 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库导师:“为什么训练集99%,验证集却崩了?”我:“模型没调好?”导师:“先别怪模型,八成是异常值把数据带歪了!”

很多同学学机器学习的时候,会把重点都放在模型上,比如随机森林、XGBoost、神经网络怎么调参。
但真到实际项目里,模型之前的数据清洗,往往才是最影响结果的环节。
这里,我们就专门把数据清洗里的异常值处理讲透。
01什么是异常值
一句话概括:
异常值,就是那些和大多数样本“很不一样”的数据点。
大家可以这样理解:
如果大部分人的月薪都在 8k 到 20k 之间,突然有一条写着月薪 300 万。
这条数据要么是录入错了,要么这个人身份特殊,总之它和其他数据明显不在一个层级上。
这类数据,我们就会怀疑它是异常值。
但是这里有个特别重要的点:
异常值不一定是错的。
它有可能是录入错误,也有可能是真实但稀有的现象。
这句话很关键,口语化翻译一下就是:
不是所有“离谱”的数据都该删。
为什么异常值会影响机器学习模型?
因为很多模型对极端值非常敏感。
比如:
均值会被极端值拉偏 标准差会被极端值放大 线性回归会被少数离群点“拽歪” 基于距离的模型,比如 KNN、KMeans,会被异常值干扰距离结构 梯度优化时,极端样本会让损失函数变化很大,训练不稳定
总之就是说,异常值最可怕的地方,不是它少,而是它会“带偏整体判断”。
02一个通俗例子
我们这里先不用模型,先用一个特别通俗的小例子给大家建立直觉。
假设有 5 个小朋友的身高,单位是厘米:
前 4 个都很正常。
最后一个是 300 cm,显然不合理。
先看平均值
平均值是:
你会发现,平均身高居然变成了 157.2 cm。
这明显不对。
因为前面 4 个人明明都在 120 左右,结果被一个 300 直接拉高了。
这就是异常值最直观的影响。
再看中位数
把数据排序:
中位数是中间那个数:
这个值就合理很多。
所以这里你会得到一个非常重要的认知:
均值对异常值敏感 中位数对异常值更稳健
当数据里有极端值时,均值容易被带跑偏,中位数更靠谱。
03异常值到底怎么判断
很多同学一看到异常值处理,就开始找“万能算法”。
但这件事其实没有万能答案。
因为判断异常值,通常取决于 3 件事:
业务含义 数据分布 模型类型
我们先把常见方法过一遍。
1)基于业务规则判断
这是最靠谱的一类方法。
比如:
年龄不能小于 0,也不能大于 120 身高不能是 500 cm 商品销量不能是负数 考试分数不能超过满分
