 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库DeepSeek-V4:华为昇腾适配、性价比王者、最新底层技术

作者丨梁丙鉴
编辑丨马晓宁

越过数个发布窗口,4 月 24 日,DeepSeek 最新一代旗舰模型 DeepSeek-V4 终于正式发布。
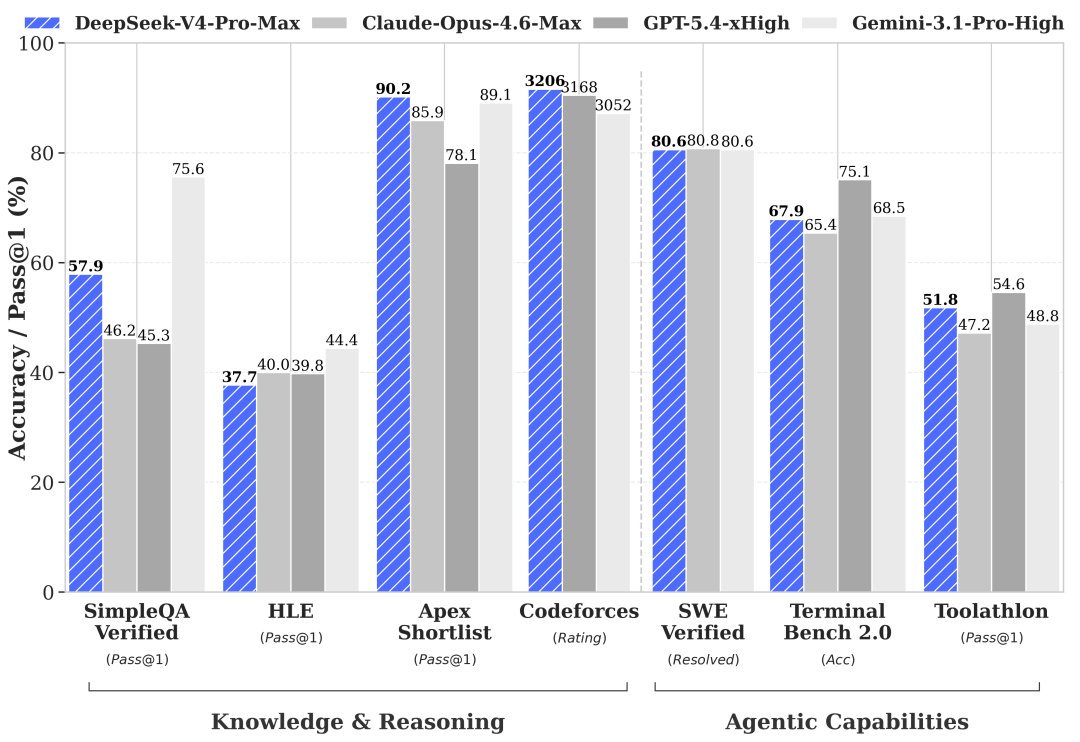
此次发布的 DeepSeek-V4 主打百万字超长上下文,在 Agent 能力、世界知识和推理性能上均表现亮眼。有意思的是,4 月 8 日凌晨 DeepSeek 悄然上线了专家模式和快速模式,外界一度猜测是 V4 的不同版本。这一猜测得到了官方确认,按参数量大小,V4 此次同步推出了 pro 及 flash 两个版本。

