 五度妙笔
五度妙笔 API商城
API商城
 数据库
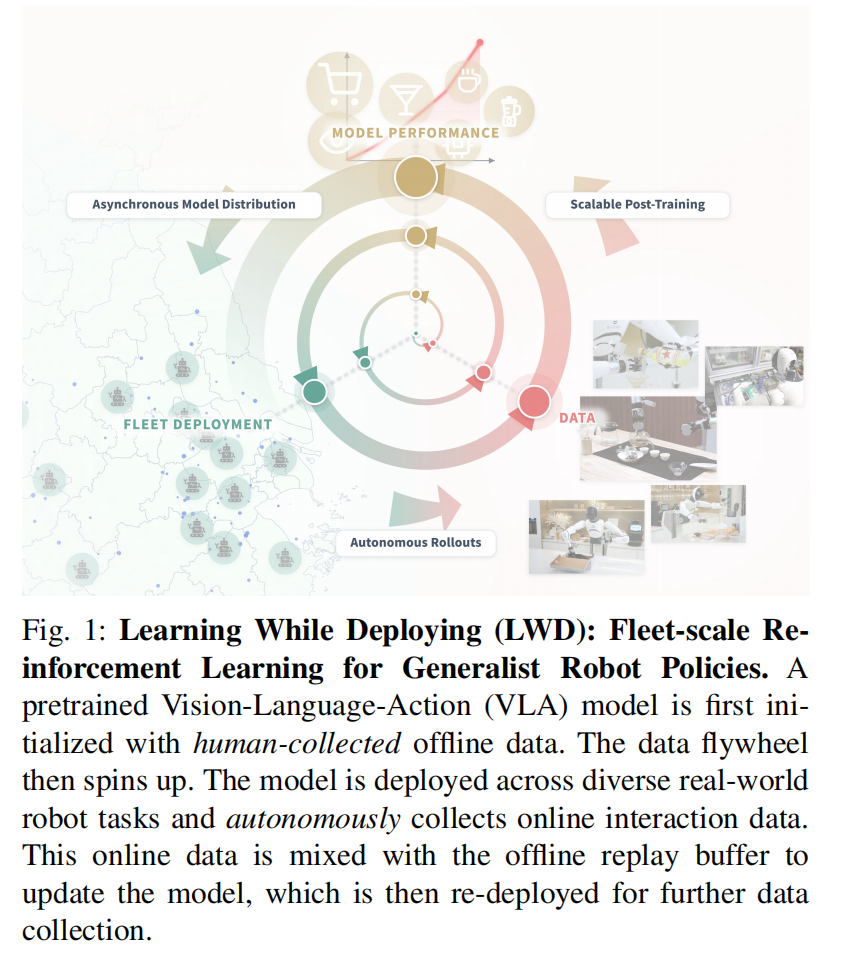
数据库首次大规模真实世界验证:机器人边部署边进化,8项任务全面碾压基线
家人们,不得不承认,这一年来,具身智能是真的越来越出圈了。
从春晚穿着大花袄扭秧歌的机器人,到被万人围观的机器人马拉松,今年真是我最真切感受到机器人走近生活的一年——而且走得特别近。
作为一名长期关注具身智能的科技博主,我一直期待着机器人能从实验室走到我家里稳稳当当地开工干活。
最近和一位行业内的朋友深聊,他聊到一个研发成本公式:
研发成本 ≈ 真机调试时间 × 硬件折旧 × 数据未利用率
真机调试不仅耗时,风险也大,机器人摔一跤,那可都是真金白银。而且目前的仿真环境还存在虚实偏差,还不能完全替代真实调试。
更大的问题是,数据利用率提升缓慢。
虽然机器人在真实场景中每天产生海量数据,但那些宝贵的失败轨迹,却因为缺乏高效提炼机制,很难被转化为高价值的学习素材。
这些局限,导致机器人的进化步伐,远远赶不上复杂现实中层出不穷的长尾问题。
去年,我就关注到智元机器人提出的 SOP(可扩展在线后训练)系统,让机器人在真实部署中能边干边学。
智元研究传送门:
https://finch.agibot.com/research/lwd
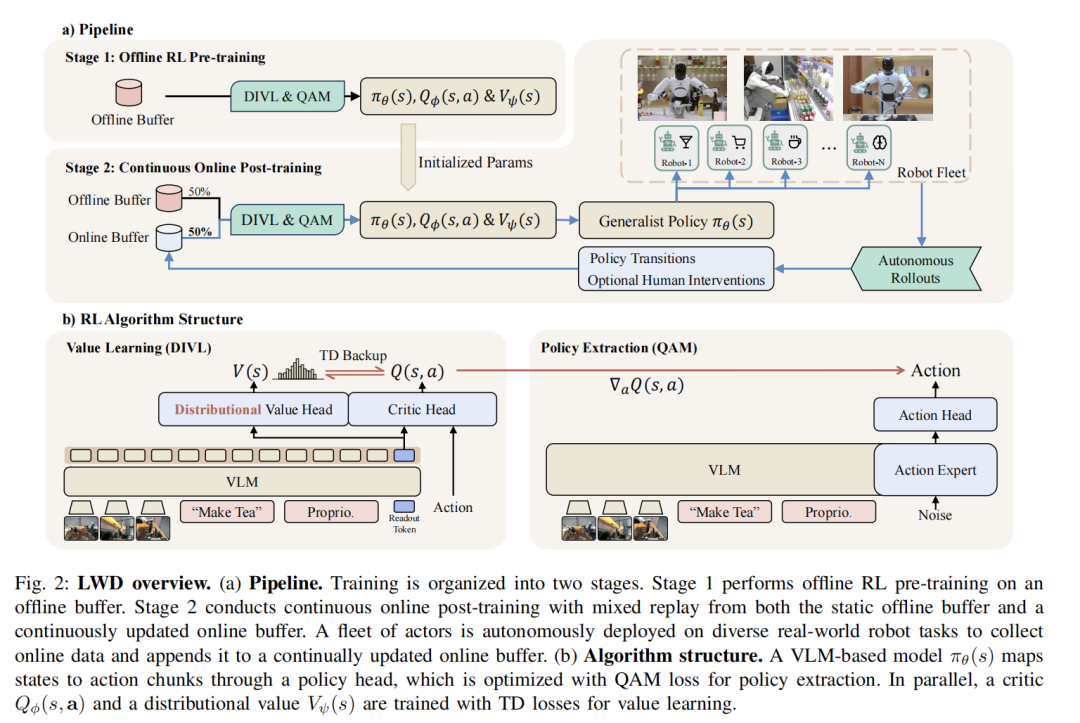
最近,上海创智学院和智元具身研究中心联合发布推出了更强大的 LWD (Learning While Deploying)边部署边学习框架。论文第一作者为创智学院在读博士生,指导老师为创智学院导师,智元首席科学家罗剑岚。我第一时间啃完论文,今天给你们讲透!

传送门:
https://finch.agibot.com/research/lwd
◈从「人喂数据」到「数据飞轮」