这种属于规则型异常值。
它的特点是:不用统计方法,直接靠常识或业务约束判断。
2)基于统计分布判断
这类方法最常见。
Z-Score 方法
如果一个值离均值太远,就认为它异常。
公式是:
其中:
:当前样本值 :样本均值 :样本标准差
通常如果:
就会把它看作异常值。
这个方法的核心逻辑是:
看一个点离“平均水平”有多远。
但它有个前提:数据最好接近正态分布。
如果数据本身偏态很严重,这个方法就没那么稳。
IQR 四分位距方法
这个方法在实战里非常常用,而且更稳健。
第一四分位数: 第三四分位数: 四分位距:
然后设上下界:
超出这个范围的数据,就可以认为是异常值。
这个方法的优点是:
不太怕极端值 不要求正态分布 对偏态数据也常常好用
它不是拿均值做中心,而是看中间 50% 数据的稳定范围。
所以一般比 Z-Score 更稳。
3)基于模型判断
当数据是多维的,单看某一个特征不容易发现异常值时,就可以考虑模型方法。
常见的有:
Isolation Forest(孤立森林) Local Outlier Factor(LOF) One-Class SVM DBSCAN 聚类检测离群点
今天我们后面案例会重点用 Isolation Forest。
因为它在实战里很好用,而且 sklearn 直接支持。
就是说,越容易被“单独隔离”出来的点,越可能是异常值。
比如一堆点都聚在中间,只有几个点飞得很远。
这些飞出去的点,很容易被树结构快速切分出来,于是异常分数就会更高。
04异常值怎么处理
很多人一提异常值处理,就条件反射:删掉,说实话很管用,但是还是有些方法可以试试的。
1)删除异常值
适合场景:
明确是录入错误 数据量足够大 异常值占比很小 删除不会破坏数据分布
比如年龄是 999,身高是 0,收入是负数。
这种一般直接删。
但要注意:如果异常值本身是真实稀有样本,删掉可能会损失重要信息。
2)截断 / 缩尾
比如把特别大的值压到上限,把特别小的值抬到下限。
举个例子:
小于第 1 百分位的,统一替换成第 1 百分位 大于第 99 百分位的,统一替换成第 99 百分位
这样做的好处是:
保留样本数量 降低极端值影响 比直接删除更温和
不把它扔掉,而是把它“拉回合理区间”。
3)替换为统计量
比如替换成:
中位数 均值 分组中位数 业务约定值
通常在数值特征里,中位数会更稳。
4)做变换
像对数变换就是非常常见的一种:
它适合处理右偏严重的数据,比如:
收入 金额 浏览量 销量
因为这类数据往往少数值特别大,取对数后,大值会被压缩,小值差异还能保留。
