 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库林俊旸点赞!AI-First是年轻人的机会,最佳实践公开了

AI应用风向标(公众号:ZhidxcomAI)
编译|江宇
编辑|漠影
智东西4月15日报道,近日,前苹果机器学习专家、前Meta GenAI科学家、硅谷AI创企CreaoAI联合创始人兼CTO
Peter Pang
,在X上发了一条热帖,阅读量突破百万,引发业内广泛讨论。
不少行业人士纷纷转发评论,其中就包括前阿里通义千问团队负责人
林俊旸
,他还分享了自己对“AI-first”战略的独到见解。
在这篇名为《
为什么你的“AI优先”战略可能大错特错
》中,有几个核心观点值得关注:
1、人在AI时代可能成为障碍。
产品经理花几周设计需求,而AI两小时就能实现;QA测试需要三天,而AI写代码只用两小时;团队人数有限,远比不上竞争对手。效率的提升被传统流程严重限制。
2、AI-first意味着把人从日常构建链条中解放出来。
AI可以独立完成代码编写、审查、自动测试、部署上线和监控状态,出现问题自动回滚。每天AI定时扫描日志、发现问题、分配任务、跟踪修复,人只在关键节点做判断。
3、AI-first的成功依赖五个前提条件
:自动化测试、CI/CD全流程自动化、A/B测试与线上监控、任务管理和清晰的系统架构。
任何环节做不到,AI的速度优势就无法释放,AI-first也只是“一纸空谈”。
4、AI-first的真正目标是提升决策和流程效率
,而非让AI干所有工作。
它强调在每次决策时思考AI能做什么、缺失哪些条件,并建立扎实的基础设施,使AI能力真正释放。
5、小白更容易受益。
在AI-first转型中,适应能力比积累的经验更重要。要训练批判性思维,学会评估论证、发现漏洞、质疑假设。学习什么是好的设计,能力会逐步累积。
以下是该文章的全文翻译(智东西在不改变原意的前提下,做了简单的编辑):
我们99%的生产代码是由AI完成的
。上周二上午10点,我们上线了一个新功能,中午进行了A/B测试,下午3点因为数据不支持而下线。晚上5点,我们上线了一个更优版本。
三个月前,这样一个周期至少需要六周。但我们围绕AI重新构建了整个流程,改变了
团队计划、开发、测试、部署和组织
的方式,改变了公司中每个人的角色。
CREAO是一个Agent平台。团队中有10名工程师。我们从2025年11月开始构建Agent,但从两个月前,我从底层重构了整个产品架构和工程工作流。
OpenAI在2026年2月提出了一个概念,与我们的做法不谋而合。他们称之为:
Harness Engineering(Harness工程)
——工程团队的主要职责不再是写代码,而是让Agent能够执行有用工作。
当出现问题时,解决方案从来不是“更努力”,而是:
“缺失了哪项能力?如何让Agent可以理解并执行?”
我们自己也得出了这个结论,只是当时没有名称。
1、AI-First并不等于使用AI

大多数公司只是把AI附加到现有流程上。工程师用Cursor,产品经理用ChatGPT起草规格说明,QA用AI生成测试。流程没变,效率提高了10%到20%,结构没有改变——
