 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库FlagOS 核心算子库 FlagGems 全量支持 DeepSeek V4 算子,多芯片适配与多项首创性能优化技术同步落地
DeepSeek V4 模型以 CUDA + Tilelang 组合方式使用了数十个算子。为了能在多种 AI 芯片上运行 DeepSeek V4,众智 FlagOS 采用 Triton/Triton-TLE 重写了全部新增算子,并基于 Triton-TLE 实现了 TopK Selector 等高难度算子,在“算子全覆盖”的基础上,进一步提升性能。同时,通过 C++ Wrapper 和 FlagOS-Tune 等优化手段,在 H20上的端到端推理性能 (toks/s) 最高能超过 DeepSeek 原生发布版本的 11.2%。
FlagGems v5.0.2仓地址: https://github.com/flagos-ai/FlagGems/tree/v5.0.2 https://gitcode.com/flagos-ai/FlagGems/tags/v5.0.2 https://gitee.com/flagos-ai/FlagGems/tree/v5.0.2
01
FlagGems新增5个Triton算子支持 DeepSeek V4
DeepSeek V4 延续了 MoE 架构,在注意力机制和量化策略上引入了 5 个新算子(Tilelang+CUDA)。为了让众多 AI 芯片(海光/沐曦/天数/昆仑芯/摩尔/昇腾/平头哥等)能直接运行。FlagOS 社区基于 FlagTree 统一编译器,用 Triton 语言对全部 5 个算子进行了重新实现。
亮点一:用 Triton 重写算子,性能全面超越 TileLang
5 个算子在 NV H20 上的单算子性能全部优于 TileLang 或CUDA 原版,具体数据如下。
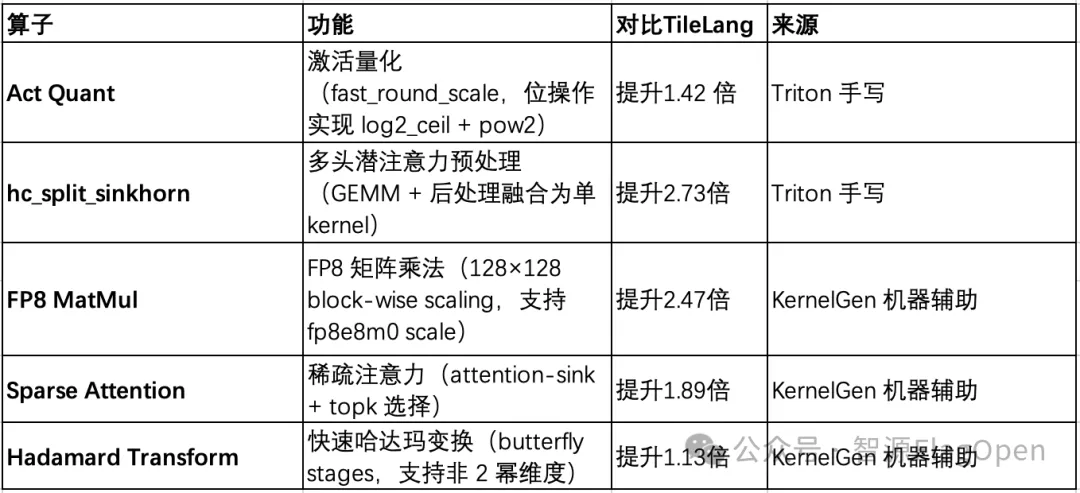
