一周AI丨Meta采集员工行为数据训AI;GPT-5.5与DeepSeek V4本周发布;特斯拉车机语音大模型服务在沪备案;SpaceX拟600亿收购Cursor……
发布时间:2026-04-26来源:世界人工智能大会

Meta采集员工“鼠标移动和键盘操作”,用以训练AIGPT-5.5正式发布:多项测试超越Claude,实力重回前列特斯拉中国车机拟接入豆包大模型,已完成备案
腾讯开源混元Hy3preview大模型,推理效率提升40%
小米MiMo-V2.5语音模型正式发布:一句话生成声音、克隆真人音色
DeepSeek-V4正式发布,昇腾超节点系列产品全面支持Kimi K2.6发布并开源,代码及Agent集群能力全面提升
SpaceX宣布有权以600亿美元收购Cursor
谷歌计划向Anthropic投资至多400亿美元,支持后者大幅扩展算力
OpenAI出资15亿美元成立合资公司,专攻企业AI部署
Meta采集员工“鼠标移动和键盘操作”,用以训练AI
4月22日,据路透社报道,一份内部备忘录显示,Meta已开始在美国员工的工作电脑上部署追踪软件,实时采集鼠标移动轨迹、点击行为及键盘操作,并定期截取屏幕内容,所有数据将用于训练其AI模型。该工具被命名为“模型能力计划”(Model Capability Initiative,MCI),运行范围覆盖工作相关应用程序与网站。
Meta发言人Andy Stone确认,MCI采集的数据将作为AI训练的输入之一,并表示相关数据不会用于员工绩效评估或其他任何目的,同时已设置保护措施以屏蔽“敏感内容”,但未具体说明哪些类型的数据将被排除在外。
据报道,MCI的部署是Meta大规模AI转型战略的缩影。公司内部已开始要求员工使用AI智能体完成编程等任务,即便短期内会降低效率。与此同时,Meta正在打破部分岗位之间的职能边界,推行一种名为“AI构建者”(AI builder)的通用职位。
上个月,Meta新成立了应用AI(AAI)工程团队,专注于提升AI模型的编程能力,并利用这些模型打造能够承担产品构建、测试和发布工作的AI智能体。本月初,Meta已开始将“优秀”软件工程师调入AAI团队。
Meta首席技术官Andrew Bosworth在备忘录中描绘的愿景是:“我们正在构建的未来,是智能体主要承担工作,而我们的角色是指挥、审查并帮助它们改进。”他补充称,目标是让智能体“自动识别我们感到需要介入的地方,以便下次做得更好”。
这一举措在法律与劳工权益层面引发了明显争议。
耶鲁大学法学教授Ifeoma Ajunwa指出,电脑日志记录和截屏技术历史上主要被企业用于追查员工不当行为或非工作活动,而此次对键盘操作的记录则将数据采集目标推向了更深层次——使白领员工承受此前仅限于快递司机和零工经济从业者的实时监控程度。
在欧洲,法律环境则截然不同。多伦多约克大学研究技术与比较劳动法的法学教授Valerio De Stefano表示,此类监控在欧洲很可能被认定为违法。
在意大利,利用电子监控追踪员工生产力被明确禁止;在德国,法院裁定雇主仅在涉嫌严重刑事犯罪等特殊情形下方可部署键盘记录。此外,De Stefano认为,该做法还可能违反欧盟《通用数据保护条例》(GDPR)。
De Stefano还指出,雇主监控意识的提升从更宏观层面改变了职场权力格局,使天平进一步向雇主一方倾斜。
蒸馏所有员工:Meta强制收集鼠标键盘输入训练AI,社区炸了
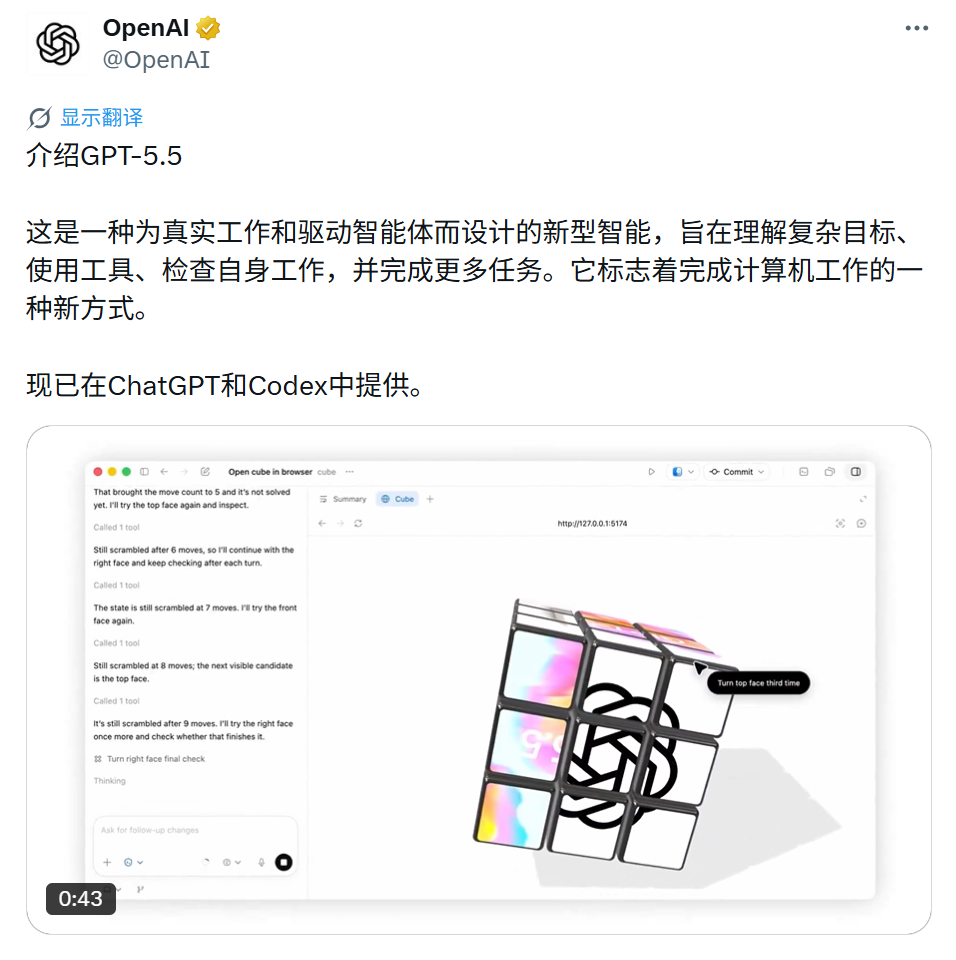
GPT-5.5正式发布:多项测试超越Claude,实力重回前列
