 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库中国科学院发布类脑大模型瞬悉2.0,打破长序列与低功耗部署核心瓶颈
将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


当前,大模型发展正从「参数和数据规模驱动」逐步延展至「上下文能力驱动」。在智能体、代码理解、长文档分析等应用中,模型需要处理数十万甚至百万级 token。但传统 Transformer 在长序列处理及资源受限场景下的部署仍面临诸多痛点。因此,如何以极低成本构建基础模型,打破 Transformer 在不同序列长度、不同硬件平台下的能耗瓶颈,成为大模型领域的关键探索方向。
近日,中国科学院自动化研究所李国齐、徐波团队在类脑脉冲大模型「瞬悉 1.0」研究基础上,针对当前大模型长序列处理与低功耗部署等核心瓶颈,推出 SpikingBrain2.0-5B(简称 SpB2.0-5B)模型系列,通过引入更丰富的类脑机制 —— 包括稀疏化记忆建模、更精细化的脉冲激活值编码等,在瞬悉 1.0 的基础上实现了全方位升级。

论文地址:https://arxiv.org/abs/2604.22575
开源地址:https://github.com/BICLab/SpikingBrain2.0
此次发布的瞬悉 2.0 以超过瞬悉 1.0 十倍的训练开销节省,续训数据量从瞬悉 1.0 的 150B 降低至瞬悉 1.0 的 14B:即仅需 32 张 A100 显卡,9 天内即可完成对当前主流 Transformer 架构大模型(如 Qwen3 系列模型)的持续预训练,通用知识(如 MMLU、ARC-C、BBH 等任务)以及 SFT 后推理能力(如数学推理 GSM8K、MATH,代码 HumanEval、MBPP 