 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库罗福莉又上分了!小米连甩4款模型,让AI超逼真配音

智东西(公众号:zhidxcom)
作者 | 程茜
编辑 | 心缘
智东西4月24日报道,今天,小米MiMo-V2.5家族语音模型系列正式发布:
MiMo-V2.5-TTS Series、MiMo-V2.5-ASR
,前者可免费体验,后者发布即开源。其中TTS Series包括语音、语音设计、语音克隆模型三款。
就在昨天,小米MiMo官宣MiMo-V2.5中
旗舰推理模型MiMo-V2.5、全模态Agent模型V2.5-Pro
开启公测、即将开源,再加上今天的4款语音模型,该系列共计6款模型。
MiMo-V2.5-TTS Series包含三款模型:
语音模型MiMo-V2.5-TTS、语音设计模型MiMo-V2.5-TTS-VoiceDesign、语音克隆模型MiMo-V2.5-TTS-VoiceClone
,MiMo-V2.5-ASR是这些语音模型的听觉基座,发布即开源。
MiMo-V2.5-TTS的模型集成多款音色、支持一句话复刻音色、定制全新音色等。MiMo-V2.5-ASR则支持中英双语、中文方言、强噪音、多说话人等复杂场景的语音识别。
小米此次发布的几大模型,均为
智能体场景
打造,其在官方文章里透露了几大模型可以搭配使用的智能体式创作链路:用
MiMo-V2.5-Pro
作为规划与编剧,拆任务、写剧本、排节奏、决定剪辑顺序;用
MiMo-V2.5-TTS Series
提供音色与素材,VoiceDesign生成音色、VoiceClone合成内容;
MiMo-V2.5
扮演裁判,听反馈的音频中角色一不一致、节奏对不对、有没有跟用户初衷偏离。
其放出了一条经这一套链路生成的音频:
不过音频中,有出现主人公边说边自己旁白的情况,且爷爷的声音特点并没有在整个说话环节都保持一致,中间会突然背离需求的“嗓门哑、拖长音”,语气突然变快等。
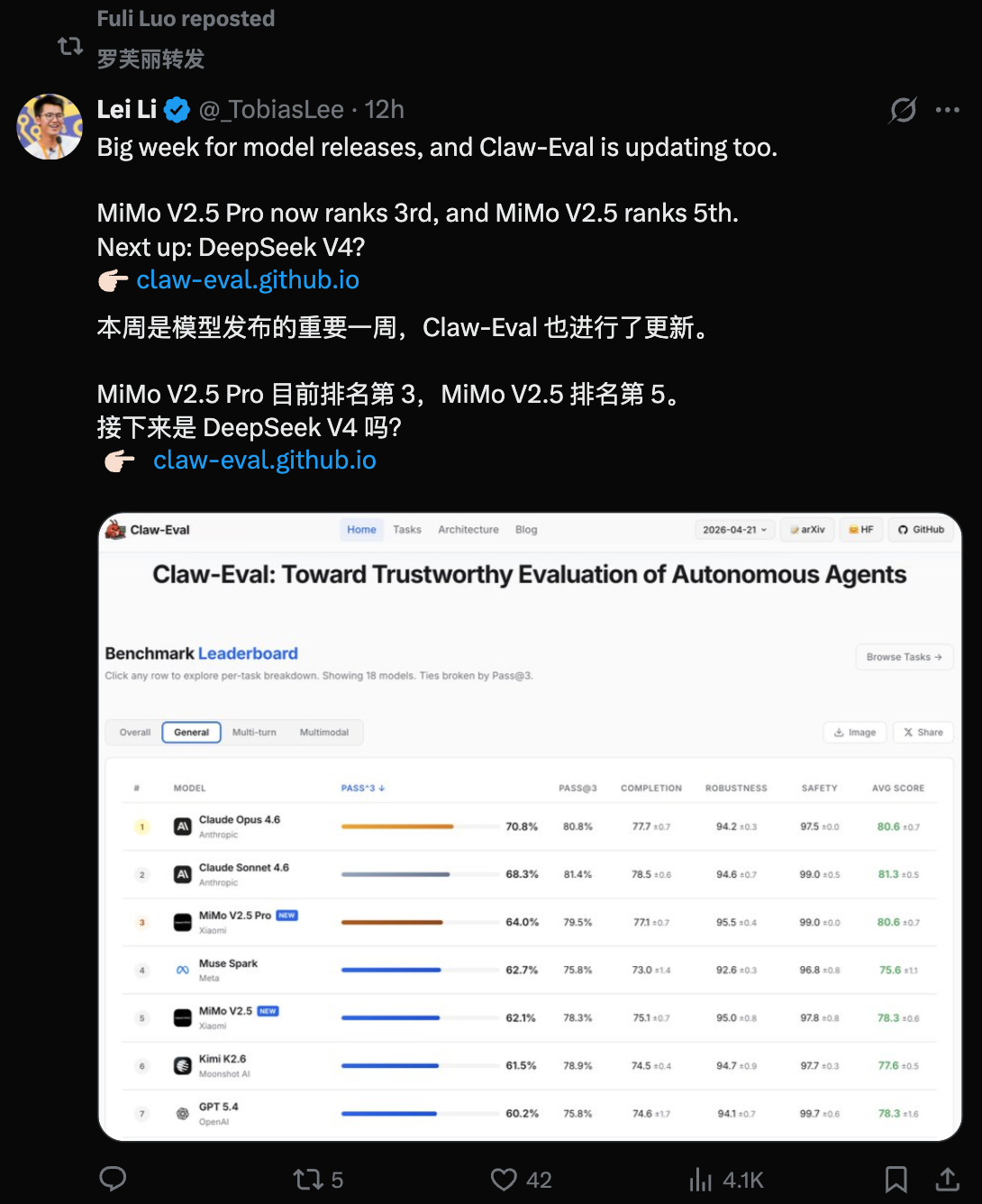
小米MiMo大模型负责人是原DeepSeek核心成员、被业内称为“天才少女”的罗福莉,今天凌晨,她在社交平台转发了大语言模型智能体端到端透明基准测试框架Claw-Eval、香港应用科技大学博士生Lei Li的帖子,其帖子提到,MiMo V2.5 Pro目前在Claw-Eval排名第3,MiMo V2.5排5,接下来是DeepSeek V4吗?