4月24日,OpenAI发布新一代旗舰模型GPT-5.5,并在其官网写道,是其迄今为止最智能、最直观易用的模型,也是在计算机上完成工作的新方式的下一步。
这一发布迅速引发行业关注,不仅因为它号称在智能体任务上实现突破,更因其在多项基准测试中展现出的“统治力”。
在衡量复杂终端操作的Terminal-Bench 2.0 上,GPT-5.5直接冲到82.7%;软件工程评测SWE-Bench Pro得分58.6%;内部长周期任务测试Expert-SWE则达到73.1%。值得留意的是,这三项测试它都用了更少的token就完成了任务。在跨44种职业的综合评测GDPval中,它胜出或打平的比例为84.9%;在模拟客服工作流的Tau2-bench Telecom场景中拿到98.0%;在模拟真实计算机操作的OSWorld里也做到78.7%。
在更专精的领域,它的表现同样抢眼:生物信息学评测BixBench得分 80.5%,位列所有已公布成绩的模型之首。更令人印象深刻的是,一版内部模型还证明了一个关于Ramsey数的长期猜想,并在证明助手Lean中完成了形式化验证。
从底层硬件的协作来看,这套模型针对英伟达GB200/GB300 NVL72系统做了联合设计。结果是,它的每token延迟被保持在与GPT-5.4持平的水平上,同时通过负载均衡优化,token生成速度反而提升了超过20%;在执行同样的Codex任务时,GPT-5.5所消耗的token数量也显著更少。
但与高性能一同被曝光的,还有高幻觉率。在Artificial Analysis的私有基准测试AA-Omniscience中,GPT-5.5的幻觉率高达86%,远高于Claude Opus 4.7的36%。
这意味着,当这个目前“最聪明”的AI大脑面对不确定或未知的问题时,选择“坦言不知”的概率极低,反而更倾向于“自信地虚构”一个答案。而这种高幻觉率一旦放在需要高可靠性的工作场景中,很可能导致分析偏差、决策失误甚至财务损失。
目前,GPT-5.5已向ChatGPT Plus、Pro、Business和Enterprise用户开放,Codex支持最高400K的上下文窗口;API版本也即将上线,标准定价方案是每百万输入token 5美元、每百万输出token 30美元,而GPT-5.5 Pro的API定价分别为30美元和180美元。
4月22日,据《科创板日报》从知情人士处获悉,特斯拉车机语音服务将接入豆包大模型。此前,据网信上海消息,4月21日,上海新增1款已完成备案的生成式人工智能服务,为特斯拉车机语音大模型服务。这也是自2013年进入中国市场以来,特斯拉车机语音助手的一次大更新。
2025年8月,特斯拉与字节跳动旗下火山引擎达成合作,由火山引擎为特斯拉智能座舱交互体验部分提供大模型服务。
特斯拉中国官网的《特斯拉车机语音助手使用条款》显示,特斯拉Model车型的车机语音系统将同时接入字节跳动旗下的“豆包大模型”和深度求索旗下的“DeepSeek Chat”,两款模型均通过火山引擎接入。其中,豆包大模型将承担语音命令功能,如导航设定、媒体播放操控、空调温度调节等,同时还支持语音查询车主手册;DeepSeek则将提供AI互动功能;在支持AI互动能力的特斯拉车型上,车主可以与语音助手聊天,获取天气、新闻等资讯。
特斯拉表示,车主可以通过物理按键,“嘿,Tesla”或自定义唤醒词激活车机语音助手,进而与车辆进行语音交互。
2025年7月,特斯拉在美国先行启用AI大语言模型,该模型使用的是马斯克旗下xAI推出的人工智能Grok。和中国市场不同,美国AI互动功能仅支持搭载AMD Ryzen芯片的特斯拉车型,车主还需要订阅每月9.9美元的“高级车载娱乐服务包”。
