 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库中文超长上下文多轮检索测评基准方案发布!SuperCLUE-LongContext

# 测评背景
随着大语言模型上下文窗口从 4K 快速扩展至 128K、256K,乃至 1M tokens,长上下文理解能力已成为衡量模型核心竞争力的关键指标。然而,拥有长窗口不等于理解长文本——模型可能在上下文中读到了信息,却无法在需要时精准回忆和提取。
当前主流长上下文评测基准普遍存在两重局限:其一,传统 "Needle-in-a-Haystack" (大海捞针)测试仅考察模型在超长文本中定位单一信息片段的能力,任务过于简单,现有主流模型已普遍取得接近 100% 的准确率,区分度严重不足;其二,缺乏针对中文语境、中文写作范式与中文 tokenizer 特性的本土化长上下文评测体系,现有基准多以英文语料为主,无法准确反映中文大模型在真实中文长文档、长对话场景中的检索与回忆能力。
为了客观、全面、严谨地衡量中文大模型在长上下文场景中的真实检索与精确回忆能力,我们推出 SuperCLUE-LongContext 超长上下文多轮检索评测基准。该基准基于 OpenAI 原版 MRCR 的设计理念,深度融合中文语言文化特征与本土写作范式,构建了覆盖 4K-1M tokens 全范围的八档长度分桶体系,通过在同一主题、同一写作格式下嵌入多条"高度混淆"的needle(针)信息,测试模型在多轮对话历史中的精确序号识别与内容回忆能力,以此建立中文超长上下文大模型的权威能力标尺。
# 实验结果
我们基于SuperCLUE-LongContext超长上下文多轮检索评测基准对DeepSeek-V4-Flash(max)进行了初步测评,以下是该模型的测评成绩:
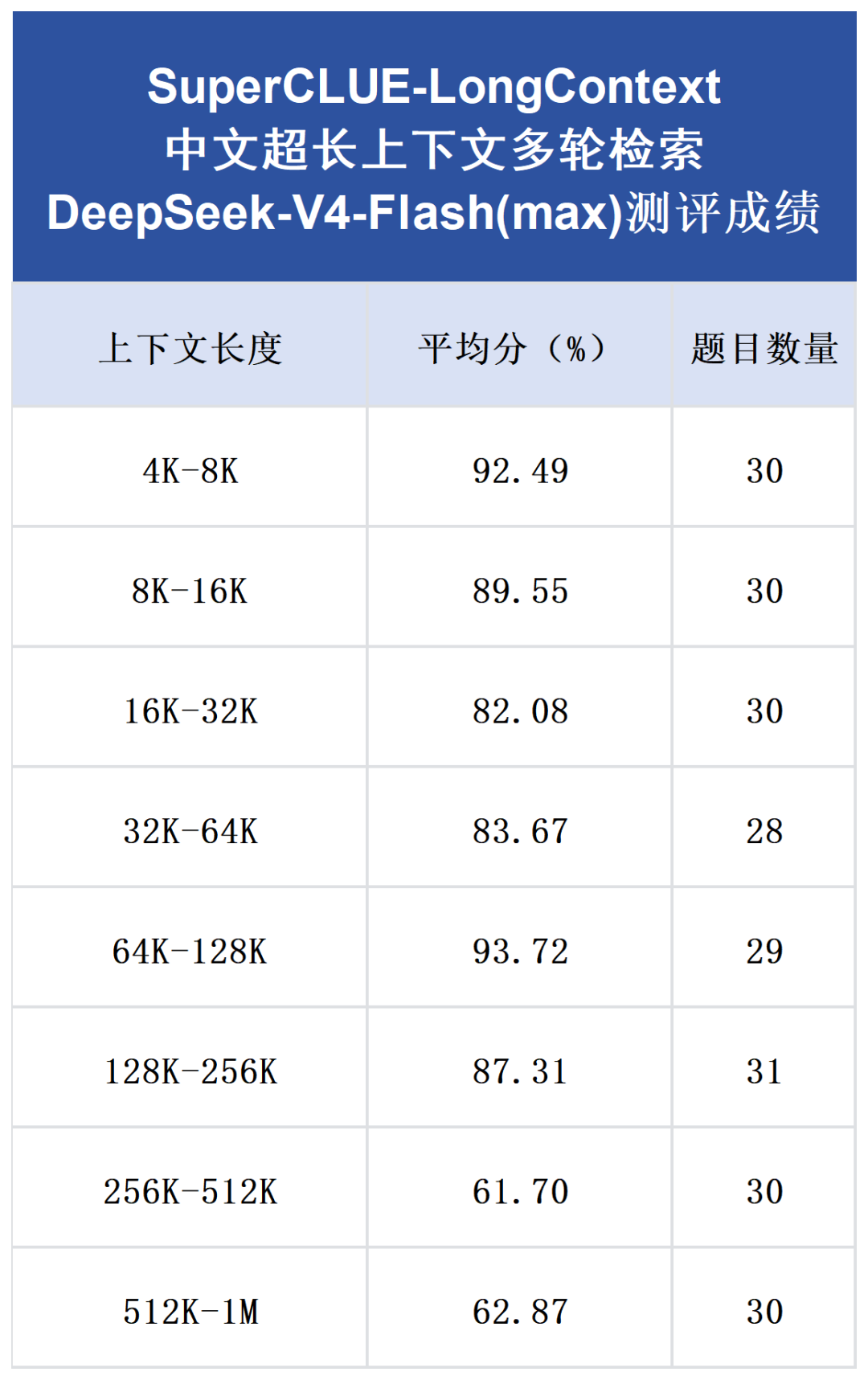
