 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库模速生态 | 阶跃语音模型位列 Artificial Analysis 评测榜中国第一、全球前三

刚刚,全球知名 TTS 评测榜单 Artificial Analysis Speech Arena Leaderboard 更新,模速生态企业阶跃星辰新一代语音生成模型 StepAudio 2.5 TTS 成功跻身全球前三,成为该榜单上排名最高的中国大模型。
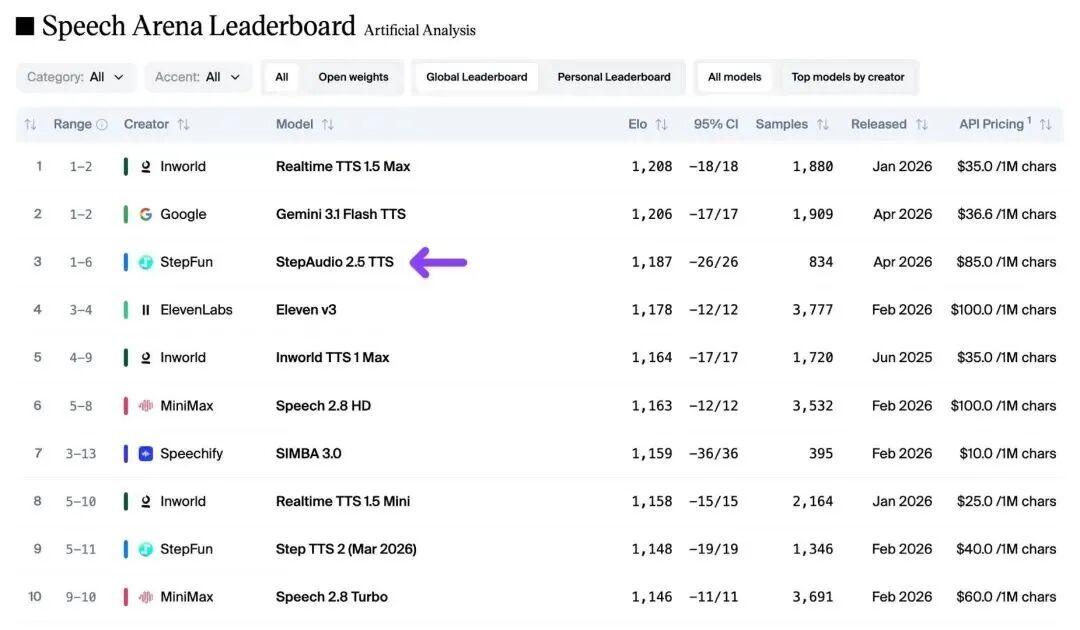
Artificial Analysis Speech Arena Leaderboard 是业内最具公信力的 TTS 模型评测榜单之一。榜单采用盲测 Elo 评分机制——用户在不知道模型身份的情况下,聆听同一段文本生成的两段语音,选出听感更加自然拟人的那一段,测试场景覆盖客户服务、知识分享、数字助手和娱乐四大真实使用场景。能在这一机制下胜出,意味着模型生成的语音在真实用户耳中更自然、更像真人。
StepAudio 2.5 TTS 是阶跃最新一代语音生成大模型,它基于 3 大核心能力让语音生成更精准可控、更自然、更灵活也更有表现力。
全局语境控制:支持自定义整段语音的情绪基调、角色状态与场景氛围,使表达更统一、更连贯。
文中语境控制:不仅能控制一句话怎么说,还能进一步调节语气、节奏、停顿、轻重变化、角色感和场景感,让声音表达更有分寸。
零样本复刻与全音色控制:在保留目标音色特征的同时,支持对情感、风格和表达方式进行灵活调节,让同一种声音说出更多不同感觉。
此外, StepAudio 2.5 系列 共包含 3 款模型,覆盖 AI 语音全链路。目前 3 款模型均已全量上线:
StepAudio 2.5 TTS:让语音生成更自然、更有表现力
StepAudio 2.5 ASR:让语音识别又快又准,推理峰值 500 token/s
StepAudio 2.5 Realtime:让 AI 语音实时对话更有“活人感”
Agentic 时代,语音是人机交互的核心入口。语音不仅是传递信息的工具,更是承载情绪、个性与意图的灵魂载体。为此,阶跃星辰持续深耕语音技术,并取得多项关键突破:
开源原生语音推理模型 Step Audio R1.1 在权威评测 Artificial Analysis Speech Reasoning 中登顶全球第一,并持续霸榜 ing;
开源全球首个迭代式情绪风格语音编辑模型 Step Audio EditX,该模型在 Artificial Analysis Speech Arena Leaderboard 上以 zero-shot TTS 方式,3s 复刻的音色效果可打败许多闭源 TTS 模型主音色;
推出国内首个千亿参数端到端语音大模型 Step-1o;
在吉利银河 M9 上实现端到端语音大模型首次上车;
为整车智能体“超级 Eva”提供语音交互能力,首发搭载极氪 8X 并已量产上市。
未来,阶跃星辰将持续探索语音技术边界,让 AI 的每一次有声表达都更灵动自然。
来源:阶跃星辰