亮点二:KernelGen 自动生成算子首次直接应用
上述 5 个算子中,Sparse Attention、Hadamard Transform 和 FP8 MatMul 三个算子由 KernelGen 2.0 自动生成,这是 FlagOS 首次将 AI 自动生成的算子直接应用于大模型生产推理。
KernelGen 构建了一套基于 Agent 的自动化算子优化 pipeline:以初始 Triton kernel 和 reference 实现为起点,Agent 在每轮迭代中自主分析当前 kernel 的性能瓶颈与历史优化数据,自动实施优化策略,并完成正确性验证与性能 benchmark,全程无需人工干预,持续迭代直至达到目标性能,能够从朴素实现逐步逼近甚至超越手工调优的 TileLang baseline。以 FP8 MatMul 为例,KernelGen 从朴素 Triton 实现出发,经过多轮自动优化后达到 TileLang 的 2.47 倍性能。在 NV 平台 110 算子基准测试中,KernelGen 2.0 实现了 99% 生成正确性、90.8% 的算子加速比超过 100%。
02
C++ Wrapper:端到端性能提升 39%
虽然单算子性能全面超越 TileLang,但端到端推理中 Python Wrapper 的调用开销抵消了算子层面的优势。具体说来,Triton 算子 + Python Wrapper 的端到端吞吐比 DeepSeek原生版本降低了20.05%。Triton 编程模型的一个已知瓶颈在于,每次 kernel 调用都需要经过 Python 解释器的调度,包括参数序列化、GIL 竞争等开销。对于单个大算子(如 GEMM),这些开销相对于 kernel 执行时间可以忽略,但在 Transformer 推理场景下,一次 forward pass 需要调用数十个算子,大量小 kernel 的频繁 launch 使 Python 层开销成为性能瓶颈。