 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库GPT-5.5 发布,详细解读
OpenAI Release
凌晨,OpenAI 发布 GPT-5.5,是 GPT-5 系列迄今最大更新
下面这个,是介绍视频
https://openai.com/index/introducing-gpt-5-5/
本次核心变化:用更少的 token,干更难的活
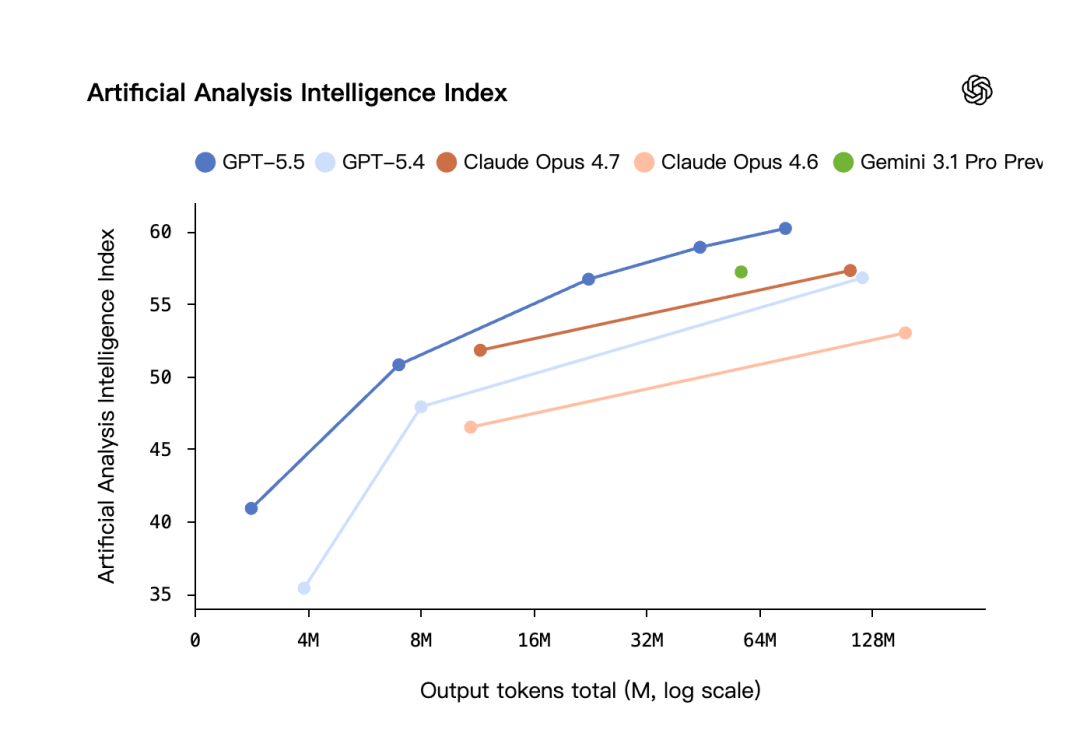
在 Artificial Analysis 的 Coding Agent Index 上,GPT-5.5 达到了最高智能水平,成本是同级别竞品的一半
GPT-5.5 这个模型,目前已向 ChatGPT 付费用户开放
更高级别的 GPT-5.5 Pro,则向 Pro、Business、Enterprise 用户开放
API 即将上线,价格大幅上涨,为 $5/$30 (每百万Token),比 5.4 翻了 3 倍

能力总览
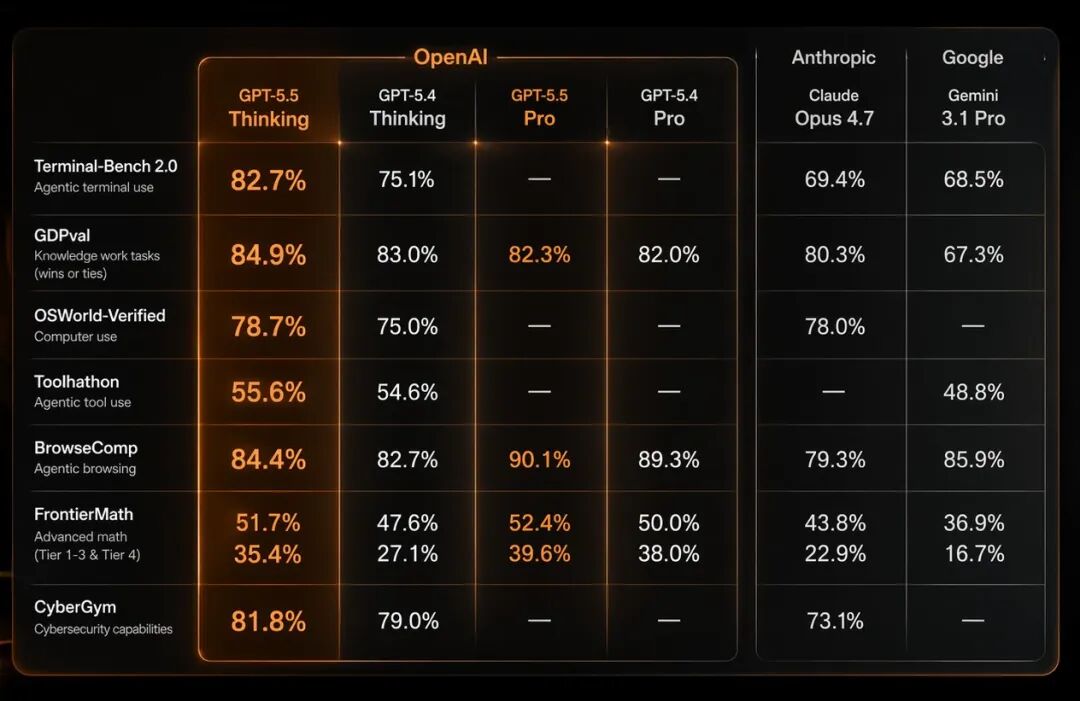
OpenAI 拿出了一张 9 项核心指标的对比表,横向对比 GPT-5.5、GPT-5.4、GPT-5.5 Pro、GPT-5.4 Pro、Claude Opus 4.7 和 Gemini 3.1 Pro
