DeepSeek V4登场:百万token,价格打下来了
发布时间:2026-04-24来源:钛媒体AGI
DeepSeek-V4成为最强开源模型,紧追闭源第一梯队。
文|飞向TAI空
作者|胡珈萌
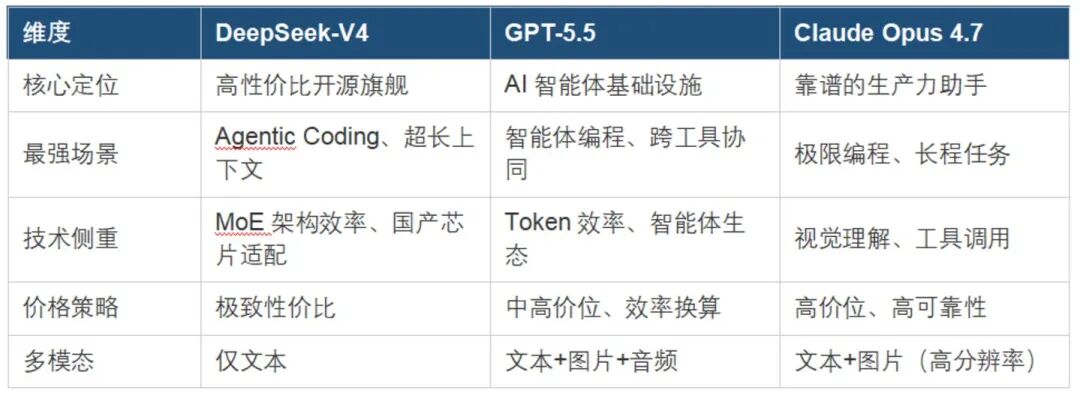
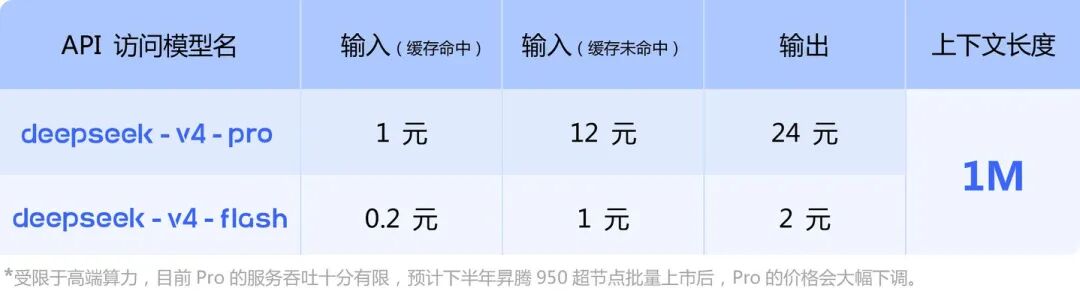
4月24日,DeepSeek通过官微宣布V4的预览版本正式上线并同步开源。在这一代模型中,DeepSeek推出了两个版本:拥有1.6T参数(49B激活)的Pro版本,以及284B参数(13B激活)的Flash版本 。而且,两款模型均原生支持100万token的超长上下文。与此同时,DeepSeek也发布了一份长达53页的技术报告,详细介绍了新模型的技术细节。为了体验新模型的能力与特质,我用网页版跑了下自己最熟悉的场景(读报告与写稿)。就体感来说,此前被普遍提及的一个问题——网页版快速模式与专家模式分层的效果不明显,从输出结果来说依然不分存在。虽然专家模式对报告的解读更细致,稿件体量更庞大,而且调用了很多外部信息,看起来十分努力,但如果从成文的立意、逻辑、华彩段落等评价来看,仍无法说与快速模式有质的差异。而在部分场景中,专家模式明显开启了“深度求索”模式,甚至“自己跟自己较劲”,花去大量时间解决看似不复杂的问题。快速模式则仍会相对快地处理各类任务。不过,问题是,专家模式是否能合理选择在什么情况下进行“深度求索”呢?目前,针对一些并不复杂的要求,比如将不同风格的文字进行统一等,专家模式可能会花费两分钟来输出一个不到200字的内容。而且,在目前的尝试中还不能确定其启动“深度求索”的契机和逻辑,但如果是追问,大概率专家模式要比首次提问耗费更多时间,体感上比V4更新前的时长差距更为明显。当然,仅从解读报告和稿件写作的角度,DeepSeek输出的结果(尤其是中文模型),看起来仍领先大多主流模型,V4更新后似乎能感觉出来其提炼能力、解读能力有所提升,明显错误则在减少。而这背后,与其在技术架构和Agent能力方面的探索也紧密相关。技术报告发布后,引起最多反响的当属V4对“长文本效率”的压榨。而在这背后,主要得益于其三大技术突破:混合注意力架构(CSA + HCA)、流形约束超连接(mHC)与Muon优化器。传统Transformer模型处理长文本有个致命弱点:文本长度每增加一倍,所需的计算和显存资源呈平方级飙升,就像要求一个人把整本书一字不差地背下来。V4的解法是“混合注意力架构”,它把两套技巧结合起来。其中,CSA(压缩稀疏注意力)对已读取的内容,只保留高度压缩的记忆缓存,并采用跳读式的稀疏计算,大幅省掉冗余运算。而HCA(重压缩注意力)则对相隔很远的段落间的关系,再做一次深度压缩,进一步削减显存占用。从技术报告给出的效果来说,在100万token下,V4 Pro的单次推理计算量仅为前代的27%,显存缓存占用仅10%。简单说,以前处理一篇百万字小说又贵又慢,现在可以经济实惠地日常使用。