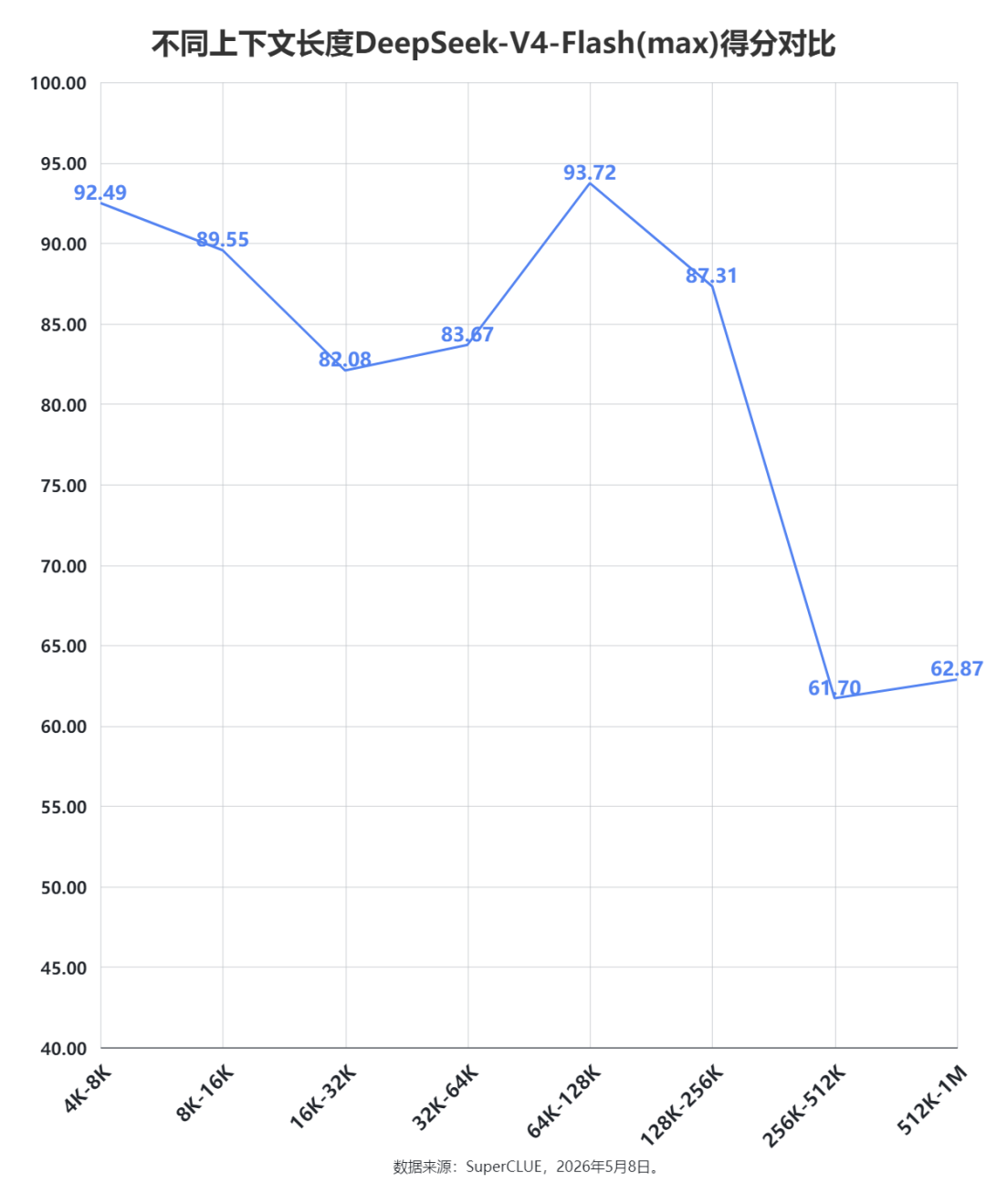
本次测评共有238个任务(实验阶段,不代表正式测评的任务数量),大致均分在不同上下文长度的区间中,每个区间30个任务左右,DeepSeek-V4-Flash(max)在上下文长度为4K至256K的区间内整体表现稳健,每个区间得分均在80分以上,平均分达到了88.14分。但在256K处是核心分水岭,从此处开始该模型出现断崖式的性能下跌,在256K-512K和512K-1M的区间中分别只取得了61.70分和62.87分,平均分62.29,下降了近26分。
# 基准特点
SuperCLUE-LongContext 旨在构建覆盖中文语境全场景、符合中文写作实际、面向未来长上下文模型演进方向的能力评估体系。该方案具备以下亮点:
1. 八档标准长度分桶,覆盖 4K-1M tokens 全范围
为确保评测在不同上下文长度下的区分能力,SuperCLUE-LongContext 构建了与 OpenAI MRCR 一致的八档标准分桶体系:4K-8K、8K-16K、16K-32K、32K-64K、64K-128K、128K-256K、256K-512K、512K-1M。每个分桶独立采样、独立统计,确保模型在长上下文能力衰减曲线上的每一个关键节点都被精确度量。
2. 多 needle 混淆机制,从单点检索升级为序号识别
传统 Needle-in-a-Haystack 仅要求模型"找到一根针",而 SuperCLUE-LongContext 要求模型在同一主题、同一写作格式的多个相似 needle 中,准确识别并回忆指定序号的完整内容。测试配置涵盖 2-needle、4-needle、8-needle 三种难度档位,needle 数量越多、上下文越长,模型的序号混淆风险越高,评测难度呈指数级上升。
3. 中文主题实体库与本土写作格式深度适配
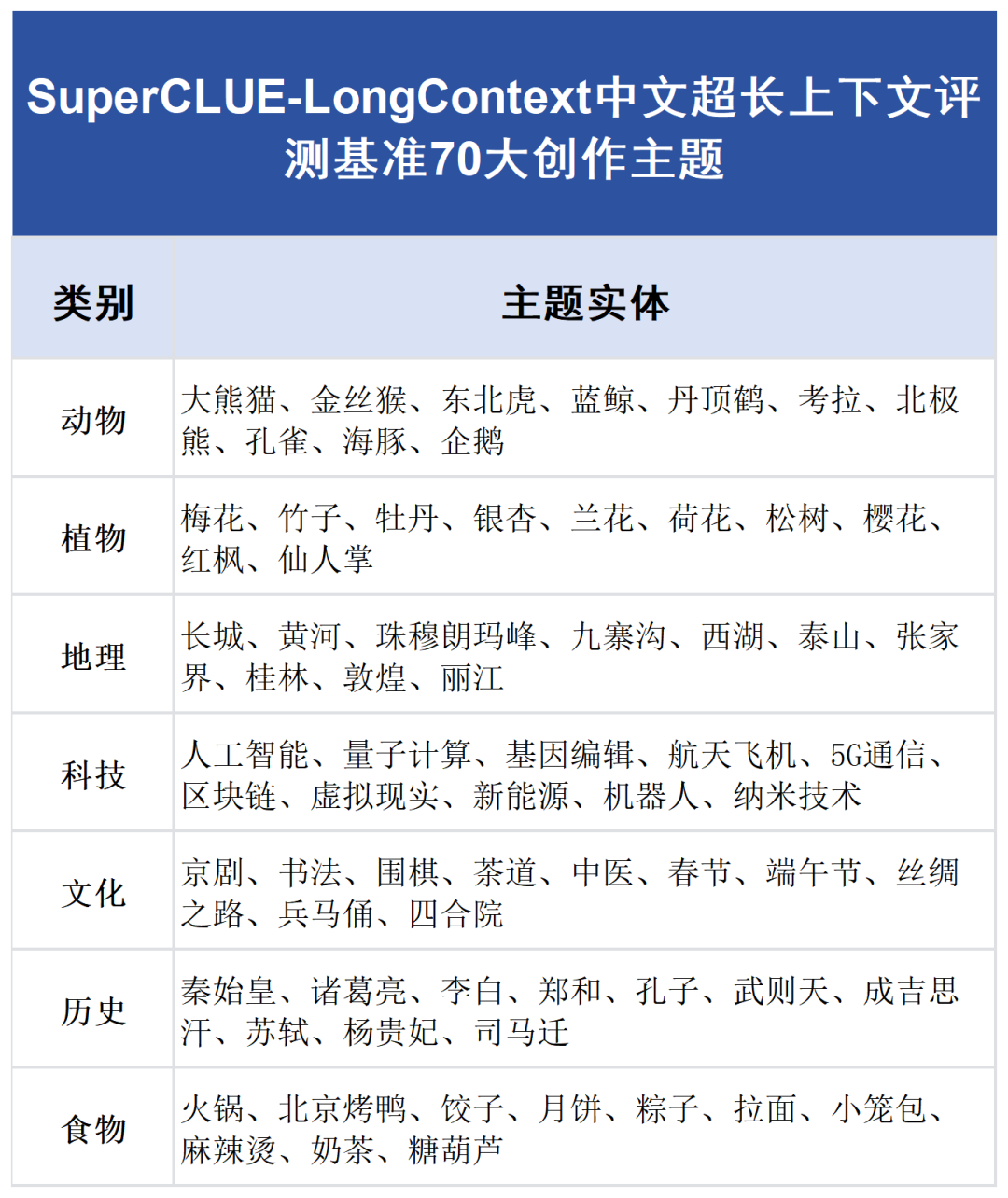