C++ Wrapper 技术针对这一问题,基于 libtriton_jit 库,将 Triton kernel 的完整调用链路(参数绑定、grid 计算、kernel launch)下沉到 C++ 层,通过 pybind11 暴露为 Python 可调用接口。
具体解决了三个问题
消除 Python GIL 竞争:kernel launch 不再持有 GIL,多线程调度不阻塞
减少解释器开销:参数传递从 Python 对象序列化改为 C++ 原生类型直传
支持设备信息缓存:避免每次调用重复查询设备属性
通过实验,C++ Wrapper 联合 Triton 的技术组合让 DeepSeek-FlagOS 版本在端到端推理上,比 DeepSeek 原生版本快了 11%。
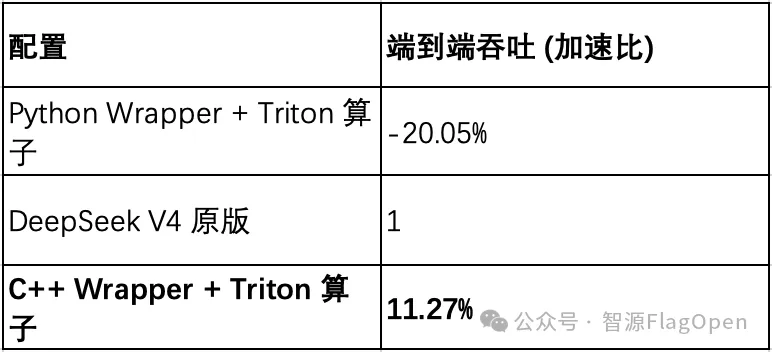
端到端效果(NV H20,DeepSeek V4 FP8)
在 DeepSeek V4 模型中,包括fp8_matmul、act_quant、nonzero、copy_、to_copy 等5个重要算子已开启 C++ Wrapper。其中单算子使用 C++ Wrapper 带来的端到端推理性能收益如下。
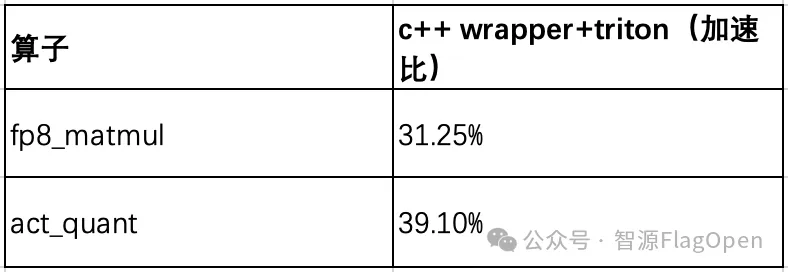
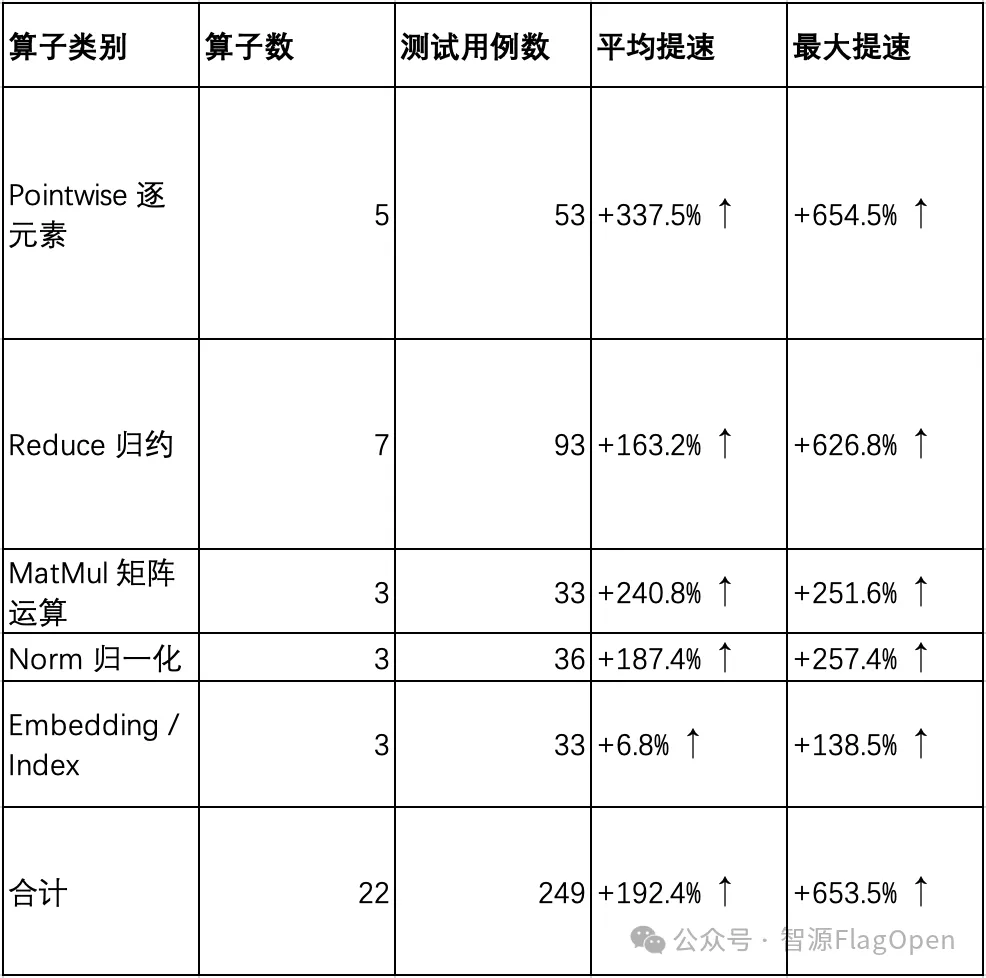
C++ Wrapper 技术同样适用于 FlagGems 中更多同类算子,按算子分类的覆盖情况和 NV 平台单算子性能对比如下。
C++ Wrapper 目前已支持英伟达、摩尔线程、华为昇腾、天数智芯、寒武纪等芯片。
03
Triton-TLE:TopK Selector 性能超越 FlashInfer 1.5 倍
DeepSeek V4 使用的 Sparse Attention 依赖高效的 TopK Selector 来选择参与计算的 KV 位置。
为什么 TopK Selector 重要?