5)使用对异常值不敏感的模型
这也是一种思路。
比如:
树模型通常比线性回归更抗异常值 使用 RobustScaler 而不是 StandardScaler 使用 Huber loss、MAE 等更稳健的损失函数
这类做法的意思是,不一定非要把异常值处理掉,也可以让模型变得更稳。
05完整案例
这里,我们做一个房价预测任务,数据集包含这些特征:
area:面积rooms:房间数age:房龄distance:距离市中心距离income_level:周边收入水平price:房价(目标值)
其中,我们会故意往数据里注入一些异常值,比如:
超大面积豪宅 极端高价房 错误录入的超远距离 异常房龄
然后比较:
原始数据训练模型效果 处理异常值后训练模型效果
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import IsolationForest, RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import RobustScaler
from sklearn.pipeline import Pipeline
# 1. 数据
np.random.seed(42)
n = 1500
area = np.random.normal(100, 20, n).clip(40, 180)
rooms = np.random.choice([1, 2, 3, 4, 5], size=n, p=[0.1, 0.25, 0.35, 0.2, 0.1])
age = np.random.normal(12, 6, n).clip(0, 35)
distance = np.random.normal(8, 3, n).clip(0.5, 25)
income_level = np.random.normal(60, 15, n).clip(20, 120)
price = (
area * 18000
+ rooms * 80000
- age * 15000
- distance * 30000
+ income_level * 12000
+ np.random.normal(0, 150000, n)
)
df = pd.DataFrame({
"area": area,
"rooms": rooms,
"age": age,
"distance": distance,
"income_level": income_level,
