 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库11.5B参数、1.2EFLOPS、训练从数周压到数小时:他们把通用原子势训练带入Exascale时代
将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


在材料发现、催化设计、能源体系模拟、药物研发等方向,原子尺度模拟一直都是底层工具,但传统 DFT 计算成本极高,很难支撑大规模筛选。过去几年,机器学习原子间势虽然发展很快,但要真正做到「一个模型覆盖材料、分子、催化、MOF 等多个领域」,并不容易。
原因很直接:这类模型训练不仅要预测能量,还要通过自动微分严格求出原子力和应力,训练中需要二阶导数;同时,为了保证分子动力学的稳定性,又往往必须坚持 FP32 精度。二阶训练、高精度要求、超大原子图,这三重约束叠加在一起,让十亿级通用原子势的训练长期停留在「理论上可扩、工程上难训」的状态。
最近,来自中国科学院计算技术研究所的研究团队把通用机器学习原子间势(uMLIP)的训练规模推到了一个新量级,提出了十亿级通用原子势模型 MatRIS-MoE,以及配套的分布式训练框架 Janus,在两台 Exascale 超算上实现了 1.2/1.0 EFLOPS 的单精度峰值性能,并把原本需要数周的训练过程压缩到数小时。

研究论文:Breaking the Training Barrier of Billion-Parameter Universal Machine Learning Interatomic Potentials
论文地址:https://arxiv.org/pdf/2604.15821v1
兼顾物理先验与扩展性的模型架构
MatRIS-MoE 建立在 MatRIS 的不变架构之上,将原子体系表示为图结构,模型对原子、成对距离和三体角度进行嵌入外,还加入任务嵌入、charge/spin 嵌入和全局特征嵌入,将不同数据集、DFT 泛函和体系类型对齐到统一表示空间中。相比原始 MatRIS,它不再只是单任务势函数,而是面向多域统一建模的 universal MLIP。
