 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库OpenAI后训练工程师翁家翌,给Agentic AI提出了新范式假设

文|晓静
编辑|徐青阳
过去十年,AI 变强主要依赖一条路径:把更多数据和算力投入到更大的模型里,让经验沉淀在神经网络参数中。这条路径造就了 ChatGPT 之后的大模型跃迁,也留下了一个难题:模型越来越强,但它为什么成功、为什么失败,很多时候仍然难以解释和修正。
OpenAI工程师翁家翌最近做的实验,提出了另一种可能:在明确目标、可运行环境和反馈闭环中,AI 不只可以通过训练模型变强,也可以通过“自主改代码”变强。
2026 年 5 月 8 日,翁家翌在个人博客《Learning Beyond Gradients》中系统写下了这组实验,并同步公开代码仓库、CSV 实验日志与视频回放。他长期专注于强化学习与后训练基础设施,参与过 ChatGPT 初始发布,并在GPT-4、GPT-4 Turbo、GPT-4o、o-series、GPT-5 等项目中承担相关工作;加入OpenAI前,他本科毕业于清华大学计算机系,硕士就读于卡耐基梅隆大学,也是开源强化学习库Tianshou与高性能并行环境引擎 EnvPool 的主要作者。

图片由AI生成
他让Codex反复写策略代码、运行环境、读取日志、查看回放、定位失败,再修改代码、补充测试、继续评估。多轮迭代后,Codex “养出”了一套纯 Python 程序化策略:在 Atari Breakout 中打到 864 分理论满分,在MuJoCo Ant和HalfCheetah这类机器人控制仿真环境中,也跑出了接近常见深度强化学习算法的成绩。
这组实验真正重要的地方,是一个核心问题: 当coding agent足够强,学习是否一定要发生在神经网络权重里?
在这套实验中,经验被写进代码、测试、日志和回放,变成一套可以阅读、修改、复查和审计的软件系统。如果这个方向继续成立,Agentic AI的下一步可能不只是训练更大的模型,还有让模型参与维护一套持续进化的工程系统。
01
从387分到满分的工程闭环
翁家翌在博客中写道,这个实验的起点其实是一个工程需求。他在业余时间维护EnvPool,需要一种比“每次都跑一个神经网络”更便宜的方式来测试游戏环境是否运行正常,因为把神经网络放进CI太贵了。原始问题是:能否写出便宜、可复现、明显强于随机策略的启发式规则,把环境驱动到信息丰富的状态?