传统的机器人训练流程是单向的:人收集数据 → 训练模型 → 部署 → 结束。模型出厂即定型,部署之后不再进化。如果表现不行,回到起点让人再收集一批数据重新训练。
这个流程有一个根本性浪费,机器人在真实世界中产生的大量失败轨迹、半成功的尝试、人类临时接管的纠偏操作——这些「非完美数据」在模仿学习范式下全是废料。
罗剑岚团队提出了LWD,把这个单向流程变成了一个强化学习驱动的闭环飞轮。
机器人集群在真实任务中执行 → 积累所有类型的交互经验 → 经验汇总到云端 → 强化学习持续更新策略 → 更强的策略重新部署到集群 → 飞轮再转一圈。
在LWD的强化学习框架里,成功的轨迹是正样本,失败的轨迹是负样本,半成功的尝试提供了中间状态的价值信号,人类介入的纠偏记录标注了哪些环节容易出问题——它们全都会被飞轮吸收进策略的下一轮更新。机器人搞砸的每一次操作,都变成了它变强的素材。
而且飞轮的转速跟集群规模正相关——机器人越多、跑的时间越长,积累的经验越丰富,学习越快。跟自动驾驶的数据飞轮是同一个逻辑。
听起来很直觉,但想在真实世界的大规模部署中跑通强化学习,技术上远没有这么简单。
因为多机器人、多任务、持续部署这种场景,跟实验室里的RL面对的是完全不同的技术困境。
第一,数据异质且持续漂移。
不同机器人在不同环境下执行不同任务,产生的数据分布差异极大。每次策略更新后,产生的轨迹分布也在变,这种持续的分布偏移,会让标准RL方法的价值估计迅速失准。
第二,奖励信号极度稀疏。
长程操作任务(比如泡功夫茶,3-5分钟连续操作),中间大部分步骤没有明确奖励反馈,只有最终成功或失败才有信号。
第三,VLA的动作生成机制跟传统RL策略梯度不兼容。
这一点很关键。当前主流VLA策略的动作是通过flow matching多步生成的,没法直接算动作似然,也就没法直接用策略梯度。硬做反向传播穿越整个生成链,计算代价极高且数值不稳定。