相较于前代模型,V4 的 Agent 能力有了大幅提高。DeepSeek-V4-Pro 在 Agentic Coding 评测中,已达到当前开源模型最佳水平,且在其它 Agent 相关评测中同样表现优异。DeepSeek 内部评测反馈显示,DeepSeek-V4-Pro 使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在一定差距。
此外在 SimpleQA Verified、HLE 等知识推理类基准测试中,DeepSeek V4 的表现均居于前列,特别是在ApexShortlist、Codeforces 两项测试中分别以 90.2 和 3206 的成绩登顶,表现出了顶级的推理性能和世界知识储备。
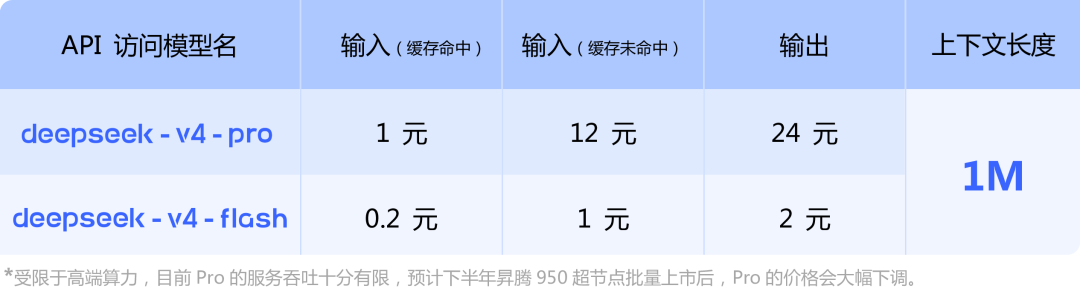
价格方面,pro 版本和 flash 版本采取了阶梯定价。更小更快的 flash 版本继承了前代模型便宜大碗路线的,同时 pro 版本的降价也被官方排上日程,预计会随着今年下半年昇腾 950 超节点的批量上市实现大幅下调。
值得注意的是,DeepSeek-V4 针对昇腾等国产芯片进行了深度适配,实现推理环节全面兼容,有传闻称利用率可达 85% 以上。而据路透社报道,此前 DeepSeek 也拒绝向包括英伟达在内的美国芯片制造商提供 V4 模型的早期访问权限。
在美国对华出台高端 GPU 禁令、限制技术交流的背景下,DeepSeek 选择以技术对等的姿态回应,和美方的脱钩构成了一种有趣的镜像关系。而回到国内,DeepSeek-V4 的背书证明了国产芯片足以支持第一梯队大模型的推理部署,开始完成从“可用”到“好用”的跨越。同时被国产算力托住的 V4,也或可视为一个备战“全华班模型生态”的起点。