雷军昨日转发了小米-V2.5系列发布微博,并配文“继续进步!”
语音模型均可以在MiMo-Studio免费体验,面向开发者,MiMo-V2.5-TTS、MiMo-V2.5-TTS-VoiceDesign、MiMo-V2.5-TTS-VoiceClone均在Xiaomi MiMo API开放平台限时免费提供。
在开源方面,MiMo-V2.5-ASR目前已开源模型权重和代码,MiMo-V2.5-TTS相关模型的接入Skill全面开源。
MiMo-Studio 快速体验地址:https://aistudio.xiaomimimo.com/#/c
MiMo-V2.5-ASR开源地址:https://github.com/XiaomiMiMo/MiMo-V2.5-ASR
MiMo-V2.5-TTS模型的接入Skill开源地址:https://github.com/XiaomiMiMo/MiMo-Skills
一、三款语音模型+一款听觉模型,小米为通用语音智能放大招
MiMo-V2.5-TTS Series包含三款模型,MiMo-V2.5-TTS、MiMo-V2.5-TTS-VoiceDesign、MiMo-V2.5-TTS-VoiceClone。
三款模型的相同之处在于,其拥有统一的风格指令遵循、音频标签控制与文本理解能力。
不同之处在于针对的创作需求:
MiMo-V2.5-TTS内置多款音色,支持语速、情绪、语气等精细化控制,开箱即用,能满足多场景表达;MiMo-V2.5-TTS-VoiceDesign支持一句话快速定义并生成全新音色;MiMo-V2.5-TTS-VoiceClone能通过少量样本高保真复刻目标音色,同时保持稳定的风格指令遵循与音频标签控制能力。
MiMo-V2.5-ASR发布即开源。根据小米官方信息,该模型在中英双语、中文方言、Code-Switch、强噪音、多说话人等复杂真实场景下的语音识别性能达到业界领先水平。
小米官方总结了这一模型的八大特点:
中文方言:支持吴语、粤语、闽南语、四川话等方言;
英文复杂场景:在AMI等复杂英文场景Open ASR Leaderboard上达到领先水平;
Code-Switch:中英Code-Switch语音转录自由流畅,无需预设语种标签;
歌曲识别:中英文歌曲歌词识别,在伴奏与人声混合场景下保持高精度;
强噪音场景:在高噪音、远场拾音等复杂声学环境中保持鲁棒识别;
多说话人:支持多人交叉对话场景的准确转录,如会议场景;
强知识关联:古诗词、专业术语、人名、地名等知识密集型内容的精准识别;
原生标点:结合语音韵律与语义原生输出标点,转写结果即拿即用,无需后处理。
其提到,对于智能体应用、内容创作工具、会议系统、语音交互产品而言,MiMo-V2.5-ASR已经在复杂真实世界语音中经过验证。
二、导演剧本、音频标签都能看懂,没需求只看音频文本也能传达情绪
智东西实际体验了MiMo-V2.5-TTS系列几款模型的效果。
首先是MiMo-V2.5-TTS,根据官方信息,该模型从情绪、语气、语速、发声方式到语言风格等多个维度,都能理解并遵循,其还可以支持导演剧本级的结构化输入:把人物、场景、详细指导分层描述,各层按自己的节奏独立更新、自由组合。
智东西选择了知性女声,上传的指令是
“声音轻柔舒缓,语速很慢,带着安抚人心的温度,说话时像在给客人递一杯热咖啡,语气温柔又有耐心,像开了几十年书店的老板娘。”
生成的音频中,老板娘说话整体语速偏慢、换气舒缓,没有急促感,字句之间留白自然,整体符合语言生成的需求。
其次,除了自然语言指令,该模型还支持行内音频标签,用于在文本特定位置精准控制情绪、状态或风格。标签支持中英双语和开放文本描述,允许在同一段文本中灵活混用。
智东西上传了一段茶馆说书人的音频标签文本,提示词为
(洪亮,开场)话说那江湖之上,有位少年侠客,仗剑走天涯。
(压低声音,神秘)可谁也不知道,他腰间那把剑,藏着一段血海深仇。
(拔高声调,激昂)今日,他终于要回来了!