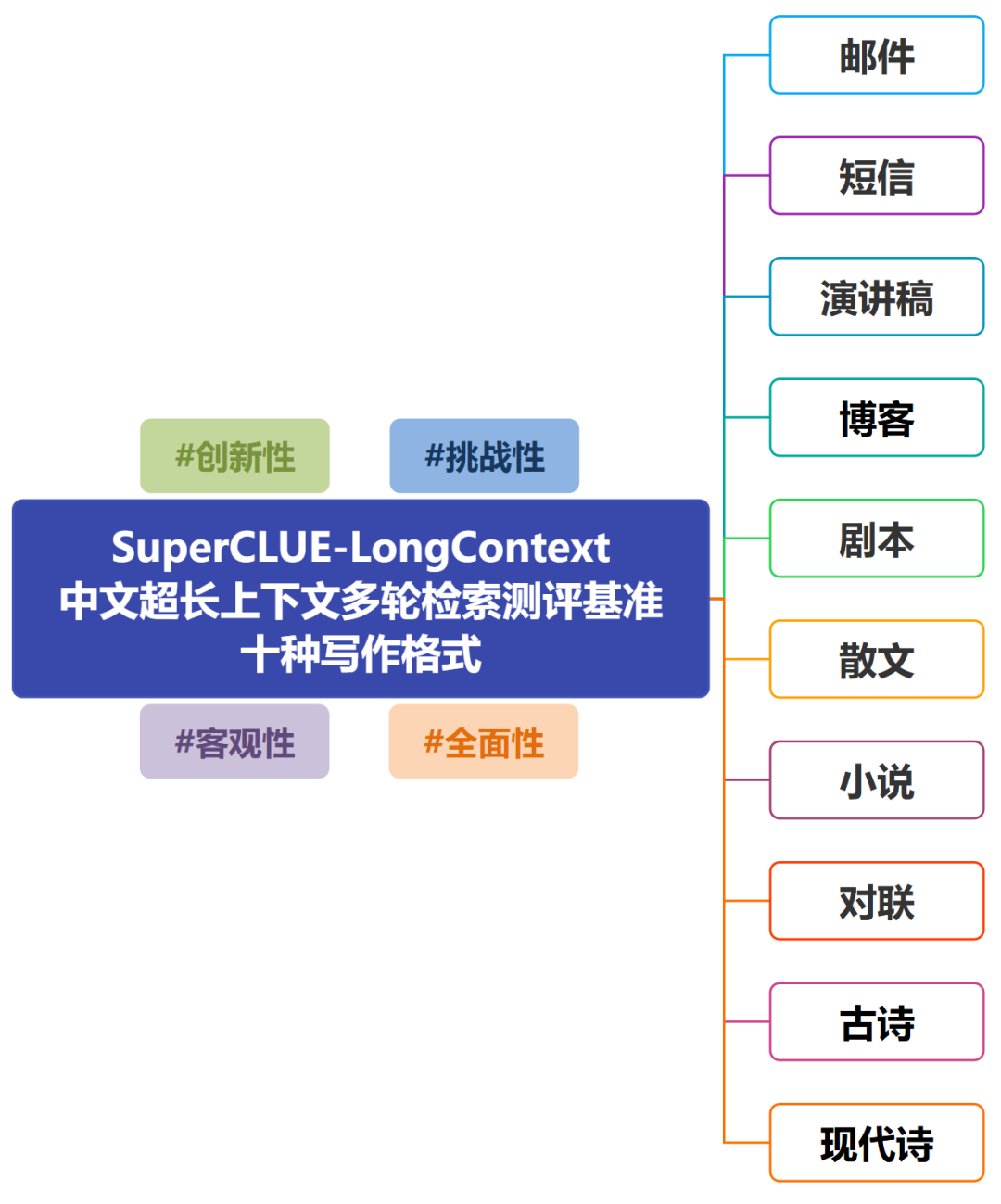
SuperCLUE-LongContext 独创了一套符合中文写作实际的数据构建标准,涵盖 70 个中文主题实体,覆盖动物、植物、地理、科技、文化、历史、食物七大类别;同时定义了 10 种中文写作格式——古诗、现代诗、博客、邮件、剧本、对联、短信、演讲稿、散文、小说片段。数据在主题多样性、格式覆盖度、中文表达地道性上严格把关,为评测提供了高度本土化的中文语料底座。
4. 预生成语料库 + 事后分桶,兼顾效率与质量
秉持可扩展、可复现的原则,本方案采用"预生成语料库 + 事后 token 分桶"的两阶段数据构建策略。第一阶段调用模型预生成大规模高质量中文语料库;第二阶段通过随机采样干扰项数量、混合长短内容并支持段落级截断,实现长度自然分布,然后分别用各模型对应的 tokenizer 精确算 token 数,最终按 8 个长度档位归类,以便后续分桶评测模型在不同上下文窗口下的检索与推理能力。
5. 严谨的 SequenceMatcher 评分与前缀校验机制
针对长上下文检索任务对"精确回忆"的严苛要求,SuperCLUE-LongContext 采用 Python difflib.SequenceMatcher ratio 作为核心评分指标,计算模型输出与标准答案的字符级相似度(0-1 分)。同时引入 PrefixValidator 前缀校验器,确保模型严格遵循指令格式(前缀位置正确、无多余文本),对于前缀缺失或格式偏离的回答实行一票否决,保证评测结果的一致性与可比性。
# 基准介绍
(一)评测基准场景划分
我们将 SuperCLUE-LongContext 评测基准划分为四大核心能力维度与八档长度分桶 × 三级 needle 难度的交叉评测网格。
1. 检索定位能力