他用 Codex(基础模型为 gpt-5.4)尝试写一个完全基于规则的版本。一开始的提示词非常直接:“写一个能解决Breakout的策略。”结果不理想。低分本身没有提供任何信息,比如动作语义可能错了,状态检测可能错了,评估流程可能错了,策略结构本身也可能太弱。
随后翁家翌改变了任务形式。他不再要求Codex直接交出一个policy.py,而是要求它维护一整套循环:探测动作和观测、写状态检测器、写策略、跑完整 episode、记录 trials.jsonl 和 summary.csv、生成视频或曲线、检查失败模式、修改策略、简化代码、跑回归。
Breakout的实验记录把这个过程记录得非常清晰。第一轮 Codex 先确认动作空间和观测形状,从 RGB 帧里识别球、挡板和砖块的颜色,再用图像标签去扫描128字节的Atari RAM。最初的baseline只有99分。加入隧道偏移逻辑之后,分数升到387分。
387 分是一个容易让人误判的局部高分。策略已经能稳定接球,但球路被困进周期性循环:不会丢命,也不会再打到新砖块,分数被卡住。如果是人写代码,可能会继续微调"接球准确度"。Codex看了视频和最近几十步轨迹,把问题定位到球路缺乏扰动。
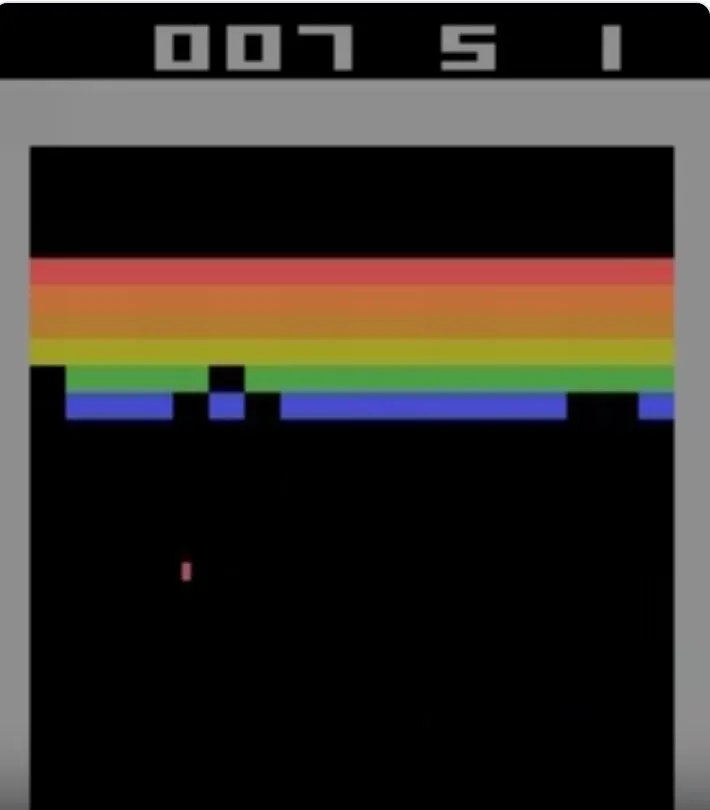
图:Atari Breakout 游戏画面。玩家通过控制底部挡板反弹小球,逐层击碎上方的彩色砖墙。Codex 在该游戏中达到了 864 分的理论满分。
随后 Codex 加入了一个“打破循环”的机制:若长时间没有奖励,就周期性地给落点预测加一个偏移量,把球打出局部循环。分数从387跳到507。继续迭代时又出现新问题:对于快速的低球,常规拦截会让挡板“过度领先”而漂走。Codex 加入了fast_low_ball_lead_steps=3参数,分数从507跳到 839。最后从839到864的提升更像是在维护一个已经复杂起来的系统:尝试 deadband、发球偏移、卡住偏移、砖块平衡偏置、前瞻步数;很多方向都没有效果,最终有用的改动是后期条件,“第一面砖墙打完后,只在球离挡板较远时启用卡住偏移,球靠近时则逐步释放”。
最终的 RAM 默认配置在三轮 episode 上稳定输出 864 / 864 / 864 分,达到 Breakout 的理论上限。Codex 随后又把同一套几何控制器迁移到纯图像输入版本——不读 RAM,仅靠 RGB 分割来识别挡板、球和砖块平衡。图像版本第一次跑出 310 分,再跑出 428 分,第七次本地 episode 后达到864分,对应14504步本地策略环境步。
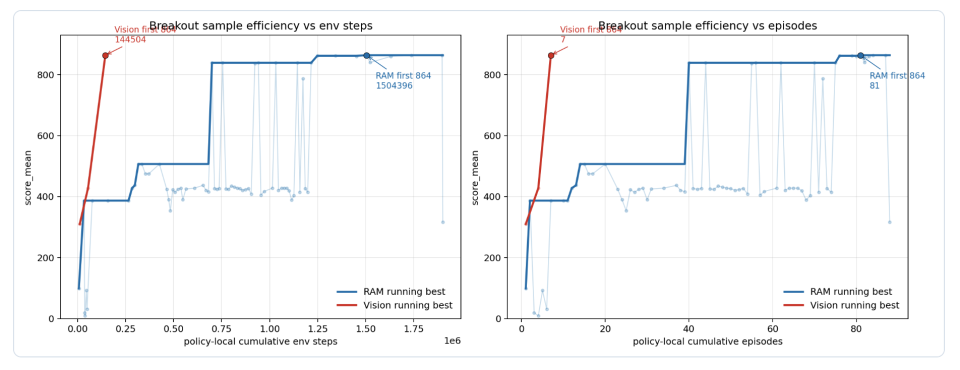