V4在架构层面的核心创新——“流形约束超连接(mHC)”,同样令人瞩目。该技术此前已于今年1月1日以论文形式发布。在目前市面上主流的大模型架构中,层与层之间传递信息就越像一场“传话游戏”——层数越多,原始信息越容易衰减和稀释。传统残差连接只能机械叠加,缓解有限。mHC对此的解题思路很明确,在特殊几何空间中约束信息流动的方向,让每一层都能更精准地汲取前面所有层的关键特征,而不是糊在一起。该技术此前已于今年1月以论文形式公开。从目前看到的效果来说,模型的训练稳定性与收敛速度的确得到了显著提升,等于为超大规模模型训练搭建了一条更高效、不易出错的信息通道。为了进一步加速训练进程,V4弃用了此前主流的AdamW,改用全新的Muon优化器,后者在收敛速度、训练平稳度上表现更优,特别适合超大规模参数。配合总量高达32万亿token的预训练数据,模型的能力边界被进一步拓宽。正是这套组合拳,使得即使是参数规模巨大的Pro版本,推理开销也降到了极低成本区间。目前看来,这将实质性推动长文档分析、复杂代码理解及多轮深度对话等应用从“能用”走向“好用”。在本次发布中,Agent能力被置于战略高度进行优化和评测。技术报告显示,为让模型具备解决真实世界中长周期、多步骤任务的能力,DeepSeek开发了一套新的后训练范式:先独立培养数学、编程、指令遵循等多个“领域专家”,再通过“在策略蒸馏(OPD)”合并为一个统一模型。报告称,V4-Pro在Agentic Coding评测中已达到开源模型最佳水平。DeepSeek官方发布的一系列硬核跑分数据也印证了技术路线的有效性。其多个指标超过或逼近了GPT-5.4、Claude Opus 4.5和Gemini 3.1 Pro等顶级闭源模型的水平。在一份针对内部85名研发工程师的调研中,超过一半的受访者表示,愿意让V4-Pro成为自己日常编程工作的首选模型。不过,技术报告也坦诚指出,在最广泛的世界知识与部分复杂Agent任务上,V4距最顶尖的闭源模型仍有约3至6个月的差距,这为下一阶段迭代明确了方向。值得注意的是,在V4发布前,OpenAI的GPT-5.5和Anthropic的Claude Opus 4.7也相继亮相。因为V4在技术报告中对比的还是前代产品,所以我们也结合三款最新模型进行了一次迭代对比。对比来看,GPT-5.5致力于做Agent时代的基础操作系统,其整体性能仍然称王,有强大的自主任务执行能力(能自主执行任务超7小时),但成本极高,输出每百万词元成本高达30美元。Claude Opus 4.7则仍在编程测试中折桂,定位偏向靠谱的生产力助手,最强场景式极限编程和长程任务,能解析2576像素图像并可靠运行长链路任务,但其价格仍然很高。而DeepSeek-V4则以约九分之一价格、标配百万词元上下文和唯一开源生态杀出重围,性价比最高,而且也依然是最强开源模型。不过,DeepSeek仍然没有集成多模态,仍然走在纯文本的道路上。这与前两者亦有了明显不同。