LWD针对前两个难点设计了DIVL(价值评估模块),针对第三个难点设计了QAM(策略优化模块)。下面拆这两个核心技术。
一个前置知识:LWD里机器人不是逐帧决策的,而是以动作块「Action Chunk」为单位。
一次规划未来H步的连续动作序列,执行完再规划下一组。后面所有的价值评估和策略优化都是在这个「动作块」粒度上操作的。
机器人执行了一组动作之后,怎么知道这组动作好不好?
◈DIVL—价值评估模块
传统的隐式Q学习(IQL)是维护一个标量Q值函数,但是在LWD面对的fleet-scale场景,来自不同机器人、不同任务、不同时期策略的轨迹全混在一起,标量回归容易过拟合,加上长程任务中奖励极度稀疏,标量估计的不确定性会被进一步放大。
DIVL 的解决方案在于改变评估方式:它不再输出一个单一的固定分数,而是学习一个完整的价值概率分布,从而提供一个包含不确定性的价值置信区间。
具体来说,它通过以下四个核心设计来实现:
DIVL 为每个状态维护了一个价值分布模型,通过训练预测未来回报落在各个离散区间的概率:
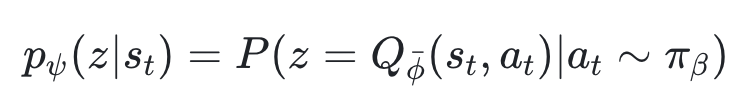
在计算时序差分目标时,DIVL 从预测的价值分布中提取上分位数。这种方法既继承了IQL向高价值靠拢的原则,又能更好地应对奖励稀疏和真实数据分布偏移的挑战:

利用预测分布的归一化熵 H(s) 作为不确定性信号,当面对价值分布散乱、机器人心里没底的状态时,自动调低分位数阈值以防止过度乐观;对于模型确信的状态,则使用较高的 τ 来积极寻求高回报:
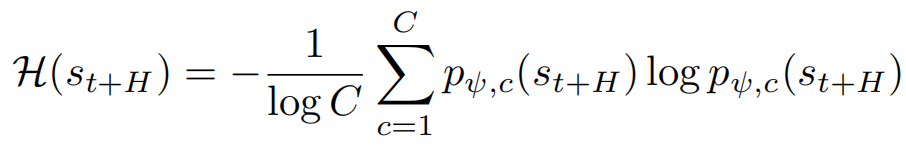
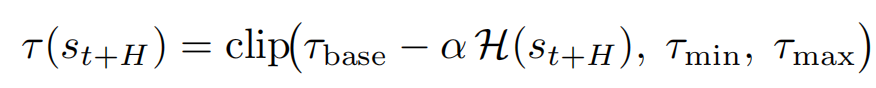
