五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库新版本发布,DeepSeek再掀效率革命|甲子光年


更便宜、更快,向Agent和国产替代更进一步。
作者|卫琳聪 周悦
终于,DeepSeek-V4 来了。
距离上次版本发布已经过去近5个月,期间多次有DeepSeek新版本发布的消息传出,但都干打雷不下雨,等待的空气里不免泛起一些怀疑。
4月24日,DeepSeek-V4 预览版正式上线并同步开源,官方新闻稿里直接宣称“迈入百万上下文普惠时代”。
此次发布的版本包含两款MoE语言模型——DeepSeek-V4-Pro和DeepSeek-V4-Flash。
前者总参数1.6T、激活参数49B,后者总参数284B、激活参数13B,两者均支持一百万token 上下文。
如果单看百万上下文的能力,在V4之前市场上已有多款模型能够实现,国外如谷歌Gemini ,国内如阿里Qwen、月之暗面Kimi等。
DeepSeek-V4 令人惊艳的地方,是又一次带来效率革命,在性能提升的同时实现成本下降,尤其是让Agent更便宜成为可能。
更重要的是,V4为打破算力束缚提供了更大可能性,大模型的算力底座从英伟达向华为迈出了坚实一步。
1.转向Agent

DeepSeek官方表示,V4在Agent能力、世界知识和推理性能上均实现国内与开源领域的领先。
其中,DeepSeek-V4-Pro性能比肩顶级闭源模型。
在世界知识测评中,DeepSeek-V4-Pro大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1。在推理性能上,DeepSeek-V4-Pro超越当前所有已公开评测的开源模型,取得了世界顶级闭源模型相当的成绩。
不过,技术报告显示,最大推理强度模式DeepSeek-V4-Pro-Max性能仍略逊于GPT-5.4和Gemini 3.1-Pro,这表明其发展轨迹大致落后于最先进的前沿模型约3到6个月。
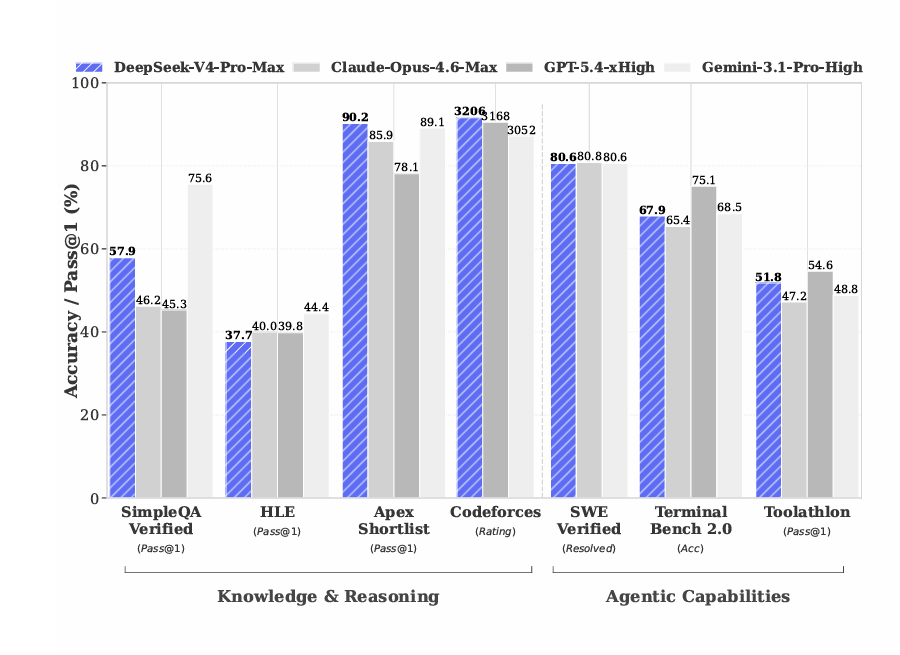
