五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库OpenAI 模型全景图:ChatGPT5.5为什么赢,Image2.0 又想解决什么

前言
本篇报告核心围绕三点展开:
OpenAI 的公开模型演进,并不是一条单一“参数越大越强”的直线,而是三条路线并行推进:以 GPT 为代表的语言预训练路线、以 InstructGPT/ChatGPT/o 系列为代表的对齐与推理路线、以及以 CLIP、DALL·E、4o Image Generation 为代表的视觉—多模态路线。到 2024—2025 年,这三条路线才在 GPT-4o、GPT-5 这样的统一产品层重新汇合。
ChatGPT 的历史地位不在于“一个更强的 GPT”,而在于它把语言模型能力、RLHF 对齐、聊天界面、免费分发和网络传播机制捆成了一个社会级产品;相较之下,所谓 Image2.0 相关路线的关键,不是“会画图”,而是把图像生成推向可编辑、可持续对话、可部署到真实工作流、可做安全追溯的生产级视觉系统。也因此,ChatGPT 与 Image2.0 虽然都属于“大模型”,但其技术重心并不相同:前者重在“意图理解、推理与工具调用”,后者重在“视觉表示、caption 质量、文字渲染、编辑一致性与版权/溯源治理”。
真正重要的转折点有六个:GPT-3 让“大模型会写”成为社会共识;Codex 让“代码生成”进入产品化;DALL·E 2 让“文本生图”从概念变成大众震撼;ChatGPT 让生成式 AI 进入全民入口;GPT-4/4o 让多模态与黑箱化争议同步升级;而 2025 年的 4o Image Generation、gpt-image-1以及后续图像模型中呈现的能力,则说明 OpenAI 的目标已从“展示模型”转向“把模型做成工作系统”。
*特别说明:“Image2.0”技术上并没有充分公开披露,本文撰写时其并未拥有独立论文与系统卡,因此没有将其作为明确基础模型名,而是认为是一种产品代际表述。更可靠的公开技术锚点,是 2025 年已明确发布的 4o Image Generation 与 gpt-image-1。
模型时间线关键属性总表
本文中的“完整时间线”,采用的是有独立官方发布页、系统卡、研究页或原始论文的主要公开模型/家族与关键变体口径。并没有将每一次 API snapshot、隐藏升级、灰度别名都强行列入,以避免造成伪精确。为了清楚展现OpenAI放弃游戏中的强化学习,开始做GPT之后的进化史;同时也为了展现Image2.0的强大,我用网页版绘图功能做了下图。

图1. 模型时间线(由image2.0生成)
说明:未知”表示官方/论文未披露,或无法在公开资料中稳定核验。
Open vs Close
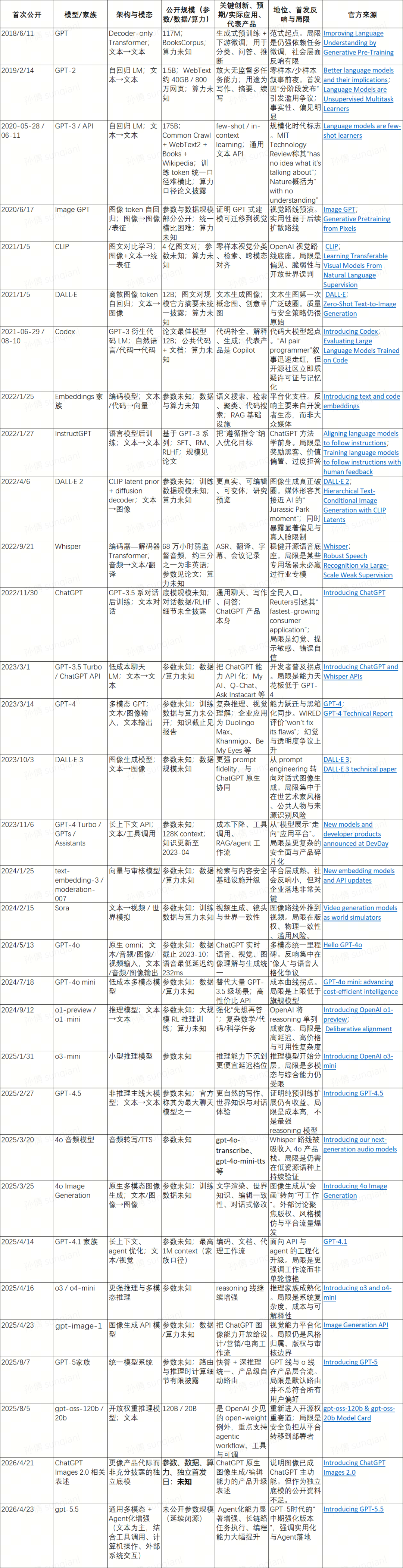