这只是“AI辅助”
。
而AI-first意味着你要重新设计流程、架构和组织,
假设AI是主要的构建者
。你要问“如何重构一切,让AI完成构建,工程师提供方向和判断?”这种区别是
指数级
的。
我看到一些团队声称自己是AI-first,但他们只是把AI加到循环里,并没有重构循环。
一个典型例子就是所谓的“vibe coding”,这只能产生原型。
生产系统需要稳定、可靠和安全,你需要一个能保证这些属性的系统,prompt是一次性消耗品。
2、我们为什么必须改变
去年,我观察团队工作,发现三个瓶颈,如果不解决,会扼杀效率:
产品管理瓶颈
PM(产品经理)们几十年如一日,花数周研究、设计、撰写规格说明。但Agent能在两小时内实现一个功能。花数月考虑问题,然后在两小时内实现功能是没有意义的。
PM必须进化为快速迭代的产品架构师,通过“原型—发布—测试—迭代循环”进行设计。
QA瓶颈
Agent上线后,QA团队花几天测试边缘情况。开发两小时,测试三天。我们要用AI生成的测试平台取代了人工QA,
验证必须与实现速度一致,否则新的瓶颈会出现在原瓶颈下游
。
人数瓶颈
竞争对手可能有100倍以上的人力,我们无法通过增加人数来追赶,只能通过AI重构来实现。三个系统必须由AI贯穿:
产品设计、实现、测试
。任何一个保持手工操作,都会限制整个流水线。
3、大胆决定:统一架构
我必须
先修复代码库
。
旧架构分散在多个独立系统中,一处修改可能需触碰3-4个仓库。人类工程师尚可管理,但对AI Agent而言,太不透明,无法推理跨服务的影响,也无法在本地运行集成测试。
我必须把所有代码统一到一个monorepo中,让AI能看到全部内容。
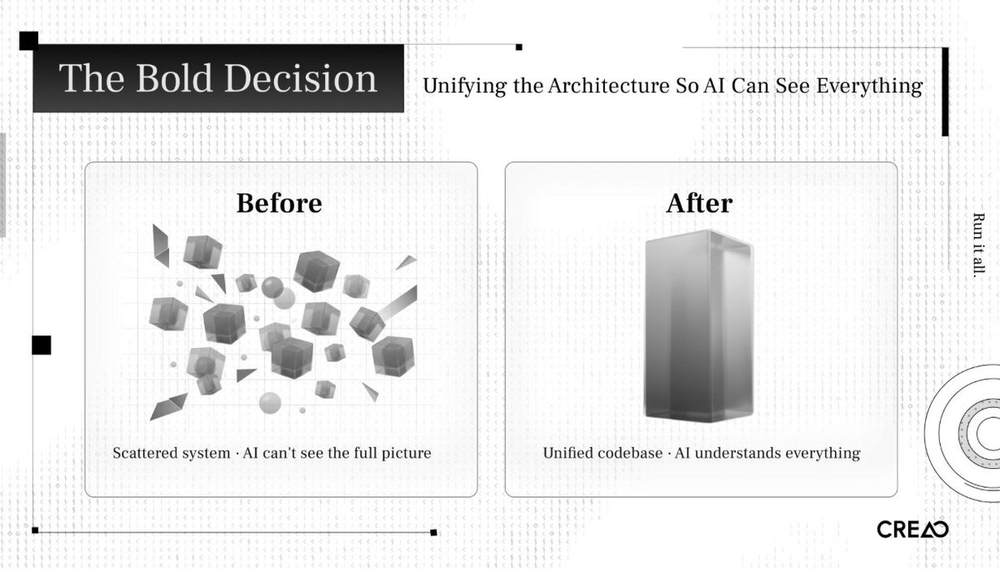
这是Harness工程的实践原则:
系统越多被Agent可读、可验证、可修改,杠杆作用越大
。
我花一周设计新系统:规划阶段、实现阶段、测试阶段、集成测试阶段。另一周用Agent重构整个代码库。
4、技术栈
以下是我们的技术栈及每部分的作用。
基础设施:AWS
我们在AWS上运行,使用自动扩缩容容器服务和熔断回滚机制。指标下降时,系统自动回。CloudWatch是中枢神经系统。每个服务的日志结构化,可查询,25个报警,指标每天由自动化工作流查询。AI如果无法读取日志,就无法诊断问题。
CI/CD:GitHub Actions
每次代码变更经过六阶段流水线:
验证CI→构建部署开发环境→测试开发环境→部署生产环境→测试生产环境→发布
每个阶段必不可少,也不能手动跳过。流水线是确定性的,因此Agent可以预测结果并推理失败原因。
AI代码审查
每次PR触发三次并行AI审查:代码质量、安全扫描与依赖核查。
这些审查门槛是“硬性需求”,人类无法全量关注每个PR。工程师还可在GitHub Issue或PR中@Claude,Agent能看到整个monorepo,上下文跨对话传递。
5、自愈反馈循环
核心机制为:
每天UTC 9:00,会
运行自动化健康工作流
