 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库让代码数了数女儿脑袋里的英语单词
故事是这样的。
周日晚上 7 点,我女儿 lgg,小学一年级,坐在沙发上。
iPad 里放的是 Bluey 布鲁伊,一部澳大利亚学前动画片。
第一集放完,她转过头,激动的跟我说,
freeze
我配合她演布鲁伊第一集里的情节,听到她说 freeze 我就假装被定住了。
说实话,我没吃惊。
因为三天前,我就已经用代码算出来她会看得懂。
单词覆盖率 90.3% 评级 💚 简单,可以泛听放松看。
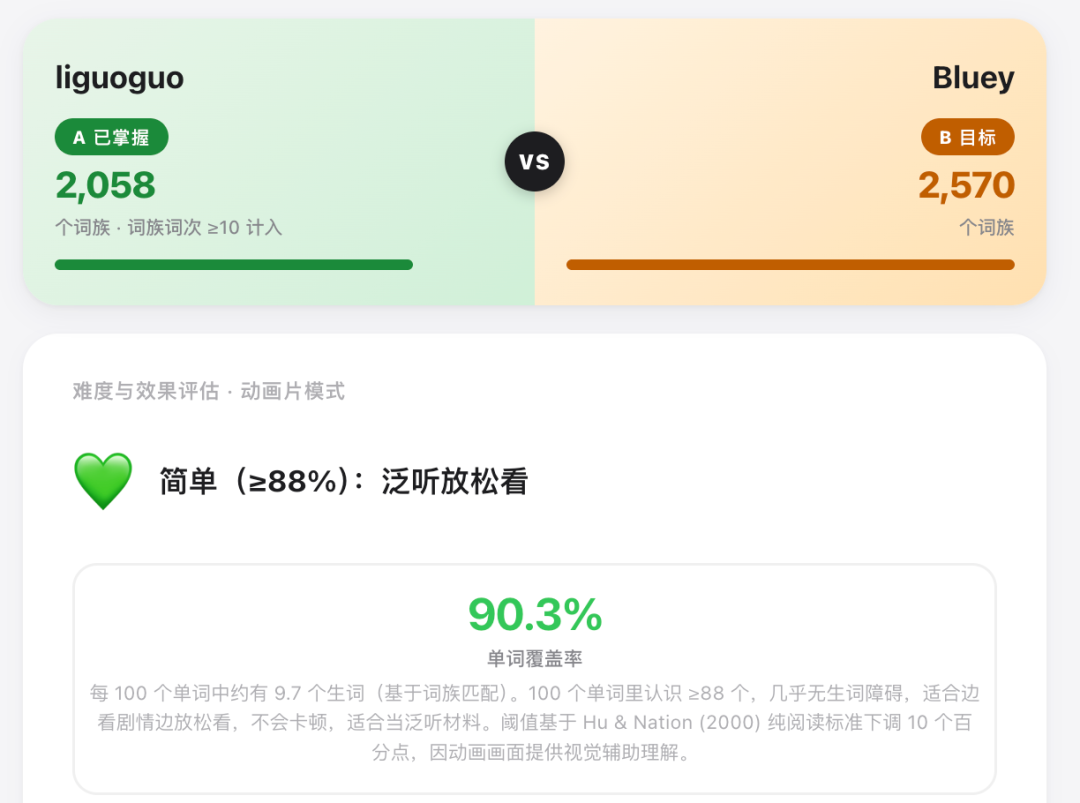
她点开这一集的时候,我心里是有把握的。
就像一个赌徒翻牌前,已经偷看过底牌。
但真听到她从沙发上转过头来,亲口说出那句「freeze」的时候。
我还是愣了一下。
不是愣她听懂了。
是愣在一个三天前跑在我电脑屏幕上、冷冰冰的 90.3%,今天居然从我亲生女儿嘴里,变成了一句活人话。
数字变成了血肉。
这得,容我从头讲起。
你想想看,我们这一辈人学英语,从初一开始,抱着课本背单词,抄课文,做阅读理解。听力是附加题,口语基本没练过。
但按语言习得理论,像母语者一样学英语,正确顺序是听、说、读、写。
你学中文也是这么来的。小时候你妈跟你说「开门」,同一秒,你眼睛看到她的手按在门把手上、耳朵听到咔嗒一声、门哗的一下开了。
音、画、动作,三个信号在同一秒打到你脑子里。
这个东西叫音画对应。母语就是这么习得的。
所以学中文,先听,再会说,再会读,再会写。这是自然顺序。
而我们学英语,大多数人是直接从读写开始的。
我跟你说,这是真的搞反了。
搞反的这套方法,在 AI 到来之前,其实也能勉强挺着用。毕竟大家都这么学,高考也这么考。
但 AI 一来,情况立刻变了。
我查了一下数据,还挺扎眼的。
2018 到 2022 这五年,全国至少有 101 所本科院校撤销了外语类专业,其中英语 20 所。
表面看是「英语不重要了」。但你往深里想一层,是反过来。
英语不再是一个独立专业,而是默认你就应该会。
就像三十年前,会开车是本事,得写在简历上。现在呢?你简历上写「会开车」,HR 只会当你脑子有病。
高考也在往这个方向调整。上海从 2025 年开始改英语考试,听说分值从 10 分一下涨到 35 分,听说占比从 6.7% 一下干到了 23.3%。
这一调整一下子把问题,推回给每一个家长。
你要你家小孩像母语者一样先「听」,可她没有母语环境。
英语不是你家里说的语言。你跟她说 open the door,她只能看到你嘴在动,门那边什么都没发生。
没有音画对应。没有现实反馈。
想来想去,对普通家庭来说,能做到音画对应的、唯一可行的路子,只有一条。
看动画片。
小猪佩奇说 I'm going to jump in a muddy puddle 的时候,画面里她真的在跳泥坑。
音和画,在同一秒对上了。
好,动画片有了。
但第二个问题立马来了。
看哪部?
