模型介绍
DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 是深度求索于2026年4月24日开源的 DeepSeek-V4 系列模型的两个预览版本。该模型携手国产芯片,在 Agent 能力、世界知识和推理性能上均实现了国内及开源领域的领先。DeepSeek-V4 开创了一种全新的注意力机制,在 token 维度进行压缩,不仅实现了全球领先的长上下文能力(百万级别),还大幅降低了对计算和显存的需求。SuperCLUE团队基于2026年3月中文大模型测评基准体系,对 DeepSeek-V4-Pro(max) 和 DeepSeek-V4-Flash(max) 的中文能力进行了测评,以下是测评结果与分析:
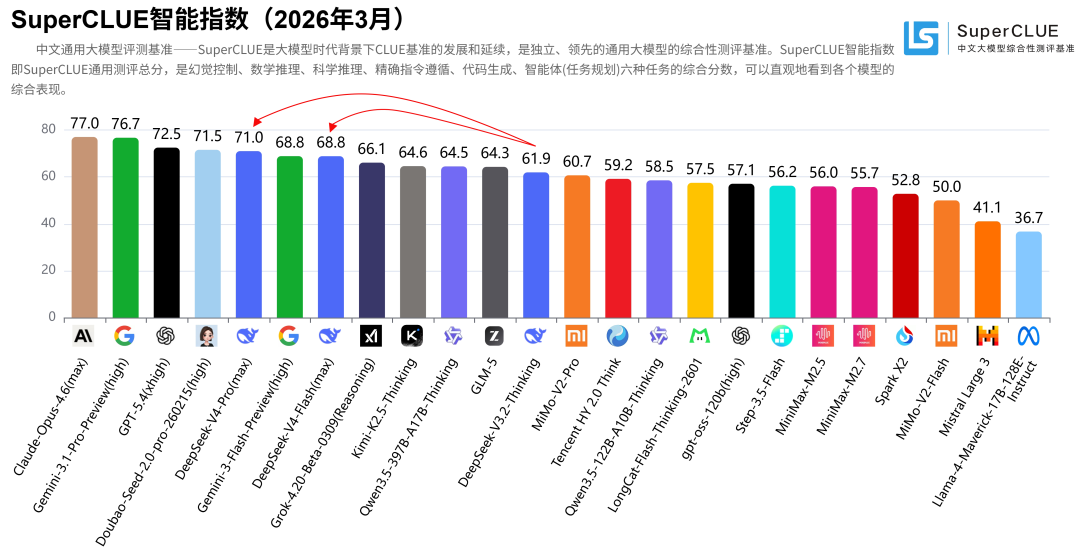
1. SuperCLUE智能指数(2026年3月通用测评)
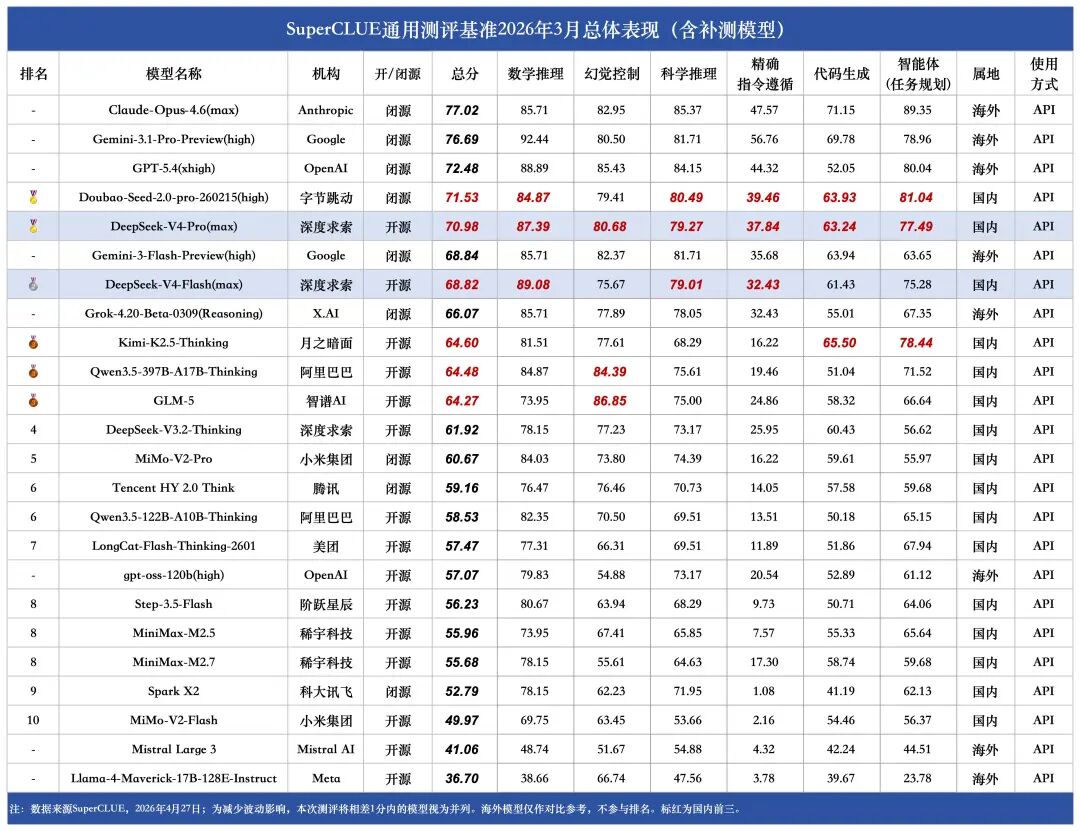
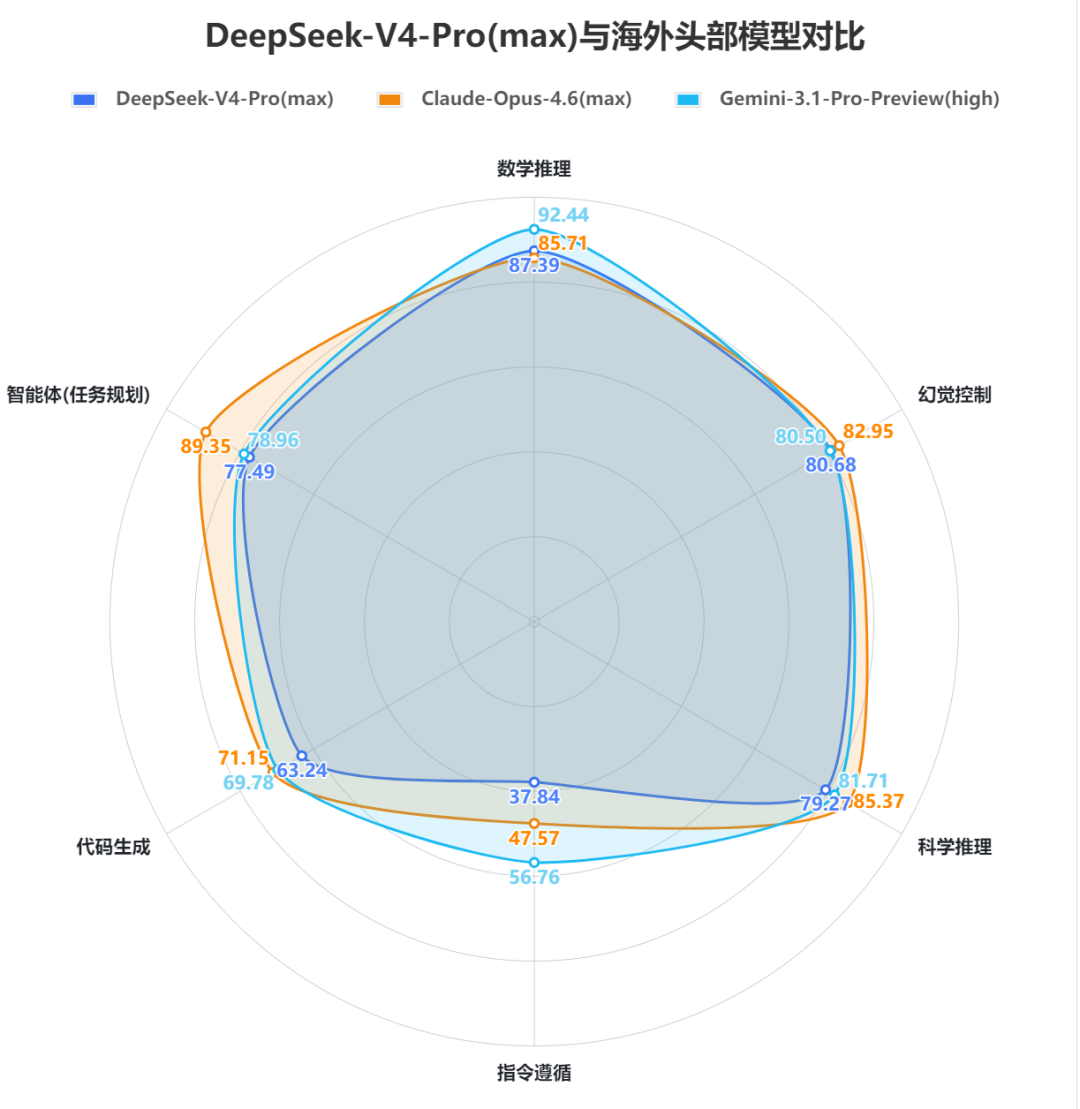
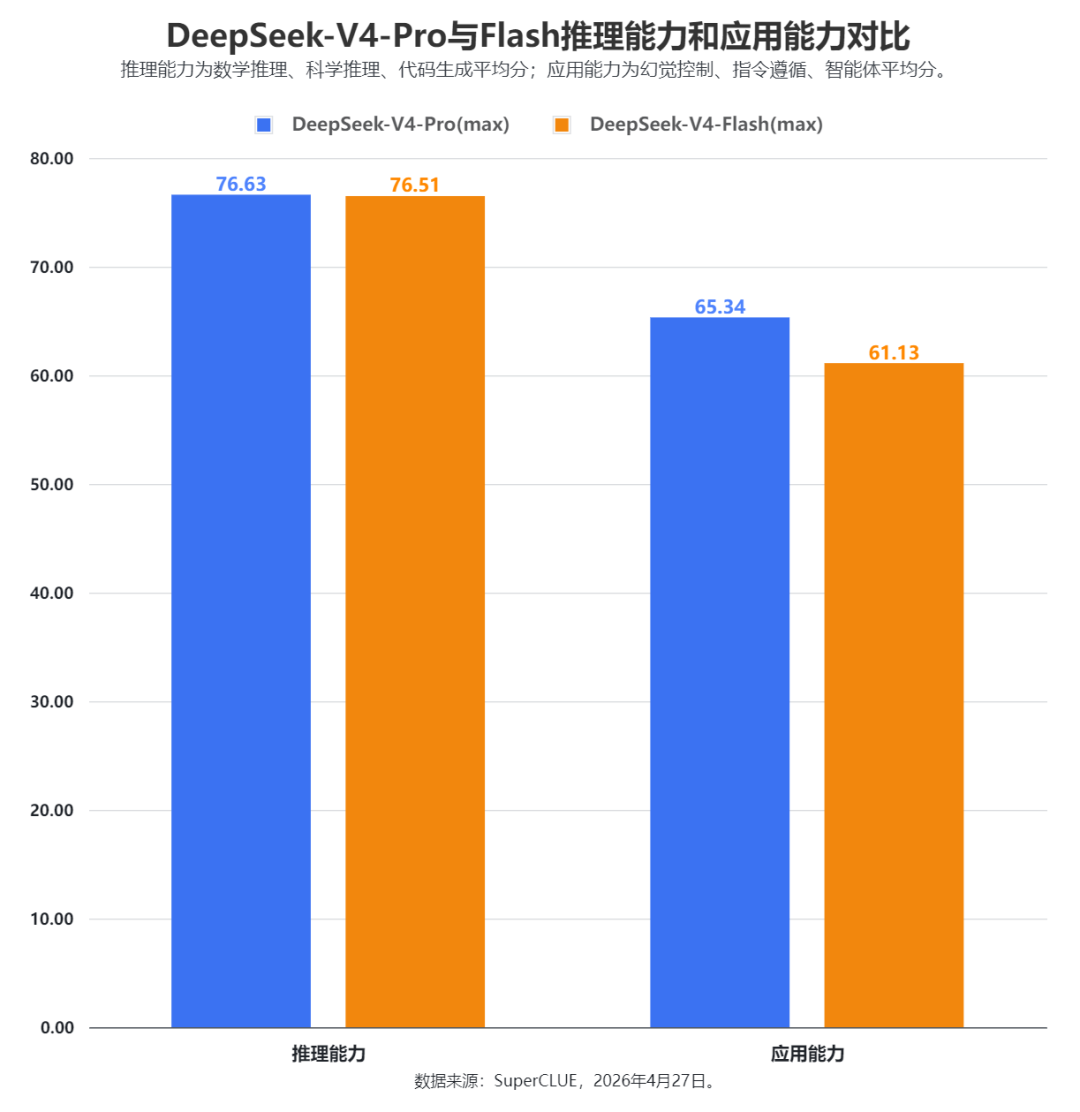
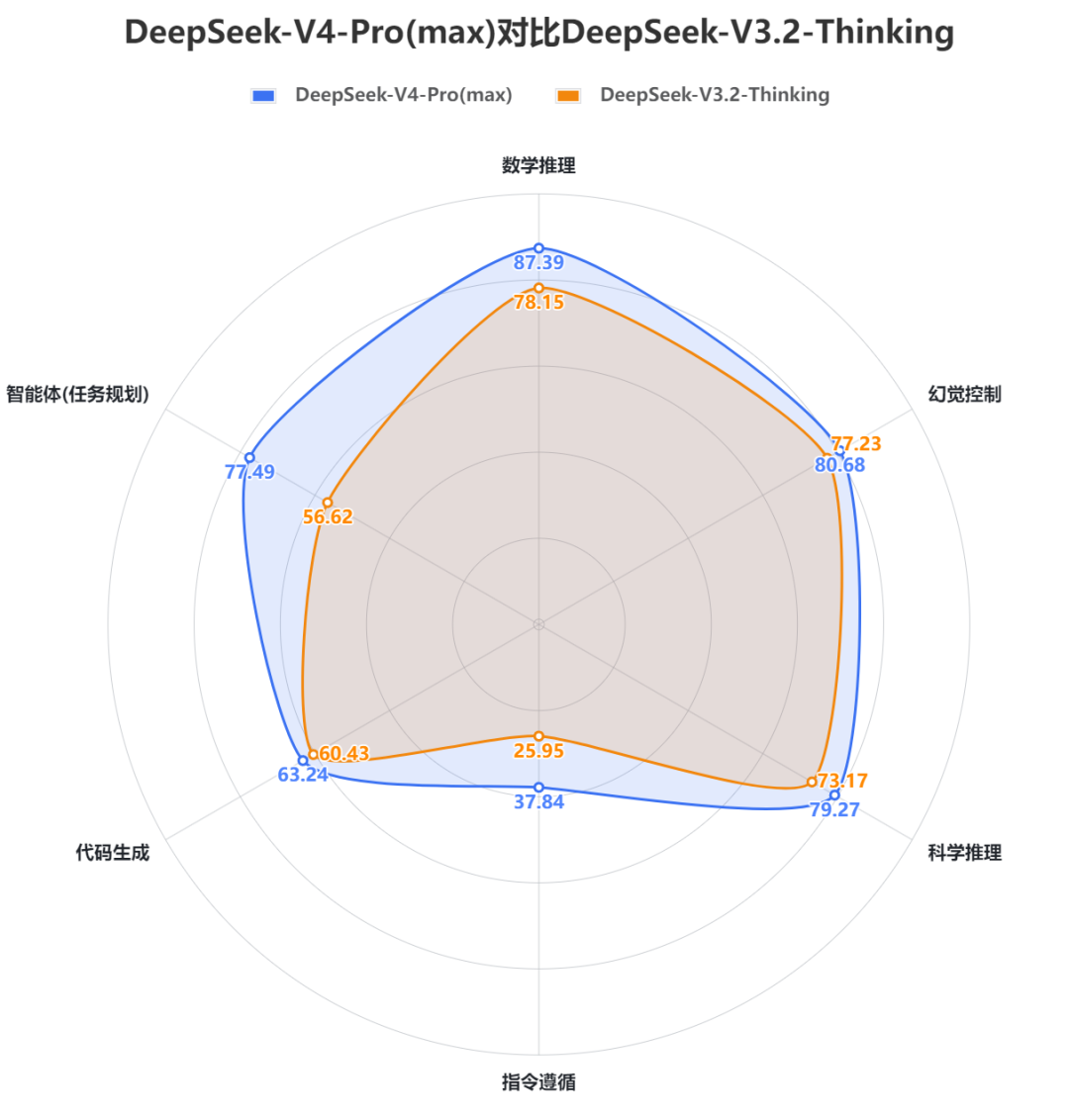
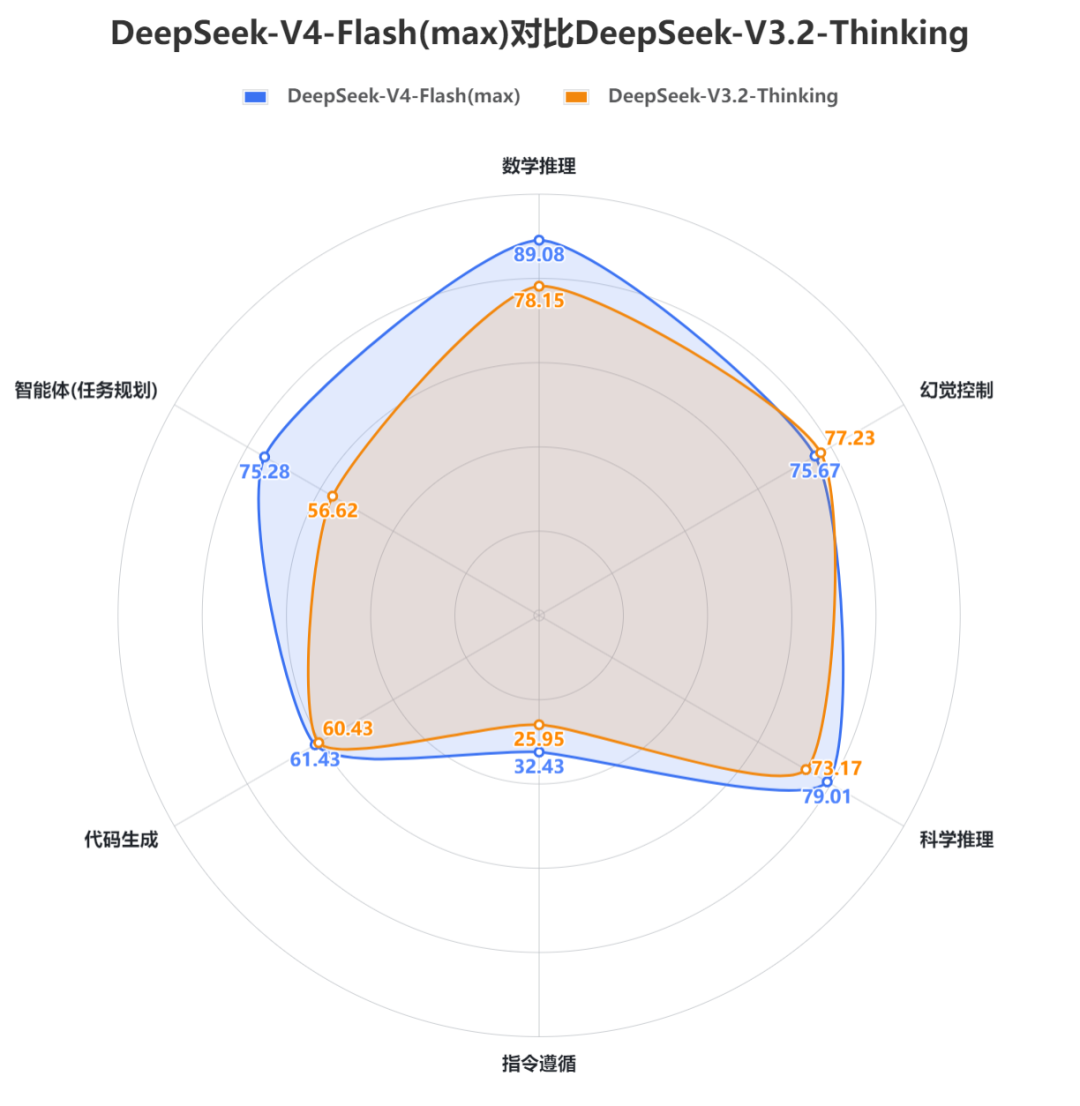