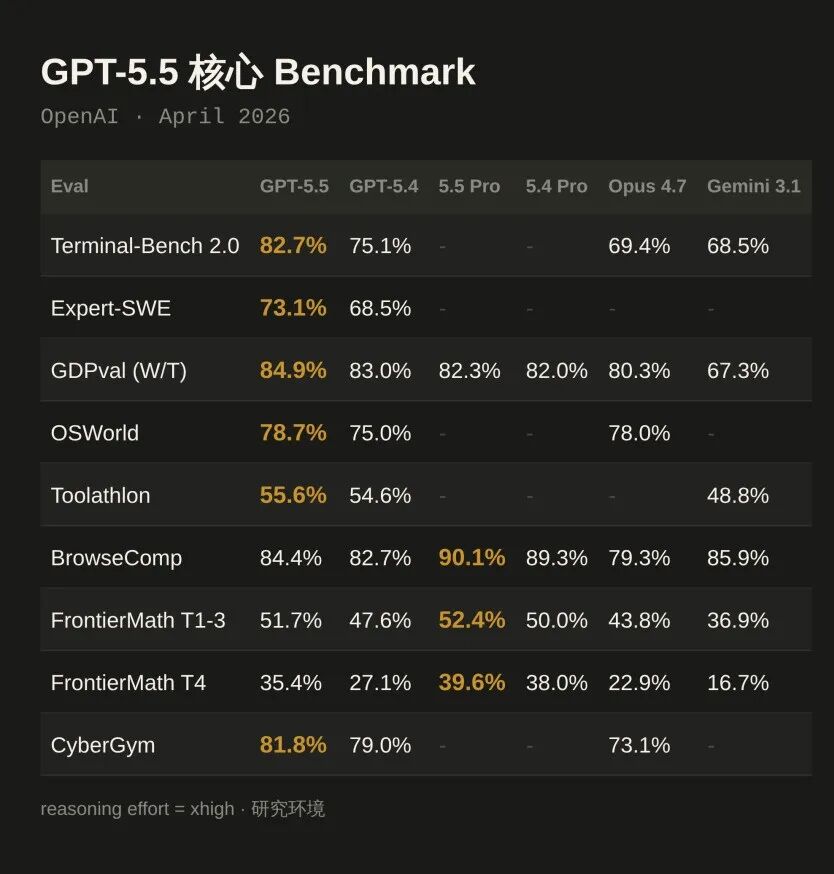
核心 Benchmark 总览
在 Artificial Analysis Intelligence Index(第三方,10 项 eval 加权平均)上,GPT-5.5 在同等输出 token 量下智能得分最高,token 总消耗明显低于其他模型
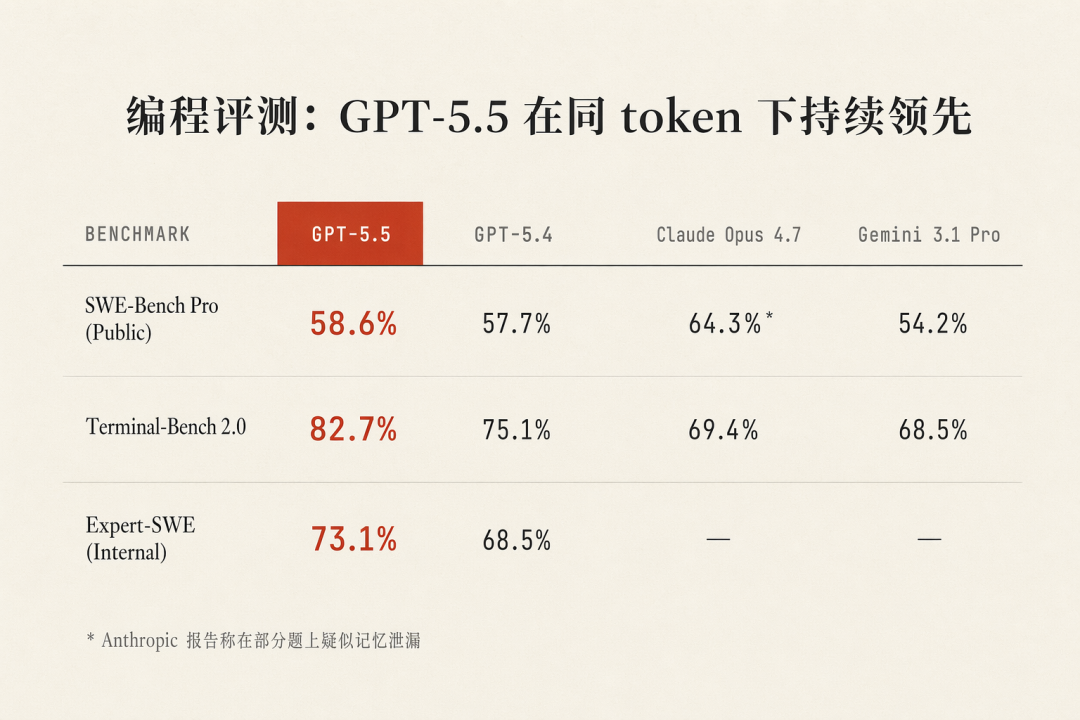
Terminal-Bench 2.0复杂命令行工作流:82.7%,vs GPT-5.4 的 75.1%,vs Claude Opus 4.7 的 69.4%
SWE-Bench Pro真实 GitHub issue 解决:58.6%,vs GPT-5.4 的 57.7%。Claude Opus 4.7 报了 64.3%,但 Anthropic 承认部分问题存在记忆化
Expert-SWE内部长周期编码任务,中位人类完成时间 20 小时:73.1%,vs GPT-5.4 的 68.5%
在 Codex 里,GPT-5.5 可以接手从实现、重构到调试、测试的完整工程工作。上下文窗口 400K