"price": price
})
# 2. 注入异常值
outlier_idx = np.random.choice(df.index, 20, replace=False)
df.loc[outlier_idx[:5], "area"] = np.random.uniform(300, 800, 5)
df.loc[outlier_idx[5:10], "price"] = np.random.uniform(15000000, 40000000, 5)
df.loc[outlier_idx[10:15], "distance"] = np.random.uniform(40, 100, 5)
df.loc[outlier_idx[15:20], "age"] = np.random.uniform(50, 120, 5)
# 避免价格为负
df["price"] = df["price"].clip(200000, None)
# 3. 可视化设置
plt.rcParams["figure.figsize"] = (10, 6)
# 图1:面积-价格散点图
plt.figure()
sns.scatterplot(data=df, x="area", y="price", hue="rooms", size="income_level", palette="bright", alpha=0.8)
plt.title("图1:面积与房价关系(含异常值)")
plt.show()
# 图2:各特征箱线图
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
sns.boxplot(y=df["area"], ax=axes[0, 0], color="#FF6B6B")
axes[0, 0].set_title("图2-1:面积箱线图")
sns.boxplot(y=df["age"], ax=axes[0, 1], color="#4ECDC4")
axes[0, 1].set_title("图2-2:房龄箱线图")
sns.boxplot(y=df["distance"], ax=axes[1, 0], color="#FFD93D")
axes[1, 0].set_title("图2-3:距离箱线图")
sns.boxplot(y=df["price"], ax=axes[1, 1], color="#6C5CE7")