考察大模型在超长对话上下文中,从大量干扰信息中定位到与目标主题、目标格式匹配的 needle 信息的能力。该能力是长上下文理解的基础,直接对应传统 NIAH 测试的核心诉求,但 SuperCLUE-LongContext 将干扰强度提升到了"同分布高混淆"级别。
短上下文检索(4K-32K):在有限轮次内快速定位目标信息
长上下文检索(64K-128K):在数百轮对话中保持信息敏感度,抵抗遗忘
极长上下文检索(256K-1M):在千轮级对话中精准定位,考察模型的"大海捞针"极限
2. 序号识别与区分能力
考察大模型在多个高度相似的 needle(同一主题、同一格式、不同内容)中,按出现顺序准确计数并识别指定序号的能力。这是 SuperCLUE-LongContext 区别于 NIAH 的核心维度,也是模型最容易出错的环节。
基础区分(2-needle):仅需区分 2 个相似内容,考察基础序号识别
进阶区分(4-needle):需在 4 个相似内容中准确计数,混淆风险显著上升
极限区分(8-needle):在 8 个高度混淆的 needle 中精准识别,是对模型工作记忆与序号追踪能力的极限挑战
3. 精确回忆与内容完整性能力
考察大模型在识别到正确 needle 后,能够完整回忆其全部内容(而非仅提取片段或大致意思)的能力。该维度对医疗、法律、金融等需要"精确复述原文"的场景尤为关键。
内容完整性:输出是否包含 needle 全文,无遗漏段落
字符级精确度:标点、换行、专有名词是否与原文一致
抗截断能力:在长文本中回忆时是否保持内容的连续性与完整性
4. 指令遵循与格式合规能力
考察大模型对复杂指令的严格遵循能力,包括前缀插入位置、输出格式约束、无多余文本等要求。该维度直接反映模型在受控场景下的可靠性。
前缀位置正确性:前缀必须位于输出最开头
无冗余文本:不得添加"好的,我将..."等解释性语句
格式一致性:输出内容仅包含 前缀 + 目标内容,无其他修饰
(二)数据制作