最开始那阶段最痛苦的事不是孩子坐不住,是你不知道该给她放什么。
只能靠问。
家长群、各路英语启蒙博主。有人说《Wow English》好,你跟着看《Wow English》,有人说《小猪佩奇》好,你跟着看《小猪佩奇》。
但看了几部之后问题又升级了。
她喜不喜欢看,这个好判断。小朋友对不喜欢的东西根本坐不住。她自己愿意挨到片尾,基本就是喜欢。
难的是下一层。
能看懂吗?能看懂多少?
这个问题我死活得不到答案。
我之前也用豆包问过。我说「我女儿一年级,看过Wow English,你觉得她看 Peppa Pig 能看懂吗?」
豆包说,Peppa Pig 难度比 Wow English 更低 ……
真的吗?
笑死,我就把豆包关了。
没人能告诉我,那就让代码告诉我。
我用 Claude Code 写了一个词频分析工具。
思路很朴素。
把她这一年看过的所有动画片的英文台词本全收集起来,喂给代码。Wow English、卡由、小猪佩奇 1-6 季、Bluey 布鲁伊、托普西、BBC 的 Do you know、牛津 1-9 阶绘本。
连她平时自己开口说英语的录音也全转写成文本丢进去。
让代码统计,每一个英文单词出现过多少次。

阈值我定的是 10 次。一个词如果在她接触过的内容里出现 10 次以上,我就默认她听懂了。
我得打断一下在这里。
我非常理解那些「AI 就是对话框」的朋友,打几个字,出来一段回答,这就是你对 AI 的全部想象。
这种用法没错。大多数日常场景,这样就够了。
给孩子挑动画这件事,就需要用好 AI,它天生需要一个具体的数字答案。
