五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库Z Tech|对话王子涵:离开DeepSeek,我人生的逆向思考


01 导语
很多人知道王子涵,是从Twitter上开始的。
当时随着DeepSeek R1、V3的相继发布,西方技术社区第一次大规模感知到这家中国公司的存在,也由此将目光投向了站在一线的研究者,这位年轻研究者的推特账号突然涌入大量关注。他至今还记得,当时西方从业者对DeepSeek的震撼,就像目睹了一种“来自东方的神秘力量”,甚至还流传着不少有趣的传言,连梁老板的照片都被传错,至今没更正过来。
最初,他只是想做一件简单的事:把真实情况讲清楚:讲DeepSeek是如何做研究,团队的工作方式,和那些被忽略的技术细节,希望尽可能在信息失真之前,提供一个更接近一线的视角。巧合的是,昨天准备访谈内容时,遇上了DeepSeek V4的发布,王子涵早期在DeepSeek的亲身经历,也补充了更多关于这家神秘公司的更多一手信息。
但比起这段略带偶然的“走红”,更能定义王子涵的,是一条更早开始、也更稳定的技术路径——他对Agent system的持续探索。
他进入中国人民大学开启计算机研究的时间点,恰好处在一个“前范式”阶段:GPT-2已经验证了生成式架构的潜力,但学界与工业界的主流重心,仍然停留在以BERT为代表的非生成式范式之上——围绕分类、信息检索、表示学习与任务拆解不断深化。也正是从那个阶段起,他沿着一条清晰却不张扬的技术路径持续推进:从推荐系统与信息检索算法出发,延展至Berkeley的强化学习交流项目,以及与UIUC合作开展的MINT Agent benchmark研究;随后进入DeepSeek,围绕MoE模型中的专家Specialization(专业化)展开深入探索,并在此后的博士阶段,将问题进一步下探至Agent强化学习的底层机制,持续追问其能力边界与实现路径。
与许多从大模型能力出发进入这一领域的研究者不同,他的起点更朴素:一个AI系统,是否可以像人一样,在没有持续外部指导的情况下,自主学习、自主改进?
在这一问题之下,他引入马尔可夫决策过程MDP(Markov Decision Process )来抽象Agent的决策闭环:状态(state)、动作(action)、转移(transition)与反馈(reward)共同构成一个自洽的系统。但他的兴趣并不止于传统强化学习对“策略优化”的关注,而是一个更具挑战性的主题——构建真正理解世界的Agent,在行动发生之前,就已经在内部完成了对未来的预演与模拟。
这也成为他后续所有工作的起点。作为直博二年级学生,他已在NeurIPS、ICLR 、CVPR、EMNLP等AI顶级会议上发表十余篇论文,google scholar citation 1600余次,并包揽NeurIPS LAW outstanding paper,ICCV SP4V best paper等荣誉。无论是最早探索的 Agentic scaling law,还是之后持续推进的RAGEN 1/2,VAGEN,MindCube等框架,核心都指向同一个问题:如何让Agent的决策,从“对输入的响应”,转变为“基于世界演化的判断”。
图为RAGEN 1,受访者提供
在这次对话中,我们试图回到这些问题的起点:从他最早的研究经历出发,穿过在DeepSeek的一线实践,再到他当下对Agent的系统性思考,去还原他个人的研究与探索是如何一步步展开的。以下为Z Potentials与王子涵的对话实录,Enjoy!
Z Highlights:
后来慢慢发现,很多看似高深的idea可能只是包装,甚至在复现实验时会发现根本跑不通。我开始具备辨别能力,能看出哪些工作外表华丽、公式复杂,实则并不成立。我产生了一种逆向思考:既然有些看上去高深的领域未必如此,那一些看似比较工程化的领域,会不会反而也没有那么简单,做出来一篇工作也需要很多的努力?
我当时特别感慨,怎么会有研究员密度这么高的公司。之前待过的地方,200个人里能有10个专职研究员就很不错了,但在DeepSeek,这200人里几乎多多少少都在做研究相关的事。就算不是专职研究员,每天也会在群里分享最新的大模型进展、大厂动态,连HR都会转发相关新闻,氛围特别不一样。
还有一件事让我印象很深,当时在DeepSeek有位做infra的前辈,我第一次提交代码时,前辈逐行帮我修改,每一行都能找到优化空间。比如通过in-place操作避免重新克隆张量。我觉得so amazing。
之前有人问我:到底什么才是Agent?我觉得,一个东西算不算 Agent,取决于它被放在什么样的Physical或Digital环境里。给它完全开放的计算机环境,它就是OpenClaw;给它受限计算机环境,它就是Claude Code 或 Codex;只给一个聊天界面,它就是GPT。环境的开放程度,决定了Agent从0到1的智能指数。
很多任务的设定都是给你一笔钱,把任务做得越漂亮越好。但更重要的是:一个真正具备资源适应能力的人或Agent,给他一万块能做出一万块的效果,给他一百万就能做出一百万的效果。我们希望打造的,就是这种高度自适应资源约束的 Agent。
02 从人大IR到伯克利RL:“没有人脉,就从Office Hour突围”
ZP:欢迎子涵,先从你早期的科研经历聊起吧。在人大读书初期,什么样的契机开始接触AI领域的?当时有哪些特别的故事吗?
王子涵:我接触AI比较早,2020年读本科,2021年初就开始正式做AI相关科研。这得益于人大的培养模式:大一上不分专业,所有理科生一起上课,选课自由度很高,学校也开了人工智能、统计学这类课程。那段时间我其实更偏向统计学,当时国内也普遍认为本科应该打好数理基础,多学数学和统计。
但我不想只走统计一条路,于是主动联系了人工智能学院的老师,进入课题组做研究。那时GPT-3已经有了,但对文本生成模型的研究远不如非生成式模型(如BERT等)多。我在组里主要做推荐系统和搜索算法,用比较基础的DPR、RAG做QA任务。坦白说那段科研很枯燥,没有生成能力,很多事情都要靠人工精细设计。比如做QA要从原文里抽span,做conditional QA还要抽条件特征,把condition和answer一一对应。虽然做法很传统、很手工,但我已经初步感受到了AI的意义——我们的AI模型在现实生活中的应用逐渐转向自然语言,相比于隔壁做SVM的传统结构化数据方向已经要广得多。
ZP:刚进入AI领域,你的选题或研究方向基本上是组里的导师安排吗?