,分析所有服务的错误模式,并生成执行摘要发至团队。
一小时后,
分诊引擎运行
。聚类生产错误,按九个严重性维度评分,自动生成Linear任务,包含日志样本、受影响用户和端点、建议调查路径。
系统去重
。如果同样错误模式已存在任务,更新它;若已关闭任务再次出现,检测回归并重新打开。
工程师推送修复
,流水线同样处理,三次Claude审查、CI验证、六阶段部署,部署后分诊引擎重新检查CloudWatch,如原错误解决,Linear任务自动关闭。

每日循环形成自愈闭环:错误被自动检测、分诊、修复和验证,人工干预最少。
6、从功能想法到生产
新功能流程
架构师定义任务(结构化prompt + 代码库上下文、目标、约束)
Agent分解任务、计划实现、写代码、生成测试
PR打开,Claude三次审查,人类审查战略风险
CI验证(类型检查、lint、单元/集成/端到端测试)
Graphite merge queue重跑CI,合并通过
六阶段部署流水线推进开发和生产环境的测试。
功能门控为团队开启,逐步增加比例并监控指标。如有问题,可用关闭开关立即下线,严重问题触发熔断回滚。
Bug修复路径
CloudWatch和Sentry检测错误
Claude分诊引擎评分,生成Linear任务
工程师调查,AI已完成诊断,人工验证并提交修复
走同一套严格的代码审查、验证、部署和监控流水线
分诊引擎复核,任务解决自动关闭
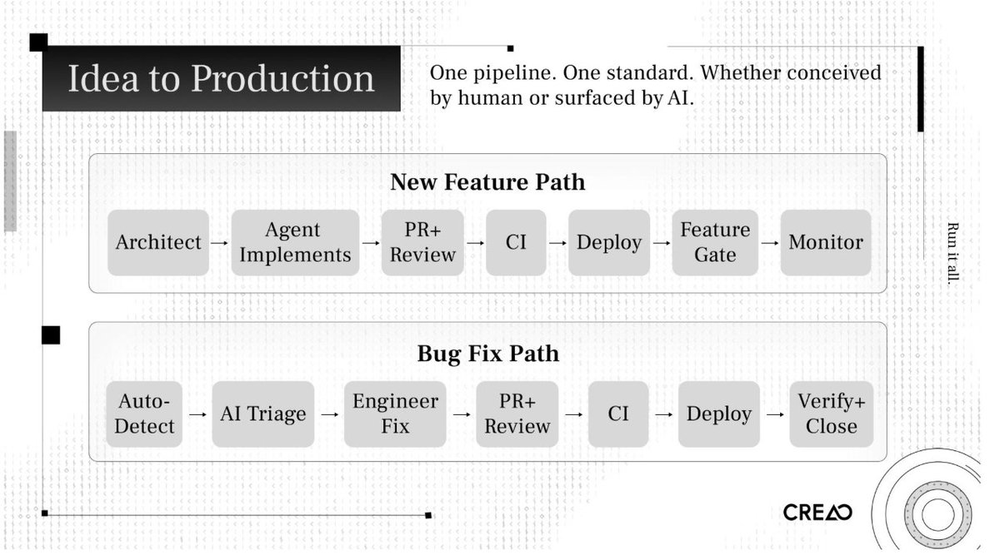
两个流程使用同一套流水线,一个系统,一个标准。
7、成果
14天内,每日平均3-8次生产部署。旧模式下,两周可能连一次发布都没有。
错误功能当日下线,新功能当日上线。A/B测试实时验证效果。
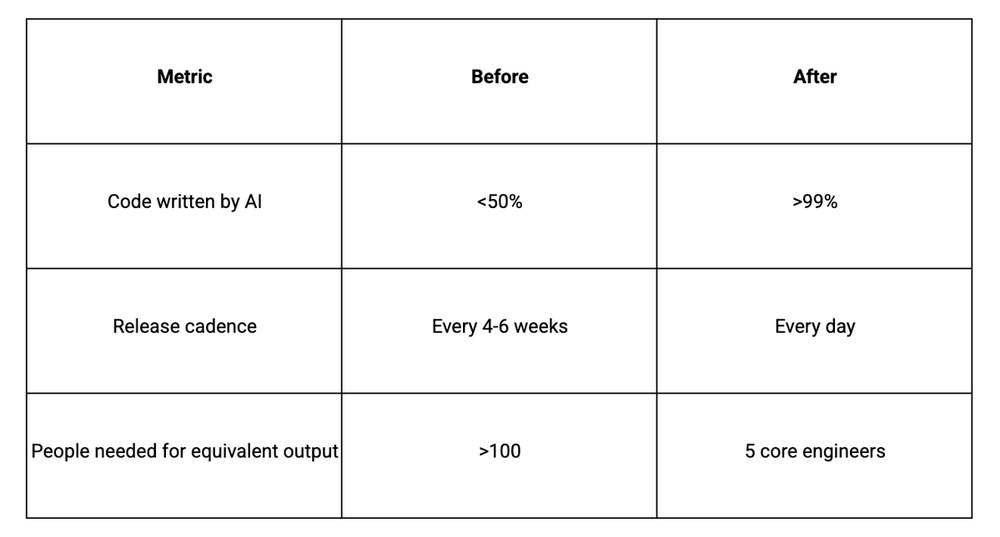
很多人以为我们为了速度牺牲质量,但用户参与度和付费转化率提升。因为反馈循环更紧密,每日发布学到的东西比每月发布更多。
8、新工程组织
新组织将存在两类工程师:
架构师
1-2人。设计SOP教AI工作,构建测试、集成和分诊系统,决定架构和系统边界,定义Agent“好”的标准。需要深度批判性思维,质疑AI、发现漏洞、分析潜在安全和技术负债。
操作员
负责具体执行任务的团队成员。他们的工作仍然关键,但流程和责任与传统角色有所不同。AI分配任务,分诊系统生成任务并指派给合适人选,人类调查、验证、批准修复。
任务包括Bug调查、UI优化、CSS改进、PR审查、验证。需要技能和专注,但不要求传统架构推理能力。
9、谁适应得最快
在AI-first转型中,团队发现初级工程师适应得比资深工程师更快,因为他们没有长期的传统工作习惯包袱,可以更自然地利用AI工具放大影响力。
而资深工程师则适应较慢,他们过去需要两个月完成的工作,现在AI一小时就能完成,这对长期习惯深厚的人来说,是一大挑战。
在这个转型中,适应能力比积累的经验更重要。
10、人类层面
管理工作减少
两个月前,我60%时间用于管理。现在低于10%。从管理转向构建,工作时间从早9点工作到凌晨3点点,设计SOP和架构,维护Harness。
