 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库飞书接入Claw类产品哪家强?SC-LarkClaw首测:MiMoClaw夺冠

# 测评背景
飞书凭借开放的机器人生态和深度的办公协同能力,成为 Claw 产品落地企业场景的核心阵地。当多款 Claw 产品共存于同一个飞书工作台,对话质量、任务执行力和平台功能调用的高下立判。SC-LarkClaw 聚焦 Claw 产品在飞书环境中的实际表现,围绕内容创作、数据处理、研究分析、记忆能力四大维度,通过自动化脚本与大模型相结合的评估方式,对各产品进行独立量化测评,为用户选型和产品迭代提供客观依据。
SC-LarkClaw测评方案文章详见:Claw产品接入飞书测评方案发布!SuperCLUE-LarkClaw
SC-WeClaw测评基准文章详见:微信接入Claw类产品哪家强?SC-WeClaw首测:MiMoClaw夺冠
SuperCLUE-XClaw国产龙虾Claw产品测评基准文章详见:国产龙虾Claw产品首测:10款产品真实测评
# SC-LarkClaw榜单概览
1. 总分对比
SC-LarkClaw测评摘要
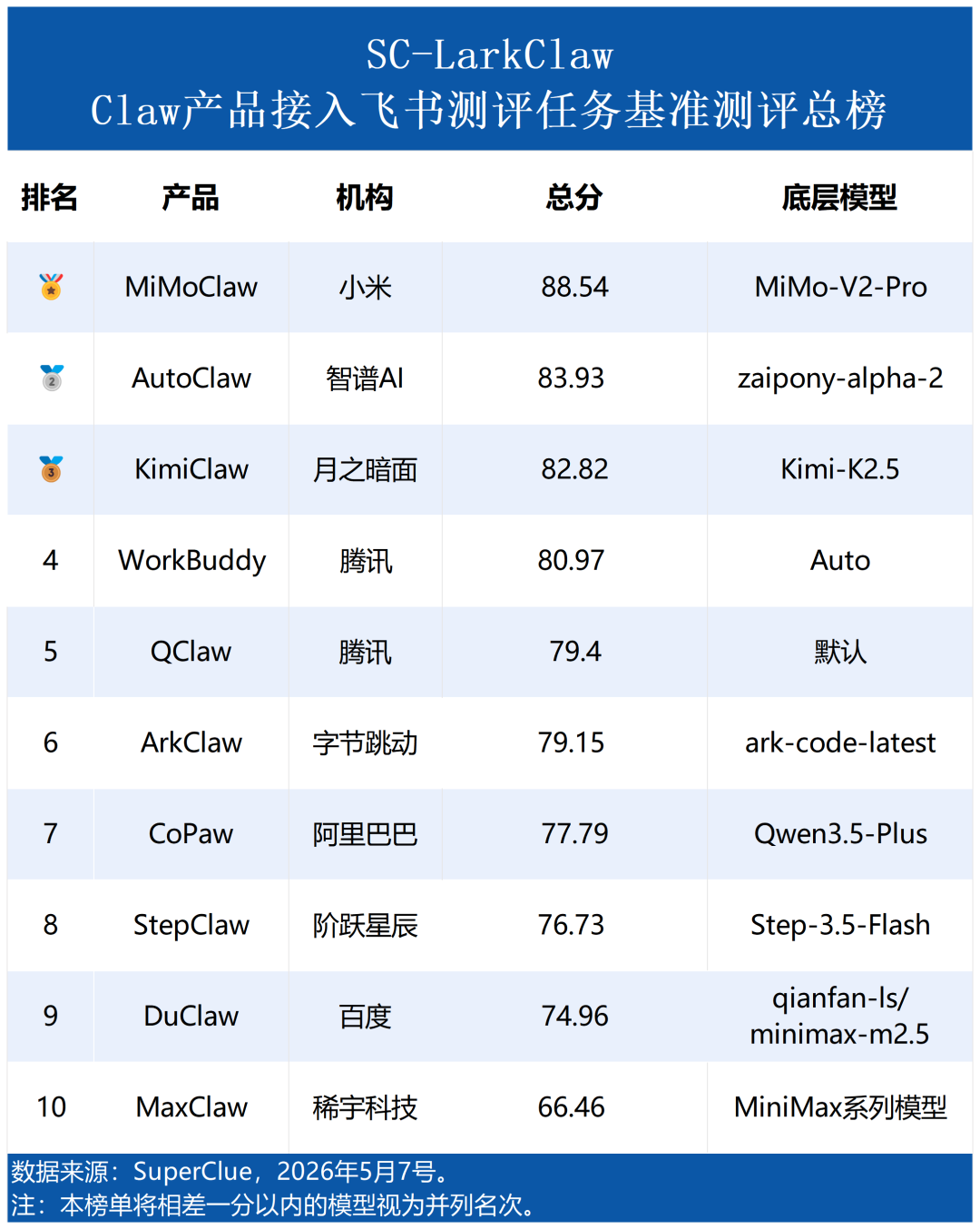
摘要1:头部梯队拉开分差,MiMoClaw 以88分领跑