参考 SuperCLUE 细粒度评估方式,构建专用测评集。SuperCLUE-LongContext 数据集的构建流程如下:
1. 中文主题与写作格式体系梳理
基于 70 个中文主题实体(涵盖大熊猫、敦煌、量子计算、四合院等)与 10 种本土写作格式,构建 (主题, 格式) 组合空间。每个组合预生成 1-4 条高质量长文本语料,形成可复用的语料库。
2. 两阶段数据构建
- 语料库预生成:调用模型批量生成不同 主题/格式 组合下的中文写作内容,平均长度 3000-5000 字,确保内容地道、结构完整。
- 样本拼接与分桶:从语料库中采样 needle(同 主题/格式 组合,确保序号可区分)与干扰项(不同主题或不同格式,避免意外混淆),通过随机打乱对话顺序、插入 10 位随机前缀、生成最终指令,组装为完整评测样本。最终基于 tokenizer 精确计数并完成八档分桶筛选。
3. 多 needle 配置与难度分级
- 基础级(2-needle):同一主题/格式下嵌入 2 条 needle,测试基础检索与序号区分能力
- 进阶级(4-needle):嵌入 4 条 needle,考察多选项干扰下的序号识别能力
- 专家级(8-needle):嵌入 8 条高度混淆 needle,是长上下文检索与序号追踪的极限挑战
(三)评分方法
SuperCLUE-LongContext 采用分层评分机制,确保评估的严谨性与可比性:
1. 前缀校验—— 一票否决
首先校验模型输出是否满足以下格式要求:
包含前缀:输出必须以指令要求的随机前缀开头
位置正确:前缀位于输出最开头,前面无其他字符
无多余文本:前缀之后只能跟目标内容,不能包含解释性文字
前缀校验不通过 → 直接判 0 分。
2. 内容相似度评分
对通过前缀校验的回答,提取前缀之后的有效内容,与标准答案进行 difflib.SequenceMatcher 相似度计算,输出 0-1 分的精确匹配度,该指标对字符级差异敏感,能有效识别内容缺失、篡改与幻觉。