据特斯拉4月初最新公布的2026年第一季度全球产量、交付量和部署情况,当季交付量为358023辆,其中Model3/Y交付量为341893辆;当季汽车产量408386辆,其中Model3/Y产量394611辆。同期,特斯拉储能产品装机量达到8.8吉瓦时。
一季度,特斯拉的交付量同比增长6.3%,但环比下降14.4%。根据StreetAccount数据,分析师此前预计特斯拉一季度交付量约为37万辆。
值得一提的是,特斯拉上海超级工厂3月交付电动车超8.56万辆,创年内新高;第一季度交付21.3万辆,同比增长23.5%。
新闻拓展:
特斯拉接入豆包:汽车产品定义权,又东移了一点点
腾讯开源混元Hy3preview大模型,推理效率提升40%
4月23日,腾讯正式发布并开源新一代大模型混元Hy3preview。这是前OpenAI研究员姚顺雨加盟、混元团队重组后训练的首个模型,也是混元系列目前最智能的版本。这是一个快慢思考融合的混合专家模型,总参数295B,激活参数21B,最大支持256K上下文长度。这是混元重建后训练的第一个模型,也是混元迄今最智能的模型,在复杂推理、指令遵循、上下文学习、代码、智能体等能力及推理性能上实现了大幅提升。
据介绍,Hy3 preview可以视为混元快速探索实用性大模型、解决真实世界问题的一个开端。对此,腾讯首席AI科学家姚顺雨表示,Hy3 preview是混元大模型重建的第一步。腾讯希望通过这次开源和发布,获得来自开源社区和用户的真实反馈,帮助提升Hy3正式版的实用性。与此同时,腾讯也在继续扩大预训练和强化学习的规模,提升模型的智能上限,并通过与腾讯众多产品的深度Co-Design,持续提升模型在真实场景中的综合表现,并开始探索特色模型能力。
目前,Hy3 preview已在腾讯云、元宝、ima、CodeBuddy、WorkBuddy、QQ、QQ浏览器、腾讯文档、腾讯乐享等首发上线,微信公众号、和平精英、腾讯新闻、腾讯自选股、腾讯客服、微信读书等多个主线产品也在陆续上线。另外,Hy3 preview支持接入流行的开源智能体产品,如OpenClaw、OpenCode、KiloCode 等,并已上架腾讯云大模型服务平台TokenHub。
据悉,正式上线之前,Hy3 preview在腾讯主要AI业务进行了产品测试,获得明显正收益。
新闻拓展:
刚刚,姚顺雨带队「重建」混元,首个大模型上线了
小米MiMo-V2.5语音模型正式发布:一句话生成声音、克隆真人音色
4月24日,小米正式发布MiMo-V2.5语音模型,带来MiMo-V2.5-TTS系列与MiMo-V2.5-ASR。
这是一套面向Agent时代的全链路语音模型系列,覆盖识别与合成两大核心能力,让语音的输入与输出都可以被语言自由调度。在语音合成方面,MiMo-V2.5-TTS系列提供三大模型,分别对应不同创作场景:首先是MiMo-V2.5-TTS,内置多款高质量精品音色,经过专业调优,发音自然、情感贴合,并支持语速、情绪、语气等精细化控制,开箱即用,满足多场景表达。其次是MiMo-V2.5-TTS-VoiceDesign,支持通过一句自然语言描述生成全新音色,无需任何参考音频。用户可从年龄、性别、口音、音质乃至性格气质等多个维度自由定义,例如“低沉略带嘶哑的老年学者”或“元气满满的少女”,模型即可自动生成对应声音形象。依托大规模预训练能力,模型对复杂、模糊、甚至相互矛盾的描述也能合理解读,而不局限于"男/女/青年/老年"这类粗粒度标签。