MiMoClaw 以 88.54 分领跑,与第二名 AutoClaw(83.93)拉开近 5 分差距。KimiClaw(82.82)紧随其后,三甲构成第一梯队。WorkBuddy(80.97)、QClaw(79.40)、ArkClaw(79.15)差距不足 2 分,竞争最为胶着。CoPaw(77.79)、StepClaw(76.73)逐级下滑,DuClaw(74.96)与 MaxClaw(66.46)尾部断层显著,MaxClaw 同榜首拉开近 22 分。
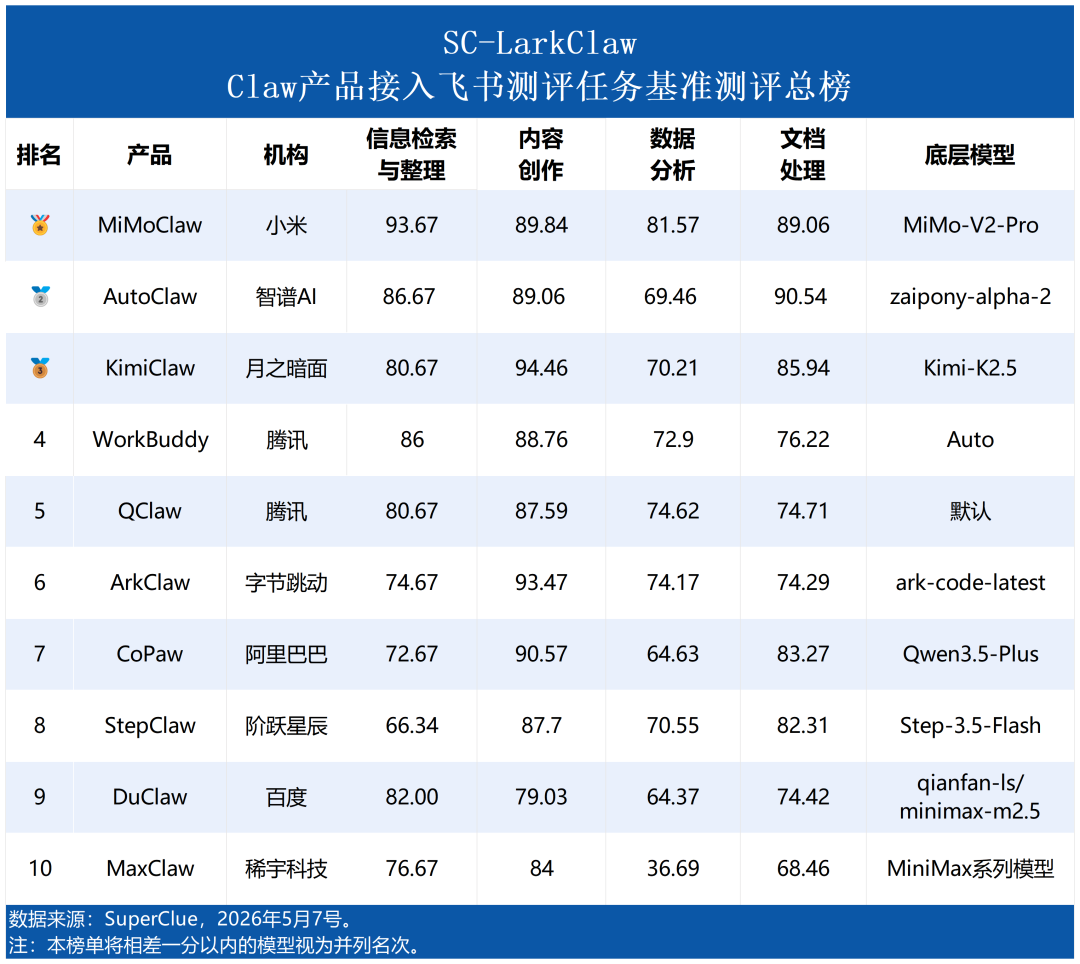
摘要2:内容创作均分88分领跑各维度,数据分析成共性短板
内容创作以 88 分均值领跑各维度,KimiClaw(94.46)拿下全场最高单项分,头部产品普遍突破 89 分,通用文本生成能力已趋成熟。文档处理均分 80 分,AutoClaw(90.54)、MiMoClaw(89.06)表现最突出,构成专业任务支撑底盘。信息检索与整理均分 80 分,MiMoClaw(93.67)大幅领先。数据分析均分仅 68 分,为所有维度最低,除 MiMoClaw(81.57)外,其余产品普遍在 64—74 分区间,是当前参评产品的共性薄弱环节。
摘要3:专长各异、全面者胜——四大维度揭示不同产品的能力图谱