她能听懂多少?
这部比上一部多多少个新词?
她现在卡在哪一档?
对话框回答不了这些问题。
需要代码。
结果跑出来,那天我又愣了一次。
屏幕上先蹦出来一个数字。
315,834
这么多?
31 万 5 千多个单词,这是她一年来接触到的总词量。
听着挺唬人对吧。
但等等。
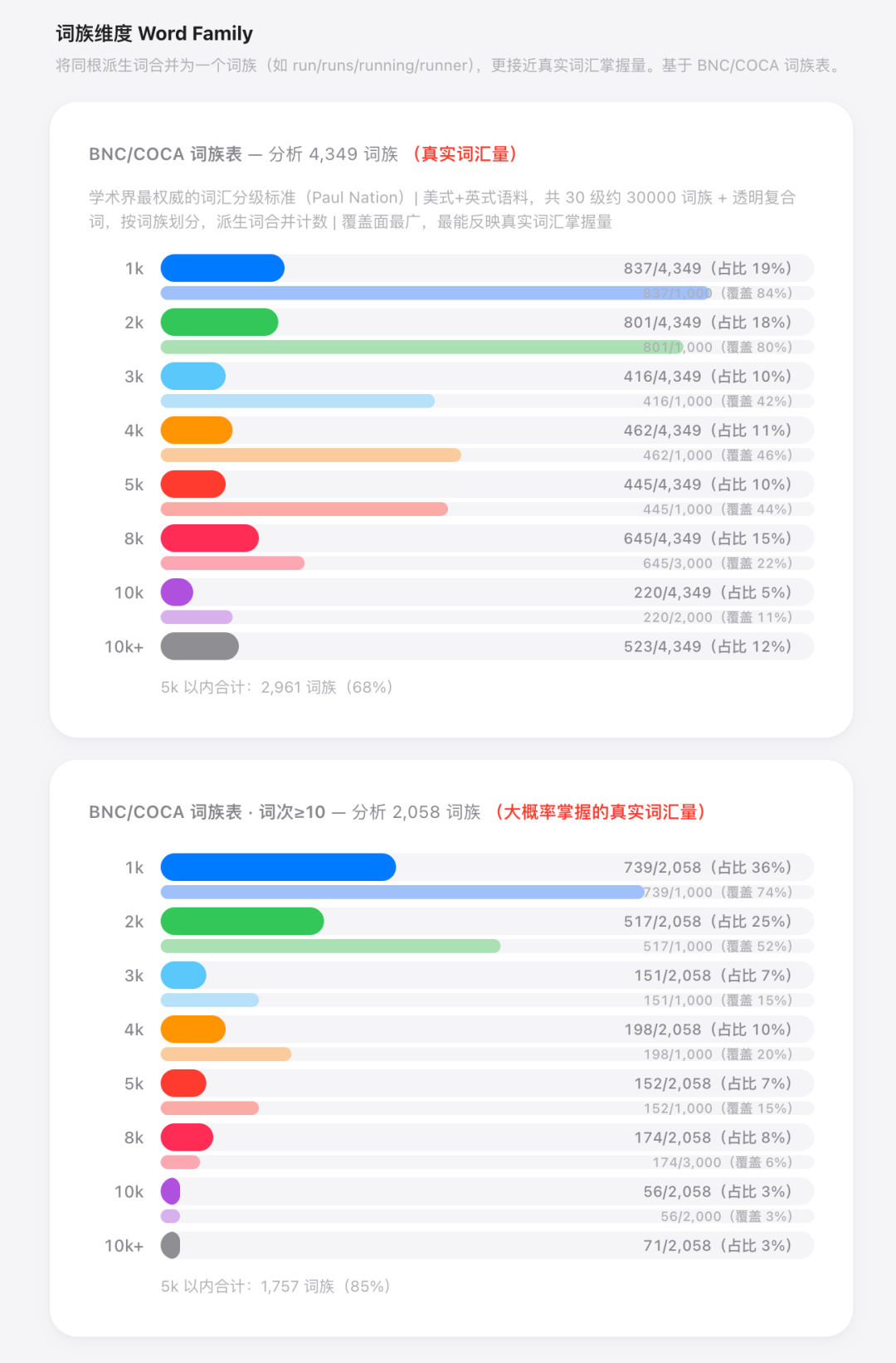
这 31 万里,去掉所有重复的词,词原形只有 5,509 个。
可即便是这5,509,也不能算她「真会的词」。里面有的词一共只出现过 1-2 次,根本不可能听得懂。
真正能算「她能听懂的」,得是出现次数足够多的那批。
这个阈值怎么定我也不懂。现查。
查到 Paul Nation。惠灵顿维多利亚大学的语言学家,词频学界的奠基人。他给的学术标准就是 ≥10 次,可以视作有效习得。
按这个口径再算一遍。
lgg 真正掌握的,是 2,058 个词族。
不是 31 万。
不是 5,509。
是 2,058。
为了让这个 2,058 更准,我后来又让 Claude Code 把全世界主流的词族表一套一套集成进来。
启动这个项目之前,我跟你交代一个真实情况。
这些词族表,我之前是一个都没听说过。
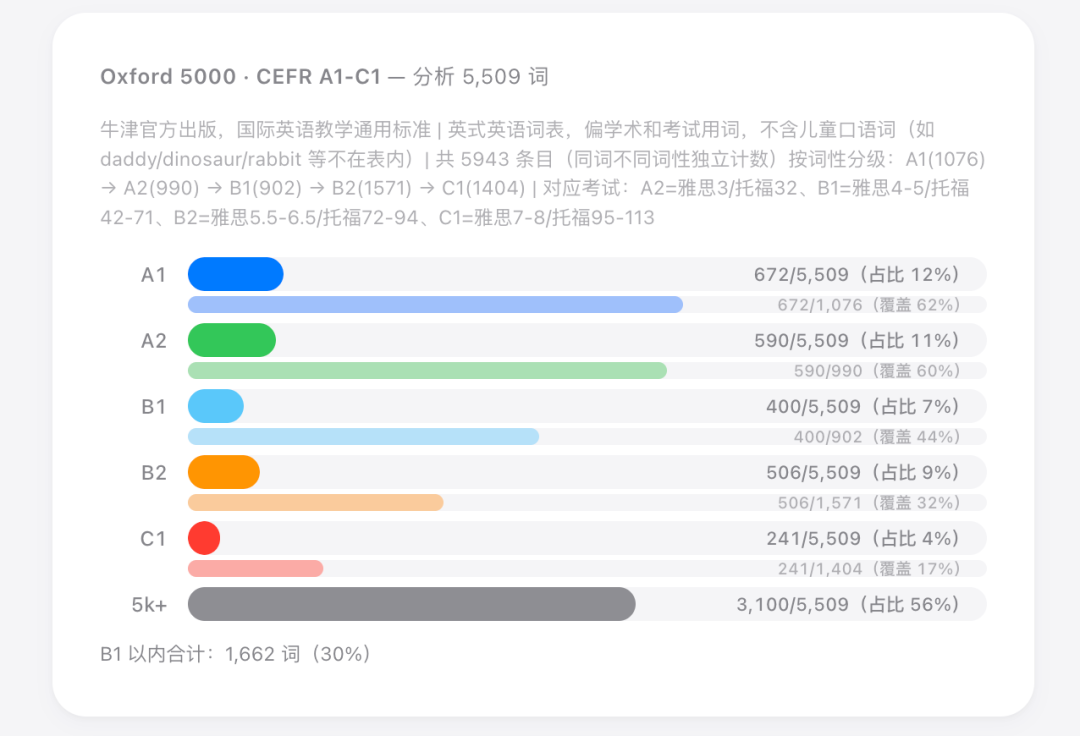
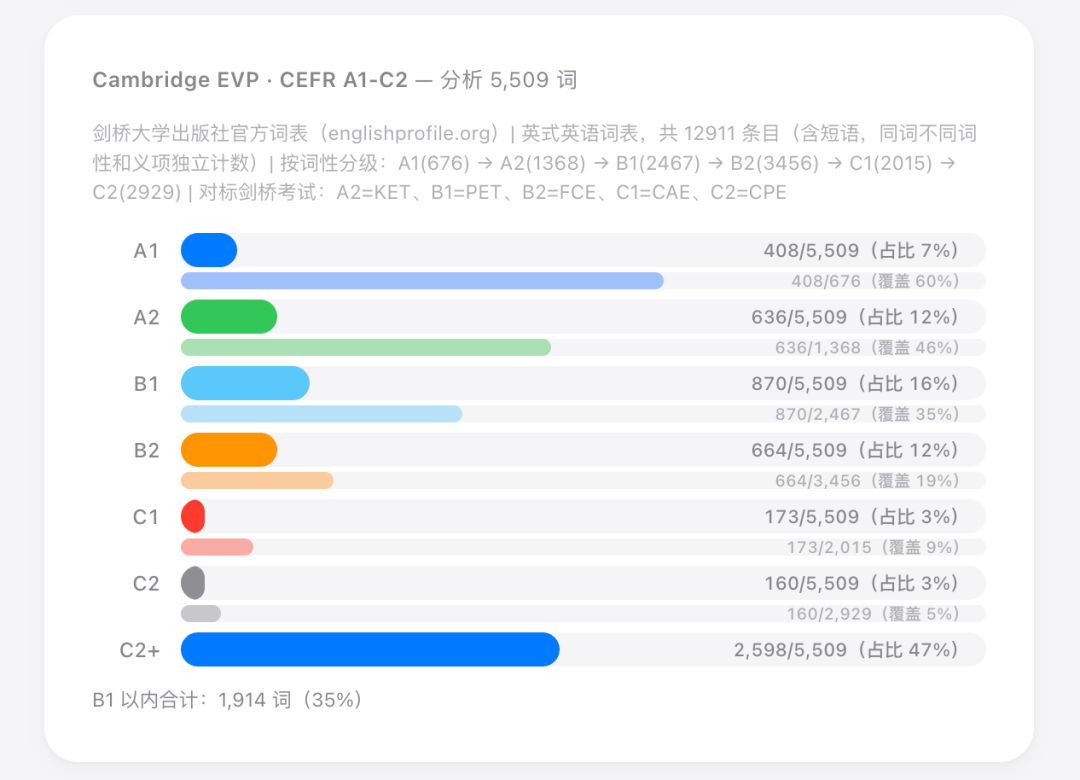
BNC/COCA 是啥?Paul Nation 是谁?Cambridge EVP 跟 Oxford 5000 有啥区别?Longman 3000 又是什么东西?