第三是MiMo-V2.5-TTS-VoiceClone,主打音色克隆能力,用户仅需提供数秒参考音频,无需训练或微调,即可复刻真人播客、配音演员、品牌代言人,或者用户本人声音。复刻后的声音不仅保留了原始说话人的音色身份,也保留了气息、节奏、习惯性停顿等个人特征。同时,克隆音色可继续叠加自然语言指令、音频标签、导演剧本级脚本,实现更高自由度的语音创作。作为全链路语音模型系列的听觉基座,MiMo-V2.5-ASR在中英双语、中文方言、Code-Switch、强噪音、多说话人、高知识密度等复杂真实场景下均达到业界领先水平。目前,MiMo-V2.5-TTS、MiMo-V2.5-TTS-VoiceDesign、MiMo-V2.5-TTS-VoiceClone已在Xiaomi MiMo API开放平台限时免费。
新闻拓展:
罗福莉又上分了!小米连甩4款模型,让AI超逼真配音
DeepSeek-V4正式发布,昇腾超节点系列产品全面支持
4月24日,Deepseek宣布,其全新系列模型DeepSeek-V4的预览版本正式上线并同步开源。
DeepSeek-V4模型按大小分为Deepseek-V4-Pro(专家模式)和Deepseek-V4-Flash(快速模式)两个版本,均拥有百万字超长上下文,且同时支持非思考模式与思考模式。据介绍,DeepSeek-V4-Pro的知识储备和推理能力优秀。其在世界知识测评中,大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1;在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro超越当前所有已公开评测的开源模型,取得了比肩世界顶级闭源模型的优异成绩。相比DeepSeek-V4-Pro,DeepSeek-V4-Flash在世界知识储备方面稍逊一筹,但展现出了接近的推理能力。而由于模型参数和激活更小,相较之下V4-Flash能够提供更加快捷、经济的API服务。据官方介绍,DeepSeek-V4预览版具备两大亮点——Agent能力大幅提高:相比前代模型,DeepSeek-V4-Pro的Agent能力显著增强。在Agentic Coding评测中,V4-Pro已达到当前开源模型最佳水平,并在其他Agent相关评测中同样表现优异。目前DeepSeek-V4已成为公司内部员工使用的Agentic Coding模型,据评测反馈使用体验优于Sonnet 4.5,在代码任务、文档生成任务等方面表现均有提升,交付质量接近Opus 4.6非思考模式,但仍与Opus 4.6思考模式存在一定差距。结构创新和超高上下文效率:DeepSeek-V4开创了一种全新的注意力机制,在token维度进行压缩,结合DSA稀疏注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文能力,并且相比于传统方法大幅降低了对计算和显存的需求。从现在开始,1M(一百万)上下文将是DeepSeek所有官方服务的标配。目前,DeepSeek API已同步上线V4-Pro与V4-Flash,支持OpenAI Chat Completions接口与Anthropic接口。值得一提的是,业界一直在关注DeepSeek-V4是否会使用国产算力,从官方API页面来看确实是与华为昇腾合作。DeepSeek在小字中表示,受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。新闻拓展:
刚刚,DeepSeek V4 双版本正式上线!