整体来看,音频中的三句话都符合前面的音频标签特征,但每一句之间的衔接仍有优化的空间,会出现声音突然从高变低,又突然拔高的情况。
最后是文本理解能力,即使用户没有上传具体需求,模型也能根据文本判断其中的韵律与情感,在音频中表现出标点的停顿、句式的起伏等。
官方提示词为
“Ten… nine… eight… seven… six… five… four… three… TWO… ONE… ZERO! LAUNCH! LAUNCH! WE HAVE LIFTOFF! GO GO GO! SHE’S CLIMBING! ALTITUDE 1,000… 5,000… 10,000 FEET AND CLIMBING! BEAUTIFUL! AB-SO-LUTE-LY BEAUTIFUL!”
如上面这段提示词,模型感知到文本的节奏逐渐加快,从倒计时阶段的专业、冷静到最后情绪爬升与赞叹时,还原出了人物的情绪变化。
三、无需参考音频生成全新音色,还支持一句话复刻
另外两个是音色设计和克隆模型。
音色设计模型MiMo-V2.5-TTS-VoiceDesign无需任何参考音频,支持用户通过自然语言描述从零生成一款全新音色。其可以自由使用年龄、性别、口音、音质、发声方式、性格气质等维度进行描述,模型即可合成对应的角色音色。
智东西上传的提示词是
“一位20多岁的女性,说南方软语,声线慵懒松弛,带一点点刚睡醒的鼻音,她是深夜电台主播念稿时尾音轻放,读听众留言时会放柔语气。”
生成的音频确实声线慵懒,听起来是一位年轻女气,但说话时仍然是普通话,没有南方软语的特征。其声音为了刻意保持慵懒松弛,会在尾音时可以压低声音,会减弱松弛感。
此外,小米官方给出了一段示例,其提示次是“一位年迈的老先生,说带北方口音的普通话,语速缓慢而沉稳,嗓音略带沙哑和沧桑感,仿佛一位饱经风霜的老爷爷在讲故事,充满岁月的智慧”。
音色克隆模型MiMo-V2.5-TTS-VoiceClone,用户可以让其复刻一位真人播客、配音演员、品牌代言人,或者用户本人的声音。
其只需提供一段数秒的参考音频,无需额外的训练、标注或微调过程,复刻后的声音可以保留原始说话人的音色身份,以及气息、节奏、习惯性停顿等个人特征。
小米放出的官方案例,用严肃、字正腔圆的新闻播报声线,复刻了《康熙微服私访记》中的一段经典台词,极具反差感。
其新音色的提示词为
“用尖锐刻薄的嗓音,带着狐假虎威的得意感说话,在提到大人物的身份时故意放慢语速并加重语气,营造压迫感。”
文本为“你以为我是谁,也敢在这儿跟我耍横?我告诉你,站在我身后的那个人,说出来吓死你——是当今的——万岁爷!你今天要是不给我个说法,我让你这铺子明天就开不了门。”
音频中,音色与新闻播报的声线保持一致,在说“万岁爷”、“开不了门”等重点内容时,还可以拉长声线、加重语气。
结语:语音AI四大研发路线,打造真正通用语音智能
小米公布了其下一步研发方向:
1、更大规模的语音预训练与强化学习后训练:MiMo-V2.5-TTS-Series 证明了大规模预训练与后训练的巨大收益,扩大这两者的规模:通过更多的数据、更大的模型、更强的算力,让更强大的语音智能从规模中涌现;更加精细的奖励建模与强化学习算法,推动模型迈向更高阶的语音表达智能。
2、通用音频生成:语音只是第一步,他们正在将能力扩展到更广义的音频生成:环境音效、动作声、氛围铺底,乃至短乐句与旋律片段,逐步建模出一个完整的声音世界。他们认为真正的通用音频模型,不是把语音、音效、音乐简单拼在一起,而是让它们在同一套空间里彼此理解、协同创作。
3、上下文理解能力:上下文理解意味着模型不再只是一个“逐句执行的工具”,而是一个懂得故事语境的表达者。这是其迈向真正通用语音智能的关键一步。
4、通用语音理解能力:他们的目标是,让方言、噪音、中英混杂这些“真实世界的常态”不再成为语音识别的短板。未来,他们将持续扩展更多方言覆盖、并深化上下文感知能力。