都是 AI 在我写代码的过程里,顺手掏出来喂给我的。
集成到后来一共 6 套。
最权威的那套叫 BNC/COCA,Paul Nation 搞的,差不多 30,000 个词族。
然后是牛津出版社的 Oxford 5000,按 CEFR 分 A1 到 C1。
剑桥的那套叫 Cambridge EVP,覆盖到 C2,还带短语。
朗文的 Longman 3000 能把一个词到底是口语高频还是书面语高频给你分开。

OpenSubtitles 是 16 万词的影视字幕库,反映真实说话的词频。
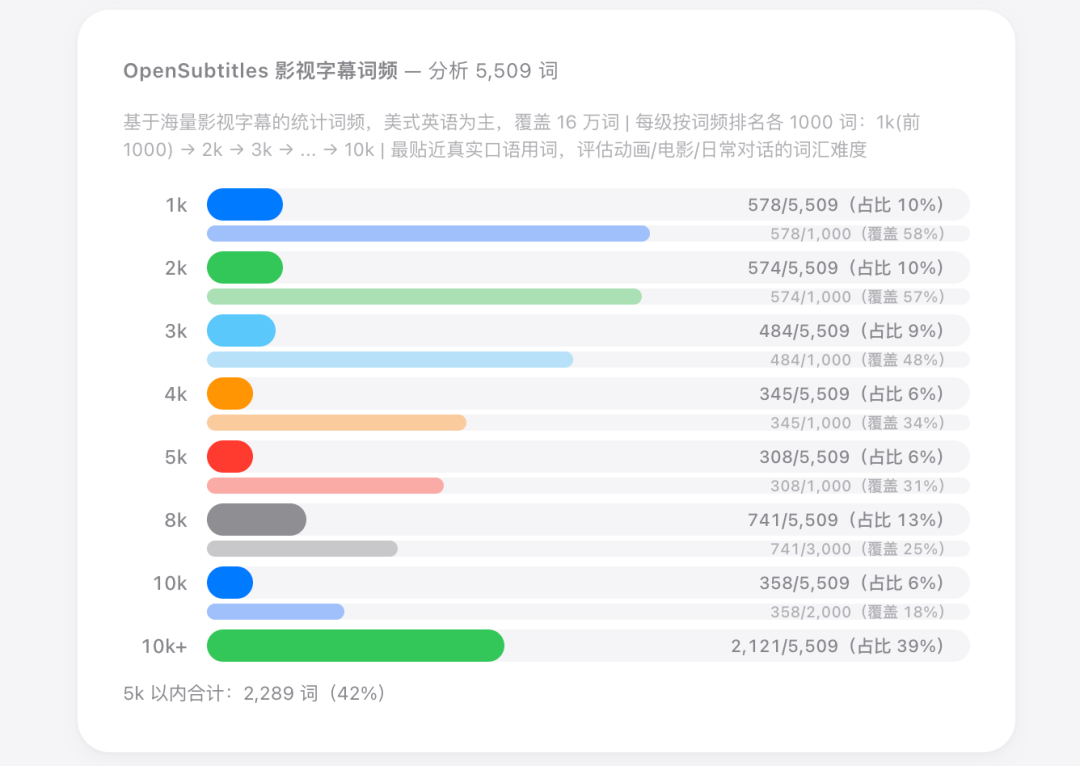
Fry 1000 则是美国小学教室里挂着的那种视觉词卡片。
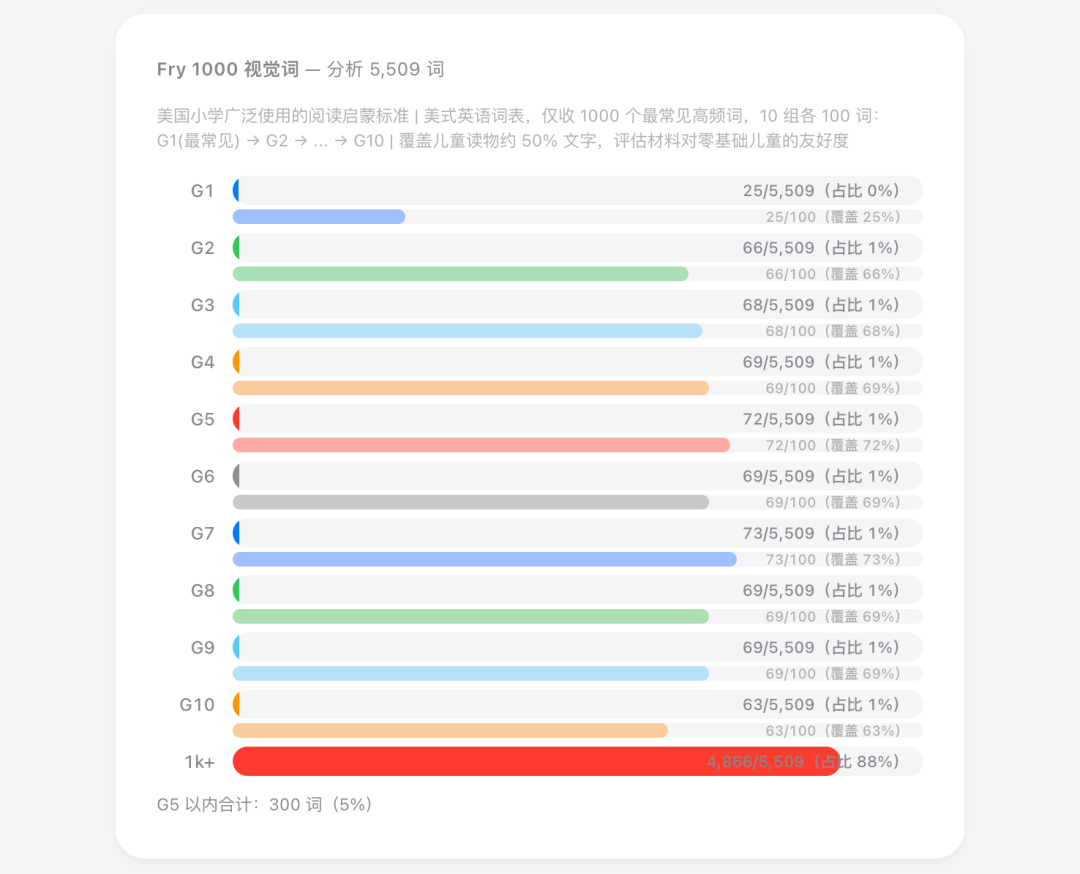
每套各有各的适用场景。Oxford 偏阅读考试,Cambridge 偏口语交流,OpenSubtitles 直接映射影视语料……
它不是让我去学词频学,是我一边写代码,一边顺手就把这些东西学会了。
写代码的过程,本身就是学习过程。
这点特别重要。很多人以为要先学会,再来写代码。但对 AI 时代的普通人来说,是反过来。
先想知道一件事,然后写代码,然后代码长出来的过程里,你自然就学会了。
还有一件事我必须摊开说。
我自己也不会写代码。
我不是程序员。不会 Python,不懂什么叫 spaCy 词形还原,Claude Code 帮我跑出来的代码每一行在干啥,我也看不明白。
你真把一串代码甩我脸上,我跟你一样懵。
所以千万别被「写代码」这三个字吓到。
AI 时代说的「写代码」,不是让你先买本书啃 30 个小时语法,再坐下来自己一行一行敲。
是你把脑子里那个「我到底要什么」说清楚,Claude Code 接住你的意思,它去敲。
你负责的其实就两件事。
一,把你想要的东西,想清楚。
二,看 AI 跑出来的结果对不对。
这两件事跟你会不会写代码,一点关系都没有。
