 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库DeepSeek-V4终于更新了!一百万超长上下文,Agent能力大幅增强,能力接近Opus 4.6

刚刚,期待已久的 DeepSeek-V4 终于更新了。
DeepSeek 正式上线并开源了 DeepSeek-V4 的预览版,分为 Pro 和 Flash 两个版本。DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。
这次的更新力度不小,有两个核心变化:一是,V4 拥有 1M 的超长上下文,1M 上下文已经成为了标配;二是,Agent 能力大幅的增强。
DeepSeek 官方提到,V4-Pro 在 Agentic Coding 评测中已经达到了当前开源模型最佳水平,也是公司内部员工日常在使用的 Agentic Coding 模型。据内部员工评测,V4-Pro 的反馈体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式。
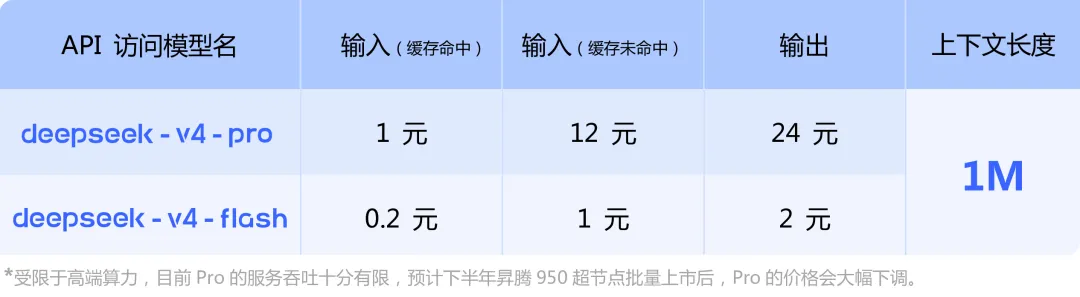
目前,DeepSeek-V4 已经在官网、官方 App 中上线,用户可以直接体验。同时,API 也已同步上线,model_name 改为 deepseek-v4-pro 或 deepseek-v4-flash 即可调用。
Founder Park 正在持续寻找值得被看见的 AI 团队与项目。
我们将通过「AI 产品市集」、内容报道、社群分发等方式,帮你触达早期用户、获得真实反馈,以及建立关键连接。
如果你正在做 AI 相关的事,欢迎和我们聊聊。
01
两款新模型:Flash、Pro 版本
此次更新的 DeepSeek-V4 模型,按大小分为两个版本:DeepSeek-V4-Pro 和 DeepSeek-V4-Flash。

V4-Pro 拥有 1.6T 总参数、49B 激活参数;V4-Flash 为 284B 总参数、13B 激活参数,两款模型均原生支持 1M token 的上下文长度。
此外,V4-Flash 在 32T tokens 上完成预训练,V4-Pro 则在 33T tokens 上完成预训练。
DeepSeek-V4-Pro 是这次发布的旗舰版本,各项能力均对标顶级闭源模型。
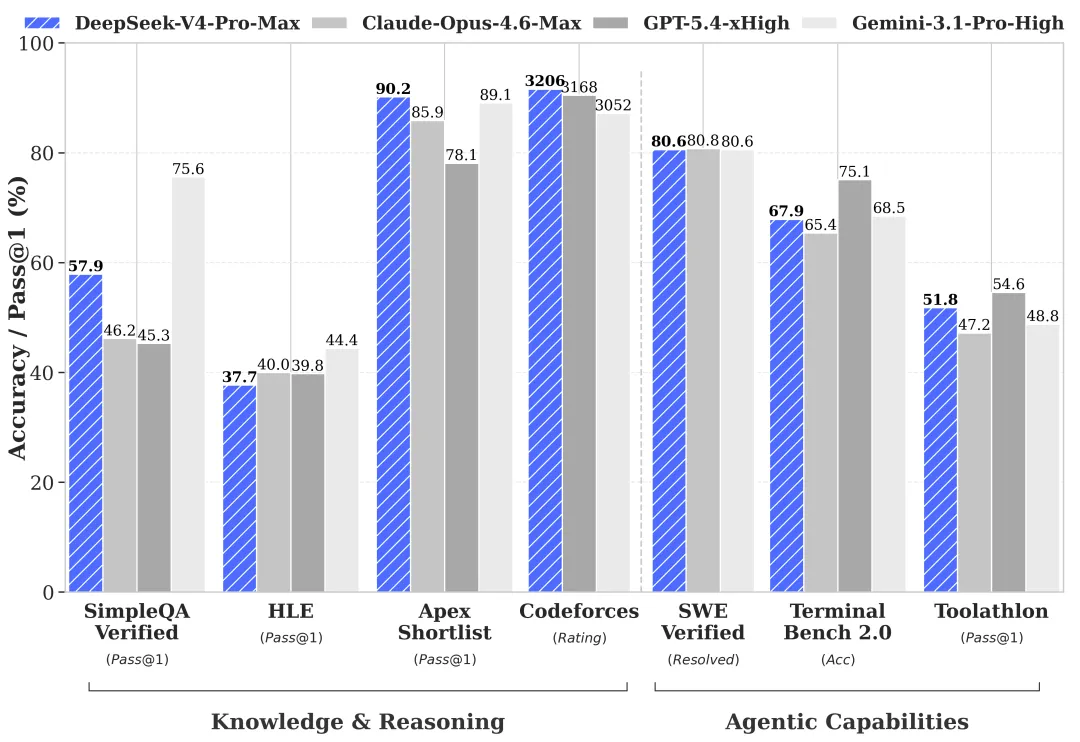