axes[1, 1].set_title("图2-4:房价箱线图")
plt.tight_layout()
plt.show()
# 图3:相关性热力图
plt.figure(figsize=(10, 8))
corr = df.corr(numeric_only=True)
sns.heatmap(corr, annot=True, cmap="Spectral", fmt=".2f")
plt.title("图3:特征相关性热力图")
plt.show()
# 4. 用 Isolation Forest 检测异常值
features = ["area", "rooms", "age", "distance", "income_level", "price"]
iso = IsolationForest(
n_estimators=200,
contamination=0.04,
random_state=42
)
df["outlier_flag"] = iso.fit_predict(df[features])
# 正常点=1,异常点=-1
# 图4:异常值检测结果可视化
plt.figure(figsize=(10, 6))
sns.scatterplot(
data=df,
x="area",
y="price",
hue="outlier_flag",
palette={1: "#00C853", -1: "#D500F9"},
style="outlier_flag",
s=100,
alpha=0.85
)
plt.title("图4:Isolation Forest 检测出的异常值")
plt.show()
# 5. 划分原始数据和清洗后数据
df_clean = df[df["outlier_flag"] == 1].copy()
X_raw = df[["area", "rooms", "age", "distance", "income_level"]]
y_raw = df["price"]
X_clean = df_clean[["area", "rooms", "age", "distance", "income_level"]]
y_clean = df_clean["price"]
# 6. 建模对比
def train_and_evaluate(X, y, title="dataset"):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = Pipeline([