OpenAI的Open程度也一直是大众的关注所在,如果观察其公开参数(官方或原始论文明确披露参数)情况,除去权重开源的gpt-oss系列,我们只能看到下图。这张图恰好体现了一个重要事实:OpenAI 在 2020—2021 年仍愿意把“参数规模”作为公共叙事中心,而从 GPT-4 起逐步转向披露更少、产品更多、系统性更强的发布风格。也就是说,OpenAI 的技术路线变化,不仅体现在模型本身,也体现在“公开什么、不公开什么”的治理与商业策略上。
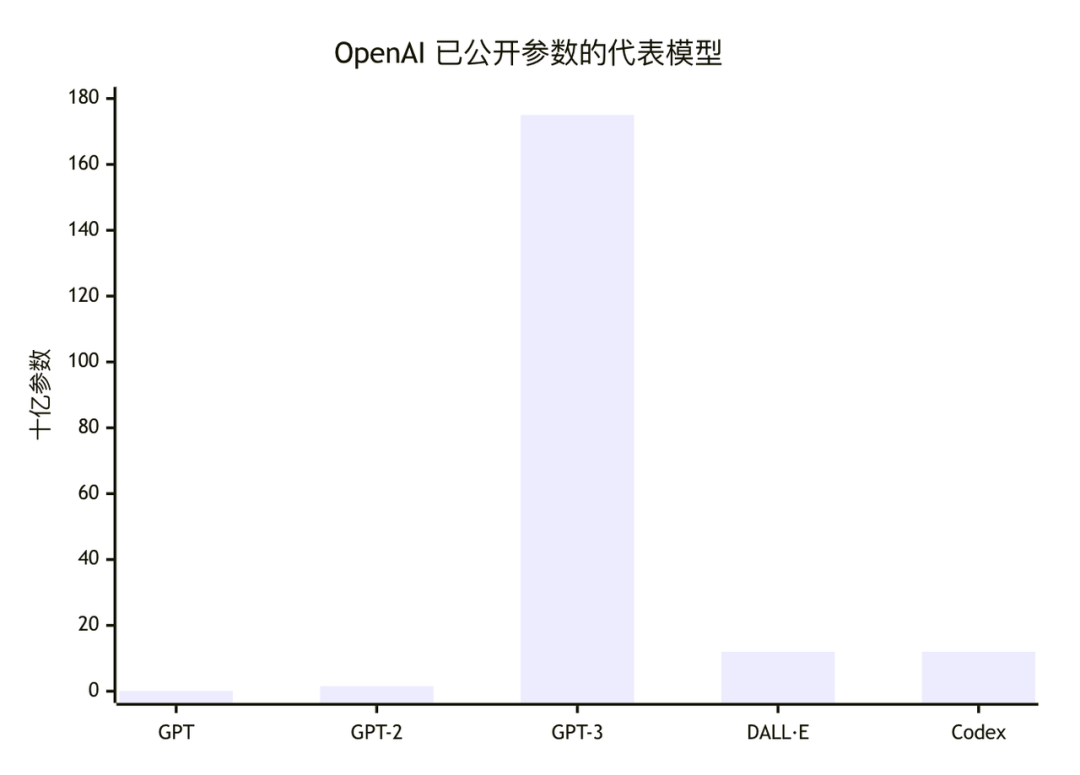
模型地位与首发反响
GPT 到 GPT-3:从“预训练范式”到“规模神话”。
最早的 GPT、GPT-2、GPT-3,地位并不完全一样。GPT 的历史意义在于方法论:它把“先学语言、再做任务”变成正统路线;GPT-2 的历史意义在于证明“规模本身就是能力来源”,并第一次把模型发布变成公共政策议题;GPT-3 的历史意义则是把“少样本提示学习”变成大模型时代的基础接口。也正因为 GPT-3 的表现过于像“会了很多”,质疑也来得很快:一类批评指向幻觉、偏见和事实性不足,另一类批评指向闭源与不可复现。前者后来推动了 InstructGPT 和 ChatGPT,后者则在 GPT-4 时代进一步激化。
Codex:把语言模型第一次做成可持续付费的生产力工具。
Codex 不是公开讨论里最响亮的名字,却是 OpenAI 史上极关键的一环:它证明“在特定高价值领域做语料偏置 + 界面封装”,比单纯追求通用 benchmark 更容易形成产品闭环。Codex 基于自然语言与代码进行训练,最重要的现实落地就是 Copilot。它的“地位”在于把 LLM 拉进了真实工程流;它的争议也很典型:开源社区很快把问题集中到代码来源、许可证兼容、近似照抄与记忆化风险上。换句话说,Codex 是 OpenAI 第一次在商业上明显尝到“模型即副驾驶”的甜头,也是第一次正面遇到生成式 AI 与知识产权冲突。
InstructGPT 与 ChatGPT:能力本身不够,对齐才是产品化门槛。
InstructGPT 的方法学价值极高:SFT、奖励模型、RLHF 共同把“正确完成用户指令”写进了目标函数。这一步看似是后训练,但本质上改变了模型的产品性格。ChatGPT 则把这套方法推向大众。它的地位,不只是“一个基于 GPT-3.5 的聊天机器人”,而是第一个让普通用户愿意每天都打开的大模型产品。Snap 的 My AI、Quizlet 的 Q-Chat、Instacart 的 Ask Instacart 等案例,说明 GPT-3.5 Turbo 让聊天能力真正渗透到了应用层;而 ChatGPT 自身则成了史无前例的分发器。
GPT-4、GPT-4 Turbo、GPT-4o、GPT-4.5、GPT-5 与 o 系:从“更强模型”走向“系统化智能”。