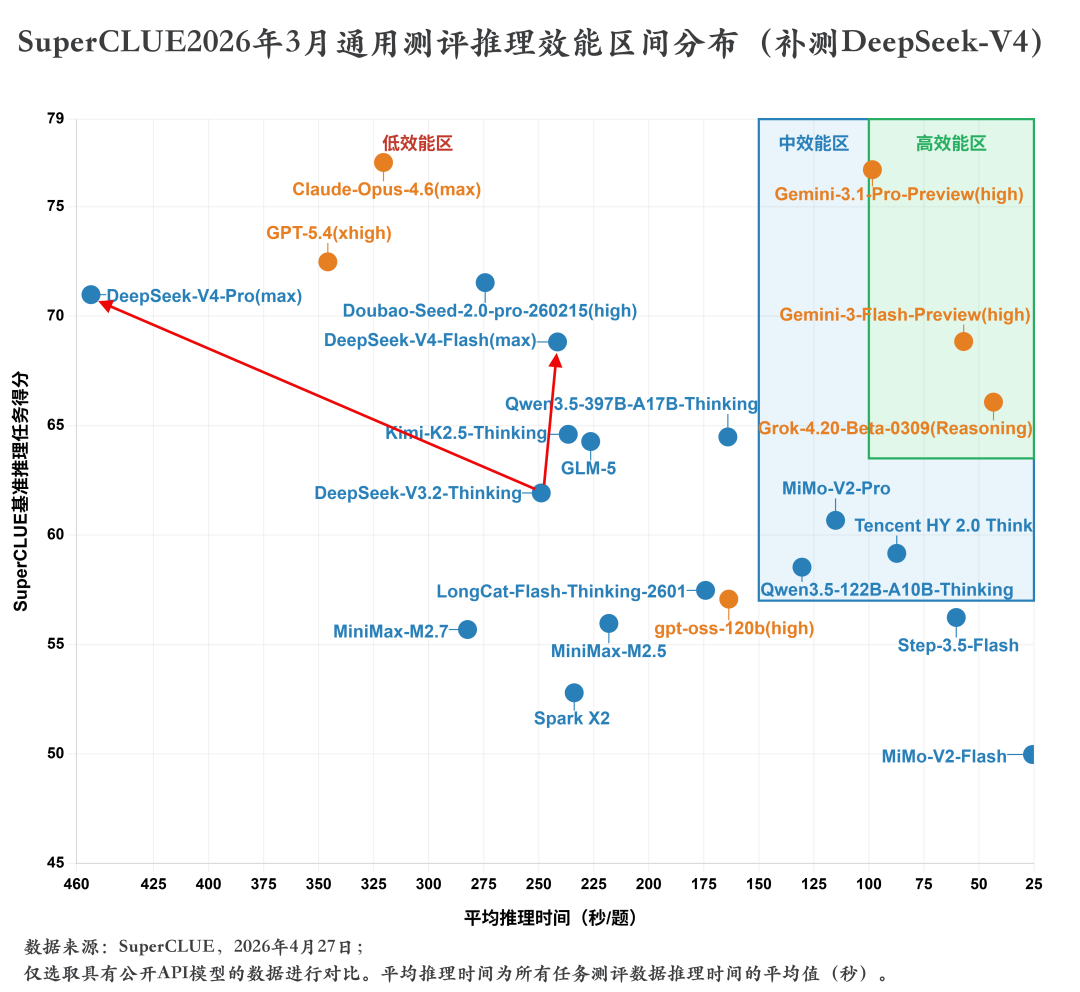
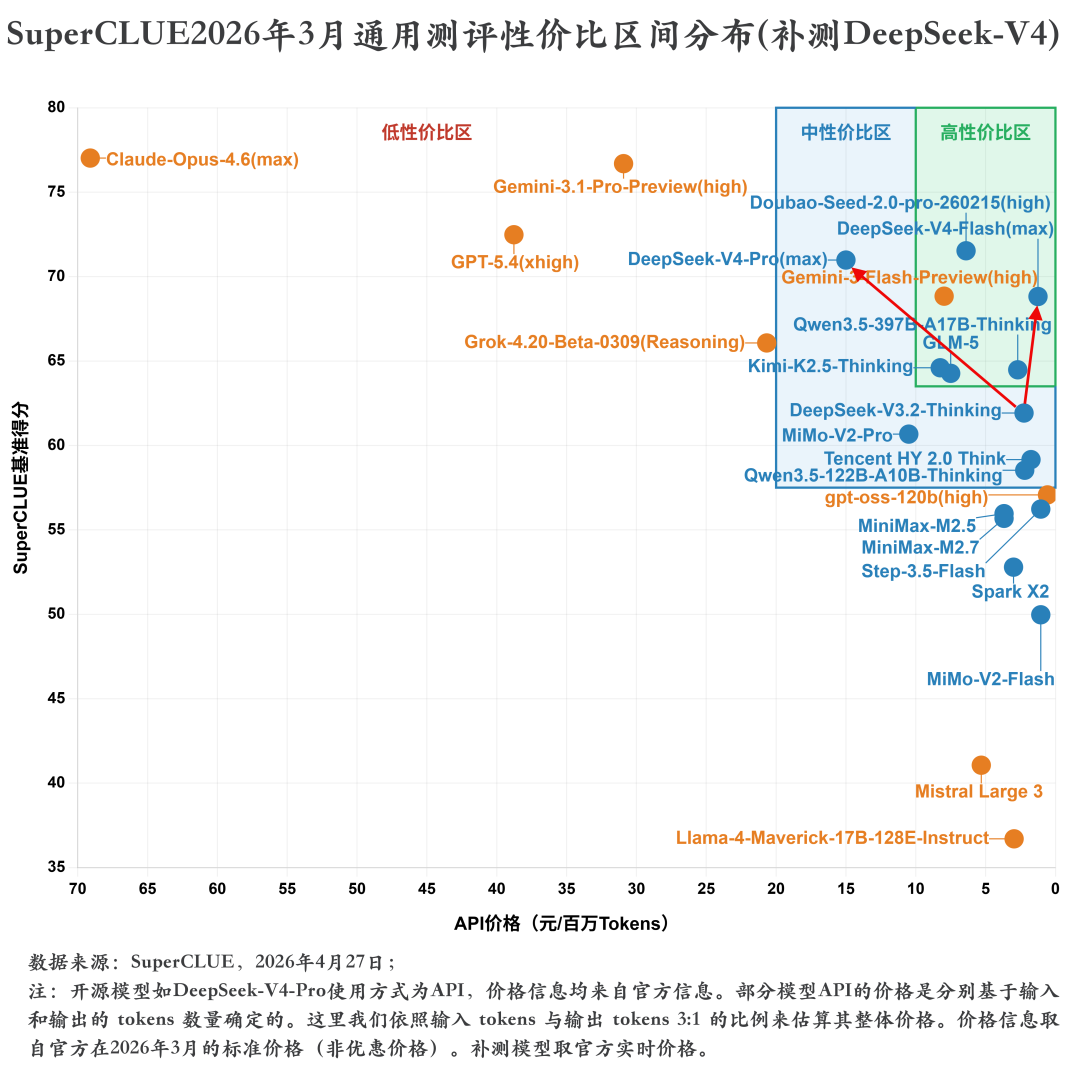
2. SuperCLUE开源模型对比(2026年3月通用测评)DeepSeek-V4-Pro(max)(70.98分)在3月中文通用能力测评中取得国内第一的成绩,六大任务均跻身国内前三。DeepSeek-V4-Flash(max)(68.82分)在3月中文通用能力测评中位于国内第二,整体表现不俗。DeepSeek-V4系列模型相较于V3.2整体提升显著,特别是在智能体(任务规划)、数学推理、科学推理以及指令遵循能力上,在代码生成和幻觉控制也有