王子涵:我选的导师在人大AI学院口碑好,学生去向也不错,最初更多是凭口碑和感觉选的。方向后来也有变化,最开始做的是信息检索(IR)。这个项目做完之后,萌生了出国的想法,大二申请了大三去Berkeley交换。
之后方向就换了好几次。回头看本科阶段,最有意思的还是那段IR的科研经历。我们有一篇投CIKM的工作,核心是:能不能用生成模型做信息检索?当时我们尝试让GPT逐个生成文档对应的token,每个文档对应一串token,做推荐或搜索时就让模型生成这串token,匹配到哪个文档就返回哪个。这里面的困难点有点类似早期GPT的幻觉——让它引用文献,它会编出不存在的条目。为了解决这个问题,我们提出了约束解码的方法,给模型限定一个文档库,强制它只能在库内的token序列中解码,确保生成结果精准指向库内文章。
ZP:在整个海外学术交流的过程中,你收获了什么?
王子涵:伯克利的经历让我变得非常独立。我认识的学长里只有一个去过伯克利,还是数学方向,和我完全不相关,没有任何经验可以参考。刚去时人生地不熟,甚至不觉得自己能找到教授做科研。
没有现成人脉,我就从上课找突破口。选课可以利用老师的office hour直接交流,也有机会跟着学习。我当时选了Sergey Levine的强化学习课,每次下课都主动去问问题。课程大作业让我印象很深,那时开始用OpenAI Gym,我觉得RL特别有意思,这也是后来我兜兜转转还是回到RL的原因。在我看来,RL和SFT的区别在于,它让模型具备自我进化的可能,就像AlphaGo到AlphaZero那样。课程大作业允许自主选题,我关注到OpenAI的VPT(Video Pre-training)工作,让模型通过观看视频学习动态模型,像人看游戏直播学操作一样。我在一个简化的2D类Minecraft环境里实现了一个低配版,效果还不错,那门课也拿到了满分。
当时还处在探索阶段,对这份满分作业挺满意的。但我也意识到不能只停留在课程层面,我看到有同学把课程作业改成论文并成功中稿,觉得很受启发。
我跟Sergey提出想做科研,他把我推荐给一位学长,但聊下来发现方向兴趣不太匹配。此后也尝试接触了一些其他组,Berkeley校内和校外的都有,有一些也认真做了一段时间,但有很长一段时间都没有真正做出来收尾的项目。
一开始我觉得科研是很神圣的事,要钻研宏大概念或高深想法。但后来慢慢发现,很多看似高深的idea可能只是包装,甚至在复现实验时会发现根本跑不通。我开始具备辨别能力,能看出哪些工作外表华丽、公式复杂,实则并不成立。我对科研也不再像大一大二那样抱有仰望心态,更多以观察者的视角去看待别人的工作。
这种心态一直持续到申请暑研。我产生了一种逆向思考:既然有些看上去高深的领域未必如此,那一些看似比较工程化的领域,会不会反而也没有那么简单,做出来一篇工作也需要很多的努力?
那时我找到了UIUC的导师季姮和Mentor星尧,他现在在All-Hands AI做Coding Agents创业。我们当时聊要不要一起做一个benchmark。很多人觉得benchmark简单、不够“性感”,但经过之前的思考,我意识到看似简单的事情背后也需要极强的严谨性,比如搭建分类体系、定义能力维度、编写大量严谨的test case。我那时才明白,做benchmark本身也不是一件容易的事。
我是2023年3月找到他的,当时他就提议,我们可以一起做Agent benchmark。
ZP:那个时候,关于Agent大家理解是什么样子?
王子涵:2022年底ChatGPT出现,很多人第一次意识到AI可以流畅对话,但很少有人进一步去想:AI除了聊天,是否能主动操控现实世界中的工具?它自己生成的token,能不能转化为真实行动,并在执行后读取环境反馈?当时大家的思维惯性非常强,之前做QA还普遍在用BERT抽特征,从这种惯性里跳出来,其实是一件很有挑战的事。
我们刚开始筹划做Agent benchmark时,正好Meta在2023年2月发表了Toolformer,算是当时最前沿的Agent相关工作之一。它定义了日历、计算器等5个工具,让Agent完成简单数学题之类的测试,虽然提出了基本的tool use思路,但并没有形成一套系统化的benchmark。
于是我们就在思考:既然大家都看到了Agent的潜力,下一步该怎么做?我们意识到,Agent在与世界交互的过程中,有两类核心资源至关重要:一类是工具(tools),另一类是人类。
当时ChatGPT也在推进工具能力,我们便设想了一种工具+人类反馈的Agent架构,和后来的TauBench思路比较接近:让Agent能够调用一系列工具,并结合人类反馈持续优化决策。这两类反馈的本质截然不同:
来自工具的反馈是可验证的客观事实,比如查询、计算结果,Agent应该直接当作真实依据使用;
来自人类的反馈则更嘈杂,比如用户会指责、表达不清,甚至需要Agent反问才能明确意图。

图为MINT benchmark框架,受访者提供
基于此,我们构建了一个融合tools + Agent + simulated user的基准测试。这项工作在暑研结束后完成,大概2023年9月左右发布。从那之后,我就开始系统地深入研究Agent相关方向。
ZP:当时的能力做Agent还是过于困难,模型的tool calling能力比较弱,也没有像样的推理,所以包括多Agent这类框架基本都很难落地。
王子涵:尤其当时没什么合适的任务能给Agent用,整体能力还支撑不了复杂场景。最后能做的基本也就是RAG和代码相关,让模型自己写代码、过验证器,再根据返回结果迭代。现在看,纯文本Agent最主流的场景也还是这两类:搜索Agent和代码Agent。
ZP:从2024年到现在,你观察到benchmark已经趋于饱和了吗?