("scaler", RobustScaler()),
("rf", RandomForestRegressor(
n_estimators=300,
max_depth=8,
random_state=42
))
])
model.fit(X_train, y_train)
pred = model.predict(X_test)
mae = mean_absolute_error(y_test, pred)
r2 = r2_score(y_test, pred)
print(f"{title} -> MAE: {mae:.2f}, R2: {r2:.4f}")
return model, X_test, y_test, pred
model_raw, X_test_raw, y_test_raw, pred_raw = train_and_evaluate(X_raw, y_raw, "原始数据")
model_clean, X_test_clean, y_test_clean, pred_clean = train_and_evaluate(X_clean, y_clean, "清洗后数据")
# 图5:真实值 vs 预测值(原始数据)
plt.figure(figsize=(10, 6))
plt.scatter(y_test_raw, pred_raw, c="#FF5722", alpha=0.7, s=70, edgecolors="k")
plt.plot([y_test_raw.min(), y_test_raw.max()], [y_test_raw.min(), y_test_raw.max()], 'b--', lw=2)
plt.title("图5:原始数据 - 真实房价 vs 预测房价")
plt.xlabel("真实房价")
plt.ylabel("预测房价")
plt.show()
# 图6:真实值 vs 预测值(清洗后数据)
plt.figure(figsize=(10, 6))
plt.scatter(y_test_clean, pred_clean, c="#00BCD4", alpha=0.7, s=70, edgecolors="k")
plt.plot([y_test_clean.min(), y_test_clean.max()], [y_test_clean.min(), y_test_clean.max()], 'r--', lw=2)
plt.title("图6:清洗后数据 - 真实房价 vs 预测房价")