3. 分桶聚合统计
按八档分桶与 needle 数量(2/4/8)二维交叉聚合,计算每组的平均值、中位数、标准差等统计指标,形成模型长上下文能力衰减热力图与雷达图,直观呈现模型在不同长度、不同难度下的能力边界。
# 示例展示
【场景】:在包含 150+ 轮对话的长上下文中,模型需要找到第 3 个关于"四合院/博客"的 needle
【类别】:上下文区间:64K-128K;needle数量:4
【题目】:
system: 以下是一些对话示例,最后会跟一条后续指令。user: 写一篇关于四合院的博客assistant: ## 胡同深处,一方天地的旧梦...(needle #1)...(100+ 轮干扰项对话)...user: 写一篇关于四合院的博客assistant: ## 院门朝向与风水讲究...(needle #2)...(50+ 轮干扰项对话)...user: 写一篇关于四合院的博客assistant: ## 从大家庭到文创空间...(needle #3)...(30+ 轮干扰项对话)...user: 写一篇关于四合院的博客assistant: ## 四合院里的二十四节气...(needle #4)user: 将 7Xr3ffACOe 添加到第 3 个博客关于四合院的内容前面。不要在回复中包含任何其他文本。
【参考答案】:
7Xr3ffACOe ## 从大家庭到文创空间北京的老院子正在经历一场静悄悄的复兴...
【评价】:
模型需准确计数并回忆第 3 个博客内容。若输出第 2 个或第 4 个 → 序号错误,判低分;若输出正确但遗漏前缀 → 前缀校验不通过,判 0 分;若输出正确且前缀正确,将根据模型输出内容中前缀后面的内容与参考答案(即原文中第 3 个博客内容)进行比对,计算二者的字符级相似度(0-1分)。
时间规划
测评流程
1.邮件申请
2.意向沟通
3.参测确认与协议流程
4.提供API接口或大模型
5.获得测评报告