MiMoClaw 凭借信息检索(93.67)的突出优势叠加其余三维全面高水准占据榜首,属于"全面强势型"。AutoClaw 以文档处理(90.54)为最强长板,综合实力紧咬榜首。KimiClaw(94.46)与 ArkClaw(93.47)内容创作拉至 93+ 水准,属于"专长驱动型"。WorkBuddy、QClaw、CoPaw 四维均衡无短板,属于"全面发展型"。综合排名更多反映能力全面性而非绝对实力差距,每家产品都有值得肯定的强项领域。
# 基准介绍
(一)场景设计
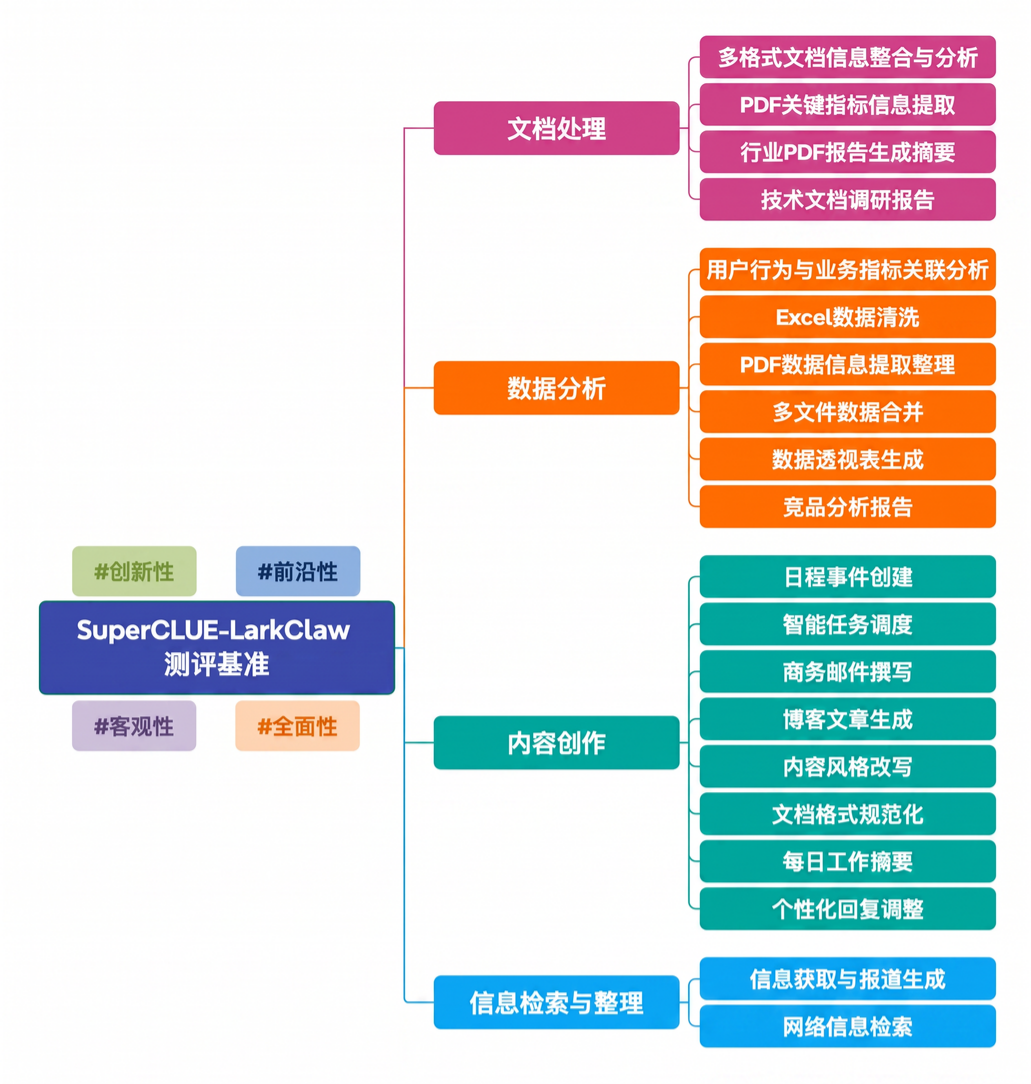
SC-LarkClaw 测评基准的任务设计严格遵循飞书生态——所有原始文档均以飞书在线文档形式呈现,覆盖从基础办公到高阶分析的完整链路。测评维度聚焦于文档处理、数据分析、内容创作及信息检索与整理四大核心能力域,并下设二十余项细分任务指标,全面量化了 Agent 在统一交互场景下的真实表现。四大场景设计为:
文档处理: 重点考察模型对多格式、长文本专业资料的深度理解与关键信息提取能力,典型任务包括合同条款提取、简历对比排序、会议纪要待办生成及多模态文档解析,结果需以飞书云文档形式结构化写回,检验端到端的文档读写质量与输出规范度。
数据分析: 以飞书表格或多维表格为输入载体,涵盖数据清洗、统计计算、趋势分析、异常检测及可视化图表生成等任务,重点评估模型的数据理解、统计推理及商业洞察力,所有结论需写回飞书在线文档,考验端到端的数据分析交付能力。