跟你能不能用普通话、跟另一个活人把一件事描述清楚,关系还大一点。
换个角度讲,这整件事就只是换了一种思维方式而已。
以前你脑子里冒出来一个问号「她到底听懂了多少」,本能反应是问人,问豆包,家长群里丢一句求推荐,然后在七嘴八舌里挑一条你觉得靠谱的。
AI 时代你的反应,应该反过来。
把这个问号本身写成代码。
不是让你去写,是让代码被写出来,为你所用。
一旦你脑子切换到这个视角上,你会突然发现,好多事都在射程里。
事后我让 Claude code 总结了下,其实就在「挑动画片」这一个小项目里头,脚本文件夹里已经躺着 18 个脚本,每个脚本完成一件小事。
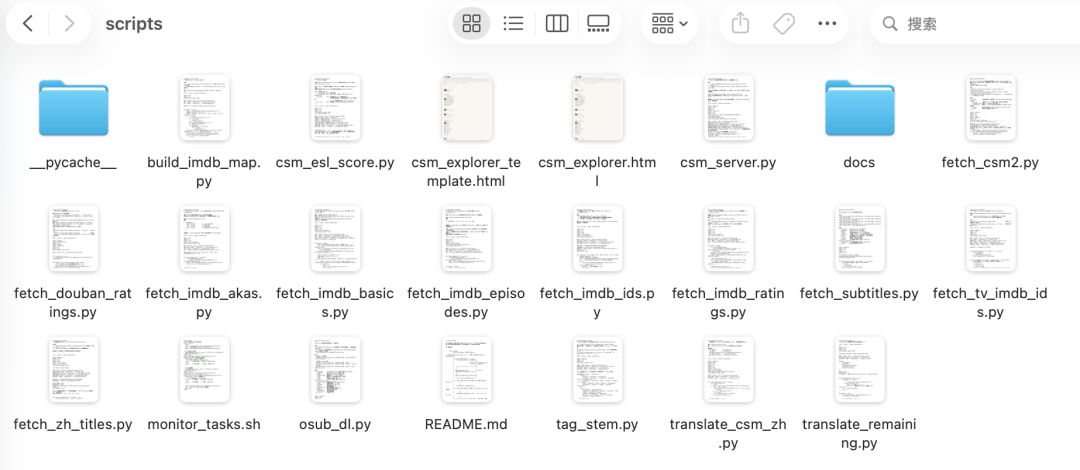
字幕从 OpenSubtitles、YouTube 自动字幕、各种字幕站多源抓取,429 自动切下一家;
CSM 官网那 35,972 部片子里的家长须知、教育意义、和孩子聊什么全是英文,让代码批量过腾讯翻译君翻成中文(每月 500 万免费额度);
lgg 的绘本是扫描版 PDF、她的口语练习是 m4a 录音、动画片是 mp4,词频分析只吃文本,那就挂上 OCR 和 Whisper、ffmpeg,一键都转成文本喂进主流水线;
……
每一个文件名的背后,都是某一天我脑子里闪过的一句「自动化 XX 」。
我从来没把这些当成「项目」来启动。
我就是把我生活里想要、懒得反复处理的每一件事,一件一件都写成了代码。
仅此而已。
这些事单拎出来,没有一件是「大项目」。每一件放在几年前都只能想一想就放弃了。
但在 AI 时代,它们每一个都是我随便起个念头、扔给 Claude Code、十来分钟就跑出结果的小事。
它们不在你「能写代码」的射程范围里,
但它们从现在开始,每一件都在。
门槛没变高。
是门槛被 AI 一脚给砸塌了。
只是大部分人还没意识到。
知道 lgg 掌握 2,058 词族之后,下一个问题马上跟着冒出来。
接下来给她看哪一部?