GPT-4 的首发意义非常大:它把视觉输入、复杂推理、企业级可靠性都抬高了一档,但同时也把“前沿模型为何越来越不披露参数和数据”变成公开争议。后来 GPT-4 Turbo 强调上下文窗口与工具调用,GPT-4o 强调原生音频/视觉/图像统一,o1/o3 则把“推理时计算”与“先思考再回答”独立为产品卖点,GPT-4.5 返回到“更自然、更有世界知识”的非推理主线,最后 GPT-5 尝试把快答与深推理重新以路由方式统一。其总体地位可以概括为:**OpenAI 的主线不再只是训练一个更大的模型,而是在构建“模型 + 路由 + 工具 + 产品默认接口”的系统。**对应的批评也从“会不会胡说”,升级到“不透明、太像人、难审计、默认行为难预测”。
CLIP、DALL·E、DALL·E 2/3、4o Image Generation 与 Image2.0:视觉路线的关键不在审美,而在表示与可控性。
很多人把 OpenAI 的图像路线理解成“DALL·E 会画画”。这其实低估了 CLIP 的意义。CLIP 先把图文对齐做成通用表征,把图像理解的核心从“监督标签”换成“自然语言对齐”,其真正价值不是生成图,而是为后面的图像生成、检索、跨模态理解提供共享语义空间。DALL·E 仍然带着早期 GPT 路线的味道:把文本和图片都离散成 token,然后用统一自回归模型生成。不过它独特的意义在于其把文本生成图像做成可见产品。DALL·E 2 借助 CLIP latent prior 与 diffusion 把质量和编辑能力推高,DALL·E 3 又用更好的 caption/recaptioning 提升了 prompt fidelity。到了 2025 年的 4o Image Generation 与 gpt-image-1,重点不再是“图好看”,而是是否能在对话上下文里反复编辑、是否能渲染清晰文字、是否能服务设计/营销/电商工作流,以及是否能做安全溯源。Reuters 与外部媒体对 2025 年图像热潮的报道,关注点已经不只是“惊艳”,而是风格模仿、版权与大规模流量扩散;这意味着图像生成已经从 demo 进入产业摩擦区。
Whisper、Embeddings、Moderation、Sora:OpenAI 的“隐形中台”。
真正支撑平台化的,往往不是最出圈的模型。Whisper 为语音输入提供了低门槛高鲁棒底座;Embeddings 和 moderation 系列让检索与安全审查可工程化;Sora 则说明 OpenAI 希望把视觉能力继续外推到视频与世界模拟。这些模型/家族的媒体声量不如 ChatGPT 和 GPT-4,但从产品架构看,它们构成了 OpenAI“主模型之外的能力层”和多模态拼图。
中文世界的反响则更偏产业化。新华社在 2024 年的综述里,已经把 ChatGPT 视为这一轮全球大模型竞赛的引爆点;中文科技与财经报道的关心点,也明显集中在“能不能形成应用生态、会不会重塑搜索/办公/教育/设计软件”。这与英文媒体更强调“能力边界、版权与伦理”并不矛盾,恰好说明 ChatGPT 的影响已从科研演示变成产业现实。
两条技术路线