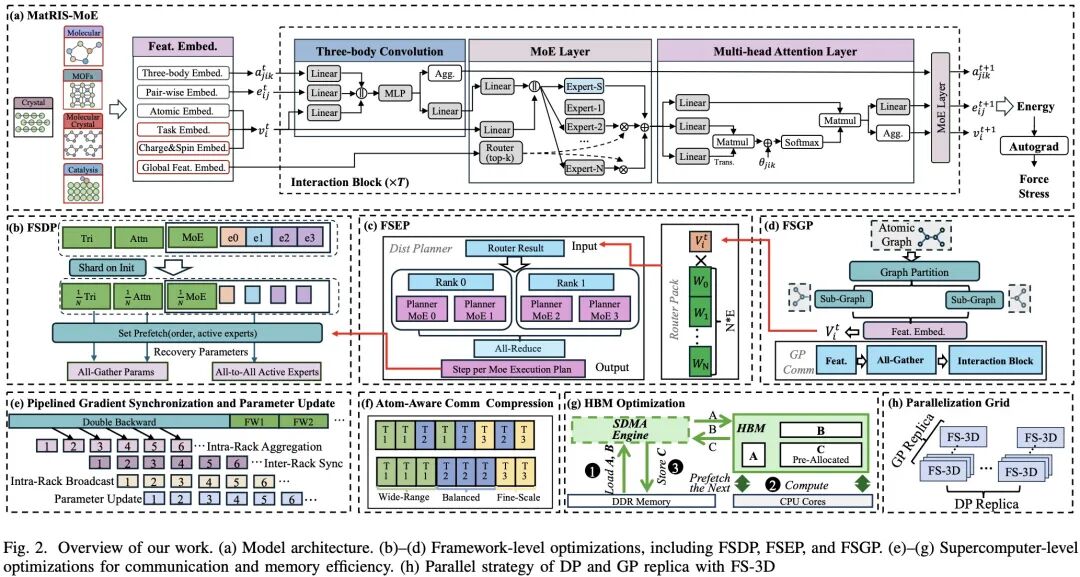
更关键的是,作者没有简单堆大参数,而是引入了 MoE。在 MatRIS-MoE 中,MoE 层被插入到注意力前后,分别处理消息构造和特征更新。其一个重要设计是:路由不依赖瞬时坐标,而是按元素类型进行 Top-K 专家激活。这样既能让不同专家学习不同元素和化学环境下的规律,提升跨域表达能力,也能保持专家激活稳定,从而有助于维持连续、平滑的势能面。
训练上,这项工作依然坚持「保守式」路线:模型先预测总能量,再通过自动微分得到力和应力,而不是单独开力头直接拟合,这对保证物理一致性很重要。同时,作者还设计了 multi-task robust loss,在每个任务内部统计 batch loss 的均值和方差,并对离群样本做平滑降权,以减轻异构任务之间的干扰。
兼顾 MoE 稀疏执行与二阶反传的训练框架
如果说模型解决的是「怎么表达」,那么 Janus 解决的就是「怎么训练」。
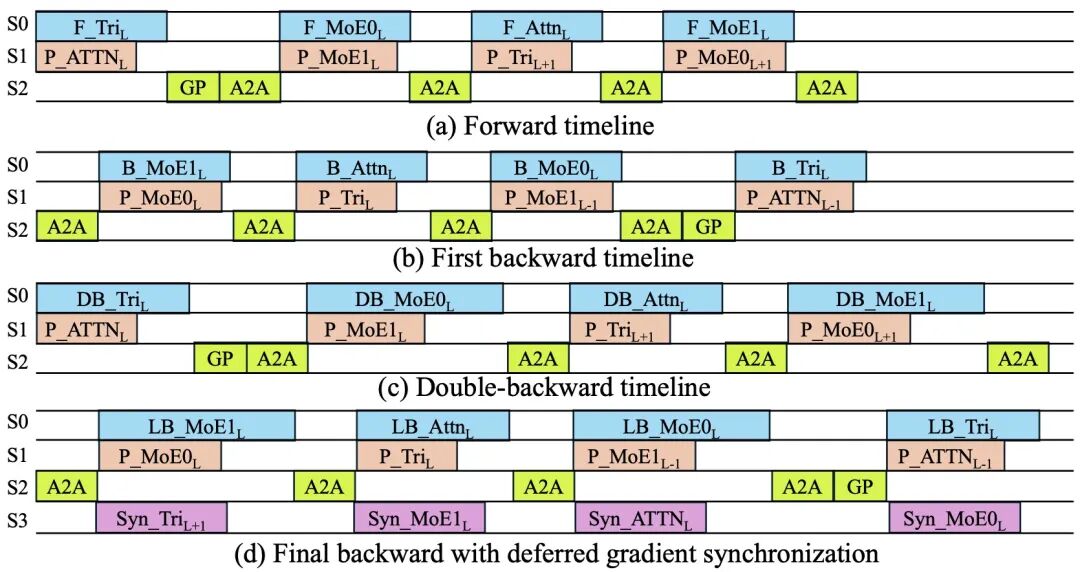
Janus 的核心是一个叫 FS-3D 的统一执行单元,把 FSDP、FSGP 和 FSEP 三种并行机制揉到了一起。简单说,FSDP 负责切参数,降低模型参数、梯度和优化器状态的静态显存占用;FSGP 负责切图,把一个大原子图划分到多张卡上,降低激活开销;FSEP (以 LAER-MoE 为基础) 则专门面向 MoE,把专家参数分布到不同设备上,只在需要时恢复活跃专家。对于既有超大图、又有 MoE、还要做 double backward 的 uMLIP 来说,这种三维统一分片的设计,是这篇工作的关键工程创新之一。
为了进一步解决 MoE 的低效问题,作者还提出了 JIT planning。传统 MoE 训练往往会保留很多当前 step 根本用不到的专家;作者利用体系静态属性决定专家激活的特点,在每个训练 step 开始前,先对所有 MoE 层做批量路由,统计各专家 token 负载,再基于负载做局部规划和全局合并,只恢复当前真正活跃的专家,并按负载尽量均衡地放到不同 rank 上。
