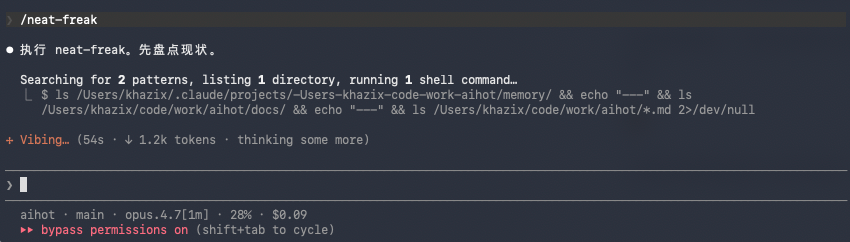
今天没选题了,所以想开源一个我自己做的,已经用了快1个多月,迭代了好多版的一个我觉得很有用的Skill。名字可能听着还挺呆逼的,但是我觉得它能干的事,虽然看着非常的简单,但是却又很实用,在公司内部同事和一些我们的合作伙伴使用后,还都反馈挺不错的。做的事大概就是,每次你在Agent里,做完一个功能或者又解决了一个BUG,就调用这个洁癖Skill,然后说一声帮我全面审查一下或者直接就/Neat一下,它就会自动审查你整个项目的文档体系和记忆文件,然后根据这次对话,把该改的文档、记忆、CLAUMD.md进行迭代,确保非常干净之后,最后,再给你一份变更摘要,让你知道改了啥东西。四个平台通用,Claude Code、Codex、OpenCode、OpenClaw都能装。相信我,这玩意会让你的Agent越来越聪明,也非常符合洁癖的定义。每次一个任务做完,要退出这个窗口的时候,如果不跑一遍/neat,我就浑身难受,如坐针毡如芒刺背如鲠在喉。如果你看过我之前写的那篇约束先行理念的文章,你大概能理解这种感觉。大家现在也都知道,在很多时候,你的Agent之所以越用越笨,其实是因为,你的上下文过于混乱。上下文不止是你跟你的Agent在单次对话中的聊天记录,也包括你这个项目里面的,各种文档,还有约束,还有记忆。但是其实很多的小伙伴,在用Agent的时候,比如CC和Codex去做一个项目,初期的文档规范倒是规划的挺好,但是每次迭代,每次更新,其实你会发现,这些文档和记忆,都是疏于维护,你可能代码都迭代了7、8轮了,新功能都上了无数了,但是你的文档,还是最开始的1.0.0版本的初始文档。其实不止Agent,很多公司内部项目的文档也都这样,前期雄心壮志,文档规范贼清晰,过两个月之后,规范?文档?你在说什么,我听不懂。我自己的项目里其实就出过这种事,就比如我做的AIHOT AI热点监控系统(PS:这个我最近会再打磨打磨降降成本,然后会免费向所有人开放,到时候也会发文章介绍,希望对大家有用。)光精选策略相关的功能就有乱七八糟的5、6个,一个信息抓到系统里,会需要十几个步骤进行数据清洗、加工、好几层评估等等,然后才会落库。现在每天处理的量级,在我严格挑选和管控信源的前提下,还是会有500多条信源产出的数据。然后我当时刚开始做的时候,其实想把整个项目后续封装成CLI,允许所有人的Agent都可以来浏览这上面的数据,能让大家用起来更方便,所以呢,我就把数据库从SQLite换成了PostgreSQL。但是这个切换其实工作量还是有点大的,当时用的还是Opus 4.6,时间一长的,真的就是顾头不顾尾,然后,搞完以后,文档啥的我忘记改了。结果后来我继续开发新功能的时候,Claude还在调用SQLite的语法,我当时还以为是模型啥的原因,搞了半天,发现是文档没改,包括我的CLAUDE.md里面,还赫然写着大概项目使用SQLite数据库这个意思。这种只是一个小摩擦,当你如果经历多了之后,你会发现,Agent很多时候犯的大多数莫名其妙的错误,根源其实都不是模型笨,是文档和记忆已经都脑腐了,都出现明显的混乱了。很多朋友可能会说,这不是专业开发者才需要关心的事吗?但是我想说,恰恰相反,很多我的专业开发者朋友都有自己的一套工程化习惯,git commit message写得规规矩矩,README随手就更新。真正被这个问题折磨最深的,反而是我们这些借助Agent来vibe coding的人,比如设计师、产品经理、内容创作者,当然也包括我自己。vibe coding前期特别爽,跟AI聊两句代码就出来了,功能也就跑起来了。但项目一旦做大,文档就不可避免地开始混乱,而且很多人也完全没有维护的概念,到最后就越来越混乱,你就会感觉到,我靠我的Agent怎么越来越笨。而这个维护,就是今天这个洁癖.skill,它要做的事情。之前Claude Code有一个功能叫AutoDream,也就是做梦,我也写过文章:Claude Code悄悄学会了做梦,我当时挺兴奋的,因为这玩意感觉就是我想要的东西?