内容创作: 聚焦办公效率与文本生成质量,包含商务邮件撰写、PPT大纲生成、营销文案撰写、风格化改写及个性化回复调整等高频任务,考察创意生成、格式控制及飞书文档输出专业度,反映产品在内容生产场景下的实用价值。
信息检索与整理: 独立评测模型联网获取实时信息、筛选有效信源、多源整合并以飞书云文档或多维表格结构化呈现的综合响应水平,重点评估信息检索策略、事实判断准确性及文档结构化质量。
详细场景维度和任务如下:
(二)测评流程及评估方法
SC-LarkClaw测评采用每个云产品连接飞书机器人获取答案和自动化评估的方式,确保评估结果真实反映各产品连接飞书机器人后的实际能力。
1. 自主设计测评任务
我们根据4大维度(文档处理、数据分析、内容创作信息检索与整理)的任务场景,自主设计详细的测评题目和明确的输出要求。
每道题目都附带:
完整的任务描述
明确的输入文件
具体的输出格式要求
详细的评分标准
2. 评分方法
本次SC-LarkClaw测评采用三层评分架构,包括自动化脚本评估、大模型评估以及两者的混合评估。以下对各层机制进行详细说明:
(1)自动化脚本评估
该机制适用于客观题的评分。当任务结果能够通过明确且无歧义的标准进行验证时,采用预设的Python脚本自动检查模型输出。
评分标准:采用0/1二分制。
- 1分:脚本验证全部通过,所有检查点均符合预期,任务判定为成功。