个人认为,“ChatGPT 路线”可以理解为会话式/通用 LLM 路线,“Image2.0 路线”可以理解为 OpenAI 从 DALL·E 到 4o image/gpt-image-1/ChatGPT Images 2.0 的图像与原生多模态路线。
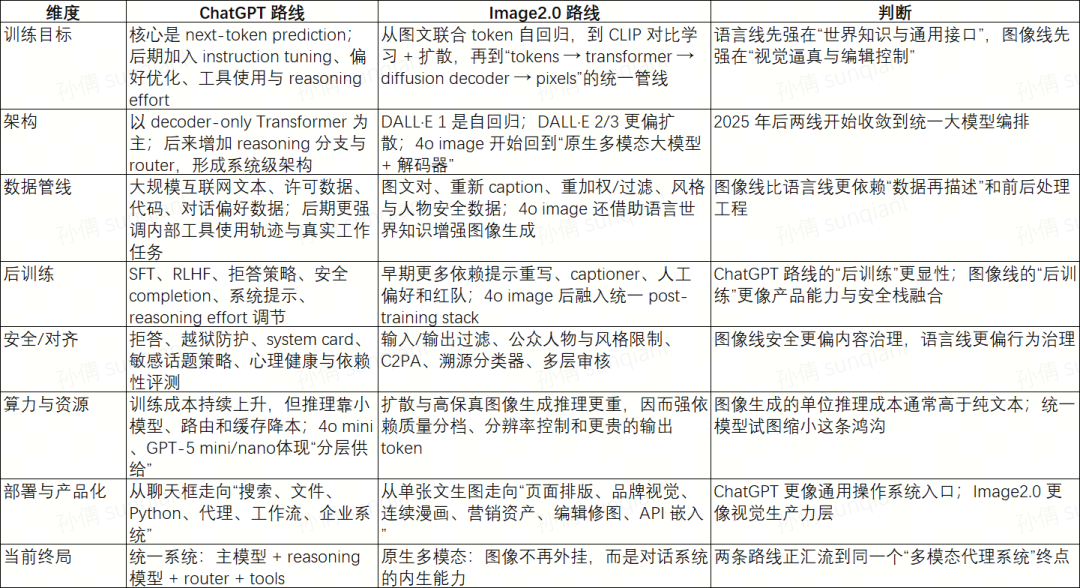
可以把这两条路线的差异概括得更直白一些。ChatGPT 路线解决的是“如何让模型在语言里懂用户、遵循意图、调用工具并完成任务”;Image2.0 路线解决的是“如何让模型在视觉里真正服从指令、保持连续性、处理字体与布局,并把图像纳入统一工作流”。前者的难点在对齐和代理,后者的难点在视觉真实感、精确可控和安全约束。2025 年之后的 OpenAI 选择并不是二选一,而是把两者合并:同一个系统既能写、能算、能搜、能看,也能画。
如果要对“ChatGPT 与 Image2.0 等大模型的技术路线”做结论,最重要的一点是:OpenAI 已从“单模态基础模型公司”转成“以统一多模态代理系统为目标的产品公司”。这也是为什么 2025–2026 年的官方发文,不再执着于参数,而更强调 real-world work、tool use、documents、spreadsheets、scientific research、professional outputs 和 image assets。路线层面看,这是一种从“模型 scaling”走向“系统 orchestration”的转向。
尾语
过去几年,外界总喜欢把 OpenAI 的故事讲成一条简单曲线:参数越来越大,模型越来越强。但如果把时间线真正摊开,会发现这其实是两条路线交错推进的历史。第一条是 ChatGPT 所代表的语言路线:从 GPT 的生成式预训练,到 GPT-2 的规模化、GPT-3 的 few-shot,再到 InstructGPT 和 ChatGPT 的 RLHF 对齐,目标始终是让模型更懂人、更会按要求做事。第二条则是图像与多模态路线:从 Image GPT、CLIP、DALL·E,到 DALL·E 2、DALL·E 3,再到 4o Image Generation、gpt-image-1 与 ChatGPT Images 2.0,目标从“生成一张图”升级为“在真实工作流里做出可用的视觉产物”。
真正改变行业叙事的,不是某一个参数数字,而是三个拐点。第一个是 GPT-3,它证明大模型可以在几乎不微调的情况下迁移到大量任务上;第二个是 ChatGPT,它把原本属于研究者和开发者的能力包装成普通用户可用的对话入口,并迅速成为“史上增长最快的消费者应用”;第三个是 GPT-4o 以及后续 4o image/gpt-image-1,它把语音、图像、视觉理解与生成重新收编回统一模型,意味着 OpenAI 不再满足于做“回答问题的聊天机器人”,而是在打造一个能搜索、会看图、会写代码、会分析文件、还能生成视觉资产的工作系统。