等任务)的表现可与强基线 Qwen3 比肩且实现比瞬悉 1.0 更优综合性能;并在 4M 序列长度下达到主流 Transformer 模型 Qwen3 的 10.13 倍首 Token 生成加速,FP8 量化路径下 4M 长度下相比 Qwen3 BF16 基线提速达 15.13 倍,整数 - 脉冲化编码路径下,精度损失仅为 0.69%,且脉冲稀疏度高达 64.3%,模拟结果显示,该方案在测试场景下相比 INT8 矩阵乘法基线,有望使得面向类脑大模型的神经形态芯片面积减小 70.6%,在 250/500MHz 工作频率下功耗降低 48.1%/46.5%。
瞬悉 2.0 在长序列处理效率、训练开销、综合 Benchmark 性能、跨硬件平台适配性及应用场景拓展等方面显著提升,为轻量级、多模态高效脉冲基础模型的研发提供了可行路径,为新一代人工智能创新发展注入新动力。
瞬悉 2.0 与 Qwen-3 速度对比演示
架构设计
短序列场景中,Transformer 的计算瓶颈源于大量前馈矩阵乘法;长序列场景中,计算瓶颈则向注意力模块转移,导致推理效率大幅下降。瞬悉 2.0 因此对注意力和前馈矩阵乘操作分别做出针对性设计,期望缓解 Transformer 的能耗问题。
(1)双空间混合稀疏注意力:
瞬悉 2.0 提出双空间稀疏注意力(Dual-Space Sparse Attention, DSSA),用于在层间混合稀疏 Softmax 注意力 MoBA 与稀疏线性注意力 Sparse State Expansion (SSE)。其中,MoBA 对完整的 KV cache 进行块级稀疏计算,SSE 则对压缩式状态表征进行稀疏计算。这一设计对应类脑化的稀疏记忆机制,实现了优良的长序列性能 - 效率权衡 (图 2)。
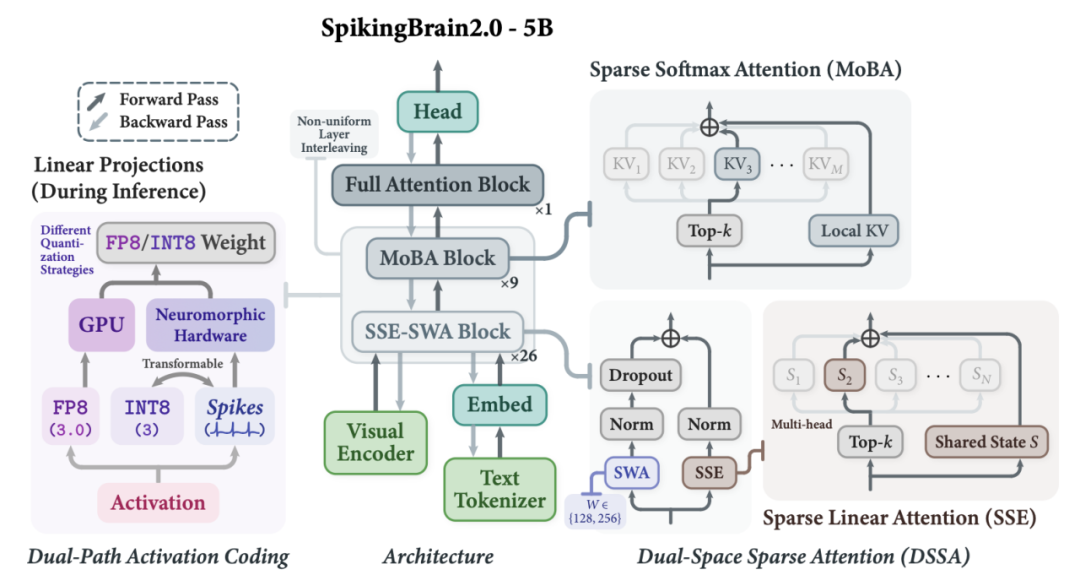