Kimi K2.6发布并开源,代码及Agent集群能力全面提升
4月21日,月之暗面正式发布并开源Kimi K2.6模型,该模型在代码编写、长程任务执行及Agent集群能力方面实现全面升级,现已上线kimi.com、最新版Kimi应用、Kimi API和Kimi Code编程助手,面向所有用户开放使用。据官方披露,Kimi K2.6的通用Agent、代码、视觉理解等综合能力全面提升,在博士级难度的完整版“人类最后的考试”、考察真实软件工程能力的SWE-Bench Pro、评估Agent深度检索能力的DeepSearchQA等基准测试中均取得行业领先成绩,表现持平或优于GPT-5.4、Claude Opus 4.6和Gemini 3.1 Pro等闭源模型。
作为月之暗面迄今最强代码模型,Kimi K2.6长程编码能力显著提升,测试中可连续不间断编码13小时,编写或修改超过4000行代码,完成复杂系统开发优化。在Kimi内部代码评测基准Kimi Code Bench中,该模型成绩较上一代K2.5提升约20%。
实测显示,K2.6在Mac本地部署Qwen3.5-0.8B模型时,经过4000余次工具调用、12小时不间断运行,将吞吐量从约15 tokens/s提升至约193 tokens/s,推理速度较LM Studio快20%;在重构拥有8年历史的开源金融撮合引擎exchange-core任务中,该模型连续作业13小时,迭代12套优化策略,修改4000余行代码,实现中位吞吐量185%的增幅。
Kimi K2.6的Agent集群架构同步升级,最多可调度300个子Agent并行完成4000个协作步骤,任务完成度和交付质量较K2.5显著提升,针对OpenClaw、Hermes Agent等主动式Agent框架可支持最长5天的持续自主运行。内部Claw Bench测试结果显示,K2.6综合性能较K2.5提升10%。
新闻拓展:
Kimi K2.6 这次把 Agent 玩明白了吗?
SpaceX宣布有权以600亿美元收购Cursor
4月22日,SpaceX官方宣布,已与人工智能初创公司Cursor达成协议,获得在今年晚些时候以600亿美元收购该公司的选择权,或者以100亿美元收购双方正在合作的项目。
SpaceX在X上发帖表示,其正在与Cursor紧密合作,共同打造世界上最好的编码和知识工作人工智能。Cursor的领先产品和其面向专业软件工程师的分销渠道,搭配SpaceX的超级计算机将建成全球最有效的模型。SpaceX创始人兼首席执行官马斯克于今年2月将SpaceX与他的人工智能初创公司xAI以及社交平台X合并,这笔交易使SpaceX估值高达1.25万亿美元。而SpaceX现在准备上市,其估值有望进一步增加至1.75万亿美元,并创下IPO纪录。之前有消息称,Cursor正在洽谈融资20亿美元,其估值预计将超过500亿美元,科技基金Andreessen Horowitz预计将领投此轮融资,英伟达和Thrive Capital预计也将参与。Andreessen和Nvidia此前也投资了xAI。对于密切关注的业内人士而言,SpaceX和Cursor的交易并不令人意外。上周有报道称,xAI将开始向Cursor出租其数据中心的计算能力。上月,Cursor的两位资深工程主管Andrew Milich和Jason Ginsberg也离开了公司,加入了xAI,并直接向马斯克汇报工作。但SpaceX与xAI合并后普遍被认为在一直亏损,且其已经计划了诸如Terafab半导体工厂的大规模资本投资项目,收购Cursor对该公司来说仍是一笔不小的开支。另一方面,业内认为,无论是Cursor还是xAI,都没有能够与Anthropic和OpenAI的领先产品相媲美的专有模型,而这后两家公司目前却正与Cursor在竞争开发者市场。4093亿!马斯克要收购Cursor,4个00后即将封神
谷歌计划向Anthropic投资至多400亿美元,支持后者大幅扩展算力
4月24日,谷歌表示将向Anthropic投资100亿美元,并可能在后续追加300亿美元,从而强化两家公司之间的关系。