但实际用了以后我发现一个很致命的问题。
AutoDream只动记忆,不动项目文档,这就尴尬的一比了。
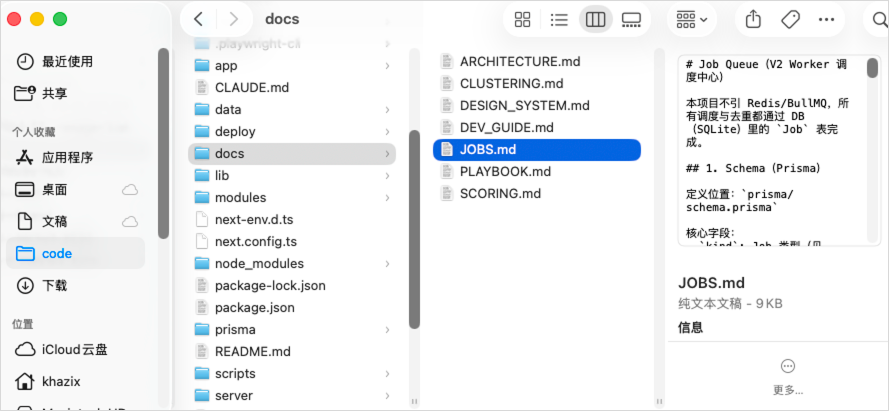
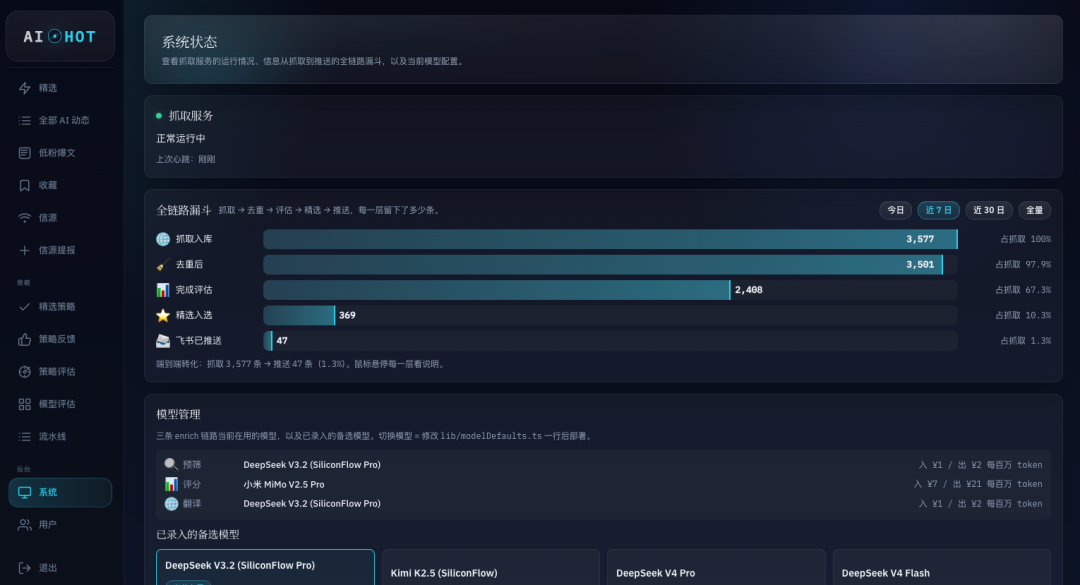
如果你用Agent开发过任何东西,你就知道,一个项目里的知识其实分三层,每一层服务的人不太一样。第一层是Agent自己的记忆系统,过去的聊天记录、项目的隐性知识。第二层是项目根目录的CLAUDE.md,给AI自己看的,项目约定、结构、红线、路由清单等等。第三层是docs/目录和README,给其他人看的,比如Agent、同事、下游开发者等等,比如接入指南、架构说明、运维手册等等。比如CLAUDE.md里写新增了五个路由不等于docs/integration-guide.md里写下游怎么接这五个路由。前者是提醒自己,后者是教别人,两份作用是完全不同的,都得写。AutoDream的问题就在于,它只管了第一层,记忆文件确实变干净了,但是另外两个,它确实是不管,所以也就导致,我用下来,确实作用不大。目前老规矩,已经在我自己的Skills仓库里面开源,所有人都可以随意使用:https://github.com/KKKKhazix/khazix-skills
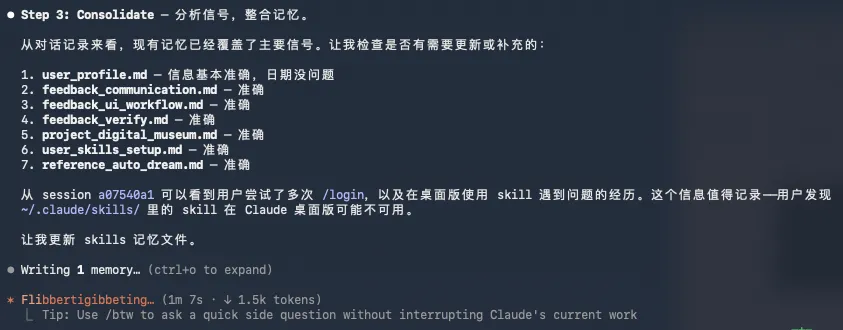
里面最核心的原则,其实就是合并优于追加,删除优于保留。这个跟大多数人的直觉是反的,因为很多时候,大家会觉得,信息多总比信息少好吧?万一以后用得上呢?但其实在AI协作的场景里,信息多不是优势,信息准才是,坦率的讲,一条过期的记忆,比没有记忆更糟糕,因为没有记忆的时候,AI至少知道自己不知道,它会问你。但如果它读到了一条过期的信息,它会以为那是对的,然后基于错误的前提做事。OpenClaw越用越笨,就是它的记忆系统实在是过于臃肿了。而当你安装了洁癖.skill,每次跑洁癖.skill的时候,它会按顺序做五件事。第一步,就是先强制机械式盘点。把项目里所有的md文件全列出来,每一个都读一遍,都不要漏掉,因为之前遇到过好几次,你看着是给你改了,结果哎就给你漏了那么一个文档,关键还是贼关键的。第二步,用我的变更影响矩阵文档去识别一下需要改什么。