虽然更累,但我更享受构建的过程。
争论减少,关系改善
以前团队交流多为会议、争论、权衡,现在非工作话题更多,关系更好。
不确定感真实存在
在转型过程中,部分团队成员感到不确定:CTO不天天交流意味着什么?我在新模式下的价值是什么?
有些人花更多时间在讨论AI能否替代他们的工作。
我的原则是,无论是人还是AI出现问题,都不因为一次错误就惩罚责任方。团队会通过改进审查流程、加强测试和增加约束条件来解决问题,从而保证系统安全和稳定。
11、跨越工程之外
其他部门仍手工操作会成为瓶颈。工程、产品、市场和增长团队运行在统一的AI-native流程中。如果某个职能按Agent速度运作,而另一个按人工速度运作,慢的那部分就会限制整体效率。
12、对工程师的启示
价值从代码产出转向决策质量。快速写代码越来越不重要,而评估、批判和指导AI变得更重要。
产品感觉和判断力也关键:能否在用户反馈前发现问题,并提前做出调整?
我告诉19岁的实习生:
训练批判性思维。学会评估论证、发现漏洞、质疑假设。学习什么是好的设计。这些能力会逐步累积。
13、对CTO与创始人的启示
如果你的PM流程耗时超过构建时间,从这里开始着手。
在扩展Agent前先构建测试Harness。快速的AI输出如果缺乏验证,会产生快速累积的技术债务。
先从一个架构师开始,一个人构建系统并证明其可行。系统稳定后,再让其他人进入操作员角色。
推动AI-native进入每个职能。
做好心理准备:有些人会反对。
14、对行业的启示
OpenAI、Anthropic及独立团队在结构化上下文、专业Agent、持久记忆和执行循环方面达成共识。Harness Engineering正成为行业标准。
模型能力是驱动这一转变的时钟:Opus 4.5做不到的事情,Opus 4.6可以完成。下一代模型还将进一步加速。
我相信一人公司模式将会普及:一个架构师带Agent即可完成100人工作,许多公司无需第二名员工。
15、我们仍处于早期
我接触的大多数创始人和工程师仍在按传统方式运作。有人在考虑转型,但很少有人真正实践。
工具对任何团队都是可用的。我们的技术栈没有专有限制。竞争优势在于决定围绕这些工具重构一切,并且愿意承担成本。
成本是真实存在的:员工的不确定感,CTO每天工作18小时,资深工程师重新审视自身价值,旧系统消失而新系统尚未完全验证的两周过渡期。
我们承担了这些成本。两个月后,数据说明一切。
林俊旸的观察与思考
在Peter Pang的AI-first实践之后,前阿里通义千问团队负责人林俊旸也分享了他对AI-first战略的理解:
批判性思维至关重要
在Agent时代,人类需要与AI“辩论”,通过列举理由、分析问题,达成更深入的认知和全面的判断。
健康且结构良好的组织与系统必不可少
完善的体系与高效工具能让人类与AI协作效率成倍提升,同时为员工争取更多时间照顾身心、探索新机会。
新人更容易受益
因为经验包袱较轻,对当前困难的恐惧少。资深工程师则需仔细甄别哪些经验值得保留,哪些与第一性原则相符。
林俊旸总结道:“
无论如何,AI-first都是极其令人兴奋的机会。
”