知识工作
coding 之外,GPT-5.5 在日常电脑操作和知识工作上的提升同样明显
GDPval44 个职业知识工作测试,胜出或平手率 84.9%,vs GPT-5.4 的 83.0%,vs Claude Opus 4.7 的 80.3%
OSWorld-Verified模型独立操作真实电脑环境:78.7%,vs GPT-5.4 的 75.0%
Tau2-bench Telecom复杂客服工作流,无 prompt 调优:98.0%,vs GPT-5.4 的 92.8%
GPT-5.5 Pro 也有提升。早期测试者觉得 GPT-5.5 Pro 在业务、法律、教育、数据科学方向上比 GPT-5.4 Pro 更全面、更准确

财务建模 demo,手动替换:https://player.vimeo.com/video/1185616826
OpenAI 内部用例
OpenAI 公司超过 85% 的员工每周都在用 Codex,覆盖工程、财务、市场、公关、数据科学、产品管理
公关团队分析了 6 个月的演讲邀请数据,建了打分和风险框架,低风险请求自动处理,高风险请求交人审核
财务团队审了 24,771 份 K-1 税表,共 71,637 页,比去年提前两周完成
GTM 团队自动生成周报,每周省 5-10 小时
科学研究
GeneBench 是 OpenAI 新推出的 eval,测试多阶段遗传学和定量生物学数据分析。这些任务通常对应科研专家几天到几周的工作量。GPT-5.5 得分 25.0%,GPT-5.4 是 19.0%,GPT-5.5 Pro 达到 33.2%
BixBench(真实生物信息学和数据分析 benchmark):GPT-5.5 得分 80.5%,GPT-5.4 是 74.0%
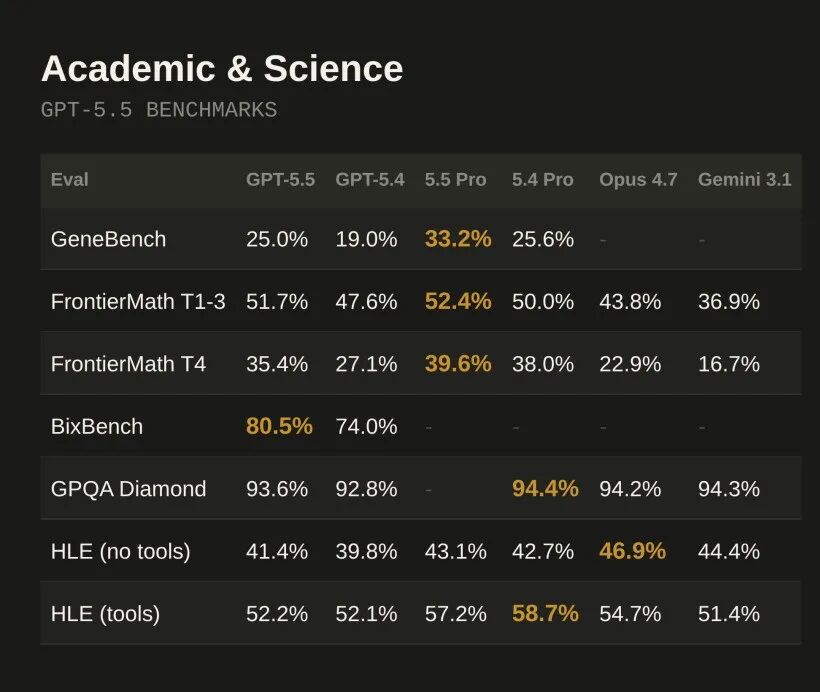
Academic 评测数据
Ramsey 数新证明
GPT-5.5 的内部版本配合自定义工具链,发现了关于 Ramsey 数的一个新证明。Ramsey 数是组合数学的核心对象,研究结果稀少且技术难度高。这个证明后来在 Lean 中完成了形式化验证

推理效率
GPT-5.5 更大更强,但实际延迟和 GPT-5.4 一样
此前,OpenAI 用固定数量的静态分区来平衡 GPU 上的计算负载
而在新版本中,Codex 分析了数周的生产流量数据,写了自定义的启发式分区算法。这一项改进让 token 生成速度提升了超过 20%

模型帮忙优化了自己运行的基础设施
网络安全