不只看对话里有什么新事实,也要去看新事实会波及哪些文档层级。然后这一步还有一个关键检查,这次对话是不是跨项目的?如果改了项目A而项目B依赖它,那项目B的docs也得跟着改,这个其实是历次同步最常翻的车。第三步,直接改,这里有一个顺序步骤,先改docs/,再改CLAUDE.md,最后整理记忆。第四步,自检清单,基本是我的skill里面的老演员了,必然都会有自检清单,就比如新增的环境变量,在runbook和CLAUDE.md都出现了吗?有没有相对时间遗留等等之类的东西,确认一遍。
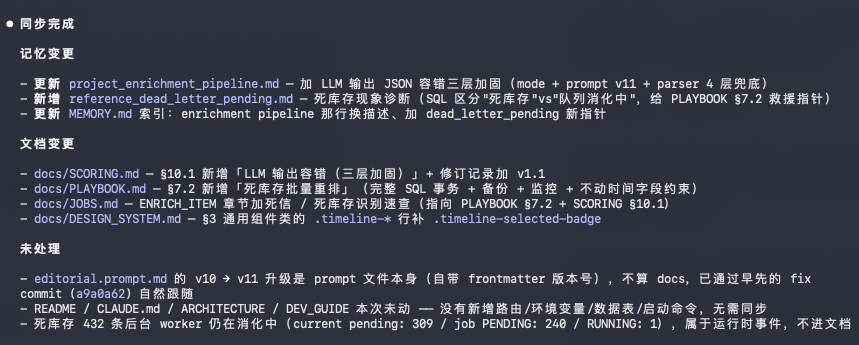
第五步,输出一份变更摘要,就是这样的东西。
这五步看着麻烦,其实就是skill自己的过程,你根本不用管,你要做的,就是运行一下这个skill。我自己一般在所有任务的收尾,都必定会运行一下/neat。我把洁癖.skill一般当类似于游戏的存档机制用,这次要结束了,要存档了,就运行一下/neat,然后,下次打开一个新的会话,还可以接着来。说实话,洁癖这个东西看起来只是在整理文档,但它真正解决的问题我觉得比整理文档有用的多。它会让你的知识体系从依赖对话上下文变成了依赖持久化文档,也就是说,对话可以随时关,但文档,永远在。因为上下文腐败问题,所以其实大家都懂,一个对话里,信息越多模型能力越差,然后再Claude里,虽然Opus 4.7说有1M上下文,但是我测试的时候,经常到了500K左右就有点不对劲了,所以我现在几乎是选择在400K左右进行一次整理并存档,然后新开窗口了。新开窗口以后,因为文档和记忆管理的足够好,所以你几乎不需要给任何提示,有任何问题直接说就行,Agent都能非常精准的给你解决,解决完了你继续/neat进行存档,你会发现,真的就是,越用越聪明。这个skill最近让公司同事和几个合作企业的朋友试了一下,大家居然意外的说挺好用的。过期的就删,重复的就合,模糊的就改。
让你的知识库,永远只保留此刻最准确的真相。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:卡兹克
>/ 投稿或爆料,请联系邮箱:wzglyay@virxact.com
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库