王子涵:那个阶段其实条件很有限,当时连GPQA这种研究生级别的问答基准都还没有,主要用的还是HotpotQA、TheoremQA,以及代码类的HumanEval和MBPP。以现在的眼光看,当年这些数据集上的任务,如今的Agent基本都已经做得比较成熟了。这两年多时间,变化确实非常大。
03 王子涵亲历:200人的DeepSeek,代码一行一行改,HR都在分享模型进展细节
ZP:在这之后你大三结束进入DeepSeek,对你来说是一个怎样的开始?是什么样的故事让你进入DeepSeek?
王子涵:从UIUC暑研回来后,我就开始申请PhD。很幸运,我拿到了UIUC学姐曼玲在西北大学课题组的offer,之前和她聊过,彼此方向、风格都很合得来,之后就正式申请并确定了去向。
敲定PhD之后,我有一个类似gap的学期,那段时间心态很轻松,方向已经定了,不用再背负各种不确定性,于是就开心地投了简历。
当时我只投了两家公司:一家是DeepSeek,另一家是创业公司,两边都给了offer,最后我选择了DeepSeek。过程其实挺顺利的,我也没海投,就想着随缘试试,没中就大四下半学期好好玩,放松一下,不过最后面试一路比较顺利。
DeepSeek给我的感觉很不一样,他们不是在考八股面试,而是结合我的研究经历和公司的技术方向,问非常针对性的问题,后来我发现DeepSeek很多同事都是这种风格。这家公司会高度定制化面试,说明他们对每个候选人都很用心,至少会提前看你的简历、你的研究、你在做什么。这种感觉和我当时PhD面试很像:他们关心的是你这个人,希望你进来之后能落地一个具体的科研项目,而不是随便安排杂活、干完了事。正是这一点打动了我,于是我就加入了。
ZP:在那个阶段,DeepSeek还是一个不那么封闭的地方。现在基本上都不怎么招短期的intern。当时人多吗?规模如何?
王子涵:当时公司大概就200人。我当时特别感慨,怎么会有研究员密度这么高的公司。
之前待过的地方,200个人里能有10个专职研究员就很不错了,但在DeepSeek,这200人里几乎多多少少都在做研究相关的事。就算不是专职研究员,每天也会在群里分享最新的大模型进展、大厂动态,连HR都会转发相关新闻,氛围特别不一样。
ZP:你在DeepSeek里面主要是干了什么?有做自己的research,还是说主要是参与主流model的training和inference?
王子涵:都有做,主要是两项工作,一个是V2的开发,另外一个是expert specialization tuning。
V2属于新模型研发,公司员工都参与其中,大家当时也日常使用这个模型。我会重点观察模型的输出逻辑与流畅度,若出现问题,会进行归因并提出反馈。这部分工作更偏向工程方向,当时我更多是抱着学习的心态,毕竟公司里前辈众多,强者如云,学到就是赚到。
从V1到V2的迭代,是一个多想法碰撞的过程。外界看到的核心成果可能只有MLA架构和更精细的专家切分,但内部实际涉及架构优化、训练后调优、数据收集等多个环节。每天都能接触到各类创新思路,这是非常好的学习机会。通过与同事交流模型设计逻辑,我也积累了大量模型研发直觉,比如关注哪些指标、特定代码对模型性能的潜在影响等。
还有一件事让我印象很深,当时有位做infra的前辈,我第一次提交代码时,前辈逐行帮我修改,每一行都能找到优化空间。比如通过in-place操作避免重新克隆张量。我觉得so amazing。
我自己负责的项目更具探索性。当时公司正逐步迁移到MoE(混合专家模型),核心需求是解决MoE模型的专业化微调问题。当时行业内与微调相关的工作,基本都采用LoRA及其变种,核心是通过矩阵分解压缩参数,无需调整全部参数。这种方式虽能实现目标,但应用在MoE模型上时,我们发现了可优化空间。
MoE模型本身自带显性的专家结构,而LoRA之所以只需少量参数,核心是通过少量参数撬动模型中与任务相关的局部参数,本质也是在寻找对任务有效的参数分解。而MoE的专家结构,恰好提供了这种显性分解。我们在前期试点研究中发现,DeepSeek 坚持的细粒度MoE,其专家分化程度远优于当时市面上部分论文中采用的“八选一”专家结构——不同任务所激活的专家完全不同。当时,我产生了一个想法:既然微调的核心是更新参数系数,那能否直接定位到与任务最相关的专家,对其进行针对性微调?这一思路最终形成了我们的ESFT论文(发表在EMNLP 2024)。
其实当时我是围绕需求找解决方案,那时候就深刻体会到,只要有明确的需求,基于需求撰写论文会非常高效。之后我所有写得快的论文,都是遵循这个逻辑——发现一个未被关注的核心需求,然后针对性地落地解决方案,这和单纯花费大量时间打磨细节、雕琢形式的体验完全不同。
从这项工作本身来看,通过针对性微调相关专家实现参数更新,有两个核心优势。一是能节省显存资源,二是能降低MoE模型中不相关专家的噪音,提升训练的信噪比。如果强行让不相关的专家去拟合当前任务,会导致模型在其他任务上的性能出现断崖式下跌。而我们的方法,能在微调新任务的同时,让模型在原有任务上的性能几乎没有下降,核心就是没有干扰到不相关的专家,也避免了模型过拟合到单一任务。
ZP:所以MoE是DeepSeek很早以前定下来的的方向,他们是怎么样定出来的?毕竟当时除了MoE的混合专家架构,千问、GLM、Llama等早期模型都是稠密模型,只有GPT-4采用了MoE架构,DeepSeek为什么能早早判断出MoE是未来的发展方向?