图:Codex 在 Breakout 上的样本效率曲线。蓝线是直接读取游戏内存(RAM)的版本,红线是只看屏幕画面(Vision)的版本。RAM 版本经历了 99 → 387 → 507 → 839 → 864 的多次跳跃,最终在第 81 个 episode、累计 150 万环境步时首次达到满分;Vision版本由于是从 RAM 版本迁移过来的成熟结构,仅用7个episode、约1.45万环境步就达到了864 分。
翁家翌特别提示,这不应该被理解成“图像输入从零起步只用14.5K步打到满分”。真实流程是 Codex先在RAM版本上发现几何控制器、循环打破和后期偏移释放,结构稳定后才把状态读取层从RAM切换到 RGB。14.5K 是图像版本的迁移预算。
02
Heuristic Learning的定义
为这个不断进化的“软件策略”找一个名字,比写出第一版策略要难。翁家翌最终把这个过程命名为 Heuristic Learning(HL,启发式学习 ),并把它维护出的对象命名为 Heuristic System (HS,启发式系统)。
按他在博客中的定义,HL由程序代码构成,和今天常见的深度强化学习一样,它有一套状态、动作、反馈、更新的循环。不同的是,被更新的对象是软件结构,而不是神经网络参数;它的反馈被 coding agent消化,可以来自环境奖励、测试用例、日志、视频、回放或人类反馈;它的更新不使用反向传播,而是coding agent直接编辑策略、状态检测器、测试、配置或记忆。
需要补充的是,“用程序而非神经网络做策略”并不是翁家翌首创的概念。学术界对 程序化强化学习 (Programmatic RL)已经讨论了多年:2019年Rice大学和 Caltech 提出的 PROPEL 框架,研究的就是把策略表示为符号语言中的短程序的强化学习方法;2021 年的 LEAPS 工作进一步学习程序嵌入空间,把可微的程序策略与RL训练结合起来;2023 年 ICML 上的 HPRL 提出分层程序化强化学习,让meta-policy组合多个程序;2024 年来自台大与微软的LLM-GS 框架则用LLM的编程能力和常识推理引导程序化 RL 策略的搜索。
这些研究的共识是:相比神经策略,程序化策略具备更好的可解释性、可形式化验证性,以及对未见场景的泛化能力。
翁家翌这次的实质贡献,在于把coding agent视为维护启发式系统的工程通道。过去做程序化RL,要么依赖手工设计的领域专用语言,要么依赖在受限程序空间里的搜索算法;翁家翌则借助Codex 把代码、日志、测试、视频回放、参数调整都纳入同一个 agent 的工作流,让程序策略的迭代成本被一次性压低。换句话说,他在论证一条 新的工程路径 :当 coding agent 足够强,过去那些被嫌弃“维护成本太高”的启发式策略可能会重新变得划算。