GPT-5.5 的网络安全能力被 OpenAI Preparedness Framework 评为 High(生物/化学能力同为 High)。没有达到 Critical 级别
CyberGym81.8%,vs GPT-5.4 的 79.0%,vs Claude Opus 4.7 的 73.1%
CTF 挑战任务内部扩展版:88.1%,vs GPT-5.4 的 83.7%
与此同时,GPT-5.5 也发布同时推出了一个新项目:生物安全漏洞赏金

规则是这样,OpenAI 准备了 5 个生物安全问题,参与者需要找到一条「通用越狱 prompt」,在 Codex Desktop 的干净对话里,一次性通过全部 5 个问题,且不触发审核,就算越狱成功
参与地址在这:https://openai.com/index/gpt-5-5-bio-bug-bounty/
第一个成功的通用越狱,奖金 $25,000。部分突破可能获得较小奖励
申请窗口2026 年 4 月 23 日开放,6 月 22 日截止,滚动审核
测试窗口2026 年 4 月 28 日至 7 月 27 日
准入条件需要现有 ChatGPT 账号,签署 NDA
保密要求所有 prompt、输出和发现均受保密协议覆盖
面向有 AI 红队、安全或生物安全经验的研究者
可用性与定价
ChatGPT
GPT-5.5 Thinking 面向 Plus、Pro、Business、Enterprise 用户。GPT-5.5 Pro 面向 Pro、Business、Enterprise 用户
Codex
GPT-5.5 面向 Plus、Pro、Business、Enterprise、Edu、Go 计划,400K 上下文窗口。Fast 模式 token 生成速度提升 1.5 倍,成本 2.5 倍
API(即将上线)
gpt-5.5$5/1M input tokens,$30/1M output tokens,1M 上下文窗口
gpt-5.5-pro$30/1M input tokens,$180/1M output tokens
Batch / Flex标准价的一半
Priority标准价的 2.5 倍
GPT-5.5 单价比 GPT-5.4 高,但 token 效率也更高
OpenAI 表示在 Codex 里,GPT-5.5 对大多数用户来说,实际消耗的 token 比 GPT-5.4 更少
完整 Benchmark 数据
以下是 OpenAI 公布的全部评测数据,按类别整理。所有 GPT 评测在 reasoning effort 设为 xhigh 的研究环境中进行
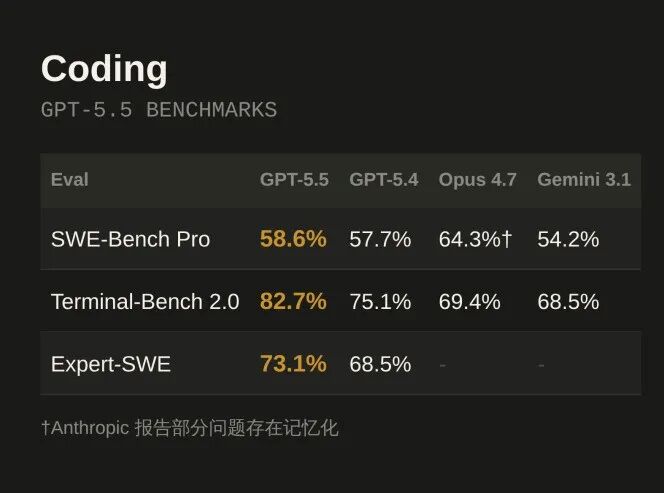