王子涵:我认为核心是“实验出真知”,DeepSeek 内部的实验做得极其严谨。我在那里学到一个重要理念:仅仅自己相信某个方向是不够的,还要为相反的观点留出充分的辩论和验证空间。哪怕团队主观上已经非常认可某个结论,还是会做大量消融实验,假设反方观点成立,去验证其可行性、寻找潜在问题。
我自己做ESFT(专家专业化微调)相关论文时,就深刻体会到了这一点。哪怕我已经非常确定自己的方法是可行的,我的 Mentor 还是会不断追问我:如果这个方法不可行,问题会出在哪里?之后我做了大量消融实验,反复验证、确认方法的有效性后,才最终将其整理成论文发表。我们做核心实验的时间其实只有一个月,但做消融实验、严谨打磨论文的时间要长得多。
DeepSeek就是这样,对待每一个技术方向都极其严谨,会全面测试各种组件和特性,只有经过反复验证、确认切实可行,才会确定其方向。我觉得正是这种严谨的实验态度,让他们早早判断出MoE是未来的核心方向
ZP:在我的印象里,DeepSeek也是比较早提出细粒度MoE(fine-grained MoE)理念的,稀疏比达到1:32,比八选一、四选一的架构更加稀疏。这种设计可能属于不同的MoE架构思路,也可能是工程驱动下的选择。V2项目之后,你相关的MoE研究成果,最终有应用到模型的最终方案里吗?还是说目前仍停留在研究阶段?
王子涵:这就不得不提到训练后调优(post-training)的相关工作了,其实这里面涉及两个方向。第一个方向类似现在的Thinking Machine Labs,核心是基于大模型,为客户定制小型模型,以API的方式定制做训练优化和部署服务。当时OpenAI、字节等公司都已经上线了类似的微调功能——他们提供模型基座,用户无需了解底层架构,只需基于基座进行训练,就能得到定制化模型。但等到DeepSeek V3推出时,公司的优先级更侧重在提升模型能力方面,所以定制化方向的商业化这件事的优先级就被调低了。

图片由受访者提供
第二个方向更具探索性,核心不是让下游用户去定制、训练模型——虽然我们已经实现了微调新任务时不影响原有任务性能这一优势,但我们想进一步探索:能否将不同任务根据其性质,分配到不同的任务组,每个任务组内部的任务需要的能力较为相近,而针对每一类任务组,只微调其最偏好的专家。这样一来,在训练任何一个任务时,都能减缓“跷跷板效应”——比如训练任务a时,导致任务b的性能下降,进而需要反复训练所有任务。当时这个思路已经明确,但因为我在西北大学已经开学了,无法在 DeepSeek继续进行全职工作,就没能继续推进这项研究。
ZP:你有没有想过推迟入学半年,继续留在公司工作?比如等到V3项目结束。
王子涵:当时我确实考虑过留下或离开这两种选择。之所以最终选择去美国读博,很大一个原因是,美国曼玲老师课题组的研究方向,是我当时在国内完全接触不到的,包括VLA、机器人技术以及各类多模态相关内容。
我当时觉得多模态领域非常有吸引力,因为在国内,我能接触到的课题组里,很少有专注于多模态研究的。这其实是一个方向上的选择,我本身就很喜欢探索新领域——本科期间因为各种原因,我也换过很多研究方向,中间还做过LLM人格个性化相关的工作,虽然最终没有产出论文,但那段探索经历也让我收获很多。所以当时选择读博,核心还是出于对研究方向的考量。
ZP:没有记错的话,还有一个小插曲——R1和V3推出后,你在推特上受到了很高的关注。那段时间具体是什么情况?
王子涵:那段时间最深的体会是,西方业界人士了解到DeepSeek后,产生了很强的震撼感,我很难用恰当的语言形容,大概就像他们目睹了一种来自东方的神秘力量。当时还出现了很多我从未听过的传言,甚至到现在,还有不少人在推特上发布的梁老板照片都是错的,一直没有更正。
当时我有很多想分享的内容,比如想跟大家真实展现DeepSeek的工作状态,以及我感受到的公司情怀和核心价值。一开始还想着帮公司宣传一下,因为我加入时,公司的推特粉丝大概只有1万左右,但后来公司的影响力逐渐提升,完全不需要我再做宣传了。
其实我很小的时候就喜欢在B站发视频,当我对一件事有强烈表达欲时,往往能激发很多灵感,包括一些想法和有趣的梗——这些梗既能自己乐,也能让别人会心一笑,笑过之后还能引发对相关问题的思考。那段时间在推特上,我聊得最多的是开源相关的话题,虽然现在行业整体还是逐渐走向闭源,但当时能为开源做一点小小的抗争,那种感觉还是很有意义的。
ZP:DeepSeek给我的一个印象是,它在infra层面的能力很强,也比较强调infra与algorithm之间的协同。他们在写paper的时候,也会比较细致地展开算子和调度这些实现层面的内容。在这样的环境里,你有没有受到一些影响?
王子涵:最典型的例子就是我刚才提到的,我第一次提交代码时,我的导师逐行帮我修改,每一行都能找到优化空间。其实对比当时市面上其他MoE模型,哪怕是DeepSeek开源的V2版本代码,其推理部分也只比其他的模型有10到20行代码的改动,但这每一行都是精心设计的。即便不了解公司内部情况,单看开源版本,其质量也非常出色,计算效率远高于当时市面上的其他模型。
这其中就涉及到infra层面的细节优化,比如计算图如何计算梯度、梯度如何回传、怎样实现最优通信、如何通过减少张量创建来节省资源等。我觉得这种文化最核心的是一种资源预算意识——在资源有限的情况下,如何做出最优决策。其实我加入时,公司的资源是很充足的,200人配备1万张显卡,这是我本科时完全无法想象的,但后来也意识到,要训练一个超级大模型,1万张显卡依然显得不足,这也更凸显了infra优化、资源高效利用的重要性。
ZP:非常巧合的是,我们稿子发布的前一天,DeepSeek发布了V4,你怎么看这次的新发布?
王子涵:我对模型和技术路线等没有什么特别想说的,我觉得他们一直都走在正确的道路上。但我非常喜欢V4发布公告里的一句话:「不诱于誉,不恐于诽,率道而行,端然正己。」对任何一个研究者而言,坚持做自己觉得正确的事,保持前进的步伐平稳,踏实地去验证每一个假设,让外界噪音的影响下降到最小。这个方向,就是前进最快的方向!
04 Agent System:环境开放程度决定智能上限,而非算力或数据规模
ZP:你从很早以前就开始想做Agent system,最开始加入西北大学读PhD做的project,你想解决什么问题,进展怎么样?