翁家翌在博客中给出了一张对照表,清晰说明HL 和 Deep RL 的差别:策略形式上,前者是规则、状态机、控制器、模型预测控制(MPC)、宏动作组成的代码,后者是神经网络参数;状态形式上,前者是显式变量、检测器和缓存,后者是网络可读的观测向量;反馈形式上,前者把测试、日志、回放都视作有效信号,后者主要依赖固定的奖励函数;记忆形式上,前者可以显式存储试验、摘要、失败原因和版本 diff,后者在 on-policy 算法里基本没有,在off-policy 算法里依赖replay buffer。
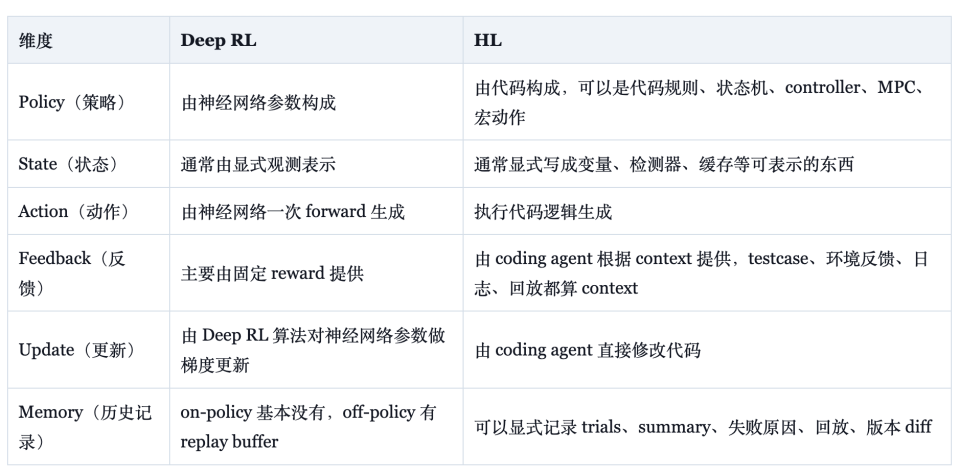
这套对照证明了HL拥有一些工程意义上的属性:策略可解释,可以被翻译成自然语言;样本效率以“一次有效的代码改动”为单位,而不是缓慢的梯度更新;旧能力可以变成回归测试、固定种子回放或 golden case;对训练种子或测试漏洞的过拟合,可以通过简化、回归检查和多种子评估来约束;旧能力不必只存在于权重中,也可以存在于规则集和测试中,这部分回应了神经网络长期未能很好解决的灾难性遗忘问题。
03
Atari57 的批量验证:边界与短板
如果只看Breakout,故事很容易被简化成“AI 写出了一份完美策略”。但翁家翌没有停在Breakout,他又把这套Codex工作流批量扩展到Atari57,跑了57款游戏、两种观测模式、三次重复,共 342 条“无人值守”搜索轨迹。
实验设计相当严苛。每款游戏分别用两种输入方式测试:一种是直接读取游戏内存,一种是只看屏幕画面,每种方式独立重复三次。这样总共产生了342条“无人值守”的实验轨迹:每个 Codex agent拿到同一份提示模板,自己摸索动作、自己写代码、自己跑实验、自己记录结果,没有人在旁边给提示。约束条件被写得很死,不准训练神经网络、不准读游戏源代码、不准利用任何隐藏信息,所有用来调试和试错的步数都必须计入总开销。这是为了避免Codex用任何“偷看答案”的方式作弊。
衡量结果时通常使用一个叫 HNS(Human-Normalized Score,人类归一化分数)的指标——简单说就是把每款游戏的得分按“人类玩家平均水平 = 1”做标准化,方便不同游戏之间横向比较。
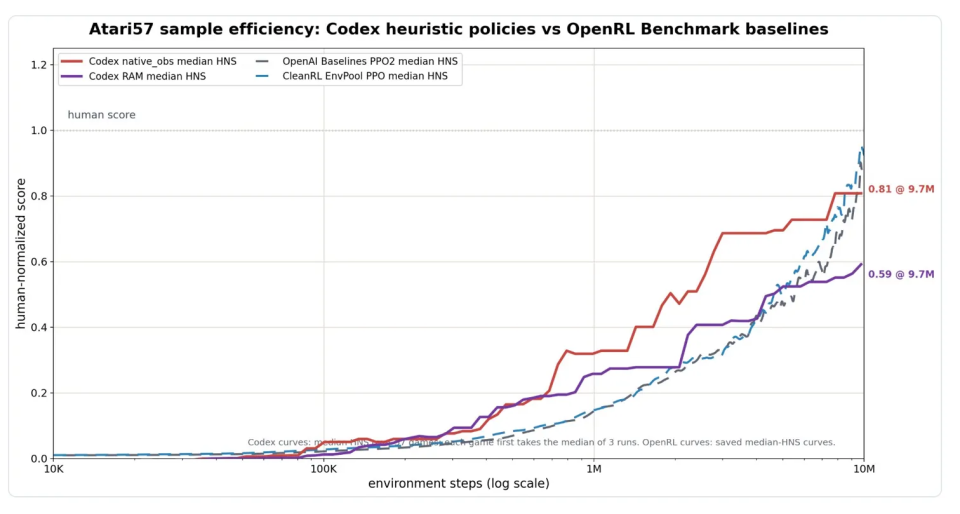