为高效学习包含数千步的复杂长程任务,DIVL 采用了动态的 n 步 TD 策略—在离线训练时使用多步更新(如10步),以加速长程奖励信号的传播;在在线部署时则切换为单步更新,以降低方差,确保学习稳定。
◈QAM —策略优化模块
有了精准的价值评估,下一步是策略改进。
当前先进的视觉-语言-动作 模型,通常采用流匹配 作为其动作生成器,该模型从一个简单的纯高斯噪声 a^0 出发,通过一个学习到的向量塑造成连贯的动作 a^1:
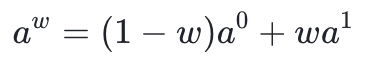
其中,参数 w从0到1,代表了从噪声到完美动作的整个生成轨迹。
如果直接用传统的反向传播来优化这个多步生成过程,计算量极大且数值不稳定,如同逆推一条湍急河流中每一滴水的轨迹。
为此,LWD 框架引入了基于伴随匹配的Q学习 (Q-learning with Adjoint Matching,QAM),将策略优化转化为一个沿生成轨迹的局部回归目标:
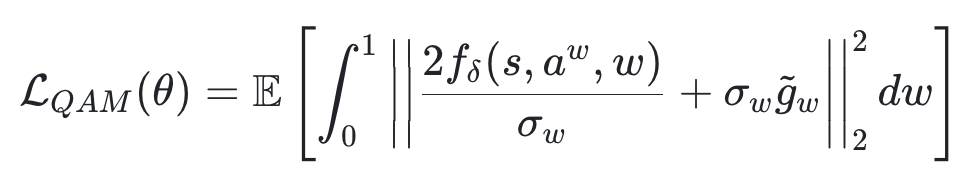
这个目标训练的关键在于终端条件,它由 DIVL 训练出的价值评估网络提供的梯度进行初始化 :
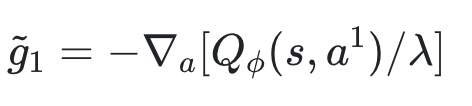
QAM 这种方法不再费力地穿越整个动作生成链进行反向传播,而是直接在动作生成的终点,利用价值网络算出一个指引方向的梯度。
这个梯度如同一个向导,牵引着整条动作生成轨迹向更高回报的方向平滑偏移。
这样一来,生成式动作网络就能平滑改进,摆脱了对显式动作似然计算的依赖。机器人真正做到了“学会新本事,不忘旧技能”。
◽实战成绩单
研究团队在 Agibot G1 双臂机器人上跑了 8 项高难度任务,分两组:
- 商超补货(4项)
常温货架补货、冷柜补货、开门补货、纠正摆放错误。主要考验对商品的语义识别和指令理解。 - 长程操作(4项)