王子涵:我做Agent相关项目的核心初心,是希望Agent能自主学习、无需人刻意教导。这受我成长经历影响,父母一直引导我自主学习,也让我更倾向于RL思路,我始终认为最终形态的RL会相对现有"生成体验+梯度下降 (experience + gradient descent)”模式的形态有较大改变,核心是让模型实现自主提升,也就是后来大家说的 self-evolving 。
我做的第一个相关研究是Agent缩放定律(Agentic scaling law),当时我们将Agent抽象为包含状态(state)和动作(action)的马尔可夫决策过程(MDP)。核心思路是,判断Agent是否理解世界,不能只看策略(给定状态s输出动作a),而要能对MDP任意环节“完形填空”,挖掘其世界建模能力——比如通过动作预测下一状态、通过状态与后续状态反推动作,这也是我们实验室目前推进工作的核心逻辑,比如VAGEN(Vision Agent, NeurIPS 2025) 本质就是这种完形填空思路的落地。
起初我尝试设计统一的完形填空框架但未成功,后来调整思路,决定循序渐进先做好策略。读博后,我发现Verl框架可应用于Agent构建,便做了简单的概念验证(PoC),由此诞生了RAGEN。第一版RAGEN未做过多工程优化,效率不及同期的SGlang,我也意识到工程优化的重要性,后续首要任务便是攻克这一难点。
RAGEN初版于去年1月27日发布,巧合的是,今年1月27日的RAGEN一周年纪念日,也是DeepMind的AlphaGo论文发布10周年。在过去的一年里,我经历了多次研究失败,也总结出了新的研究论点,目前正基于这套论点重新定位,开展新的探索,初代RAGEN也是我刚到西北大学第一个学期的核心工作。
图片由受访者提供
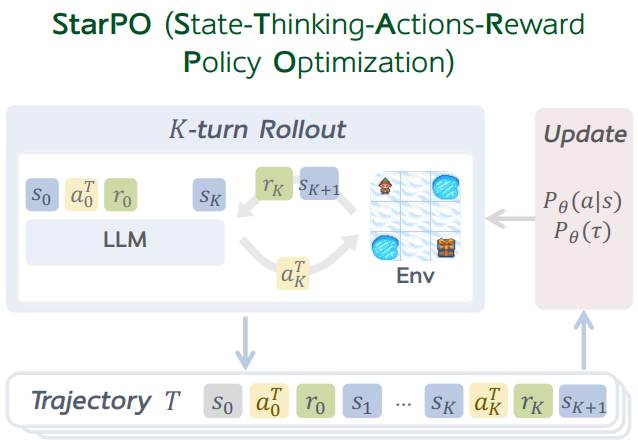
ZP:RAGEN的第二代主要是关注推理失败案例,以及强化学习失败模式(RL failure mode)相关的问题,它也从一个偏向infra定义的研究,转变为一篇基于观察的论文。在这篇论文中,你们主要的观察结果是什么?你觉得有哪些方法可以改进这种观察?
王子涵:我们梳理了去年W&B上记录的几千个实验,发现强化学习的不同领域中,多轮Agent强化学习(multi-turn Agentic RL)领域推进难度远大于推理领域。
在数学、代码等推理领域,模型reasoning长度会随训练增加,直观体现模型逐步学会深入思考;但在多轮Agent RL领域,我们测试20多个任务后,始终无法复现这一现象,反而模型推理长度持续下降。我们认为,长度只是表象,我们更需要深入理解这个长度背后,真正反映的模型推理能力和决策逻辑是什么。
ZP:导致这种现象的原因,是不是与你所定义的环境有关?你所在的框架或所在定义的环境是软件工程/代码(SWE),还是类似小游戏(Gym)?
王子涵:我们的实验环境更偏向分布外(OOD)场景,也即Agent不熟悉的场景。Code或者数学等任务一般在模型的预训练/后训练阶段都进行大量的训练,做Agent RL时推理长度下降现象更缓和,但这类规整任务仅占Agent实际应用场景的一部分。除此之外还有大量Agent实际使用场景,比如GUI Agent(即网页点击)、游戏(如Sokoban)等任务,这些都是Agent不熟悉的任务。
更具有挑战性的是,训练无法穷尽所有基准测试,测试时必然出现OOD任务。我们实验室在SPA这篇paper中,采取状态困惑度(State Perplexity)作为OOD环境的检测指标,发现推箱子任务困惑度接近200多,远高于WebShop、数学、代码等任务。

图片由受访者提供
我们的目标是将Agent部署到现实中,而现实中OOD场景最易出问题,需重点加强理解;且“推理长度下降”并非仅存在于OOD任务,分布内任务中,也可能因Agent推理噪声,导致任务偶然答对后推理链缩短。
ZP:这种“偶然答对后推理链变短”的现象,在不同类型任务中表现是否一致?