从这三个模型的对比可以看出,大模型正在从“通用能力PK”走向“场景聚焦”。没有一款模型能搞定所有事情,每家都在找自己的主战场。对用户来说,这意味着选型逻辑要变了——不再是“哪个最强”,而是“哪个场景最适合我”。在DeepSeek此次发布V4的文章和报告中,有一个细节尤其值得注意。在给出模型Token价格的同时,DeepSeek附上了依据说明:受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。结合此前DeepSeek与国产芯片深度适配的相关信息,这句话背后隐藏着深远的产业信号。首先,它证实了国产大模型在“算力自主”上的真实困境与突破路径。目前Pro版本吞吐有限,反映出当前市场主流的算力资源(无论是存量的顶级芯片,还是替代方案)在应对V4这种超大规模Mixture-of-Experts(MoE)模型的推理请求时,仍面临显存带宽或通信延迟的挑战。其次,DeepSeek对“昇腾950超节点”的明确提及,实际上是对华为昇腾平台软硬一体适配能力的“背书”。在报告中,DeepSeek提到他们已经针对华为昇腾(Huawei Ascend)平台验证了精细化的专家并行(EP)通信方案。他们开发的MegaMoE2融合内核,通过计算、通信和内存访问的全重叠(Full Overlap),在昇腾平台上实现了1.5倍至1.7倍的推理加速。1、算力底座的切换完成:DeepSeek不仅在训练中使用了国产算力,更在推理架构上深度适配了华为的底层生态。这意味着,即便在全球供应链波动的极端情况下,DeepSeek-V4依然具备大规模部署的能力。2、“超节点”带来的推理革命:所谓的“昇腾950超节点”,其核心价值在于通过更高速的互联协议(类似NVLink)解决了MoE模型在跨卡通信时的巨大延迟。一旦批量上市,DeepSeek-V4那27%的单token FLOPs优势将转化为实打实的吞吐量,从而带动推理成本的直线下降。3、二次价格战的核弹:DeepSeek曾以“一分钱买百万token”开启了大模型价格战。而这次,随着国产算力效能的爆发,Pro级别的模型可能会降至目前轻量级模型的价格区间。这对于国内众多的SaaS公司和Agent开发者来说,无异于一场普惠的及时雨。通过此次发布来看,DeepSeek的模型迭代路线已较为清晰:它不再谋求参数规模的绝对领先,而是通过原创架构和系统级创新,在效率、成本与智能三者之间建立新的平衡。从某种意义上,这也标志着国产大模型从“追赶者”变成了“规则制定者”。当然,它也不是万能的。极限编程、长推理、多模态这些场景,Claude和Gemini仍然是更好的选择。随着模型权重登陆 Hugging Face 并向社区开放,V4 所承载的技术路径——高效长上下文、国产算力适配、Agent 原生优化——正在重新定义开源大模型的能力边界。至于这条路径能否最终通向AGI,或许要等待下一代模型才能给出新的答案。
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库