 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库【AI加油站】第一百四十六部:吴恩达深度学习课精华笔记:从入门到实战的必会知识点(超全整理)(附下载)

这份笔记提炼了吴恩达老师深度学习课程的核心内容,涵盖从基础概念、模型训练技巧到卷积网络、自然语言处理与序列模型的方方面面。无论你是刚入门还是想查漏补缺,都能从中获得系统、实用的知识框架。
一、深度学习的基本趋势与思维
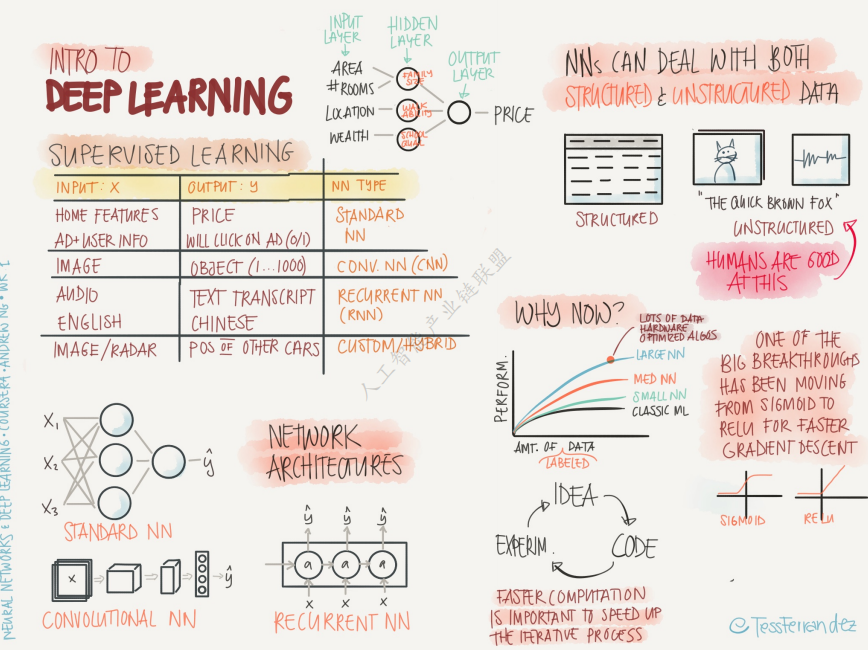
在人工智能时代,理解技术发展层次至关重要。借鉴马斯洛需求层次理论,我们可以从七个层次快速洞察前沿趋势与个人成长方向。深度学习与传统机器学习最大的区别之一在于数据量:经典ML在100–10000样本下表现良好,而深度学习通常在百万级样本上才能发挥真正优势。
二、构建机器学习项目的基础
1. 数据划分与分布
• 训练集 / 开发集 / 测试集:常见的划分比例是60% / 20% / 20%。 • 关键原则:所有数据应来自同一分布。开发集和测试集必须来自同一分布,否则你优化的目标会偏离真实应用场景。 • 实战建议:若训练集来自网络(清晰猫图),而开发/测试集来自App(模糊猫图),两者分布不同,会严重干扰模型调优。应尽量让开发/测试集反映你最终要处理的数据。
2. 偏差与方差诊断
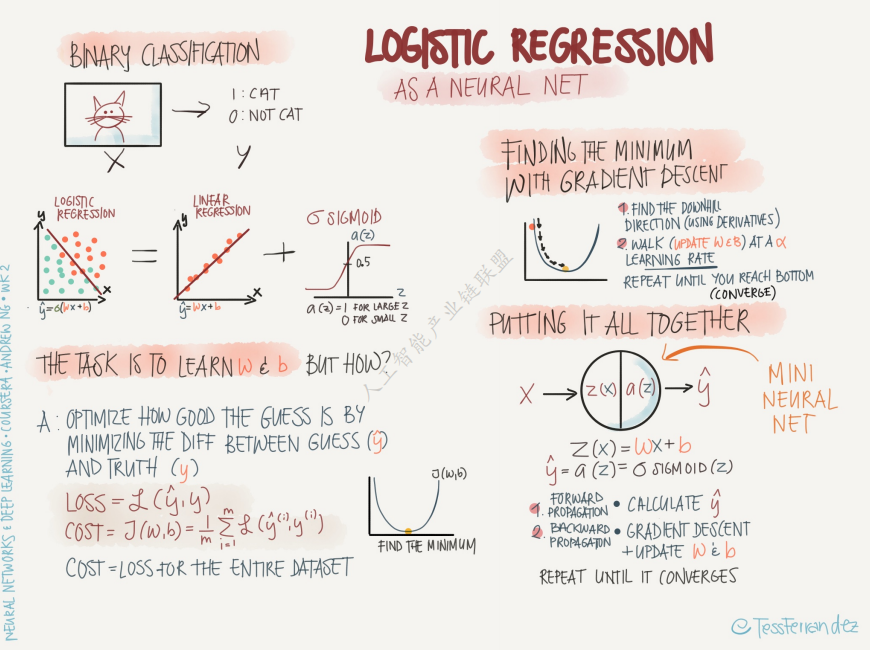
通过对比训练误差、开发测试误差与人类水平(或最优误差)可以判断模型问题:
处理“配方”:
• 高偏差 → 更大的网络、更长的训练、更换网络架构。 • 高方差 → 更多训练数据、正则化(L2 / Dropout)、更换架构。
三、正则化——防止过拟合
1. L2 正则化(权重衰减)
在代价函数中加入 (\frac{\lambda}{2m} |w|^2),惩罚过大的权重,使得网络趋向简单。
2. L1 正则化
加入 (\frac{\lambda}{m} |w|),会让部分权重变为0,产生稀疏解。
3. Dropout
每次迭代随机“丢弃”一部分神经元(依 keep_prob 概率保留)。这迫使网络不能依赖少数特征,从而更鲁棒。注意:测试时不再使用 dropout。
4. 数据增强