其中,Agent 能力是突出的升级方向。在 Agentic Coding 评测中,V4-Pro 已达到当前开源模型最佳水平,并在其他 Agent 相关评测中同样表现优异。据 DeepSeek 内部员工评测反馈,使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但与 Opus 4.6 思考模式仍存在一定差距。
值得一提的是,V4-Pro 还针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 产品进行了专项适配和优化,在代码任务、文档生成任务等方面的表现均有提升。
在世界知识方面,V4-Pro 在测评中大幅领先其他开源模型,仅稍逊于顶尖闭源模型 Gemini-Pro-3.1。
推理性能同样亮眼,在数学、STEM、竞赛型代码的测评中,V4-Pro 超越了当前所有已公开评测的开源模型,取得了比肩世界顶级闭源模型的成绩。
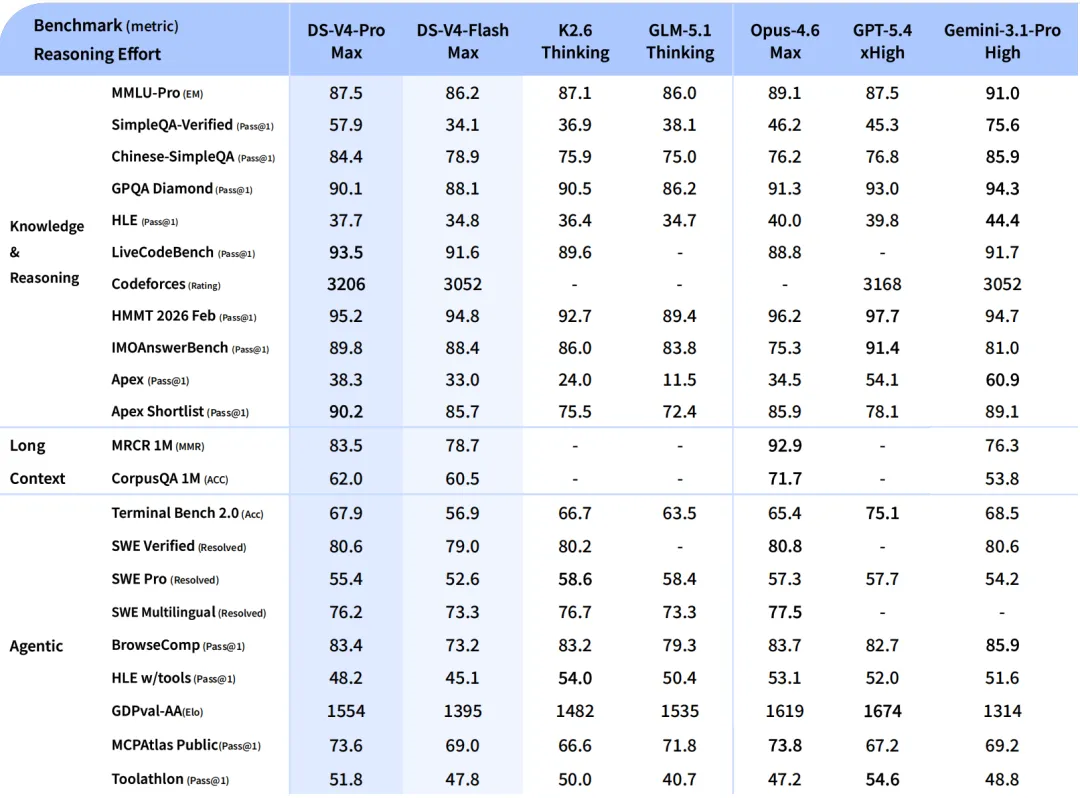
DeepSeek-V4-Flash 则是更多面向对成本和速度更敏感的场景。相比于 V4-Pro,V4-Flash 在世界知识储备方面稍逊,但推理能力接近。
由于模型参数和激活更小,Flash 版能够提供更加快捷、经济的 API 服务。在 Agent 评测中,V4-Flash 在简单任务上与 V4-Pro 相当,但在高难度任务上仍有一定差距。
02
提出全新的注意力机制,
一百万上下文成为标配
DeepSeek 官方特别提到,DeepSeek-V4 使用了一种全新的注意力机制,在 token 维度进行压缩,结合 DSA 稀疏注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文能力。同时,相比传统方法大幅降低了对计算和显存的需求。从现在起,一百万上下文将是 DeepSeek 所有官方服务的标配。
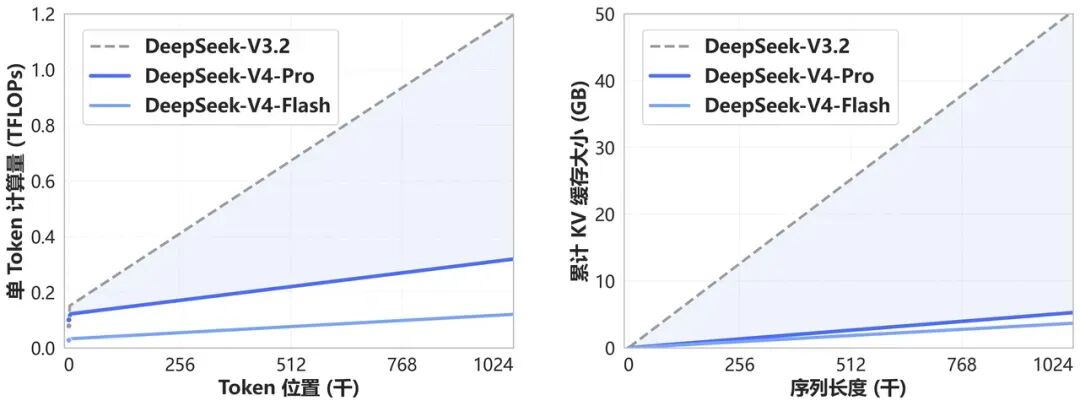
DeepSeek-V4 和 DeepSeek-V3.2 的计算量和显存容量随上下文长度的变化
DeepSeek-V4 的技术报告中提到,这次架构升级包含了三项核心创新:
CSA+HCA 混合注意力机制(Compressed Sparse Attention 与 Heavily Compressed Attention),这是实现超长上下文高效处理的核心所在;
mHC(Manifold-Constrained Hyper-Connections,流形约束超连接),用于强化传统残差连接,提升信号在层间传播的稳定性;