图:Atari57 全集上的样本效率对比。横轴是环境步数(对数刻度),纵轴是 HNS(人类归一化分数,1.0 表示达到人类玩家平均水平)。Codex 画面输入版本(红线)在前期效率明显领先 PPO 基线(蓝/灰虚线),到 970 万步时达到 0.81,与 PPO在1000万步附近的水平接近;Codex 内存输入版本(紫线)则收敛在 0.59。
按这个标准衡量,Codex在前期效率上显得相当亮眼。在仅仅消耗100万环境步时,Codex用画面输入的中位 HNS 已经达到0.32,用内存输入达到0.26,明显高于同期PPO这类经典强化学习算法的水平。到970万步时,Codex 画面版本达到0.81,已经接近 PPO 在 1000 万步时大约 0.88 到 0.92 的水准。如果允许对每款游戏挑选 Codex 表现更好的那种输入方式聚合,Codex中位HNS是 0.83, OpenAI Baselines PPO2是0.80,CleanRL EnvPool PPO是0.98——基本打成平手。
但翁家翌自己很冷静地划了一条边界:这只是环境交互效率的比较,没有把 Codex 阅读日志、写代码、看视频的成本折算进去。 “跑得快”不等于“总成本低”,后者目前还是个黑箱。
更值得关注的是,Codex在57款游戏上的表现并不均匀。在Breakout、Boxing、Krull等几何结构清晰的游戏里,启发式策略和深度强化学习都能明显超过人类水平;在Asterix、Jamesbond、Tennis这类有明确规则的游戏里,启发式策略甚至更强;但在 Atlantis、VideoPinball、RoadRunner、StarGunner 这类节奏快、模式复杂的游戏里,PPO仍然碾压。
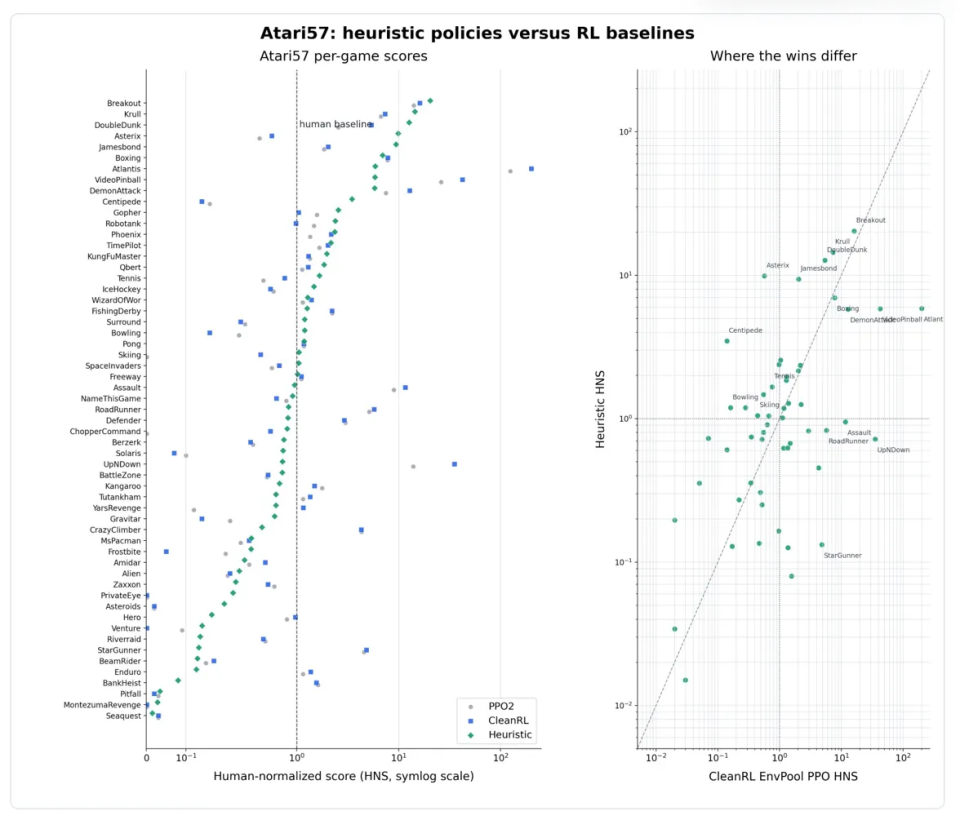
最具警示意义的反例是 Montezuma’s Revenge。这是强化学习领域著名的“硬骨头”,主角需要在错综复杂的地下城里寻找钥匙、躲避敌人、打开门,奖励信号极其稀疏,是经典的"长期规划 + 失败恢复"难题。Codex 在这款游戏上确实拿到了400 分,但翻开它生成的策略文件就会发现,那不是一份真正的“策略”,而是一串被硬编码下来的86个动作序列,对应1769 个环境步:更像背下了一条固定路线,而不是学会了走迷宫。翁家翌特别提到:“这是一个边界案例,不应该被理解为通用的 Montezuma 策略。”
Montezuma暴露的是 Heuristic Learning 的表达力极限。 普通的程序策略本质是“看到什么状态就做什么动作”的反应式逻辑,难以处理需要严格动作时序、需要从中间状态接续计划、需要长视野规划的任务。这类任务需要的不只是更多 if-else,而是更接近“宏动作组合 + 可恢复搜索状态 + 长期记忆”的程序结构。它告诉我们一件事:哪怕 coding agent 再强,有些问题也不是普通代码能装下的。