通过对已有数据进行旋转、翻转、裁剪、色彩变换等,生成更多训练样本,低成本降低过拟合。
5. Early Stopping
当开发集误差不再下降时提前停止训练。缺点:同时影响了偏差和方差,不如单独用正则化方法灵活。
四、优化训练过程
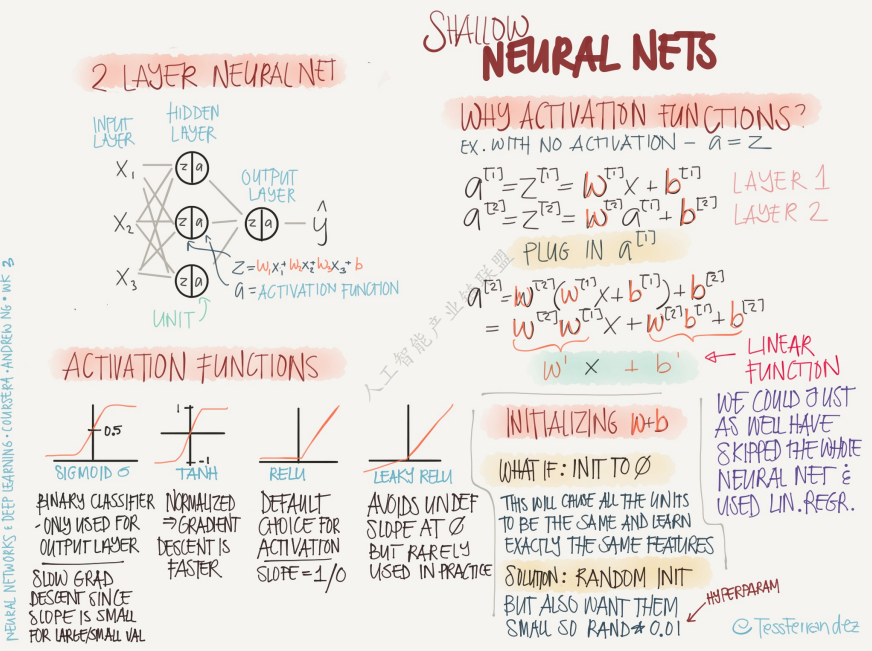
1. 梯度消失与爆炸
深层网络中,若初始权重不合适,梯度会指数级衰减或爆炸,导致训练极慢。
解决方案:合理初始化权重,如使用 Xavier 初始化:
[
w = \text{np.random.randn}(n) \cdot \sqrt{\frac{2}{n_{\text{prev}}}}
]
2. 梯度检查
如果代价函数没有随迭代下降,可能是反向传播有bug。梯度检查用数值近似验证梯度计算是否正确。注意:仅在调试时使用,非常慢。
3. Mini-batch 梯度下降
将大数据集分成小批量,每个批量计算一次梯度并更新参数,从而在未遍历完所有样本时就能看到进展。
批次大小选择:
• 样本数 < 2000 → 使用 batch 梯度下降(全量) • 否则常用 64、128、256、512 —— 保证能放入 CPU/GPU 缓存。
4. 动量梯度下降(Momentum)
对梯度做指数加权平均,平滑更新方向,减少震荡,加速收敛。
5. RMSprop
对梯度平方做移动平均,再用它归一化当前梯度,使得不同参数的更新步长更自适应。
6. Adam 优化器
结合动量与 RMSprop 的优点,成为默认首选优化器。超参数通常取 (\beta_1=0.9,\ \beta_2=0.999,\ \epsilon=10^{-8})。
7. 学习率衰减
训练初期用较大学习率快速收敛,后期逐渐减小以精细调整。
常用衰减方式:
• 指数衰减:(\alpha = 0.95^{\text{epoch}}) • 分段常数衰减(staircase) • 手动调整
五、超参数调优
最重要的超参数排序:
1. 学习率 (\alpha) 2. 隐藏单元数量、mini-batch 大小、动量 (\beta)(默认0.9) 3. 层数、学习率衰减参数 4. Adam 中的 (\beta_1, \beta_2, \epsilon)
调参技巧:从粗到细随机采样,而非网格搜索,因为不同超参数的重要性差异很大。