TopK Selector 是 DeepSeek Sparse Attention(DSA)中的关键算子。DSA 通过只对 topk 个 KV 位置做后续 attention 计算来降低长上下文的计算开销,而 TopK Selector 负责从全部 KV 中快速选出这 topk 个位置的索引。随着上下文长度增加,TopK Selector 在总延迟中的占比越来越高:128K 上下文、batch=1 时,FlashInfer 在 H800 上单次 TopK Selector 耗时 45μs,60 层模型累计增加 2.7ms 的 TPOT 延迟。
为什么 Triton 直接实现很难?
TopK Selector 与普通 torch.topk 不同:只需要索引不需要值、不需要全排序、输入序列极长。GPU 上高效实现依赖 radix selection 算法——从高位到低位逐段筛选候选集,但这需要:
片上状态管理:直方图、阈值、候选缓冲等大量中间数据需要稳定存放在 shared memory
shared memory 原子操作:histogram 统计需要高效的片上原子更新
跨 block 协作:batch=1 长序列下,单 block 并行度不够,需要多 block 分工 + 汇总原生 Triton 缺乏稳定的 shared memory 管理和 cluster 协作原语,因此无法高效实现这类算子。
TLE 补齐了什么能力?
Triton-TLE 是 FlagTree 编译器对 Triton 语言的扩展,补齐了以下关键能力。
tle.gpu.alloc / tle.gpu.local_ptr:显式分配片上缓冲,支持 load/store/atomic
tle.remote:访问其他 block 的片上缓冲
tle.device_mesh / tle.distributed_barrier:定义 block cluster 组织方式和范围同步
基于这些原语,FlagOS 社区用 Triton-TLE 实现了多个版本的 TopK Selector,其中 DSMEM 版本在 batch=1 场景下取得了最优性能:通过 block cluster 将工作量分散到多个 block,每个 block 只负责部分 tile 的局部 histogram,再通过 remote 在片上完成汇总——全程不退回 global memory。

性能结果(H800)
TLE DSMEM 版本的核心优势在于,将单行的工作量通过 block cluster 分散到多个 block,每个 block 只负责部分 tile 的局部 histogram,再通过 remote 在片上完成汇总,全程不退回 global memory。
04
FlagOS-Tune:摩尔线程关键算子加速 5.82 倍
为充分发挥摩尔线程芯片在 FP8 计算上的内核优势,FlagOS 对 DeepSeek V4 模型进行了 FP8 量化。通过系统级分析,性能瓶颈主要集中在 FP8 算子和 Sparse Attention 算子。针对这两个关键算子,FlagOS 从编译优化与自动调优两个方向入手。
方向一:深入利用摩尔线程 FlagTree 编译器能力,提升底层执行效率。 通过精细化的 shape 对齐策略,使 FP8 和 Sparse Attention 的计算 shape 更好地满足摩尔线程张量访存与计算引擎(TME/TCE)的要求;同时结合 MUSA_ENABLE_SQMMA,进一步加速 tl.dot 矩阵计算。
方向二:借助 FlagOS-Tune,自动搜索最优 Triton 内核配置。 FlagOS-Tune 能够扩展算子的搜索空间,基于模型真实 shape 离线搜索 FP8 和 Sparse Attention 算子的最优内核配置,效果优于手工调参。
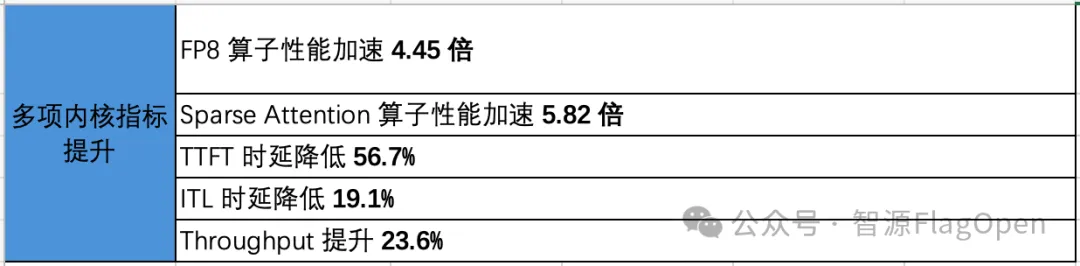