小幅优化,但相较于海外顶尖模型还存在一定的差距,差距主要在代码生成、指令遵循和智能体(任务规划)这三大任务上。DeepSeek-V4-Pro(max)在3月中文通用能力测评中领先Flash超2分,二者在推理能力上展现出相当的水平,甚至在数学推理任务上Pro版本(87.39分)由于过度思考稍逊于Flash版本(89.08分),但在应用能力上Pro领先Flash超过4分,特别是在幻觉控制任务上,Pro领先5分左右,更大的参数量让模型拥有了更加丰富的知识储备,能够更加有效地减少幻觉内容的输出。3. 与DeepSeek-V3.2-Thinking的对比DeepSeek-V4-Pro(max)相较于DeepSeek-V3.2-Thinking在六大维度上实现全面提升。其中智能体(任务规划)提升超过20分,指令遵循提升近12分,数学推理提升超9分,科学推理提升超6分,代码生成和幻觉控制均在3分左右。DeepSeek-V4-Flash(max)相较于DeepSeek-V3.2-Thinking在五大维度上实现全面提升,仅有幻觉控制任务出现小幅下降,其中智能体(任务规划)依旧是提升最显著的任务,提升接近19分,数学推理提升近11分,指令遵循提升超6分,科学推理提升近6分,代码生成有1分的提升。DeepSeek-V4-Pro(max)相较于V3.2平均每题耗时从248.84秒增加至453.44秒,整体推理效能较低;