她已经把小猪佩奇刷完三遍了。继续刷同龄的?挑战难一点的?
按自然习得理论,最佳「可习得」内容要同时踩住两个条件。
一,单词覆盖率落在 85%–88% 之间。再低她挫败,再高没新东西可学。
二,里面得有足够多「她还不会、但这部片里会出现 ≥10 次」的新词。这些才是她真能被自然习得的。
学术上管这个区间叫 i+1,略高于当前水平一点点。
挑片真正难的地方就在这。
太简单 = 浪费时间,基本不涨词汇。
太难 = 挫败感强,根本跟不上。
刚刚好 = 神仙地带,但你怎么提前知道哪部刚刚好?
老办法。
让代码告诉我。
我让 Claude Code 基于前面的词频工具,又加了一个比较模式。
输入两个东西。
A,lgg 当前已掌握的词库,那 2,058词族。
B,一部新动画的完整字幕。
输出,B 站在 A 的视角下,覆盖率多少、里面有多少个「她还不会但出现≥10 次」的可习得词族。
效果是这样。
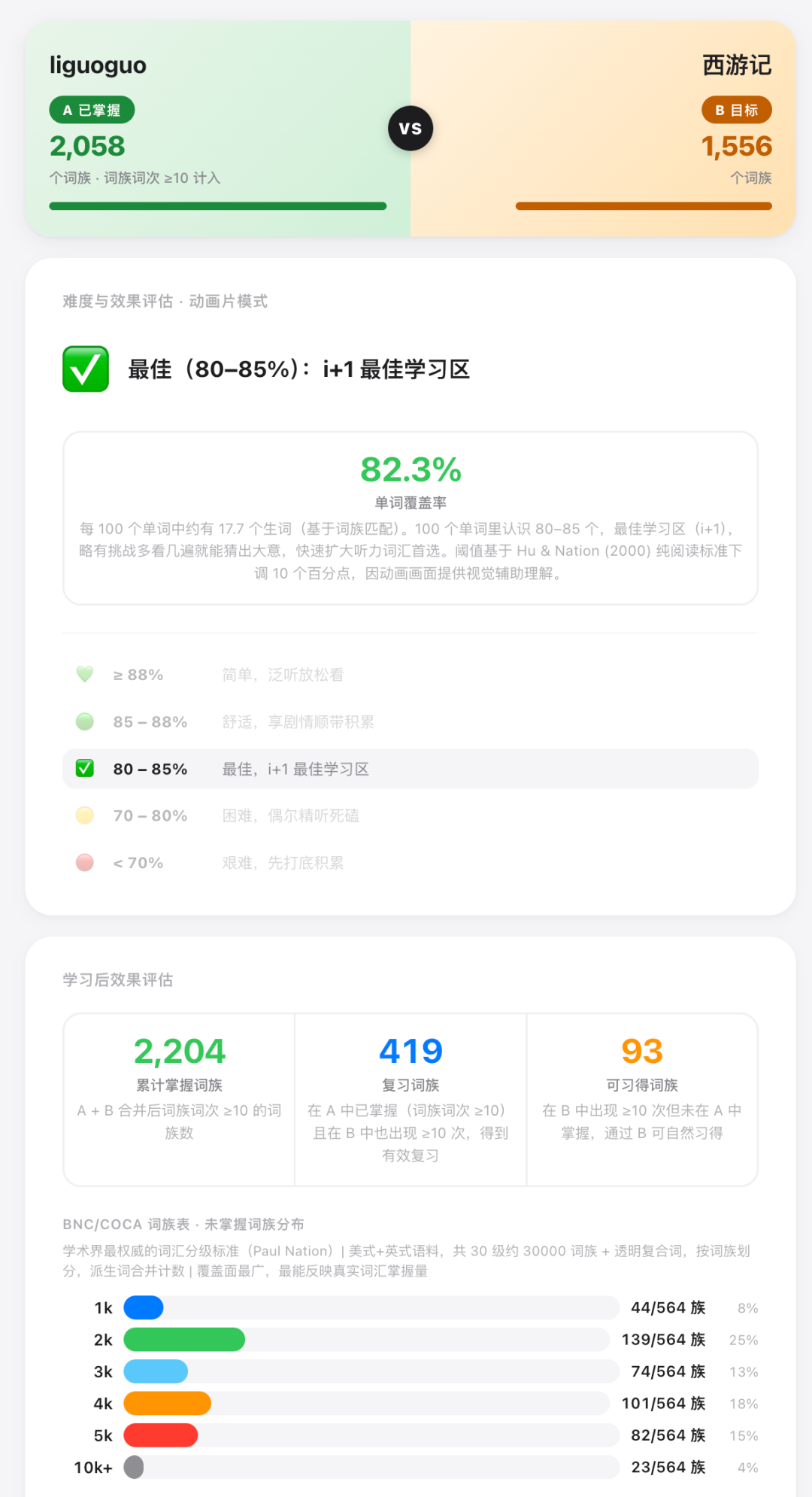
我挑了几部准备给她看的动画跑了一轮。
螺丝钉 the Fixies 单词覆盖率 89.2% 非常舒适,几乎无障碍。
Hero Elementary单词覆盖率86.9%舒适,偶有生词不影响理解。
西游记 单词覆盖率 82.3% 最佳,i+1 最佳学习区。
小纵队单词覆盖率 82.7% 最佳,i+1 最佳学习区。
判断一眼就出来了。
不是因为别人推荐,不是因为它评分高,不是因为小红书说它好。
而是因为,是 lgg 的真实单词覆盖率。
那种感觉,就像我原本在黑屋子里摸着抓阄,突然有人帮我把灯打开了。
而打开这盏灯的,不是某个英语启蒙专家,不是什么付费网课。
是AI 帮我写的代码。
但故事没结束。
比较模式能告诉我西游记适合 lgg。但它没告诉我,下一部西游记去哪里找?