- 0分:脚本验证失败,任一检查点未通过(如文件缺失、日期错误、格式不符等),任务判定为失败。
(2)大模型评估
该机制适用于主观题的评分。对于涉及内容质量、逻辑深度、创造性等难以量化的任务,引入能力强大的大语言模型(Gemini-3.1-Pro-Preview)作为评审员。裁判模型将依据以下材料进行打分:
- 原始任务指令(如“撰写一篇关于可再生能源未来发展的博客文章,要求论点清晰、论据充分”);
- 待评测模型生成的结果;
- 详细的评分细则(如“论点清晰度(1-5分)”“论据充分性与相关性(1-5分)”“文章结构逻辑性(1-5分)”“见解独特性(1-5分)”等)。
评分标准:采用1-5分制。裁判模型严格按照细则对多个维度分别打分,最终得分为各维度分数的平均值。此机制能够更精细地反映模型在复杂任务上的表现差异。
(3)混合评估
该机制适用于复杂综合题的评分,此类任务通常同时包含可客观验证的步骤和需要主观评判的内容。混合评估综合运用前两种机制,对任务的客观部分和主观部分分别评分,并按预设权重计算最终得分。 工作机制:
第一步:自动化检查客观部分。例如,任务要求“搜索过去一周关于 AI 芯片的5条重要新闻,并整理成简报”,脚本首先自动验证:是否输出5条新闻?每条新闻的发布时间是否均在近一周内?客观部分根据验证结果给予0或1分。