在离线优化之外,FlagOS-Tune 还支持在线内核配置搜索能力。用户只需开启环境变量 USE_FLAGTUNE=1,经过一段时间的 warmup 后,系统基于实际运行过程持续搜索并应用最佳配置。其中,TTFT 时延降低 16.5%,ITL 时延降低 39.7%,Throughput 提升 65.7%。
05
总结与展望
本次 DeepSeek V4 的算子适配回答了两个关键问题。第一问题是,统一的 Triton 编程模型,能否在性能上追平甚至超越针对特定硬件深度优化的 TileLang? FlagGems 用 Triton 重写的 5 个新算子性能全面超越 TileLang,C++ Wrapper 联合 Triton 的端到端吞吐比 TileLang 高 11%。算子层面的跨芯统一编程模型,已经具备与专用优化竞争的实力。
第二个问题是,Triton 的表达能力上限在哪里? Triton-TLE 编写的 TopK Selector 算子在 batch=1 的场景下性能达到 FlashInfer 的 1.5 倍、TRT-LLM 的 2.5 倍,证明 Triton + TLE 已经能达到过去只有 CUDA 才能实现的性能。
后续,众智 FlagOS 将继续推进基于 vLLM-plugin-FL 的高性能服务化部署版本,以及更多芯片平台的 C++ Wrapper 和 FlagOS-Tune 适配。
关于众智FlagOS社区
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智 FlagOS 社区。成员单位包括北京智源研究院、中科院计算所、中科加禾、安谋科技、北京大学、北京师范大学、百度飞桨、硅基流动、寒武纪、海光信息、华为、基流科技、摩尔线程、沐曦科技、澎峰科技、清微智能、天数智芯、先进编译实验室、移动研究院、中国矿业大学(北京)等,他们在 FlagOS 软件栈研发中做出卓越贡献。
FlagOS 是一款专为异构 AI 芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
官网:https://flagos.io
GitHub 项目地址:https://github.com/flagos-ai
GitCode 项目地址:https://gitcode.com/flagos-ai
SkillHub: https://skillhub.flagos.io
01
FlagGems新增5个Triton算子支持 DeepSeek V4
DeepSeek V4 延续了 MoE 架构,在注意力机制和量化策略上引入了 5 个新算子(Tilelang+CUDA)。为了让众多 AI 芯片(海光/沐曦/天数/昆仑芯/摩尔/昇腾/平头哥等)能直接运行。FlagOS 社区基于 FlagTree 统一编译器,用 Triton 语言对全部 5 个算子进行了重新实现。
亮点一:用 Triton 重写算子,性能全面超越 TileLang
5 个算子在 NV H20 上的单算子性能全部优于 TileLang 或CUDA 原版,具体数据如下。
亮点二:KernelGen 自动生成算子首次直接应用
上述 5 个算子中,Sparse Attention、Hadamard Transform 和 FP8 MatMul 三个算子由 KernelGen 2.0 自动生成,这是 FlagOS 首次将 AI 自动生成的算子直接应用于大模型生产推理。
KernelGen 构建了一套基于 Agent 的自动化算子优化 pipeline:以初始 Triton kernel 和 reference 实现为起点,Agent 在每轮迭代中自主分析当前 kernel 的性能瓶颈与历史优化数据,自动实施优化策略,并完成正确性验证与性能 benchmark,全程无需人工干预,持续迭代直至达到目标性能,能够从朴素实现逐步逼近甚至超越手工调优的 TileLang baseline。以 FP8 MatMul 为例,KernelGen 从朴素 Triton 实现出发,经过多轮自动优化后达到 TileLang 的 2.47 倍性能。在 NV 平台 110 算子基准测试中,KernelGen 2.0 实现了 99% 生成正确性、90.8% 的算子加速比超过 100%。