瞬悉 2.0 架构概览
(2)双路径激活值编码策略:
瞬悉 2.0 采用了包括 FP8 和 INT8-Spiking 两种对偶激活值编码路径(图 3):
1.FP8 编码路径:利用低比特 Tensor Core 加速矩阵乘运算,该路径面向工业 GPU 部署(如 NVIDIA Hopper GPU);
2.INT8-Spiking 编码路径:把激活值转为脉冲序列,可将密集矩阵乘法替换为事件驱动的整数累加,大幅降低部署功耗,该路径面向异步神经形态芯片部署。
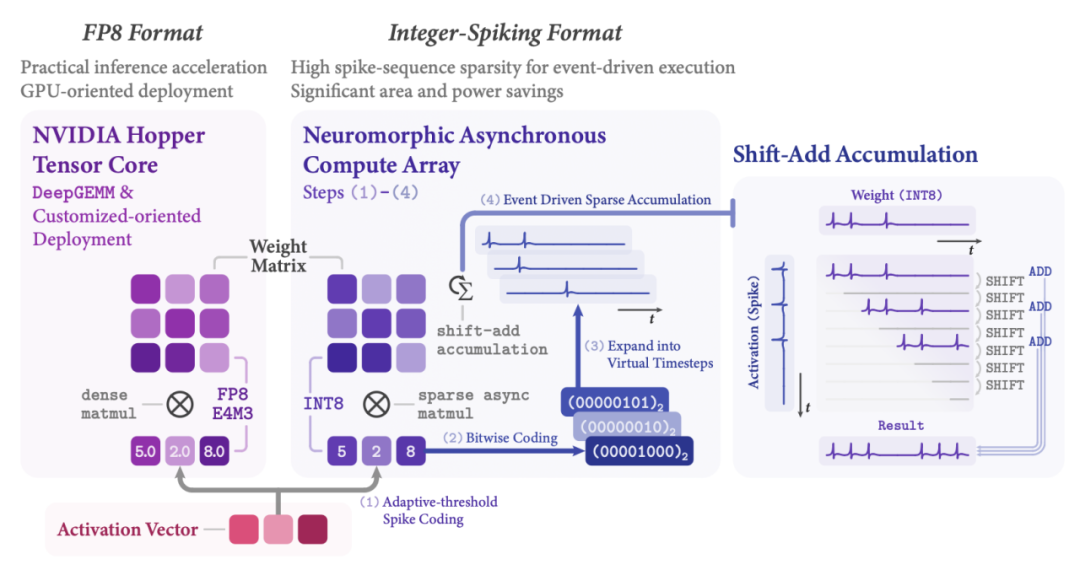
瞬悉 2.0 对偶编码路径
转换训练流程
瞬悉 2.0 采用比瞬悉 1.0 更高效、模态更广的架构转换流程(Transformer-to-Hybrid Conversion),依托极少量开源数据和计算资源,分别为语言模型与多模态模型构建两条独立的续训转换路径,大幅降低开发成本(图 4)。
(1)LLM 转换路径:包括短上下文蒸馏、三阶段长上下文扩展(最高至 512k)以及两阶段的通用加推理 SFT,同时开展了在策略蒸馏探索。(2)VLM 转换路径:包括知识蒸馏与指令微调。本文还同时分享了实践过程中的关键 Takeaways,为社区研究提供参考。
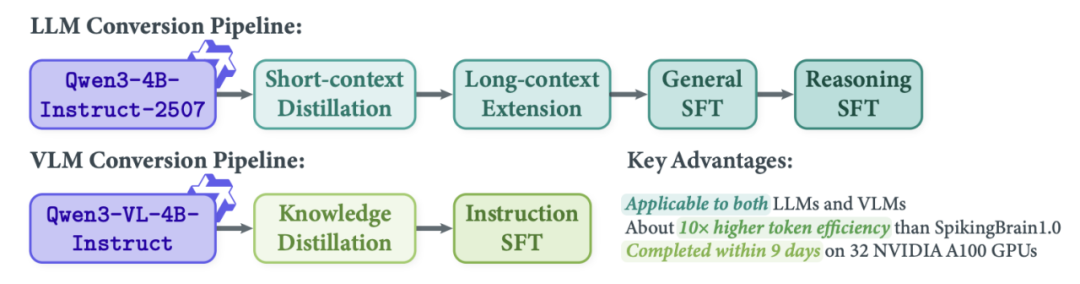
瞬悉 2.0 转换训练 Pipeline
模型性能
1. 长序列处理效率显著提升。(1)在 Huggingface 序列并行框架下,瞬悉 2.0 在 4M 长度相比 Qwen3 实现 10.13 倍的首 token 生成时延(TTFT)加速;(2)在 vLLM 张量并行框架下,512k 长度端到端生成延迟降低 4.3 倍,128k 长度下总吞吐提升 1.57 倍、请求并发数提升 3.17 倍;(3)依托 vLLM 框架,8 卡 A100 即可支持长达 10M 序列的推理,而 Qwen3 基线在 4M 长度时已超出显存限制,展现出突出的长序列处理优势。