DeepSeek-V4-Flash(max)平均每题耗时为241.45秒,相较于V3.2推理效能较高。但从整体来看,DeepSeek-V4系列模型的推理效能并不高,均位于低效能区间,与Gemini-3系列模型存在显著差距;DeepSeek-V4-Pro(max)与同属于低效能区的海外顶尖模型GPT-5.4(xhigh)、Claude-Opus-4.6(max)相比依旧存在差距。在性价比方面,DeepSeek-V4-Pro(max)依旧处于中等性价比区间,虽然API价格(15元/百万Tokens,价格计算方式见下图中的注释)较V3.2(2.25元/百万Tokens)增加了6-7倍,但整体的性能提升显著。与Pro不同,DeepSeek-V4-Flash(max)在V3.2的基础上实现了性能的显著提升(61.92➡68.82),并且其API价格仅需1.25元/百万Tokens,位于高性价比区间。
测评说明
本次2026年3月通用基准测评共有24个国内外模型参与(包括补测模型),测评集包括六大任务:数学推理、科学推理、代码生成(含Web开发)、智能体(任务规划)、精确指令遵循、幻觉控制,共702题。
(1)详细的数据集介绍及测评说明可见:2026年3月中文通用大模型测评通知!
(2)2026年3月通用基准测评往期分析文章可见:
2026年3月中文大模型基准测评结果发布!小米MiMo-V2、美团LongCat上榜
2026年3月通用文本测评——SWE(软件工程)分析:海外旗舰领跑,国产模型梯队化突围
(3)点击下方阅读原文可跳转SuperCLUE官网,查看完整排行榜。
SuperCLUE排行榜地址:www.superclueai.com
[1] CLUE官网:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜网站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark/SuperCLUE
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库