根据协议,谷歌将首先按Anthropic最新3800亿美元估值投资100亿美元,其余300亿美元将取决于特定业绩里程碑是否达成。这笔交易若全部落地,将成为科技行业对AI初创公司规模最大的投资之一。市场认为,此举凸显大型科技公司正以前所未有的资金规模争夺AI核心能力。近年来,领先科技企业正持续向OpenAI和Anthropic等前沿AI实验室投入数百亿美元,而部分投资也将通过云计算服务和模型收入回流至投资方。Anthropic表示,这项协议是在双方长期合作基础上的进一步升级。就在本月稍早,Anthropic宣布与谷歌及博通合作,锁定5吉瓦计算能力,相关资源预计明年开始上线,未来还可能进一步追加算力。目前,谷歌通过云业务向客户提供Anthropic旗下Claude模型接入服务,与亚马逊云服务和微软Azure云服务展开竞争。同时,谷歌还提供自研张量处理器(TPU),作为英伟达GPU的替代方案。不过,双方合作的同时也带有竞争关系。谷歌自有大模型Gemini,正与Anthropic的Claude争夺AI模型及服务市场份额。谷歌与Anthropic合作关系始于2023年,当时谷歌向该公司投资3亿美元,换取约10%股份;数月后又追加20亿美元投资。在此次交易宣布前,谷歌累计投资已超过30亿美元,持股比例据报约为14%。与此同时,Anthropic近期也在寻求缓解快速增长需求带来的基础设施压力。公司表示,随着企业客户、开发者及消费者对Claude需求激增,其算力资源面临“不可避免的压力”。此前,OpenAI曾批评Anthropic未能锁定足够算力资源。分析认为,此次谷歌投资模式与Anthropic数周前与Amazon达成的协议颇为类似。亚马逊当时向Anthropic投资50亿美元,并承诺未来根据特定商业里程碑最多再投资200亿美元。Anthropic首席执行官Dario Amodei此前表示,用户越来越依赖Claude完成工作,公司必须加快基础设施建设以匹配快速增长需求,而与亚马逊合作将支持其推进AI研究,并服务超过10万家基于AWS构建应用的客户。新闻拓展:
谷歌跪了?400亿砸向死敌!AI御三家终结,OpenAI孤立无援
OpenAI出资15亿美元成立合资公司,专攻企业AI部署
4月22日,据英国《金融时报》报道,知情人士透露,OpenAI已承诺向与私募股权机构成立的新合资公司DeployCo投入最高15亿美元,该合资公司估值100亿美元,融资轮预计于5月初完成交割。
据披露,OpenAI将首期注入5亿美元股权,并保留后续追加10亿美元的选择权。与此同时,TPG、贝恩资本(Bain Capital)、Advent International、Brookfield及Goanna Capital等私募股权机构将合计再投入40亿美元。在回报安排上,OpenAI向上述PE投资方承诺每年17.5%的保底回报,投资期限为五年。知情人士表示,这是一个底线……但我们预期实际回报将远高于此。这一保底承诺有效降低了投资方的风险敞口,而OpenAI则换取了“耐心资本、锁定五年”的长期资金支持。DeployCo以特拉华州有限责任公司形式注册,OpenAI持有多数股权并拥有超级投票权。该公司目前由Brad Lightcap主导管理,后者此前担任OpenAI首席运营官。DeployCo已开始自主招募员工,并接受OpenAI的人员借调。Lightcap主导了数十名“前沿部署工程师”的招募工作——这类软件开发人员将直接嵌入客户企业内部,协助其落地AI技术应用。这一模式借鉴自美国软件公司Palantir,后者是前沿部署工程师模式的先行者。DeployCo的主要客户群体为私募股权机构的投资组合公司,通过向其收取AI嵌入服务费用实现营收。此外,OpenAI还在与麦肯锡及埃森哲等咨询机构合作,共同推进企业市场的拓展布局。DeployCo持有的OpenAI股权,未来亦可用于收购技术资产和知识产权。OpenAI此举的直接背景,是Anthropic在企业市场的强劲攻势。据知情人士透露,Anthropic今年年化营收已增长逾两倍,主要得益于Claude Code等企业级产品的亮眼表现。据悉,Anthropic同样正与Blackstone、Hellman & Friedman等私募股权机构洽谈,计划成立一家合资咨询公司,帮助旗下广泛的投资组合企业部署新型AI技术。OpenAI高管将当前AI应用现状描述为存在“能力过剩”,即现有模型的实际能力远超其被使用的程度。DeployCo的成立,正是OpenAI将这一潜在需求转化为商业价值的核心载体。与此同时,General Catalyst、Thrive Capital、Lightspeed Venture Partners以及Jeff Bezos旗下AI初创公司Project Prometheus等风险投资机构,也在通过收购并注入AI技术的方式,争相布局企业AI应用市场的红利。新闻拓展:
https://www.reuters.com/legal/transactional/openai-talks-commit-up-15-billion-private-equity-joint-venture-ft-reports-2026-04-22/
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库