01
架构创新,破解模型推理“不可能三角”
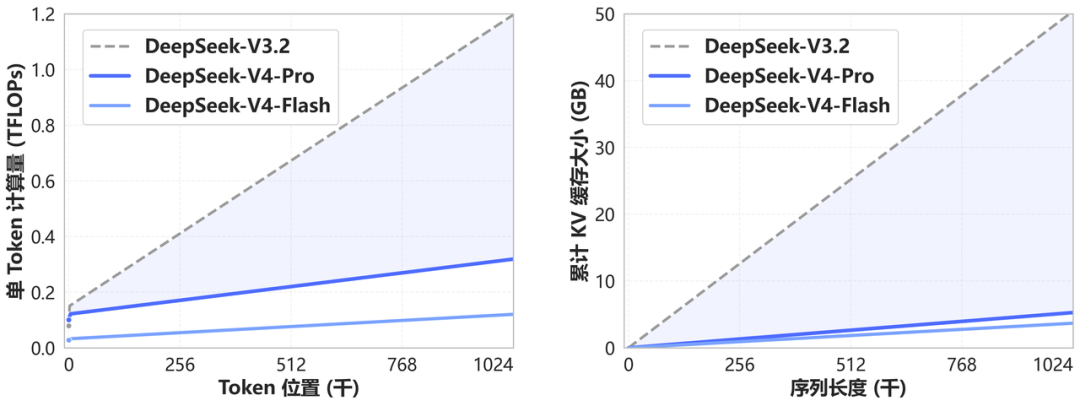
DeepSeek-V4 的上下文窗口跨越式地来到了 100 万 Token 大关,并宣称这此后将是 DeepSeek 所有官方服务的标配。
据官方技术文档介绍,这种长文本能力的成熟源于 DeepSeek 开创的一种全新注意力机制,在 token 维度进行压缩,结合 DSA 稀疏注意力(DeepSeek Sparse Attention),此举不仅实现了全球领先的长上下文能力,并且相比于传统方法大幅降低了对计算和显存的需求。
DeepSeek 对长文本能力的探索早有迹象。在 V4 迟迟没有问世的时间里,DeepSeek 低调发布的两篇论文《mHC: Manifold-Constrained Hyper-Connections》,和两周以后紧随其后的《Engram: Conditional Memory via Scalable Lookup》,被外界视为其在长文本方面的有力技术储备。
在长文本推理任务中,大模型长期存在着成本、速度、精度的不可能三角,但 Engram 架构提供了一种破局思路。该架构包含一个静态知识检索模块,和一个动态推理协同模块,前者通过哈希查找机制,将事实性知识存储在廉价的 CPU 内存中,节省了对推理尤其宝贵的 GPU 显存,后者负责判断检索到的记忆是否应该调用,并在必要时将其无缝融入推理过程。
这种设计的本质是将模型的记忆和计算分离,通过对信息存储进行更精细的分层管理,使大模型能用上廉价、大容量的 CPU 内容,并确保 GPU 显存“好钢用在刀刃上”,在其擅长的动态并行计算中发挥出更大价值,最终在降低计算成本的同时保证关键信息不会丢失。其结果是当 MoE 的“专家”们再进行推理时,会像是配备了一位专门的助理,确保他们得到的信息及时、相关且准确。
DeepSeek-V4 的另一项底层创新,是其在训练中使用 的 mHC(流形约束超连接)技术。
V4 的参数总量达到了 1.6T,这种超大规模的神经网络训练,本身就是一个富于挑战的问题。传统的 Transformer 架构中,信息会在层层传递中呈指数级放大,模型参数量越大、层数越深,这种“信号爆炸”越严重,最终可能导致梯度爆炸,训练崩溃。
mHC 技术正是为解决“信号爆炸”现象提出,其核心思想是用严格的几何约束来控制信息流动,而不是放任自由连接。
这个防爆设计由三个环节组成。流形约束会把层间连接矩阵投影到双随机矩阵流形,强制规定每个节点的"输入总和"和"输出总和"必须守恒,具体的投影过程通过 Sinkhorn-Knopp 算法执行,两者共同把信号增益严格限制在合理倍数。最后的多流残差设计在扩展残差流宽度的同时,通过非负约束避免信号相互抵消,既能增强模型表达能力,又兼顾了复杂度和稳定性。
想象信息是一条奔腾的大河,多流残差拓宽了河道,流形约束和 Sinkhorn-Knopp 算法就是一道道闸门,三者的配合保证了大规模训练时的信息洪流不会引发梯度爆炸。
而 mHC 技术更深刻的意义在于,它和 MoE 架构、Engram 架构等技术共同为后 Scaling Law 时代的大模型扩展提供了一种可能的范式,也就是在参数规模、数据量的传统维度之外,转向追求更高的连接、参数和记忆效率。区别于前者的暴力美学,DeepSeek-V4 呈现了精致工程的魔力。
02
模型之争的工程转向
用流形约束防止信号爆炸的架构理论创新得以落地,离不开算子融合、选择性重计算、通信重叠等工程手段。参数量和稳定性之间的冲突曾经是制约大模型继续扩展的根本矛盾,而 mHC 技术对此的突破,建立在顶级的工程优化之上。
Engram 架构也有着类似的启示。内存访问如何精准配合 GPU 的计算过程,多级缓存需要什么样的精细管理……Engram 架构在 V4 上落地伴随的种种工程挑战,才是底层技术创新能否转化为模型能力关键。
智能的使用应有其边界,记忆管理的精细程度直接影响模型性能,这一范式重新诠释了对智能上限的追求。未来最聪明的模型,或许是最经济地界定了智能使用边界的模型。
DeepSeek-V4 问世之后,我们和应用爆发之间的距离或许又近了一大步。
原生多模态架构、百万 Token 上下文窗口纷纷走向成熟,背后是代码、法律和金融等场景的巨大想象空间。而 V4 所展现的顶级工程能力,和模型智能迭代逐渐放缓的背景合流,更便宜、可得的智能产品也会不断涌现。


一分钟的奇迹与幻觉:实测世界模型Happy Oyster

独家 | 华为19级天才少年赵立晨离职创业,瞄准具身 Agentic OS

未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。