DeepSeek-V4-Pro-Max与同类模型的基准性能对比
值得注意的是,DeepSeek-V4-Pro的Agent 能力大幅提高。
在对DeepSeek-V4技术报告的深入分析中,「甲子光年」注意到,V4在更明显地转向Agent任务。从V3.1到V3.2,DeepSeek已经在强化工具调用和Agent能力,到了V4,这条线更清楚。
技术报告里出现了工具调用格式、推理内容管理、Quick Instruction、Agent沙箱基础设施,以及Search、White-Collar Task、Code Agent等真实任务评测。重点考察模型能不能在多步任务中低成本地调用工具、保留状态、继续执行。
在Agent 能力提高的同时,V4提供的价格相当实惠。缓存命中场景下,Flash版输入成本低至0.2元/百万Token。对于需要大量、多轮次Token交互的Agent应用来说,这无疑是降低成本的好消息。
能力提高、价格下降,毫无疑问,V4在瞄准Agent 发力,也将进一步推动Agent 的普及。
2.更便宜、更快
DeepSeek-V4系列此次表现出的最大特点,是在长上下文场景中极高的效率。
在1M上下文设置下,V4-Pro的单token推理FLOPs只有V3.2的27%,所需KV缓存空间也仅为其10%。
而参数激活数量更少的DeepSeek-V4-Flash则进一步提升了效率:在百万上下文中,其单token推理FLOPs仅为DeepSeek-V3.2的10%,KV缓存容量仅为7%。
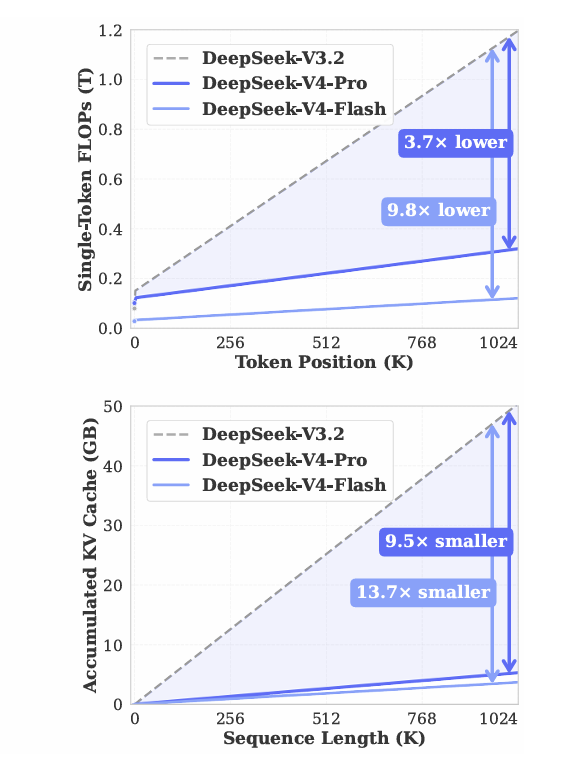
DeepSeek-V4系列与DeepSeek-V3.2的推理FLOPs计算量及KV缓存容量
基于这种进步,DeepSeek官方宣布,“从现在开始,1M(一百万)上下文将是 DeepSeek 所有官方服务的标配。”
这带来了什么?最直观的就是价格便宜。
处理一个Token所需的总计算量骤降,直接导致在云端处理每一条请求的电力、硬件磨损和运营成本都断崖式下降。这是DeepSeek敢于将API定价打到行业地板价。
DeepSeek V4-Flash输出价为2元/百万token,不到同天发布的GPT-5.5 Pro输出价(180美元)的千分之二。