plt.xlabel("真实房价")
plt.ylabel("预测房价")
plt.show()
# 图7:残差分布对比
res_raw = y_test_raw - pred_raw
res_clean = y_test_clean - pred_clean
plt.figure(figsize=(12, 6))
sns.kdeplot(res_raw, fill=True, color="#E91E63", label="原始数据残差", alpha=0.5)
sns.kdeplot(res_clean, fill=True, color="#2196F3", label="清洗后数据残差", alpha=0.5)
plt.title("图7:残差分布对比")
plt.legend()
plt.show()
# 图8:特征重要性
rf_model = model_clean.named_steps["rf"]
importances = rf_model.feature_importances_
feature_names = X_clean.columns
imp_df = pd.DataFrame({
"feature": feature_names,
"importance": importances
}).sort_values("importance", ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(data=imp_df, x="importance", y="feature", palette="viridis")
plt.title("图8:清洗后模型的特征重要性")
plt.show()
面积与房价关系散点图(含异常值):
这张图横轴是面积,纵轴是价格,颜色表示房间数,点大小表示周边收入水平。
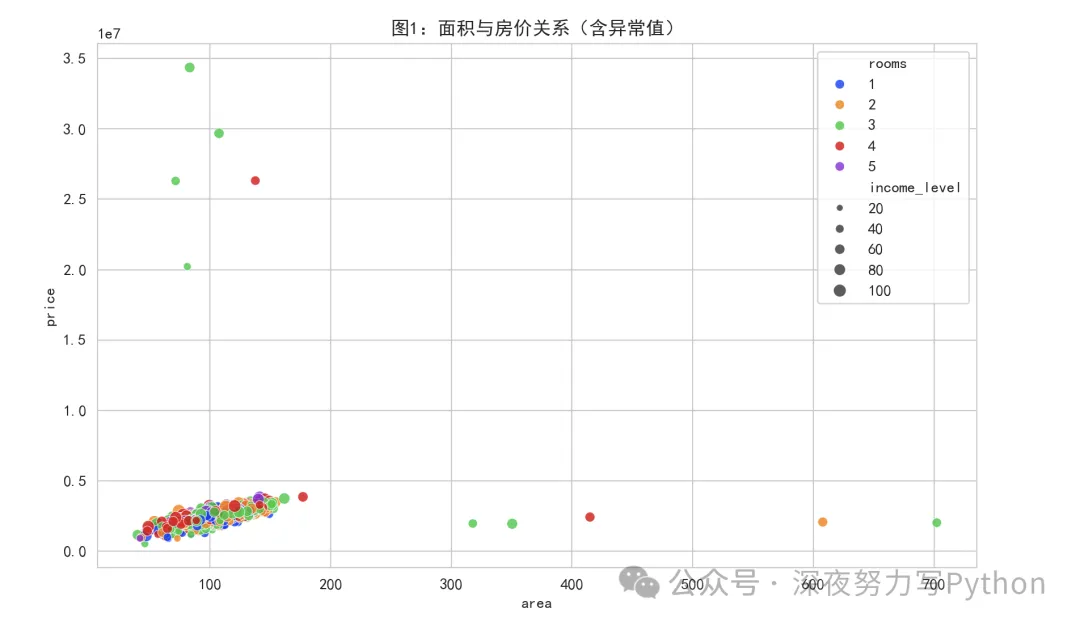
大多数样本集中在一个相对连续的区域,面积增大时,房价整体上升。
可以看到,目标值和核心特征之间的关系是否被极端点破坏。
四个箱线图:
箱线图是看异常值非常经典的工具。
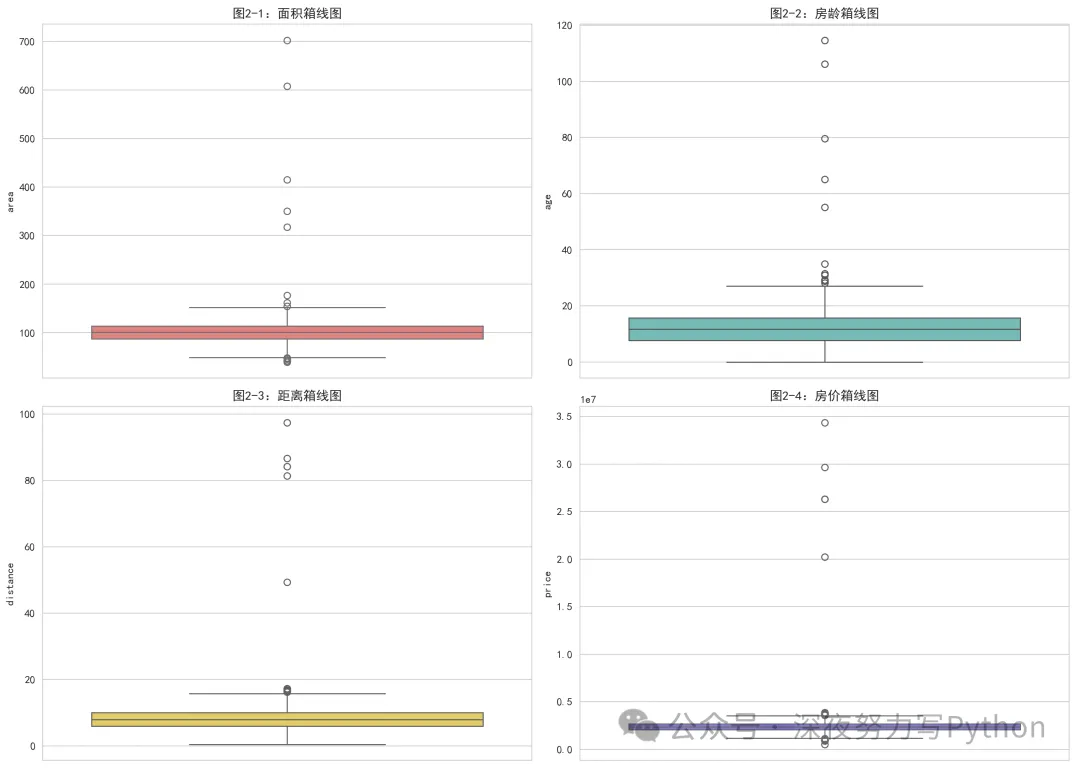
它的核心结构:
箱体中间是中位数
箱体上下边界是 和
须通常延伸到 范围
超出须的点,就是潜在异常值
从单变量角度快速排查谁最离谱。
相关性热力图:
热力图可以帮助我们看各个变量之间的线性关系。
