能会变。才不到一天,小道消息传出来的估值就到了 3000 亿人民币。
现在大家再看 DeepSeek,真不能只看 v4 新模型了。