第二步:大模型评审主观部分。无论客观检查是否通过,均进行主观评审。由 AI 裁判评估新闻的重要性、摘要的准确性与清晰度、简报排版与可读性等维度,并给出 1-5 分的评分。 评分标准:最终得分为客观部分得分与主观部分得分的加权组合。权重根据任务性质预设,并在评分规则中明确说明。若客观检查失败(得0分),则即使主观得分较高,最终加权得分也会受到相应影响。此种机制体现了在实际应用中,“做对”与“做好”均对整体表现有贡献,但两者的重要性可能因任务而异。
总结而言,通过上述三种分数设定,构建了一个涵盖硬性指标(非对即错)、软性指标(好坏优劣)以及综合指标(客观与主观相结合)的全方位评价体系。由此得出的成功率、响应速度与成本等指标,能够更真实地反映各个Claw产品在实际工作场景中的执行能力。
3. 最终统分
对每个产品每个任务,通过对应评分机制(自动化脚本评估/大模型评估/混合评估)进行1次独立测评,得到单次得分即为该任务最终得分(结果保留2位小数);
若某产品在某一任务中执行失败,该任务最终得分为0分。
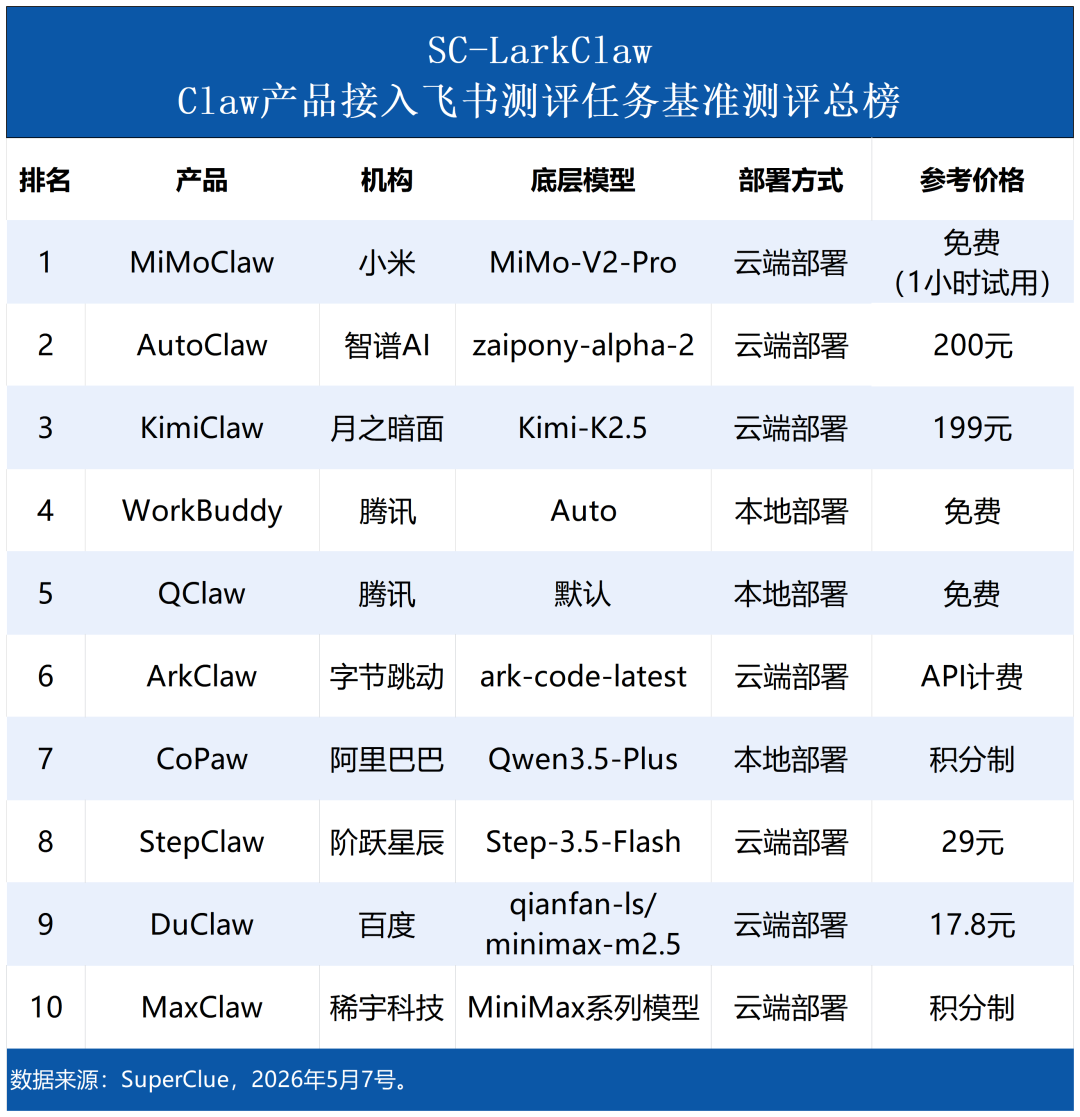
# 参评产品
本次SC-LarkClaw云Claw产品接入飞书测评共有10款主流产品参测,具体测评产品详情如下图所示
# 测评分析及结论
一、总分排名格局:头部拉开近5分差距,中段集团密集缠斗,尾部断层明显