04
一旦范式成立,产业意义在哪里?
把视角拉回到产业。如果Heuristic Learning这条路径真的成立,“即 coding agent 能够稳定维护出超过手工规则、接近 RL 基线的程序化策略”,它的实际意义在哪里?
第一个落点是机器人控制,特别是结构相对稳定的场景。 翁家翌在博客中给出的设想是关节级 HL、肢体级 HL、全身平衡 HL、任务级 HL 的层级分工。低层处理安全和低延迟控制,中层处理步态和接触,高层处理任务和长期记忆;coding agent 不必“理解走路”,它更像一条插入系统的更新通道,把失败视频、传感器流、仿真结果送回系统,再把反馈重写为代码、参数、保护规则和记忆。
仓储 AGV、巡检机器人、工厂机械臂、标准化分拣这类场景,环境结构相对固定、安全边界明确——如果核心控制策略能固化为轻量代码,机器人每一步动作不必跑一个大策略网络,部署端对高功耗GPU推理卡的依赖会下降,更多负载交给传统控制器与本地程序逻辑。
这并不意味着机器人不需要 GPU,感知、定位、建图、语义理解仍然要靠神经网络;变化的是 GPU 的角色,从“每一秒为端到端动作决策烧算力”变成“在感知、离线仿真、策略生成、异常分析中周期性发挥作用”。
第二个落点是安全关键场景的可审计性。神经策略最棘手的工程问题是出问题后无法定位。一个机械臂在某个角度突然失败、一辆车在某个边缘场景误判、一台医疗机器人在某个罕见姿态下动作异常,工程师没有办法回答“是哪个权重导致了这个错误”,最后只能补数据、重训、回归测试,然后赌新模型没有引入新问题。
如果策略以代码形式存在,状态变量、条件分支、失败日志和回归测试都是可见的;某个危险动作可以被硬编码禁止,某个corner case可以写成测试,某个错误状态转移可以被单独修补。这不让系统天然更安全,但让安全问题第一次能进入正常的软件工程流程——可以被代码评审、可以被 CI 拦截、可以被 SRE 值班响应。在自动驾驶、工业机械臂、医疗机器人这类需要监管与责任划分的领域,这种可审计性本身就是商业价值。
第三个落点是持续学习与在线学习的工程化。 翁家翌在博客里把这条作为整篇文章的论证主线。神经网络的灾难性遗忘是结构问题:学了新东西,旧能力会被冲掉。 HL 也会遗忘,但形式更工程化:一条新规则修复了一个失败模式却破坏了旧场景;一条新记忆反复把 agent 引向错误方向;一个测试范围太窄、策略学会了利用它;一次补丁改了共享接口、旧调用路径悄悄失效。