引入 Muon 优化器,带来更快的收敛速度与更稳定的训练过程;
在效率层面,技术报告同样给出了更具体的量化数据:在 1M token 上下文场景下,V4-Pro 的单 token 推理 FLOPs 仅为 DeepSeek-V3.2 的 27%,KV Cache 大小仅为 10%。V4-Flash 的效率提升更为激进,FLOPs 仅为 10%,KV Cache 仅为 7%。
03
官网、App、API 同步上线,
即日可用
目前,DeepSeek API 已经同步上线了 V4-Pro 和 V4-Flash,支持 OpenAI ChatCompletions 接口与 Anthropic 接口。访问新模型时,base_url 不变,model 参数改为 deepseek-v4-pro 或 deepseek-v4-flash 即可。
V4-Pro 与 V4-Flash 最大上下文长度均为 1M,同时支持非思考模式与思考模式。其中思考模式支持通过 reasoning_effort 参数设置思考强度(high / max)。对于复杂的 Agent 场景,DeepSeek 官方建议使用思考模式并将强度设置为 max。
需要注意的是,旧有的两个模型名 deepseek-chat 与 deepseek-reasoner 将于三个月后(2026-07-24)停止使用。当前阶段内,这两个模型名分别对应的是 deepseek-v4-flash 的非思考模式与思考模式。
更详细的调用方式请参考官方文档:api-docs.deepseek.com
开源权重和本地部署
DeepSeek-V4 模型开源链接:
https://huggingface.co/collections/deepseek-ai/deepseek-v4
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
DeepSeek-V4 技术报告:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf


AI Native的组织架构应该是怎么样的?Block CEO:每家公司都可以压缩成一个agent
对谈CREAO:20人团队、每天上线8个功能,在Pivot产品之前,我们先Pivot了组织
Canva可画联合创始人独家专访:2.65亿用户的Canva,用自研模型,解决了设计的审美问题
一款好的 AI Native 硬件,硬件只是脚手架,真正壁垒一定是 Agent
转载原创文章请添加微信:founderparker