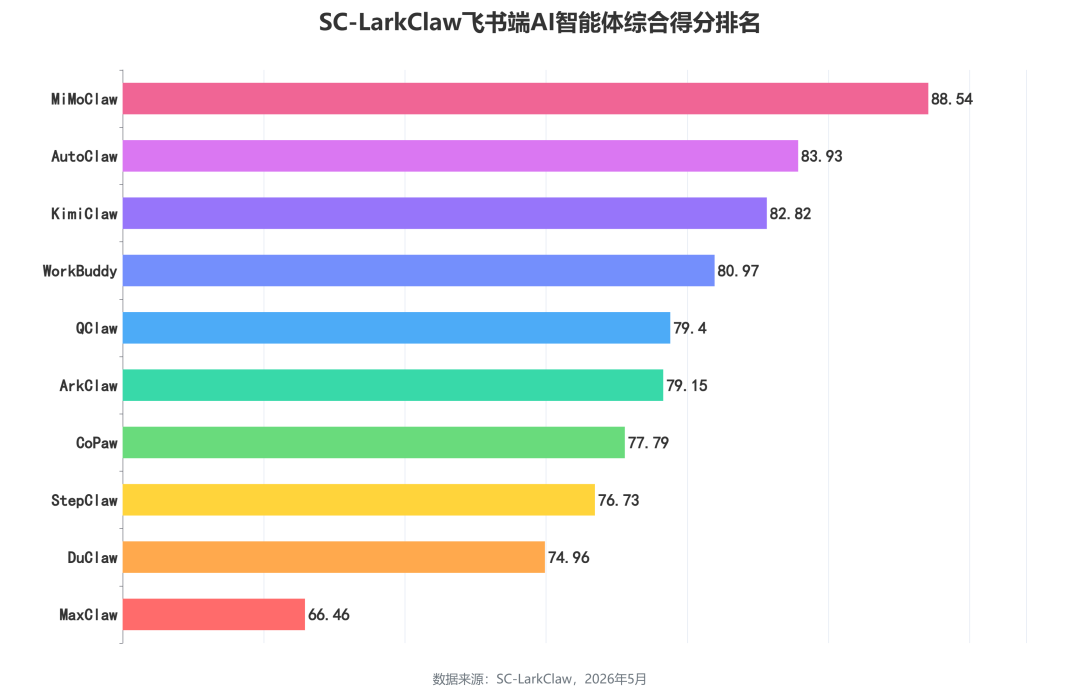
从 SC-LarkClaw 综合得分排名看,10 款参评产品的总分呈现出三档分明的梯队结构。第一梯队(≥80 分)中,MiMoClaw 以 88.54 分领跑,与第二名 AutoClaw(83.93)拉开近 5 分差距,形成独立领先的身位优势。KimiClaw(82.82)紧随其后,三甲合计构成第一梯队,内部最大分差约 5.7 分。第二梯队(76—81 分)由 WorkBuddy(80.97)、QClaw(79.40)、ArkClaw(79.15)、CoPaw(77.79)与 StepClaw(76.73)组成,WorkBuddy、QClaw、ArkClaw 三者差距不足 2 分,竞争最为胶着。前两档之间衔接平滑,能力过渡自然。而 DuClaw(74.96)与 MaxClaw(66.46)构成的末位梯队,与第二档之间存在明显落差,MaxClaw 更与榜首拉开近 22 分,形成清晰的能力鸿沟。整体格局可概括为:头部一骑绝尘、中段密集缠斗、尾部断崖式滑落的非对称分布。
二、能力分布不均,文本生成已是强项,数据分析普遍疲软
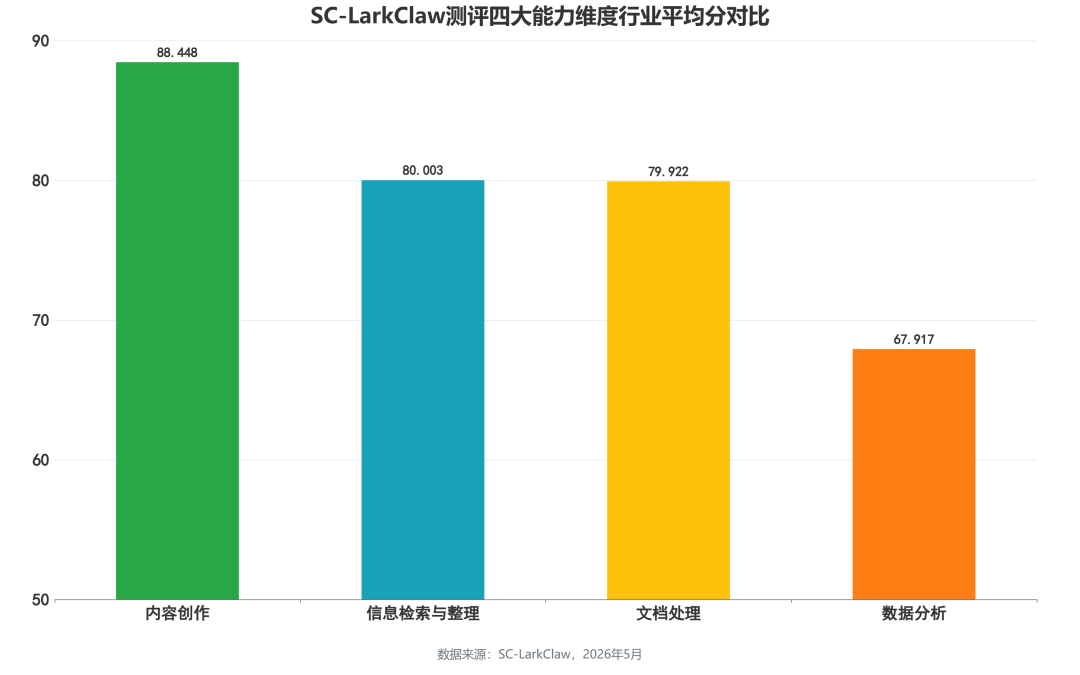