这些问题没有自动消失,但它们都是软件工程已经处理了几十年的问题,有现成的工具链——回归测试、版本 diff、固定种子回放、golden trace、显式记下的失败方向。
一个健康的 HS 必须同时具备两种操作:吸收新反馈、压缩历史补丁;只增不减的 HS 最终会变成一团没人敢动的“代码泥球”。换言之,HL 把“如何更新参数”这个数学问题,改写成“如何维护一套不断吸收反馈的软件系统”这个工程问题。
后者未必更容易,但更接近人类已有的能力边界。
第四个落点是 Agent 产品的能力沉淀。 当下 Agent 产品最缺的是稳定的工具调用、可靠的执行链路、可复用的失败经验和可审计的任务记录。 如果HL的逻辑成立,Agent在执行过程中的记忆会沉淀为可以跨会话、跨用户、跨任务复用的代码资产。它能直接对接到既有的DevOps 流程,也意味着不同公司、不同团队的Agent可以共享heuristic,但不需要共享模型,这是神经网络方案做不到的事情。
但是,需要强调的是:以上四个落点都依赖HL这条路径在更复杂任务上被进一步验证。 Breakout和Ant是相对干净的环境,真实机器人面对的是地面摩擦变化、光照变化、执行器延迟、传感器噪声,这些都还没有在公开材料里被系统评估。 Montezuma 反例已经说明,长视野任务需要超出普通 if-else 的程序形式。这套设想究竟能走多远,还要看下一阶段的实验。
05
工程债从权重转移到代码
翁家翌在博客中给的判断很克制。他写道,HL不能完成神经网络能做的所有事情,它受限于代码能表达的内容,尤其在复杂感知和长视野泛化上。以今天的认知,他无法想象一个agent 用纯 Python 代码、不借助任何神经网络去解决 ImageNet。真正值得讨论的问题,是如何把神经网络与 HL 结合起来共同处理Online Learning和Continual Learning。
他给出的分工借用了 System 1 / System 2 的语言:专门化的浅层神经网络承担 System 1 的一部分,负责快速感知、分类与物体状态估计;HL 也承担 System 1 的一部分,负责新鲜数据处理、规则、测试、回放、记忆、安全边界和局部恢复;LLM agent担任System 2,向HL提供反馈、改进数据,并周期性地从HL生成的数据中提取信息以更新自身。
如果说深度学习过去十年证明了“经验可以被压缩进权重”,那么翁家翌这次提出的假设是另一种命题:在coding agent时代,经验也许可以重新变成可读、可改、可测试的软件。

推荐阅读

OpenAI让模型“张嘴”,你要注意:辱骂AI,很贵的

ChatGPT免费的“代价”

估值2300亿美元的xAI,“死于”5月6日