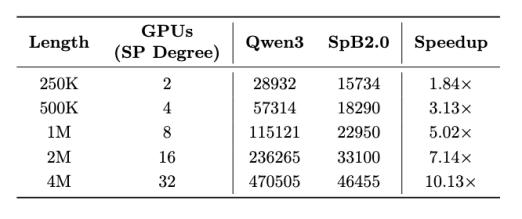
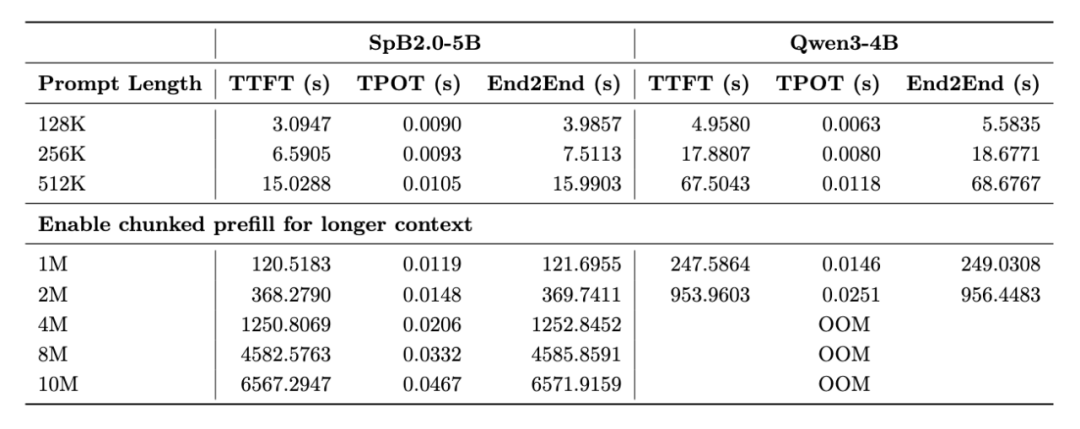
2. 训练成本大幅降低。瞬悉 2.0-5B 语言与多模态模型的总转换开销低至 7k A100 卡时以下,仅需 32 张 A100,9 天内即可完成对 Qwen3-4B 和 Qwen3-VL-4B 的全部转换训练,相较于 SpB1.0,训练成本减少 10 倍以上(LLM CPT 数据量从 150B 降至 14B),实现了高效低成本的模型开发。
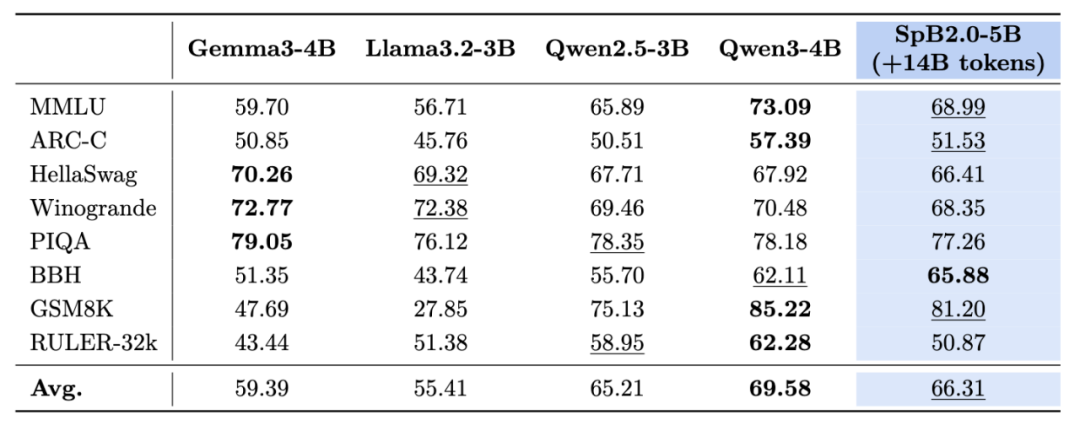
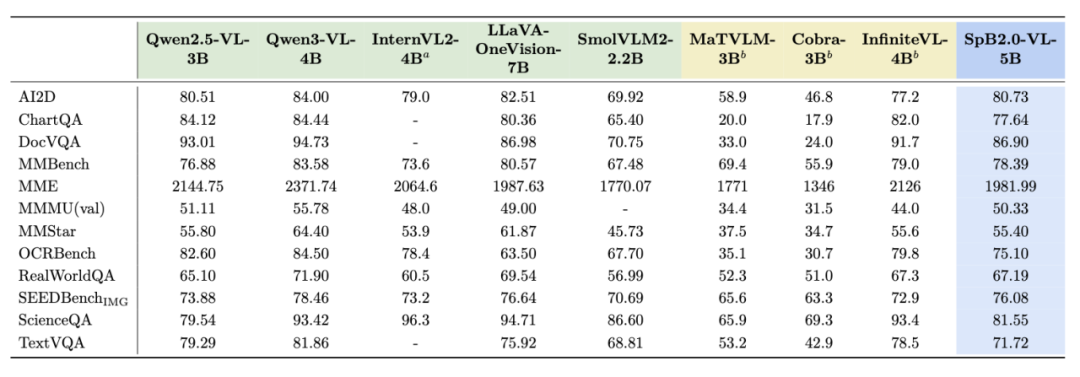
3. 模型性能保持竞争力。(1)瞬悉 2.0 语言模型在通用知识(如 MMLU、ARC-C、BBH 等任务)以及 SFT 后推理能力(如数学推理 GSM8K、MATH,代码 HumanEval、MBPP 等任务)的表现与强基线 Qwen3 比肩,综合性能优于 Qwen2.5 和更大规模的瞬悉 1.0-7B 模型。(2)瞬悉 2.0-VL 模型性能实现对 Qwen3-VL 的有效恢复,可与强基线 Qwen2.5-VL 比肩(如图表推理 AI2D、通用视觉推理 MMStar 等任务),在瞬悉 1.0 的基础上实现了多模态能力的突破。
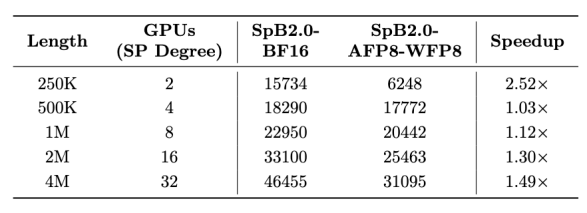