所以,今天再看 ChatGPT 的“前世今生”,最该得出的结论不是“它变强了”,而是“它变了”。OpenAI 的技术路线已经从单一语言模型竞争,转向多模态代理系统竞争。GPT-5 与 GPT-5.5 强调的是真实工作产出、长文档、研究分析与工具协作;ChatGPT Images 2.0 强调的是字体排版、多语支持、连续性和视觉工作流。这说明未来的大模型竞争,不一定是谁参数更大,而是谁更像真正能交付结果的数字同事。
其他参考文献与拓展阅读
1.Robo-writers: the rise and risks of language-generating AI
https://www.nature.com/articles/d41586-021-00530-0
2.GPT-3, Bloviator: OpenAI’s language generator has no idea what it’s talking about
https://www.technologyreview.com/2020/08/22/1007539/gpt3-openai-language-generator-artificial-intelligence-ai-opinion/
3.GitHub Copilot technical preview
https://github.blog/news-insights/product-news/github-copilot-your-ai-pair-programmer/
4.ChatGPT sets record for fastest-growing user base
https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/
5.GPT-4 Will Make ChatGPT Smarter but Won’t Fix Its Flaws
https://www.wired.com/story/gpt-4-openai-will-make-chatgpt-smarter-but-wont-fix-its-flaws/
6.DALL-E 2 and the bias debate
https://www.wired.com/story/dall-e-2-ai-text-image-bias-social-media/
7.ChatGPT image-generation wave and public response
https://www.theverge.com/openai/635118/chatgpt-sora-ai-image-generation-chatgpt
8.Nature commentary on GPT-3 and “understanding” debate
https://www.nature.com/articles/d41586-021-00530-0
9.新华社关于全球大模型热潮的综述
https://www.news.cn/tech/20240207/dd480da6982c495a9dd7c2977b13d8eb/c.html