王子涵:差异非常明显。编程、数学任务有极强因果链,“过程对则结果对”;但推箱子、WebShop等Agent任务,可能步骤错误仍能完成任务,且这类任务状态转移多带随机性。我曾在Yutori实习接触GUI Agent业务,发现长程多模态Agent训练难度大,比如让Agent通过点击网页来订机票仍是未完全攻克的难题。我们观察到,模型性能提升的同时,推理却愈发脆弱,后续抽象出“模板坍缩”现象——模型倾向于输出不随prompt变化的“套话”。
那“套话”到底该如何定义?本质上,它指的是不随题目变化而变化的推理链——无论输入什么prompt,模型都倾向于重复相同的表述。意识到这一点后,我开始寻找理论框架来解释这种现象。于是我回归信息论的底层,去研读早期的论文,最终意识到:对于输入X和推理Z,推理的总多样性H(Z),由两部分组成。第一部分是"同题多解”——给定输入X之后,推理链Z在单个输入的多样性,也即条件熵H(Z|X);第二部分是"异题异解”——不同输入X之间,推理Z的分布是否不同,也即互信息I(X;Z)。H(Z)=H(Z|X)+I(X;Z),是信息论发展几十年的成果,而从未有人尝试用其解释LLM Agent的推理坍塌现象。
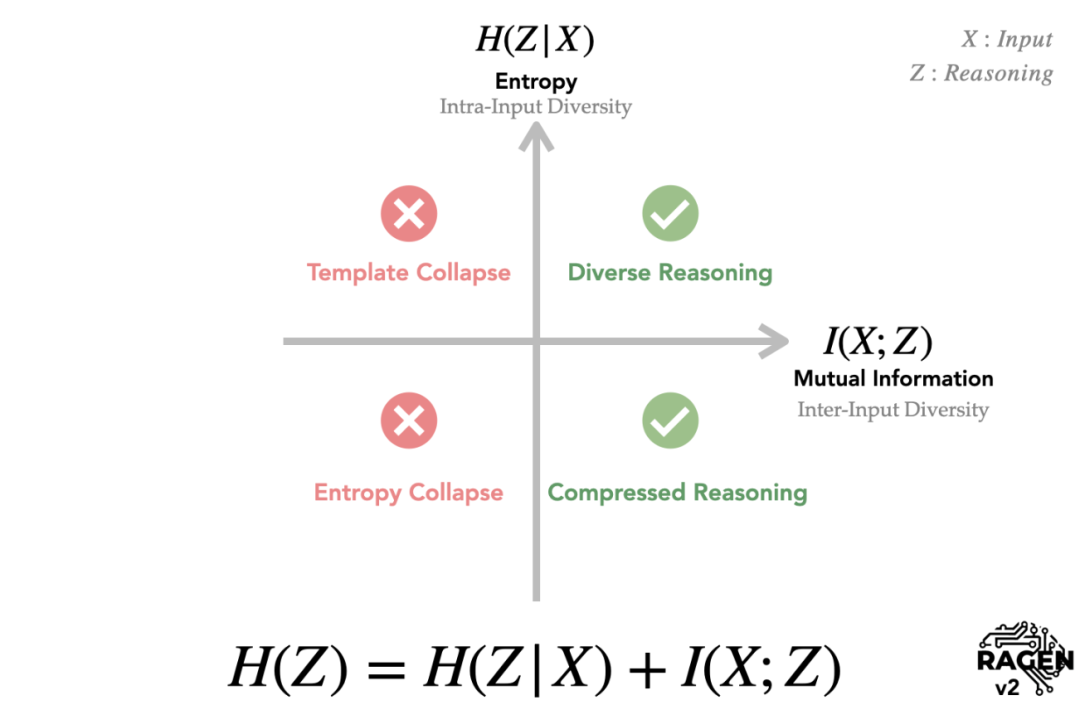
图片由受访者提供
然而在实验中我们观察到,随着训练的深入,到后面推理与输入的互信息降到几乎快没有了。尽管我们以各种方式去提高reasoning的entropy,结果却适得其反:模型生成的内容在不同prompt之间的区分度越来越小。
ZP:针对这种问题,你们在RAGEN V1阶段做了哪些尝试?
王子涵:我们尝试过提示词过滤(prompt filtering)的方式:轨迹推演(rollout)完成后,系统会检查同一输入下不同样本间的奖励是否存在不一致;如果某个prompt对应的所有奖励都相同,我们就认为该prompt无法产生训练信号,类似考语文作文,写了5篇文章都是同一个分数,没有对比和进步的空间,就直接将其剔除。
这并非我们独创,工业界同期也产生了DAPO等类似的思路。DAPO看似很有前景,但在我们的Agent任务上却无法生效,核心是因为其只剔除不同采样间分数完全相同的prompt,而Agent任务奖励系统很多时候并非二元(0/1)奖励,奖励系统复杂且Agent采样有较强随机性,我们就调整了思路。
在RAGEN V1中,我们做了一个简单的启发式尝试,发现这可能与奖励方差(RV)相关——通过观察奖励方差,来评估任务的学习价值。如果奖励方差越大,说明Agent当前的策略在该任务上的奖励不稳定,我们就保留这类样本;反之,则剔除。V1版本固定保留排名前25%或50%的高方差样本;V2阶段进一步探究prompt不可区分的原因,发现训练样本的RV越低,推理过程与输入的互信息下降越快。
ZP:那到底是什么在影响互信息?
王子涵:我们探究后发现,影响互信息的核心是两种噪声。这两种噪声来源分别是:算法内部为维持稳定性引入的正则项,以及rollout过程本身的环境随机噪声。
一是来自正则项的噪声,在奖励方差(RV)极低时,优势函数近乎为零,梯度更新主要由正则项(KL散度或熵等)主导,会把模型推到一个输出单一稳定推理链的位置;二是来自随机环境的噪声,即便采用完全不同的推理,也有可能由于噪声导向相同的结果,这就使得模型认为不同的推理可能有相同的收益,还不如稳定输出一个简单的推理,最终推理链千篇一律。
ZP:infra层面的bug,也在你定义的噪声范畴内?
王子涵:去年暑假我研读了大语言模型RL中tokenization mismatch(分词不一致)和FP16vsBF16(训练推理精度转换导致的不一致)的近期论文,发现过去的一年中RL的底层框架中存在各种各样的infra问题,而即便是这样依然能成功训练,可见其信号强度足够强。
由于各种层面的噪声难以完全消除,我们将策略从“消除噪声”转为“控制信号”,剔除信号弱、无学习价值的部分,最终设计出SNR-aware filtering(信噪比感知过滤)自适应训练方案。其核心是轨迹推演中实时评估样本信噪比,仅针对强信号、有增量学习价值的样本更新参数,既避免噪声干扰,还能节省GPU资源和时间成本。具体而言,我们按奖励方差(RV)排序prompt,仿照Top-P算法保留累积贡献前列的样本,目前该方法已在多个合成/真实、单轮/多轮、视觉/文本模态等任务上实现性能提升。
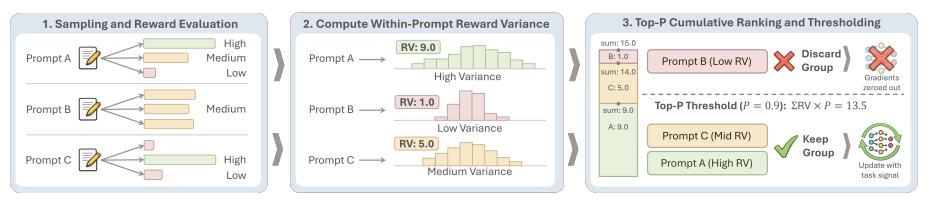
图片由受访者提供
相比于DAPO等方案仅能剔除“无信号”的样本,我们基于RL信息论框架构建的SNR-aware filtering为工程师提供了一个旋钮(Top-P threshold),可以针对自己的任务调整“拒绝区间”。信号高的任务,就少拒绝一些样本,多学点东西;信号低的任务,就多拒绝一些样本,确保学到了高质量内容。针对控制旋钮本身,相比于Top-K Filtering 固定选取前K个prompt的样本,Top-P可以动态地在训练的不同阶段针对性采集信号更高的样本,训练效率更高,也更能确保样本的质量。
ZP:既然rollout占主要的compute,那么fliter之后还是会丢掉一些样本,是否意味着这种计算投入被白白浪费了?