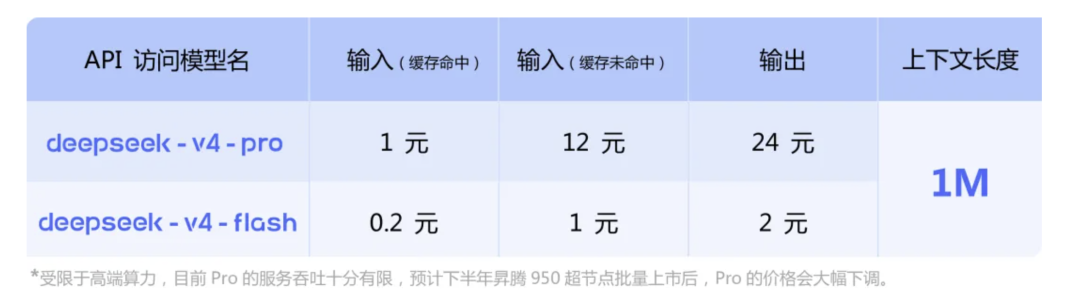
除了更便宜,模型也会更快。KV缓存占用降低,也有助于提升并发能力,并在一定程度上改善长上下文请求的响应效率。
让或许能让许多曾经“奢侈”的应用场景成为现实。例如,将整个代码库塞进上下文进行跨文件的“智能体编程”(Agentic Coding)、让AI进行长时间的自主规划与反思等。
效率的提高源自工程层面的创新。
「甲子光年」认为,在延续底层工程哲学的基础上,V4的重点进一步转向两个问题:一是如何低成本支持百万token上下文,二是如何让更复杂的模型结构和后训练流程稳定运行。
最核心的结构创新是混合注意力机制(Hybrid Attention),这让V4的长上下文效率大幅提升。
大模型在生成内容时,需要不断回看此前上下文。上下文越长,需要保存和调用的KV缓存就越多,每生成一个新Token时的推理开销也会随之增加。DeepSeek-V4的思路是,将长上下文分层处理,将压缩稀疏注意力(CSA)与重度压缩注意力(HCA)相结合。
具体来说,V4将压缩稀疏注意力(CSA)和重度压缩注意力(HCA)结合:CSA先压缩KV信息,再筛选与当前query最相关的部分参与计算;HCA则以更高压缩率保留远距离上下文的粗粒度信息。同时,滑动窗口注意力(SWA)处理近处上下文细节,弥补压缩机制可能导致的局部信息损失。
通俗地说,传统注意力机制更像把整本书逐页摊开,每次答题都重新翻一遍;V4则更像更像是一个智能索引,把近处内容保留原文,把远处内容压缩成章节摘要。
另一项核心架构创新是流形约束超连接(mHC),用于增强底层稳定性。混合注意力机制解决的是模型“怎么看长文本”,mHC解决的是模型内部信息“如何稳定传递”。
技术报告中提到,通过重计算、融合算子等工程优化,mHC带来的额外训练时间开销被控制在约6.7%。这表明它并非单纯的理论构想,而是适配V4大规模生产训练的实用设计。
DeepSeek对V4的架构很有信心,表示其性能可与GPT-5.2和Gemini-3.0-Pro相媲美,确立了其作为处理复杂推理任务的高性价比架构的地位。