泡功夫茶、调鸡尾酒、榨果汁、装鞋入盒。每项任务持续3-5分钟,包含5-7个接触丰富的物理交互子步骤——加茶叶、冲水、洗茶、倒茶、分茶,任何一步搞砸整个任务判定失败。

实验结果还是非常清晰明确的:
随着 LWD 数据飞轮的转动,机器人在功夫茶任务中的成功率,比原本的离线版本直接飙升了 17%。
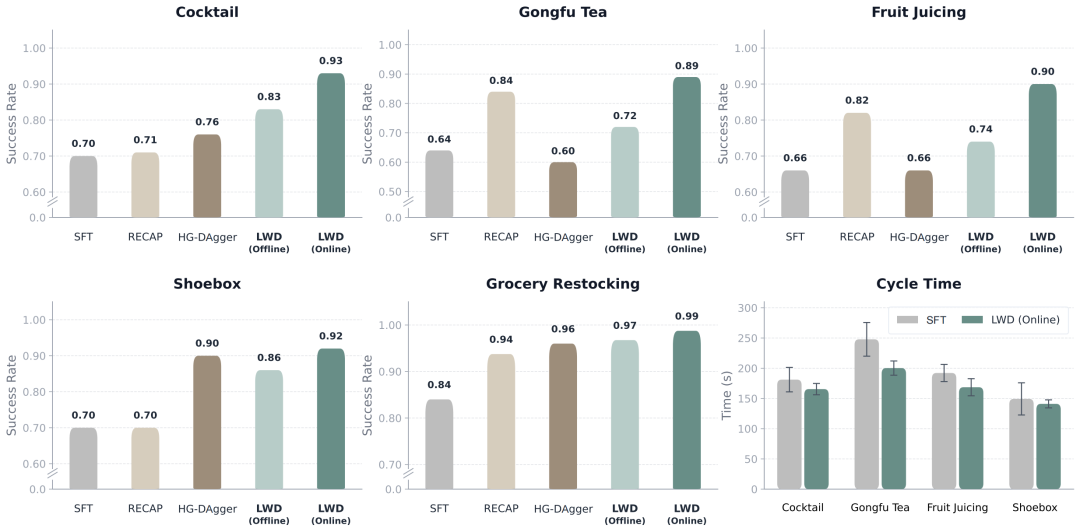
在榨果汁任务中获得 16% 的巨大提升。这证明机器人确实能从实战的错题本中吸取教训,实现自我迭代。
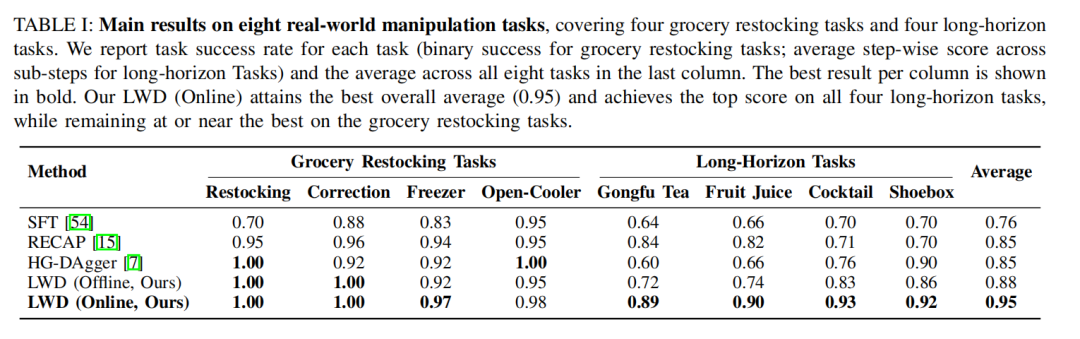
面对 RECAP、DAgger-SOP 等业界先进的基线方法,单一通用策略下的 LWD 在线版本拿下了 0.95 的平均成功率 。作为对比,RECAP 的平均分为 0.86,而 DAgger-SOP 为 0.82,LWD 展现了绝对的压倒优势。
LWD 不仅做得更准,而且做得更顺。在极其繁琐的长程任务中,它的平均循环时间(Cycle Time)足足缩短了 23.75 秒 。
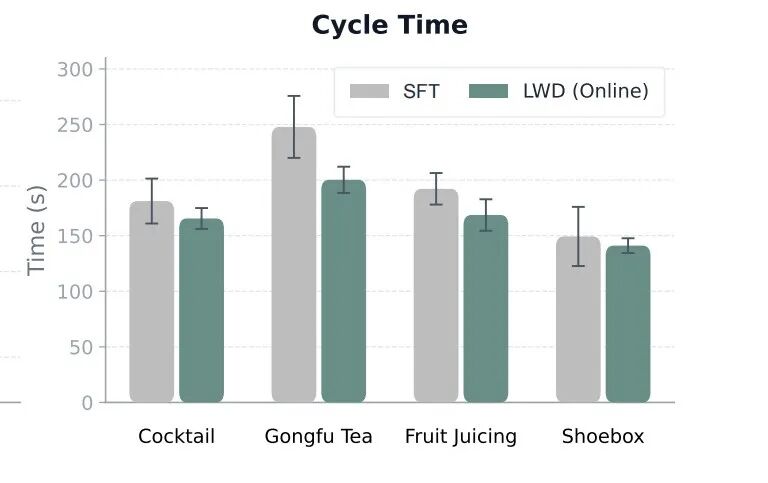
这说明机器人真的开窍了,开始学会优化动作路径、避开无效动作,干活变得越来越利落。
◽结语
从去年的SOP到今年的LWD,罗剑岚团队一直在做一件贯穿始终的事:将机器人训练的主战场,彻底推向真实世界,让干活本身,成为性能进步的引擎。
SOP的意义,在于构建了一套可扩展的在线后训练高速路,让机器人首次打开边干边学新世界。
而LWD的突破,我觉得是给这条路装上了自驾辅助系统—它让机器人在前进中,能不断从自身的每一次交互、尤其是那些错误与意外中,主动提炼更深层、更高价值的优化信号。
至此,机器人进化的驱动力,正在由昂贵的外部人工指令,悄然转向了强大的内在经验涌现
2026年,具身智能的故事又写下了激动人心的新篇章~