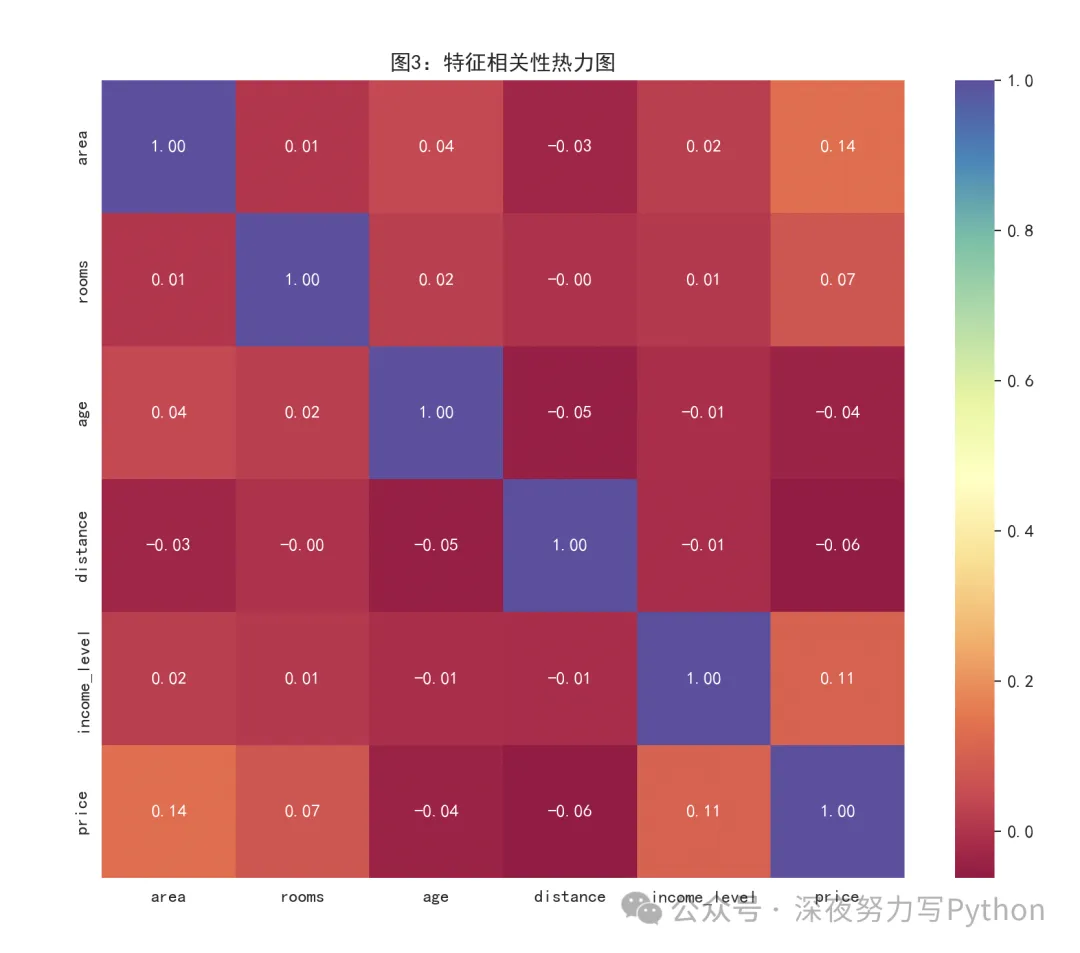
正常情况下你会预期:
area和price正相关distance和price负相关age和price负相关
但如果异常值太多,它会把这些相关性扭曲。
比如本来应该明显正相关,结果相关系数变弱。
Isolation Forest 检测结果图:
这张图会把正常点和异常点用不同颜色标出来。
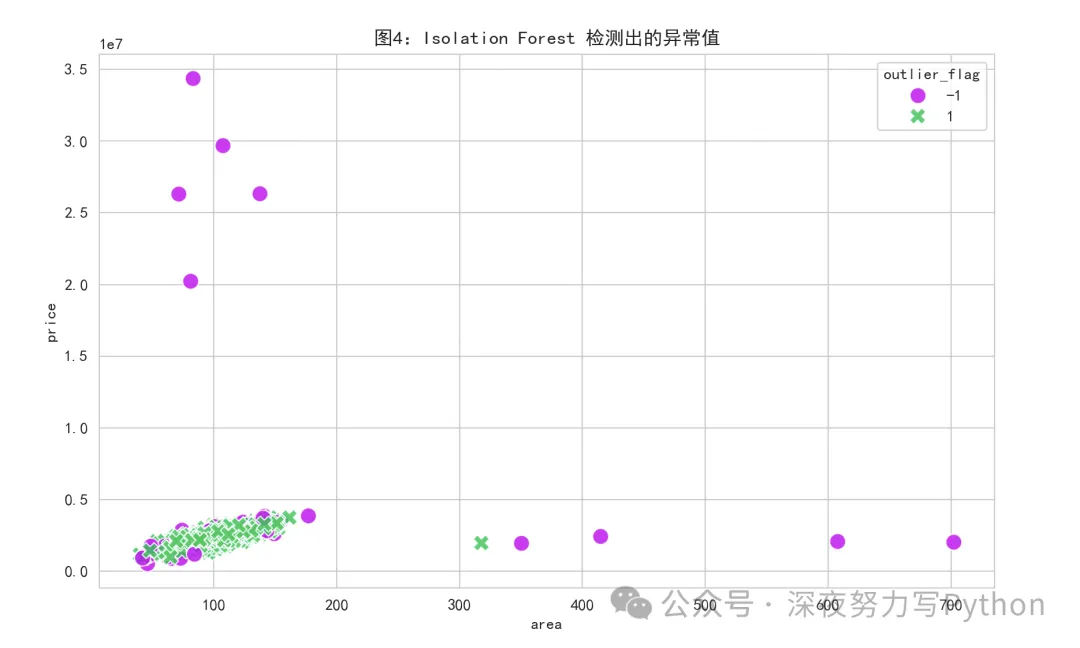
一般你会看到:
正常点集中成团
异常点在边缘、孤立位置或者奇怪区域
这张图特别适合做展示。
因为它能直观看到模型到底“抓”了哪些点。
真实值 vs 预测值:
这两张图是模型效果对比图。
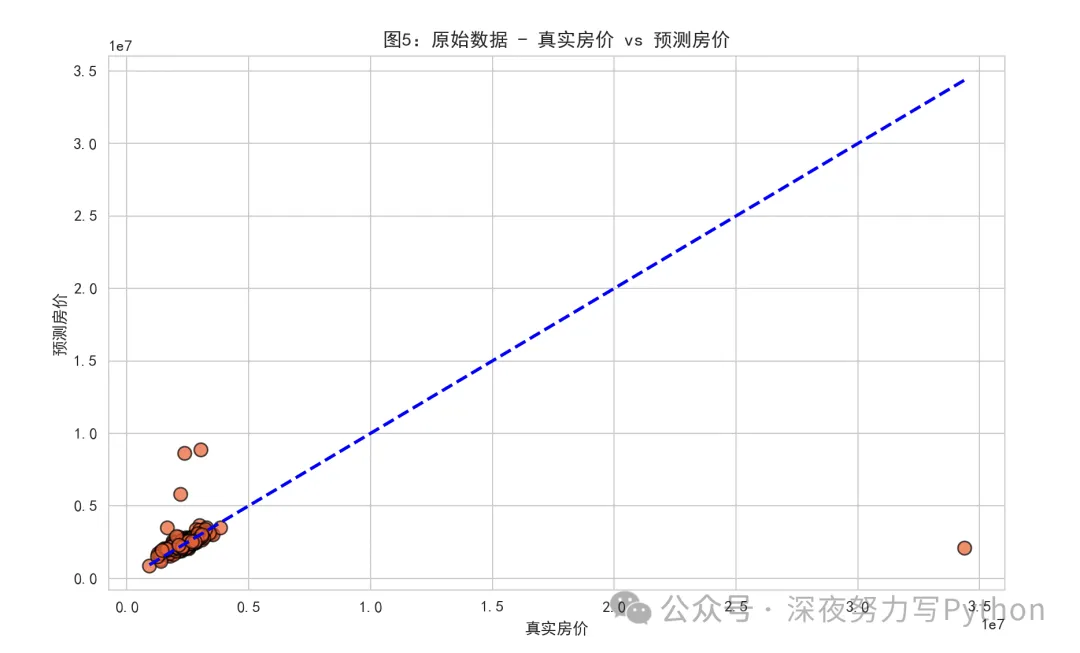
如果预测很好,点应该靠近对角线:
也就是“真实值 = 预测值”。
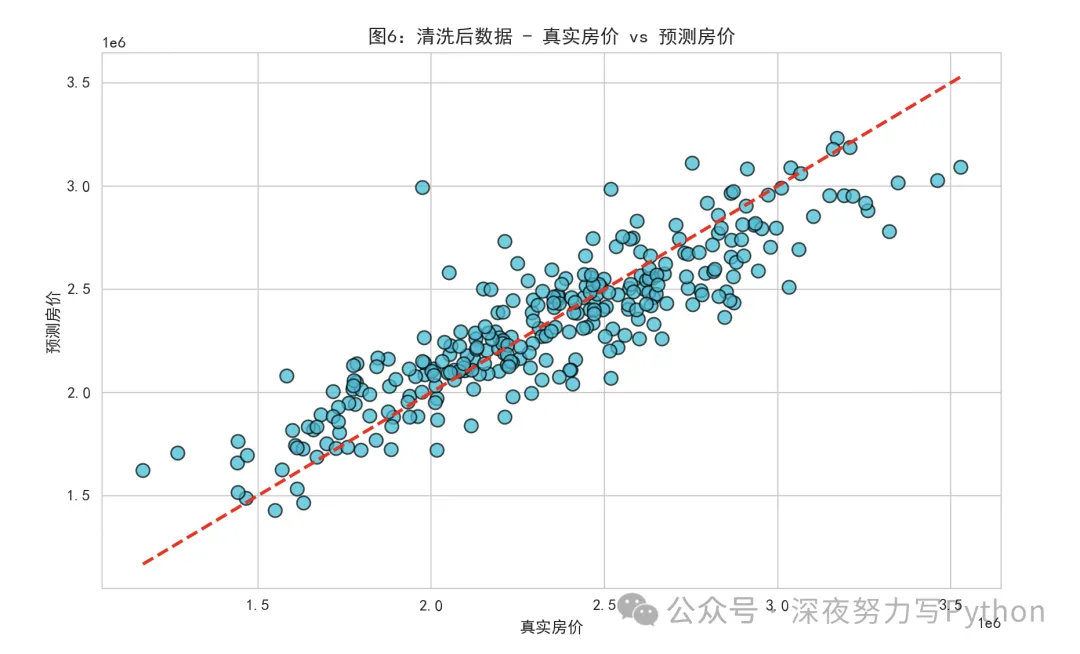
直接看异常值处理有没有提升模型预测质量。
残差分布对比:
残差定义是:
其中:
是真实值
是预测值
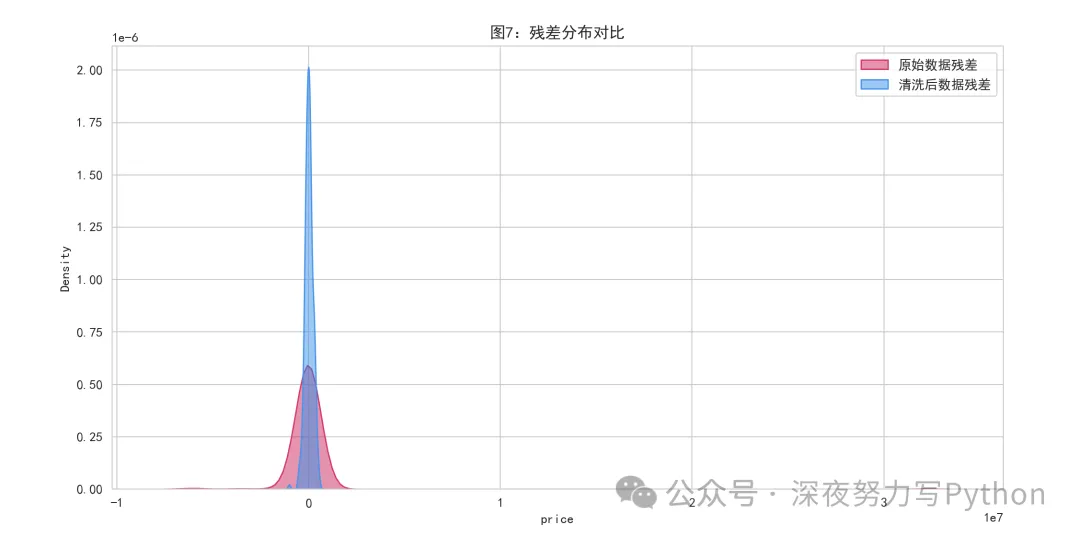
理想情况下,残差应该:
尽量集中在 0 附近
分布更窄
两边尾巴不要太长
如果异常值没处理好,残差往往会:
更分散
尾部更长
偏移更明显
所以,可以看到模型误差是不是被异常值拖大了。
特征重要性图:
这张图展示清洗后随机森林认为哪些特征更重要。
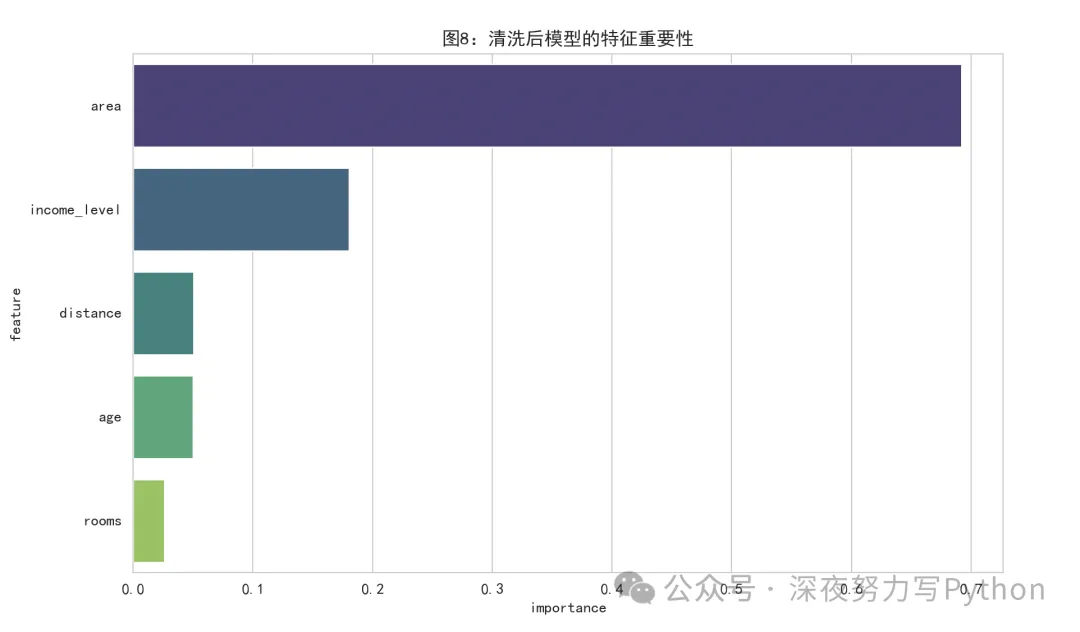
一般你会发现:
面积通常很重要
收入水平也很重要
距离和房龄也会有贡献
如果不处理异常值,有时候特征重要性会被极端样本扭曲。
总结
总的来说,我们在机器学习项目中,异常值处理一般分三步。
第一步,先结合业务规则和可视化判断异常值。
比如通过箱线图、散点图、分位数统计看极端样本,同时确认这些值是不是业务上不合理。
第二步,根据异常值性质选择处理方式。
如果是明显录入错误,会直接删除或修正;如果是真实但极端的样本,根据任务目标决定是保留、截断、做对数变换,还是使用更稳健的模型。
第三步,做处理前后的效果对比。
比如比较模型的 MAE、R2、残差分布,以及特征重要性变化,确认异常值处理是否真的提升了模型稳定性和泛化能力。
如果数据是多维的,通常还会用 Isolation Forest 这类方法辅助检测异常值。
所以说,真正要解决的是:让模型看到更稳定、更有代表性的数据结构。