王子涵:节省计算时间并非核心价值。针对“过滤是否需更多样本才能收敛”的疑问,我们做了对比实验:采样的样本数量相同时,开启过滤的模型表现显著优于未开启,证明低信噪比样本的更新不仅无益,还会产生干扰。
当时 RAGEN 正在投稿 NeurIPS,审稿人提出了很多质疑,再加上我在 Yutori 的实习 Agent RL 实验进度不如预期,每天回到工位上,看到同一个实验设置下,甚至会跑出几条不同的、近乎随机的结果曲线,那种深重的困惑感一度让我非常低落。值得庆幸的是,我们最终找到了一种方式,去解释 RL 训练中的不稳定性,也找到了让 RL 训练变得更可控的方法。
ZP:总结来看,prompt呈现出低方差(low variance)是有原因的:它可能只是碰巧有一个正确结果,也可能是任务太难导致模型始终猜不出来,还可能是任务太简单导致模型每次都能做对。本质上,这说明这个prompt可能不适合当前阶段的模型训练,所以把它整个过滤掉是比较正确的选择,强行通过后处理人为把它变成高方差(high variance),是没有实质意义的。那最后你们观察到,对于方差比较大的prompt,你觉得它是落在模型能力边界(boundary)上的一些案例吗?你怎样定义这些案例?
王子涵:确实如此,方差大的prompt恰好落在模型能力边界上,模型表现时好时坏,这类样本训练性价比最高,但这尚未完全揭示现实学习的本质。现实中,偶尔能做对、多数时候出错的任务最具学习价值,核心问题在于当前RL范式依赖梯度下降,导致学习过程扭曲,难以区分真正逻辑与侥幸结果。
最理想的学习状态是任务梯度干净、信噪比高。我们的研究也证明,奖励方差越大,梯度信号越不易被噪声掩埋。尽管如此,我对今年RL的范式转移充满期待,或许大家都会回归到提示词(prompt)的研究上,我自己最近也非常痴迷于此,觉得这是一种返璞归真。而且现在很多时候,做提示词优化的效果,甚至比做梯度下降还要好。
ZP:那回到RL,包括Agentic RL、数学领域的RL,你觉得这条scaling路线有没有可能暂停?现在整体还处在高速增长阶段吗?你觉得是scaling已经不够用、需要新范式来突破,还是scaling itself is enough?
王子涵:谈到scaling,我觉得关键是scale什么。现在行业普遍在scale关注算力,而有些人更看重数据。之前有人问我:到底什么才是Agent?我觉得,一个东西算不算Agent,取决于它被放在什么样的Physical或Digital环境里。给它完全开放的计算机环境,它就是OpenClaw;给它受限计算机环境,它就是Claude Code或Codex;只给一个聊天界面,它就是GPT。环境的开放程度,决定了Agent从0到1的智能指数。回到你的问题:Agent RL 的 scaling law,我觉得最核心的还是——你能给它提供什么样的环境。
05 Agent下一阶段的核心命题是资源自适应:给1万块做1万的事,给100万做100万的事
ZP:除了扩展环境(scaling environment)之外,模型本身你觉得还有哪些地方需要改进?比如长上下文、泛化能力这类。你觉得泛化是必然会实现的,还是本质上就做不到?
王子涵:我在和GPT对话的过程中发现,它现在模仿我的速度越来越快,这说明大家都很重视记忆能力。我觉得目前真正难突破的,还是那些贴近真实人类社会决策的任务。现实中缺乏RL训练环境和试错机会,能收集到少量离线数据已属不易。
当然我们也在尝试构建环境。我们和一些研究者合作,搭建贴近真实的场景。我们正在和耶鲁、MIT、NUS的团队一起合作做O2 AI公司(o2tech.ai),开发能深度接入垂类企业环境的Agent harness,并基于此构建“资源自适应”的 Agent全栈系统(Infra / Benchmark / Service / Research)。我们基于电子制造与回收供应链场景构建Agent,其有能力直接和企业实时数据交互、理解企业资源(如库存,时间,资源,人力)、并据此指导应该如何做企业决策,如仓库何时满仓、何时需要清库存。这种基于真实业务逻辑的交互极具实用价值,我认为这是未来Agent发展绕不开的关键环节。

图片由受访者提供
Agent在人类社会中正在逐渐从“执行角色”过渡到“决策角色”,构建具有决策能力的Agent将会越来越重要。为什么未来一定要让Agent去管理这些复杂企业事务,而不是传统模型?首先,Agent可以做出更需要复杂上下文决策。人在判断决策是否合理时,不只是根据过往数据算出来一个收益,还要考虑政策变化、商业合作意向等大量非结构化变量,这是传统模型很难覆盖的,因此必须依靠Agent。
现实中没有太多试错机会,构建沙盒环境是必然选择。所以我们正在做资源管理型 Agent。我们的研究更聚焦于:Agent在不同预算约束下究竟应该如何表现。很多任务的设定都是给你一笔钱,把任务做得越漂亮越好。但更重要的是:一个真正具备资源适应能力的人或Agent,给他一万块能做出一万块的效果,给他一百万就能做出一百万的效果。我们希望打造的,就是这种高度自适应资源约束的Agent。现实中每个部门的初始资金、资源都不对等,且充满随机约束,如何让Agent在资源受限的情况下聪明地利用资源,是一个非常值得探讨、但目前几乎没有对应benchmark的问题,这也就是为什么像O2 AI这样的公司,利用企业真实数据构建的环境和Agent系统,会更符合人类决策实际需求。
一个更本质的挑战在于,模型生成token本身就是一种资源消耗。现在很多代码类Agent,甚至只是让它说一句“你好”,都可能消耗10k、20k的token,非常不合理。针对这一点,现在很多人在研究如何优化推理开销。
但我认为,目前研究还没触达更本质的命题:预算并不是花得越少越好,核心是投入产出比的高效匹配。真正的挑战是,给你多少钱就要做出多少钱的效果。现在大多数做效率、做预算约束的工作都存在偏差——很多思路都在追求 “越少越好”,而真正的方向应该是把现有资源高效转化为目标收益,这是完全不同,也更符合真实应用场景的优化思路。
ZP:未来你会倾向于留在学术界还是工业界?两者背后的逻辑你怎么看?