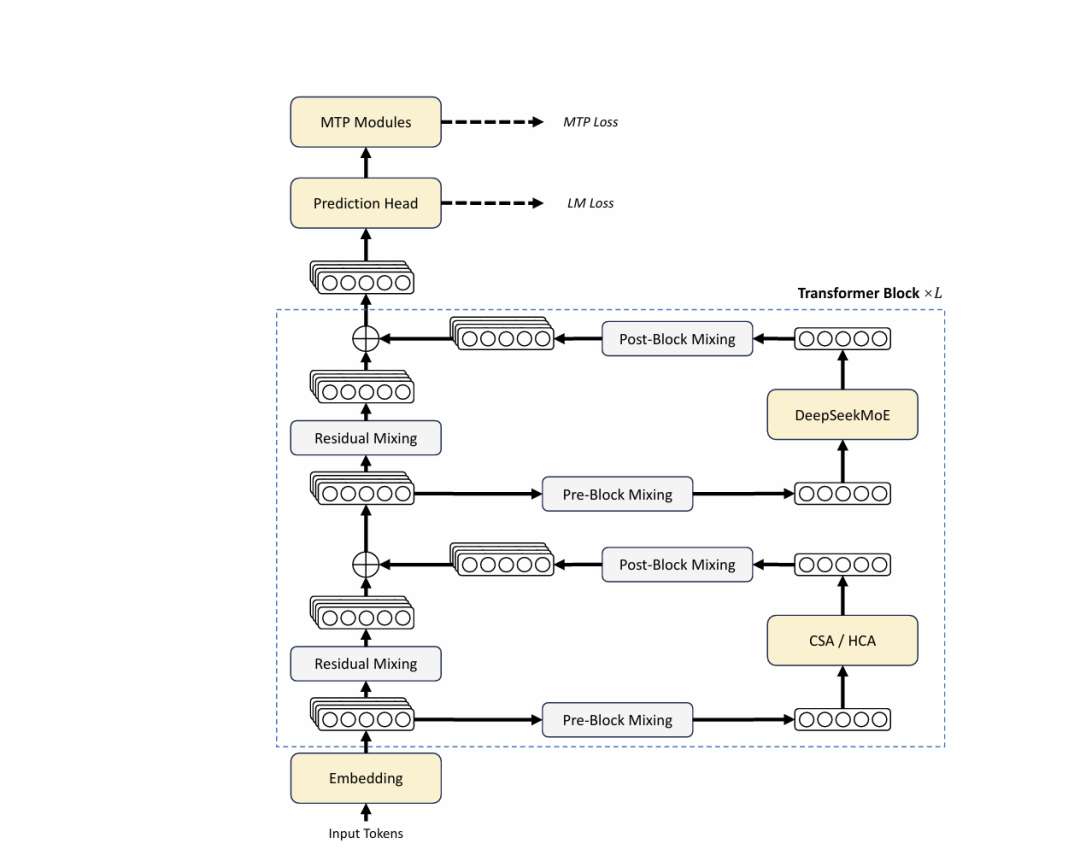
DeepSeek-V4系列的整体架构
3.加速国产替代
另一个值得注意的地方是,此次DeepSeek-V4与华为的关联更强。
技术报告中提到一个细节:DeepSeek的细粒度专家并行优化方案已经在英伟达GPU和华为昇腾NPU上验证。
并且,这套方案在通用推理负载中带来1.50—1.73倍加速,在强化学习采样和高速智能体服务等低延迟场景中最高达到1.96倍加速。
这并不等于V4全栈已经完全适配昇腾,但意味着昇腾950超节点对V4-Pro的意义不只是增加算力,也在于提升多卡协同能力。若后续供给和适配顺利,V4-Pro的吞吐和成本空间有望改善。
DeepSeek在V4发布的官宣文章中,用一行小字写道:预计下半年昇腾950超节点批量上市后,pro的价格会大幅下调。
另一方面,技术报告还提到,DeepSeek-V4系列的路由专家参数均采用FP4精度。虽然在现有硬件上,FP4×FP8运算的峰值FLOPs性能与FP8 × FP8运算相同,但从理论上讲,在未来硬件上其效率可提高三分之一,这将进一步提升DeepSeek-V4系列的运算效率。
据「甲子光年」观察,从V3开始,DeepSeek就没有单纯依赖参数规模,而是持续优化训练效率、显存占用和硬件利用率。在训练工程上,V4引入Muon优化器,并进一步使用FP4/FP8低精度训练。前者用于提升收敛速度和训练稳定性,后者用于降低显存、带宽和推理成本。
这可谓DeepSeek-V4 在技术选型上的一个“伏笔”:它在当前硬件上选择了成熟的 FP8×FP8 路线,但架构设计已为未来的 FP4×FP8 混合精度运算做好了准备,一旦硬件成熟,效率将立刻跃升。
这意味着 V4 未来有望在单卡上运行更大模型,推理成本也有望继续下降。
同时,基于DeepSeek的高效架构,即使国产AI芯片单卡算力绝对值不如英伟达等顶级产品,也能凭借其高吞吐、低显存占用的优势运行大模型。
这无疑进一步打破了算力束缚,国产替代的步伐加快了。
(封面图由AI生成,文中配图来自:DeepSeek)


END.