02
C++ Wrapper:端到端性能提升 39%
虽然单算子性能全面超越 TileLang,但端到端推理中 Python Wrapper 的调用开销抵消了算子层面的优势。具体说来,Triton 算子 + Python Wrapper 的端到端吞吐比 DeepSeek原生版本降低了20.05%。Triton 编程模型的一个已知瓶颈在于,每次 kernel 调用都需要经过 Python 解释器的调度,包括参数序列化、GIL 竞争等开销。对于单个大算子(如 GEMM),这些开销相对于 kernel 执行时间可以忽略,但在 Transformer 推理场景下,一次 forward pass 需要调用数十个算子,大量小 kernel 的频繁 launch 使 Python 层开销成为性能瓶颈。C++ Wrapper 技术针对这一问题,基于 libtriton_jit 库,将 Triton kernel 的完整调用链路(参数绑定、grid 计算、kernel launch)下沉到 C++ 层,通过 pybind11 暴露为 Python 可调用接口。
具体解决了三个问题
消除 Python GIL 竞争:kernel launch 不再持有 GIL,多线程调度不阻塞
减少解释器开销:参数传递从 Python 对象序列化改为 C++ 原生类型直传
支持设备信息缓存:避免每次调用重复查询设备属性
通过实验,C++ Wrapper 联合 Triton 的技术组合让 DeepSeek-FlagOS 版本在端到端推理上,比 DeepSeek 原生版本快了 11%。
端到端效果(NV H20,DeepSeek V4 FP8)
在 DeepSeek V4 模型中,包括fp8_matmul、act_quant、nonzero、copy_、to_copy 等5个重要算子已开启 C++ Wrapper。其中单算子使用 C++ Wrapper 带来的端到端推理性能收益如下。
C++ Wrapper 技术同样适用于 FlagGems 中更多同类算子,按算子分类的覆盖情况和 NV 平台单算子性能对比如下。
C++ Wrapper 目前已支持英伟达、摩尔线程、华为昇腾、天数智芯、寒武纪等芯片。
03
Triton-TLE:TopK Selector 性能超越 FlashInfer 1.5 倍
DeepSeek V4 使用的 Sparse Attention 依赖高效的 TopK Selector 来选择参与计算的 KV 位置。
为什么 TopK Selector 重要?
TopK Selector 是 DeepSeek Sparse Attention(DSA)中的关键算子。DSA 通过只对 topk 个 KV 位置做后续 attention 计算来降低长上下文的计算开销,而 TopK Selector 负责从全部 KV 中快速选出这 topk 个位置的索引。随着上下文长度增加,TopK Selector 在总延迟中的占比越来越高:128K 上下文、batch=1 时,FlashInfer 在 H800 上单次 TopK Selector 耗时 45μs,60 层模型累计增加 2.7ms 的 TPOT 延迟。
为什么 Triton 直接实现很难?
TopK Selector 与普通 torch.topk 不同:只需要索引不需要值、不需要全排序、输入序列极长。GPU 上高效实现依赖 radix selection 算法——从高位到低位逐段筛选候选集,但这需要:
片上状态管理:直方图、阈值、候选缓冲等大量中间数据需要稳定存放在 shared memory
shared memory 原子操作:histogram 统计需要高效的片上原子更新
跨 block 协作:batch=1 长序列下,单 block 并行度不够,需要多 block 分工 + 汇总原生 Triton 缺乏稳定的 shared memory 管理和 cluster 协作原语,因此无法高效实现这类算子。
TLE 补齐了什么能力?