王子涵:我不管在哪都想做研究。做研究本身很快乐,是发现新问题、定义什么问题更重要的过程,所以无论在哪,我都会坚持做这件事。
ZP:如果让你排序当前LLM/Agent领域最重要的三个问题,你会选哪些?
王子涵:第一个是资源管理。如前所述,当我们要让Agent参与高影响力决策时,资源管理就是它的生存根基。在 Agent 的实际部署中,到任何一个新的环境(如企业ERP)里都需要学习这个环境的资源管理逻辑。
这就很自然延伸到第二个问题,就是world model。现在行业里对world model定义很多,我们实验室更关注Agent 自身的世界模型,也就是它能否自主判断做一件事会产生什么影响。目前主流RL算法还很难让 Agent 系统性地获得这种显性预见能力。预算本质上也是一种world model,你必须预判一个动作会带来多少开销、隐性成本。
“世界模型九宫格”梗图,王子涵制作
另一个让我非常兴奋的方向是Agent对价值估计的深度建模。O2 AI公司做垂类企业决策Agent,不仅需要通用的决策管理能力,更需凭借垂类知识精准评估电子元件残值:同一批物料在不同市场周期、库存状态、拆解路径和销售渠道下,对应的残值完全不同。这种垂类的价值估计能力甚至可能在未来可迁移到游戏、交易市场等场景。定价(pricing)是极佳切入点,因其可验证——以海量交易成交价为锚点,Agent学习预测成交价、提取判断逻辑。虽存在市场波动带来的噪声,但RL本身就是兼顾策略学习与去噪的过程,持续学习中积累的判断范式越多,agent 面对新场景的进化速度就越快。
ZP:这意味着要实现真正的实时竞技级AI,需要algorithm、infra跟整个I/O的co-design?
王子涵:的确,需要全栈层面的协同,是一个非常具有普遍挑战性的课题——这种实时应对能力是人有、但Agent没有的能力。
除此之外,continue learning也是今年另一个至关重要的命题。我们需要思考:为什么人学东西会越来越快,尤其是有了AI之后,学一个新领域也越来越快。
怎么样让Agent拥有这种越学越快的能力?其核心在于让Agent在长期处理多样化任务的过程中,把积累的经验内化并迁移到全新的任务中。以我自己为例,近期我在研究关于video generation的工作,尽管我之前只做过video understanding而非generation,但学习这个新领域的速度比以前快很多。这种速度提升,本质上就是一种continual learning能力的体现。要让Agent获得这种能力,需要一个多样的test bed,让它不停地去学。我现在的想法是,让 Agent真的去玩那些游戏,如果真的存在一个Agent能打通世界上所有游戏,在这个过程中,它一定学到了一些很meta的东西。
ZP:我刚意识到一个关键问题。现在最成熟的Agent环境,比如代码、数学,奖励可验证、靠思维链就能闭环;游戏类环境交互强、试错成本低。但一旦到企业决策、预算管理这类真实场景,训练环境极度稀缺,试错要付出真实金钱和代价,很像机器人领域的困境——真实数据太难拿,只能靠仿真,但仿真和现实又有差距。你觉得构建更高保真的模拟器,对高风险、高成本的Agent任务是否有价值?
王子涵:我更偏向从算法演进来看。人类本身就具备小样本学习能力,构建高真实度环境固然重要,但现实世界才是最完美的实验场。而且仿真环境也不是零成本,太便宜的仿真和真实世界差距巨大,机器人领域就是典型。这倒逼我们必须解决样本效率问题,现在的 RL 框架还有巨大提升空间。我之前用过thinking machineAPI,一开始给了几百刀额度,一轮都没跑完额度就全用完了。RL跑500步,一步就可能生成百万token,产生1-2刀的花费,成本极高。
未来一定会出现比现有RL高效成百上千倍的方法,让Agent能持续高效学习。我们离最终的那个Agent相比还有很远,现在做环境还是做算法?对于环境,其设计本质是一种权衡:低复杂度环境无法支撑Agent泛化到真实高成本场景,高复杂度环境需要更高的成本。因此,突破口一定在Agent学习速度的进化上,而核心就在于推理 —— 推理能让它越学越快,抓住不同任务之间更本质的共性。
备注:王子涵是 Northwestern Computer Science PhD,主要研究方向为 Agent RL。他于 2024 年本科毕业于人大高瓴 AI 学院,曾参与 DeepSeek-V2 研究,并拥有微软、NVIDIA 等研究经历。迄今,他已发表 20 余篇论文,相关成果发表于 ICLR、NeurIPS、EMNLP、CVPR 等会议,累计引用 1600 余次,并获得 ICCV 2025 SP4V Best Paper,NeurIPS 2025 LAW Outstanding Paper 等荣誉。他主导/参与开发了 RAGEN、VAGEN、MindCube 等多个 Agent 训练评测框架,累计获得 10k+ GitHub Stars。相关工作获得 Stanford HAI、MIT Tech Review、Forbes、Financial Times 等关注报道。个人技术传播账号在 X 拥有 20K+ followers,代表性线程累计获得 100 万+ 阅读。
请注意,此次访谈内容已经过精心编辑,并得到了王子涵的认可,我们也欢迎读者通过留言互动,分享您对本访谈的看法。Z Potentials将继续提供更多关于人工智能、全球化市场、机器人技术等领域的更多一线技术前沿探索者的访谈。我们诚邀对未来充满憧憬的您加入我们的社群,与我们共同分享、学习、成长。