Coding 评测表
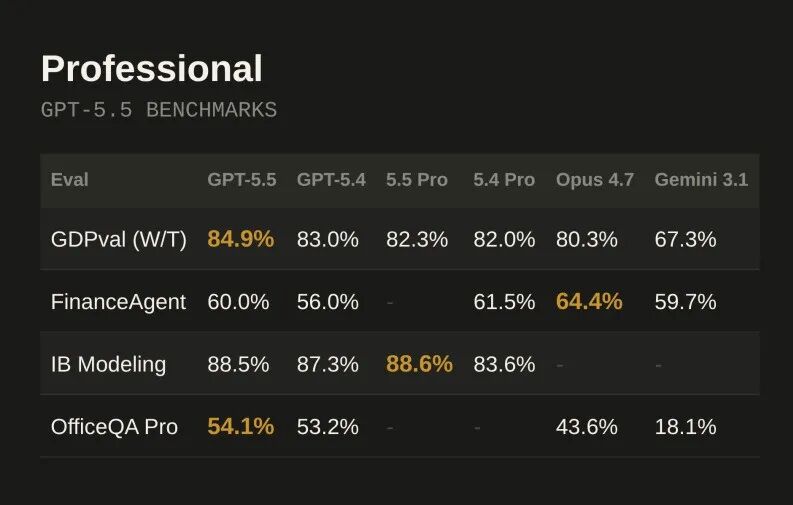
Professional 评测表
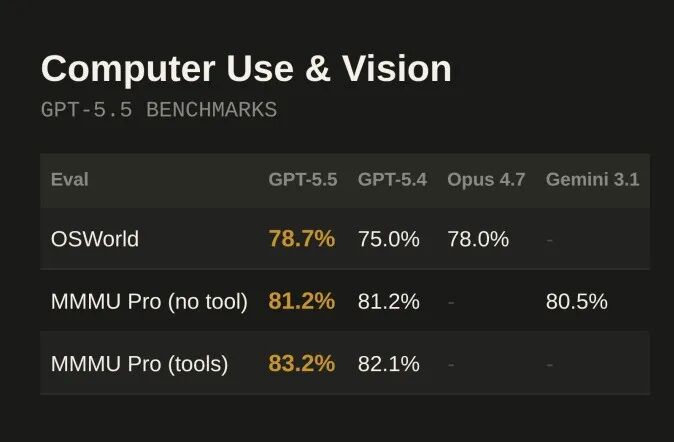
Computer Use and Vision 评测表
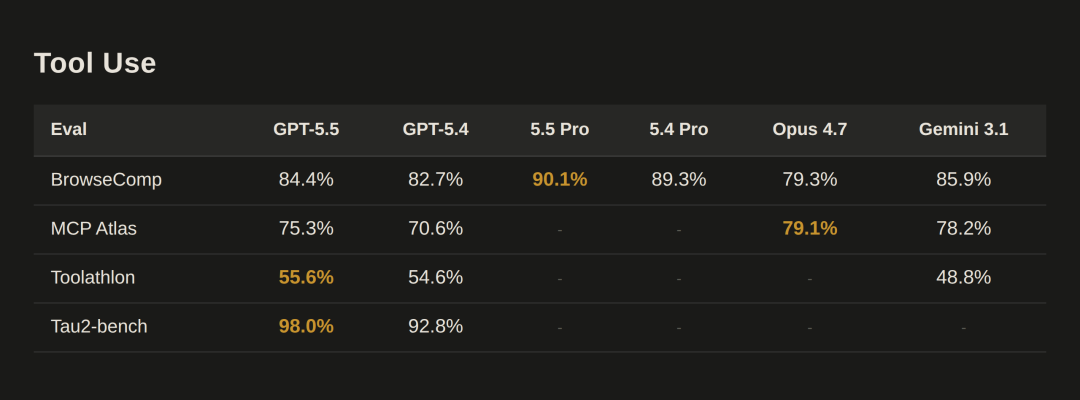
Tool Use 评测表
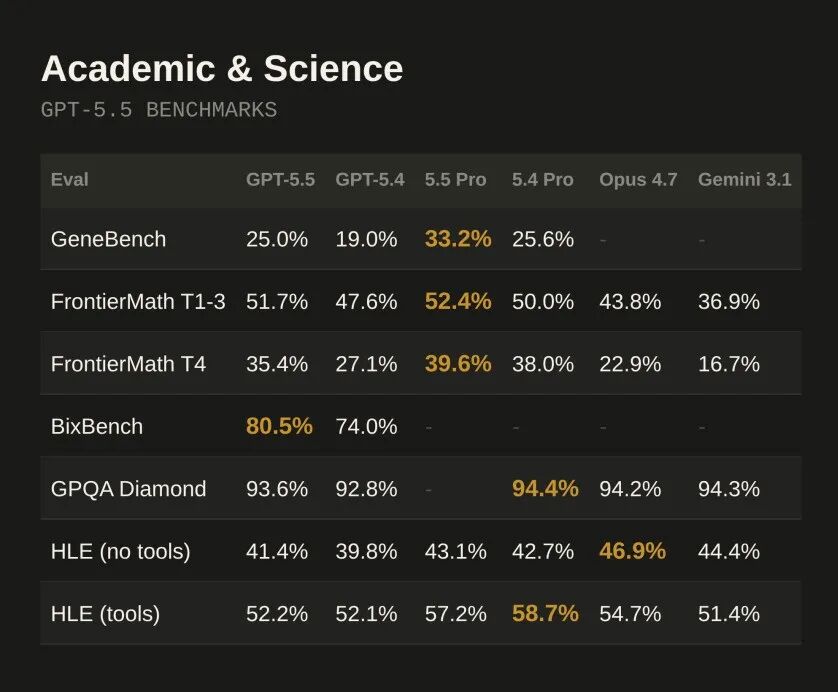
Academic 评测表
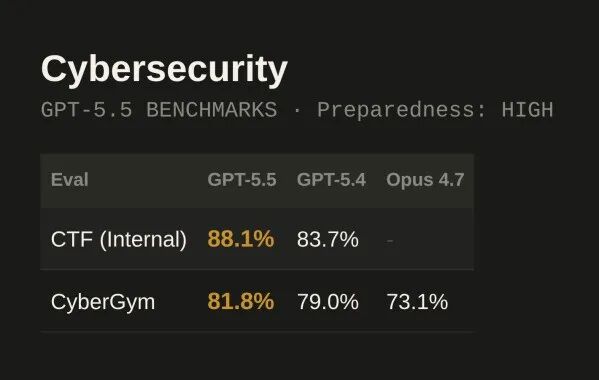
Cybersecurity 评测表
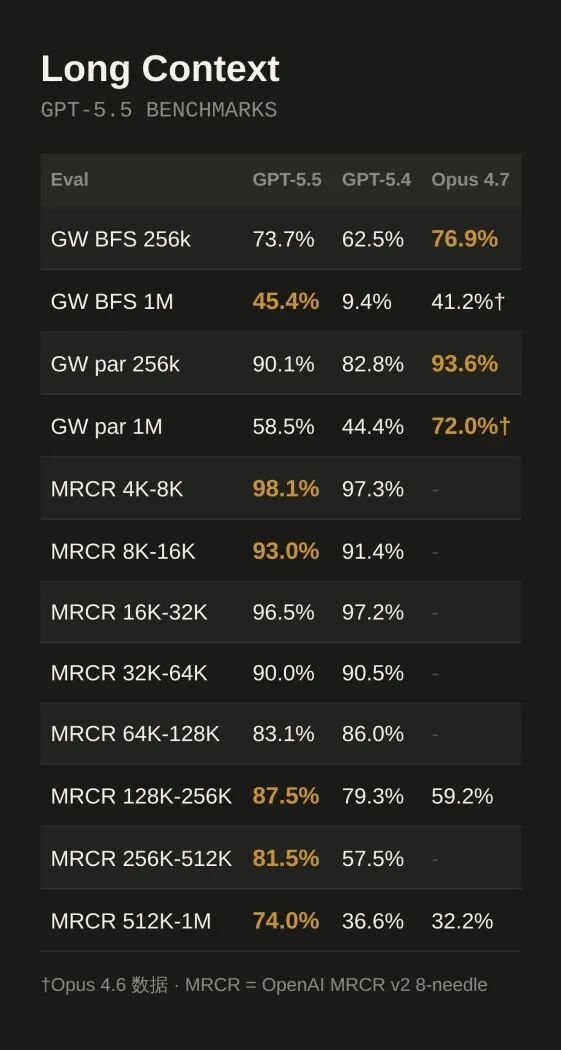
Long Context 评测表
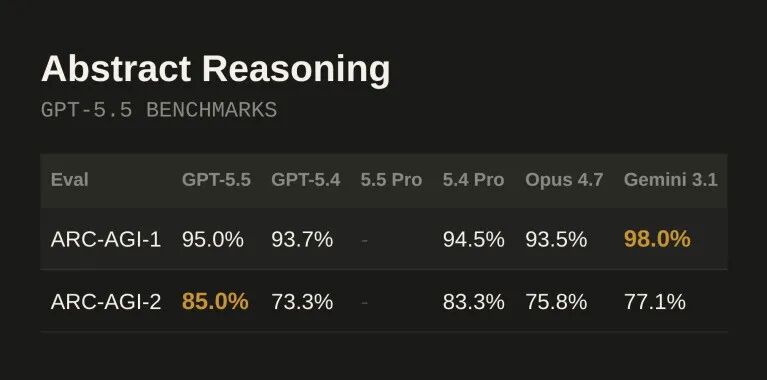
Abstract Reasoning 评测表
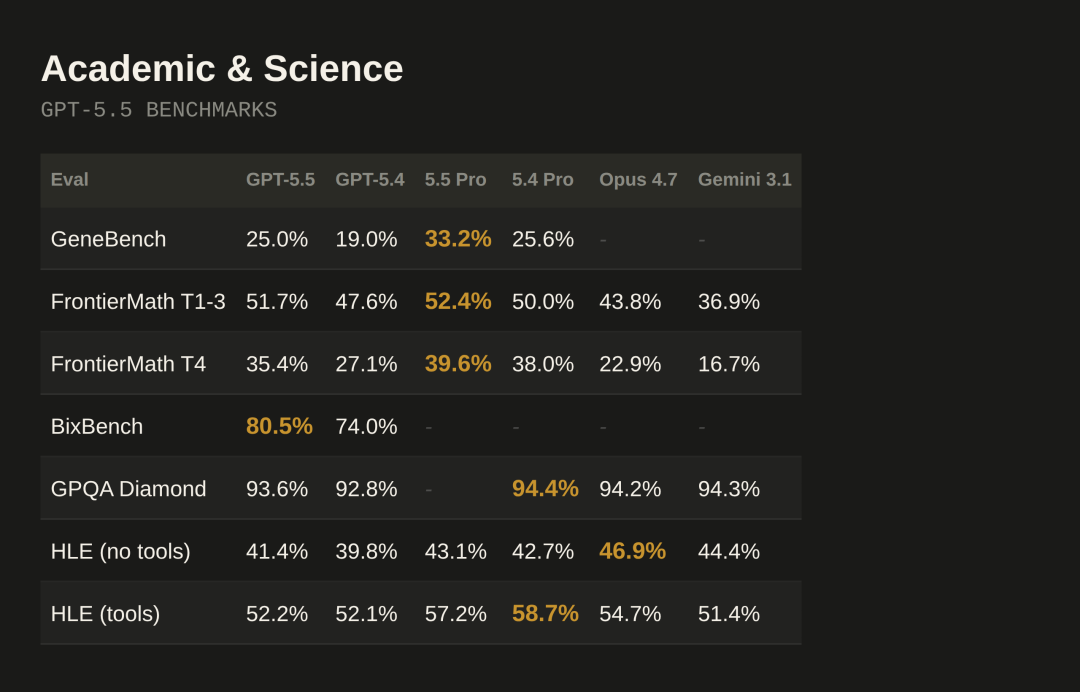
Abstract Reasoning 评测表
短板
SWE-Bench Pro 上 Claude Opus 4.7 报了 64.3%(GPT-5.5 是 58.6%),但 Anthropic 承认部分问题存在记忆化
MCP Atlas 上 Claude Opus 4.7(79.1%)和 Gemini 3.1 Pro(78.2%)均高于 GPT-5.5(75.3%)
Humanity's Last Exam(带工具)上 GPT-5.4 Pro 的 58.7% 高于 GPT-5.5 Pro 的 57.2%
长上下文 256K 以上,Claude Opus 4.7 在部分指标上仍有优势
参考材料
→ 官方博客:openai.com/index/introducing-gpt-5-5/
→ System Card:deploymentsafety.openai.com/gpt-5-5
→ Bio Bug Bounty 申请:https://openai.com/index/gpt-5-5-bio-bug-bounty/
→ BixBench 论文:arxiv.org/abs/2503.00096
→ Artificial Analysis 方法论:artificialanalysis.ai/methodology/intelligence-benchmarking
→ API 定价:openai.com/api/pricing/