批归一化(Batch Norm)
对每一层的输出(或激活前)进行归一化,能加速训练、使深层网络对权重初始化更鲁棒、产生轻微正则化效果。
六、经典的卷积神经网络(CNN)
通用趋势
• 特征图尺寸(高/宽)逐渐减小,通道数逐渐增多。 • 常见模式:几层卷积 + 池化,最后接全连接层。
1. LeNet-5
用于手写数字识别,曾使用平均池化和 sigmoid / tanh 激活(如今多用 ReLU 和最大池化)。
2. 非常深的网络(如 VGG)
过滤器数量逐层翻倍:64 → 128 → 256 → 512,结构规整易实现。
3. 1×1 卷积(Network in Network)
两个作用:
• 跨通道的信息融合,实现降维或升维。 • 减少计算量,尤其是在 Inception 模块中,先用 1×1 卷积压缩通道数,再应用大尺寸卷积。
4. ResNet(残差网络)
通过“跳跃连接”(shortcut)将输入直接加到输出上,有效缓解梯度消失,使得训练上百层的网络成为可能。核心思想:让网络学习残差 (F(x) = H(x) - x) 比直接学习 (H(x)) 更容易。
5. Inception 网络
一个模块内同时使用 1×1、3×3、5×5 卷积和池化,然后拼接所有输出。为避免计算爆炸,先用 1×1 卷积降维。多个 Inception 模块堆叠即构成 GoogLeNet。
七、目标检测基础
1. 目标定位与 YOLO 思路
• 将图像划分为 (S \times S) 网格,每个网格负责检测中心点落在该格内的物体。 • 每个网格输出一个向量:([p_c, b_x, b_y, b_h, b_w, c_1, c_2, ...]),其中 (p_c) 表示是否有物体,后面是边界框坐标和类别。
2. 交并比(IoU)
评价预测框与真实框的重合程度:(\text{IoU} \ge 0.5) 一般视为检测正确。
3. 非极大值抑制(NMS)
当多个框检测到同一物体时,只保留最大概率的框,并移除与其 IoU 过高的其他框。
4. Anchor Boxes
允许多个物体出现在同一网格(例如人和汽车重叠)。预先定义不同形状的 anchor box,每个网格预测多个 anchor 对应的框。
八、自然语言处理与词嵌入
1. 为什么需要词嵌入?