更难的是,uMLIP 训练不是普通的一次前向一次反向,而是包含 前向、一次反向、二次反向三个阶段。Janus 为此专门实现了一个「二阶训练大模型」的运行时系统:参数按需恢复,前向阶段记录执行顺序,后续阶段复用顺序做 prefetch 和 overlap,梯度同步则延迟到最终反向再进行。
结果与展望
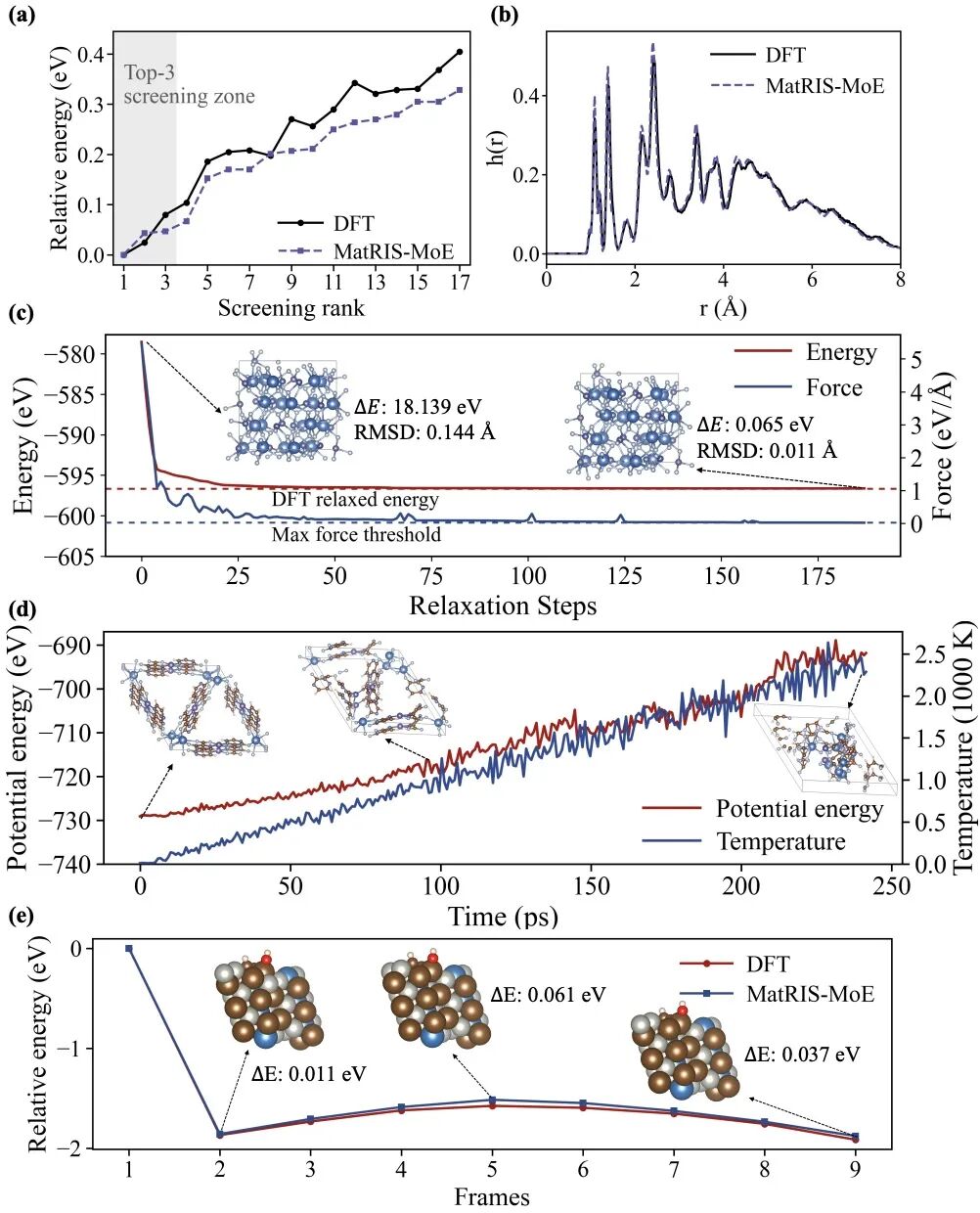
结果也确实够亮眼。论文使用了覆盖分子、材料、催化表面、分子晶体和 MOF 的 4.73 亿个原子构型,对应约 3.6 万亿条边;最大模型规模达到 11.5B 参数,2.89B active parameters,支持处理多个领域的科学任务。最终,在两台 Exascale 平台上,系统实现了超过 90% 的弱扩展并行效率,峰值达到 1.2 EFLOPS,把十亿级通用原子势训练第一次真正推到了超算级可用的阶段。
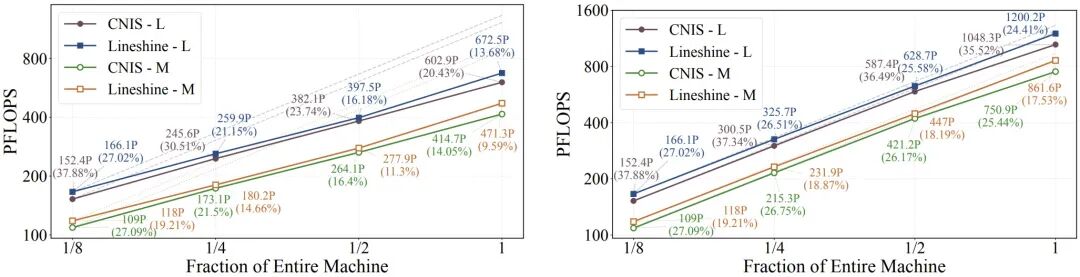
从这个角度看,这篇工作真正重要的地方,不只是「把一个模型训到了 11.5B」,也不只是「跑到了 1.2 EFLOPS」,而是它证明了一件事:通用原子势也可以像大模型一样,被系统化地扩展、训练和部署。
对 AI for Science 来说,这可能比单点精度提升更重要。因为从这里开始,通用原子势不再只是论文里的 benchmark 选手,而是在向真正的科学基础设施靠近。
作者介绍
中国科学院计算技术研究所及中国科学院大学周远昌、王宏宇、杜奕明、汪焱、李明真、胡思宇为本文共同第一作者;中国科学院计算技术研究所贾伟乐研究员为本文通讯作者。贾伟乐 2020 年获国际高性能计算应用领域最高奖戈登贝尔奖,2022 年再次入围该奖项;相关成果入选两院院士评选国内十大科技进展新闻,并获得中国超算年度最佳应用奖及中国计算机学会高性能计算青年科技人才奖等多项荣誉。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。