而且小红书、家长群、各路博主推荐的那些清单,永远都是别人视角的。别人觉得好的动画片,不等于 lgg 现在能看懂的。
我那时候维护着一张 Excel,叫「lgg 待看清单」,每刷到推荐就往里加。
加着加着,那张表越堆越长。
长到我自己都不想点开了。
那一刻我意识到,挑片的另一半也得交给代码。
还是那一招,我又让 Claude Code 写了一个精选动画/电影/电视/播客的工具。
前面比较模式解决的是「一部片子适不适合 lgg」,这一半解决的是「全世界总共有哪些适合儿童的片子,我从哪里搞到它们的全量数据,来比较」。
写之前我啥都不懂。
哪里能拿到全量的儿童向内容?
谁在做内容分级,谁的评估靠谱?
如何判断一部片子有没有不适合一年级孩子的情节?
我都不知道。
都是 Claude Code 帮我一个一个写出来的。
它告诉我,
IMDb 有完整结构化元数据,有全球评分,还有公开数据集可以整包下载,本地离线查询,这是一切片子的基础事实。
豆瓣有国内视角下的评分,给 IMDb 补上本地化这一环。
CSM,Common Sense Media,美国一家专门做儿童内容评估的非营利机构。分年龄段,分暴力、性、语言、消费主义、积极信息、教育价值等多个维度打分。
最终画出来的结构长这样。
IMDb 元数据当基础事实,IMDb评分做为全球口碑部分,豆瓣评分做为国内口碑部分,CSM 年龄标签来判断适不适合这个年龄,这是三块数据就能挑选出大家认为质量不错的片子。
三块拼好之后整个丢给前面那个比较模式,就能帮我找出 lgg 真正适合的片子。
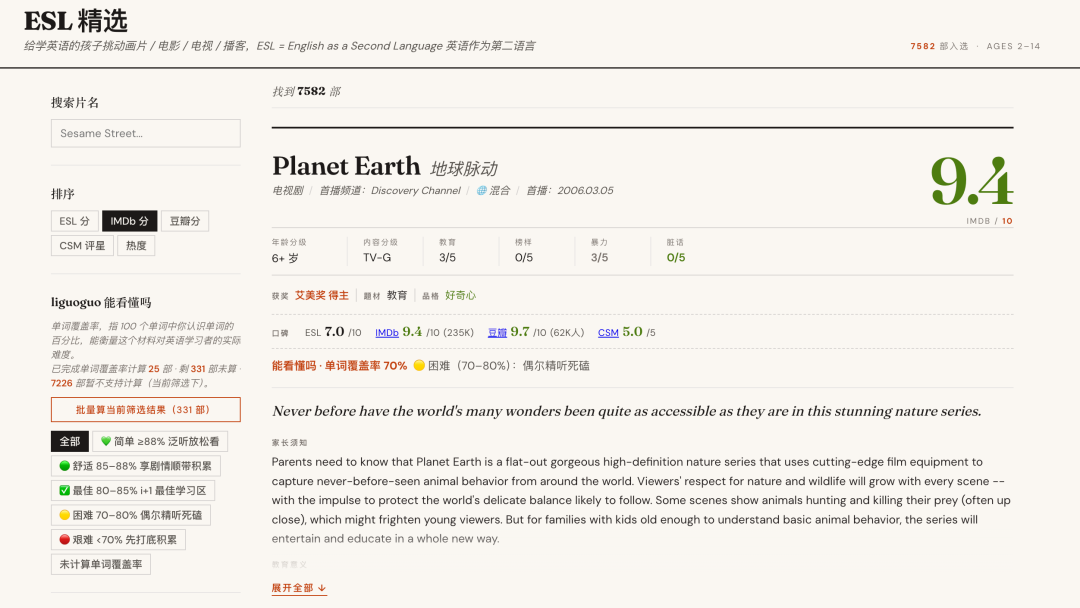
最终成品就是一个本地文件,我把它叫 ESL 精选。浏览器打开就能用,左边一堆筛选项,搜索、排序、内容类型、按年龄分级、内容分级、IMDb 评分、豆瓣评分、STEM 题材……

有一个个性化的筛选项,叫「lgg 能看懂吗」。

点 💚 简单 出来的就是 lgg 当前单词覆盖率 ≥88% 的片子,适合泛听放松看。
🟢 舒适,85–88%,享剧情的时候还能顺带积累词汇。
✅ 最佳,80–85%,是 i+1 最佳学习区,看得懂,又能快速积累词汇。
🟡 困难,70–80%,只适合偶尔精听死磕。
🔴 艰难,<70% ,暂时还看不懂,积累后才有机会看懂。
但这个过程,我必须坦诚,我犯过一个非常严重的错误。
最开始要抓 CSM 那 35,972 部片子的简介、家长须知、教育意义、和孩子聊什么的时候,我直接让 Claude Code 去抓。
35,972 部片子,每抓一部,就消耗大几千上万 token,要消耗好几个亿的 Token。
我用的是 Claude Code Max 版,每月 100 美金。它有 5 小时 跟 7 天的Token 限额,一下就被限流了。
原来是 Claude code 忘记了我开始要求的那句话,任何数据抓取的行为,都是先写成代码,再用代码去抓取数据。
我就让 Claude code 写到了 CLAUDE.md 文件里,下次就不会忘记了。
具体做法是,让 Claude Code 用bb-browser(一个浏览器自动化 CLI)先写一个适配器脚本,再在本地跑脚本去抓取数据。
写适配器脚本,只需要消耗一次 token。适配器脚本跑几万次,是在本地执行,零 token 消耗。
一百多年前美国电力普及的时候,很多工厂主花大价钱买了发电机、买了电动机,装在自己的工厂里。但装完之后发现效率没提升。
为啥?