独热编码无法表达词之间的相似性。“苹果”和“橙子”在独热空间中距离遥远,但在嵌入空间中,语义相近的词距离更近。
2. 词嵌入的类比推理
经典的例子:man → woman,king → ?
通过计算 (\arg\max_w \text{sim}(e_w, e_{\text{king}} - e_{\text{man}} + e_{\text{woman}})),可以得出 queen。相似度常用余弦相似度。
3. 学习词嵌入的方法
• Word2Vec(Skip-gram):用中心词预测周围词。为避免计算量过大,使用负采样或层次 softmax。 • GloVe:基于词共现矩阵,最小化加权平方误差。公式简洁有效。
4. 消除词嵌入中的偏见
训练语料可能隐含性别、种族等偏见。处理步骤:
1. 识别偏见方向(如性别方向)。 2. 对非定义性词(如“医生”、“程序员”)进行中和,投影到非偏见空间。 3. 均衡化配对词(如“男孩/女孩”),使它们只有性别维度的差异。
5. 情感分类
利用预训练的词嵌入(即使只有少量标注数据),可以构建有效的分类器。简单方法是对所有词向量求平均,但忽略了词序——例如“完全缺乏好品味”可能被误判为正面。改进:使用 RNN 或 LSTM 捕捉否定词和程度词的影响。
九、序列模型与机器翻译
1. 束搜索(Beam Search)
在生成序列时,每一步保留概率最高的 B 个候选(beam width)。
• B 越大结果越好但速度越慢;通常 B=3~10。 • 若束搜索选出的句子概率比另一候选低,但人工认为它更好,说明 RNN 自身概率估计不准,应改进 RNN。
2. BLEU 评分(评估机器翻译)
考虑 n-gram 的精确率,并加入短句惩罚(brevity penalty)。最终 BLEU 得分是一个综合指标,与人类评价高度相关。
3. 注意力机制(Attention)
在处理长句子时,编码器无法将全部信息压缩到固定向量。注意力模型让解码器每一步动态关注源句子中相关的部分,极大提升了长句翻译质量。
4. 语音识别:CTC 损失
语音输入输出之间往往长度不对齐。CTC 允许输出重复字符,并通过“空白”分隔,最后折叠重复字符(空白分隔的除外)。例如 “ttt_h_eee___uuu” 会变成 “the u”。
5. 触发词检测(如“Hey Siri”)
将音频片段输入 RNN,当检测到触发词时,输出 1 否则 0。为了平滑,可以在触发词后连续输出多个 1。
十、项目迭代的实用指南
1. 快速构建第一个系统并迭代,不要试图一开始就设计完美模型。 2. 错误分析:从开发集错误中手工统计各类错误占比(如“狗被误认为猫”、“标注错误”等),按优先级解决问题。修正开发集的同时也要修正测试集。 3. 迁移学习:如果目标领域数据很少,可复用已在大型数据集(如 ImageNet)上预训练的模型,只微调最后几层;若数据充足,可以微调全部层。 4. 开源不丢人:许多论文的实现细节复杂,利用开源实现能大幅提高效率——记得遵守协议并贡献你的改进。
最后的话
深度学习不是玄学,而是一门工程与科学紧密结合的学科。掌握偏差/方差诊断、正则化、优化算法、卷积网络、序列模型和项目流程,你就能独立设计、调优、部署自己的深度学习系统。希望这份笔记能成为你学习路上的“速查地图”。
欢迎收藏、分享,让更多朋友一起进阶 AI 之路!

本书免费下载地址
关注微信公众号“人工智能产业链union”回复关键字“AI加油站146”获取下载地址。
【AI加油站】第八部:《模式识别(第四版)-模式识别与机器学习》(附下载)