Triton-TLE 是 FlagTree 编译器对 Triton 语言的扩展,补齐了以下关键能力。
tle.gpu.alloc / tle.gpu.local_ptr:显式分配片上缓冲,支持 load/store/atomic
tle.remote:访问其他 block 的片上缓冲
tle.device_mesh / tle.distributed_barrier:定义 block cluster 组织方式和范围同步
基于这些原语,FlagOS 社区用 Triton-TLE 实现了多个版本的 TopK Selector,其中 DSMEM 版本在 batch=1 场景下取得了最优性能:通过 block cluster 将工作量分散到多个 block,每个 block 只负责部分 tile 的局部 histogram,再通过 remote 在片上完成汇总——全程不退回 global memory。
性能结果(H800)
TLE DSMEM 版本的核心优势在于,将单行的工作量通过 block cluster 分散到多个 block,每个 block 只负责部分 tile 的局部 histogram,再通过 remote 在片上完成汇总,全程不退回 global memory。
04
FlagOS-Tune:摩尔线程关键算子加速 5.82 倍
为充分发挥摩尔线程芯片在 FP8 计算上的内核优势,FlagOS 对 DeepSeek V4 模型进行了 FP8 量化。通过系统级分析,性能瓶颈主要集中在 FP8 算子和 Sparse Attention 算子。针对这两个关键算子,FlagOS 从编译优化与自动调优两个方向入手。
方向一:深入利用摩尔线程 FlagTree 编译器能力,提升底层执行效率。 通过精细化的 shape 对齐策略,使 FP8 和 Sparse Attention 的计算 shape 更好地满足摩尔线程张量访存与计算引擎(TME/TCE)的要求;同时结合 MUSA_ENABLE_SQMMA,进一步加速 tl.dot 矩阵计算。
方向二:借助 FlagOS-Tune,自动搜索最优 Triton 内核配置。 FlagOS-Tune 能够扩展算子的搜索空间,基于模型真实 shape 离线搜索 FP8 和 Sparse Attention 算子的最优内核配置,效果优于手工调参。
在离线优化之外,FlagOS-Tune 还支持在线内核配置搜索能力。用户只需开启环境变量 USE_FLAGTUNE=1,经过一段时间的 warmup 后,系统基于实际运行过程持续搜索并应用最佳配置。其中,TTFT 时延降低 16.5%,ITL 时延降低 39.7%,Throughput 提升 65.7%。
05
总结与展望
本次 DeepSeek V4 的算子适配回答了两个关键问题。第一问题是,统一的 Triton 编程模型,能否在性能上追平甚至超越针对特定硬件深度优化的 TileLang? FlagGems 用 Triton 重写的 5 个新算子性能全面超越 TileLang,C++ Wrapper 联合 Triton 的端到端吞吐比 TileLang 高 11%。算子层面的跨芯统一编程模型,已经具备与专用优化竞争的实力。
第二个问题是,Triton 的表达能力上限在哪里? Triton-TLE 编写的 TopK Selector 算子在 batch=1 的场景下性能达到 FlashInfer 的 1.5 倍、TRT-LLM 的 2.5 倍,证明 Triton + TLE 已经能达到过去只有 CUDA 才能实现的性能。
后续,众智 FlagOS 将继续推进基于 vLLM-plugin-FL 的高性能服务化部署版本,以及更多芯片平台的 C++ Wrapper 和 FlagOS-Tune 适配。
关于众智FlagOS社区
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智 FlagOS 社区。成员单位包括北京智源研究院、中科院计算所、中科加禾、安谋科技、北京大学、北京师范大学、百度飞桨、硅基流动、寒武纪、海光信息、华为、基流科技、摩尔线程、沐曦科技、澎峰科技、清微智能、天数智芯、先进编译实验室、移动研究院、中国矿业大学(北京)等,他们在 FlagOS 软件栈研发中做出卓越贡献。
FlagOS 是一款专为异构 AI 芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
官网:https://flagos.io
GitHub 项目地址:https://github.com/flagos-ai
GitCode 项目地址:https://gitcode.com/flagos-ai
SkillHub: https://skillhub.flagos.io