因为他们只是用电动机替换掉了蒸汽机,但整个工厂的布局、流程、管理方式全都没变。
真正吃到电力红利的那批人,是最早想明白电力到底能用来干啥的那一拨人。
AI 这件事,我觉得现在就挺像一百多年前那会儿。
就这几天,马斯克的 SpaceX 官宣,要么 600 亿美元把 AI 代码编辑器 Cursor 收了,要么至少掏 100 亿美元和 Cursor 深度合作,把 xAI 的超算 Colossus 接进去一起干下一代编程 AI。
600 亿美元,买了个写代码的工具。
Cursor 现在已经跑在《财富》500 强里 67% 的公司。世界上最大的那批公司早就用脚投了票,把一切写成代码这件事,就是 AI 时代最硬的赛道。
顶级玩家在「把一切代码化」这件事上押 600 亿。
我在「把一切代码化」这件事上押一部动画片 lgg 能不能看懂。
数量级差了十万八千里,底层是同一件事。
大多数人把 AI 当成一个对话框在用。打开豆包、打开 ChatGPT、打个字、看一段回答,关掉。
这相当于你刚装了一台电动机,但你还是按蒸汽机的节奏在用它。
有用吗?有一点。但你远远没吃到它真正的红利。
真正的红利就一句话。
把任何东西都写成代码。
你脑子里冒出来的每一个「我不懂」、每一个「我没答案」、每一个「我每次都要重新想一遍」的场景,都写成代码。
你家娃不同阶段能听懂哪部动画,写成代码。
35,972 条英文评测要翻译,写成代码。
字幕从哪家抓、哪家优先、哪家兜底,写成代码。
给每部片子打个 STEM 题材标签,写成代码。
听上去冷冰冰的这句话,是 AI 时代一个普通人能握住的、最锋利的一把刀。
这事我琢磨下来,至少分成三层。
第一层,把疑问写成代码。
我不需要先去学自然习得理论,不需要先去读 Paul Nation 的学术论文,才开始解决「她听懂多少」。我可以先把疑问写成代码,让代码在长出来的过程里把所有不懂的一个个捡起来。
第二层,把方法写成代码。
挑动画片不是一次性的事。今天 lgg 一年级要挑,明年二年级还要挑,后年三年级更要挑。再往后从动画过渡到电影、到播客、到原版书。每一步都要挑。
如果每次我都重新对话、重新筛选,我会被淹没。
但如果我把「挑片」这件事本身写成 ESL 精选 + 词频对比分析,以后每次只需要把新内容喂进去,立刻就知道合不合适。
一次性思考 → 长期可复用的能力。
第三层,把场景写成代码。
抓数据不是一次性的。以后可能还要抓豆瓣、抓 IMDb、抓 YouTube 字幕、抓哪天又冒出来的新平台。
写一次适配器脚本,让脚本去做重复的事。这是把场景代码化。
这三层加起来,就是「能用 AI」和「用好 AI」之间的距离。
说实话写到这儿,lgg 后面的词汇量会怎么涨我也不知道,英语学的怎么样我不知道。
但当 lgg 跟我玩 freeze 游戏的时候,
我越想越明白,她能接住这个单词,不是因为她天赋异禀,是因为 90.3% 的单词覆盖率下,她脑子里的 2,058 个词族刚好接住了它。
有一件事我是越来越确定的。
不是我懂英语启蒙。
是 AI 懂,是代码懂。
AI 时代最被低估的一件事,就是这个。
多数人还把 AI 当成一个「可以对话的搜索引擎」。提问,等答案,关掉。
但 AI 真正能给你的是另一个东西。
它能让你把那些想不通、搞不清、每次都要重新想一遍的事,变成一段可以反复运行、可以扩展、可以沉淀的代码。
我不懂语言学。用代码长出了一个词频工具。
我不懂儿童内容评估。用代码长出了 IMDb+豆瓣+CSM组合的判断系统。
我不懂数据抓取的坑。用代码长出了一套可复用适配器。
每一个「我不懂」,都被代码化成了「我能用」。
所以我想在这篇文章结尾说一句。
能用豆包,和用好 AI,相差十万八千里。
差的不是技术。差的是你愿不愿意把观念扭过来。
把一切写成代码。
听起来粗暴,但它就是 AI 时代的答案。
-_-我是李榜主,关注我可能会上AI产品榜
-_-来都来了,顺手 点个赞、在看、转发 吧