4. 跨硬件平台适配性突出。瞬悉 2.0 可灵活适配不同硬件平台:(1)采用 FP8 路径时,精度损失仅为 0.24%;在 H100 上实测显示,256k 序列长度下 TTFT 提速相比瞬悉 2.0 BF16 版本超 2.5 倍,同时在 4M 长度下相比 Qwen3 BF16 基线提速达 15.13 倍;(2)采用 INT8-Spiking 路径时,精度损失仅为 0.69%,且脉冲稀疏度高达 64.3%;后仿模拟结果显示,该方案在测试场景下相比 INT8 矩阵乘法基线,面积减小 70.6%,在 250/500MHz 工作频率下,功耗降低 48.1%/46.5%,有望破解端侧部署的功耗瓶颈。

瞬悉 2.0 系列模型的发布,为轻量级、多模态高效脉冲基础模型的研发提供了可行路径,进一步验证了类脑机制与高效模型架构结合的广阔前景。同时,该模型为端侧、资源受限场景的大模型部署提供了高性价比解决方案,也为低功耗神经形态计算的后续研发提供重要参考。研究团队将继续秉承类脑大模型技术「概念一致、迭代升级」的理念,持续研发可比肩主流大模型的低功耗神经形态计算。
作者介绍
李国齐,论文通讯作者,中国科学院自动化所研究员,脑认知与类脑智能全国重点实验室副主任,通用类脑智能大模型北京市重点实验室主任,国家杰出青年基金获得者;在 Nature、Nature 子刊、Science 子刊等期刊和 AI 顶会上发表论文 200 余篇。
徐波,论文通讯作者,中国科学院自动化所研究员,中国科学院自动化所所长,科技创新 2030「新一代人工智能」重大项目专家组组长,中国科学院大学人工智能学院院长。
潘昱锜,论文一作,中国科学院自动化研究所博士生,2024 年本科毕业于南京大学匡亚明学院。研究方向为通用类脑大模型与长序列基础模型架构,瞬悉 SpikingBrain 类脑大模型 1.0/2.0 核心团队成员,以第一作者在 ICLR 2026、TMLR 2026 等 AI 顶刊顶会上发表多篇论文。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。