从 SC-LarkClaw 四大维度行业均分来看,参评产品的能力建设呈现"一项突出、两项中等、一项拉垮"的分化态势。内容创作以 88.45 分遥遥领先,KimiClaw(94.46)、ArkClaw(93.47)、CoPaw(90.57)、MiMoClaw(89.84)、AutoClaw(89.06)均突破 89 分,通用文本生成场景已趋于成熟。信息检索与整理均分 80.00 分,文档处理均分 79.92 分,两项处于中等区间,构成专业任务的基本支撑面,MiMoClaw 信息检索(93.67)大幅领先,AutoClaw 文档处理(90.54)表现最为突出。数据分析均分仅 67.92 分,为所有维度最低,除 MiMoClaw(81.57)和 QClaw(74.62)尚可外,其余产品普遍在 64—72 分区间挣扎,MaxClaw 更低至 36.69 分,是当前参评产品的共性薄弱环节。
三、能力图谱分析:均衡型与专长型各有优势,全面性决定综合排名
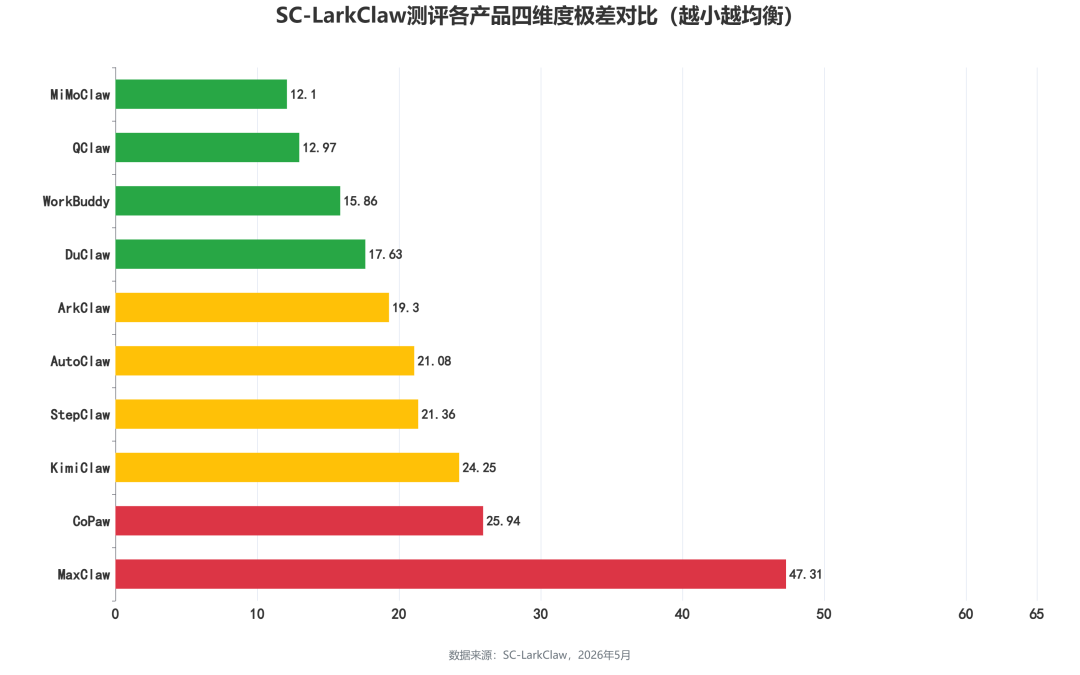
本次 SC-LarkClaw 测评覆盖四大维度,各产品的得分分布呈现出不同的能力图谱。MiMoClaw 凭借信息检索与整理(93.67)的突出优势叠加文档处理(89.06)、内容创作(89.84)的全面高水准以 88.54 分稳居榜首,属于"全面强势型"。AutoClaw 以文档处理(90.54)为最强长板,内容创作(89.06)、信息检索(86.67)同样稳健,综合实力紧咬榜首。KimiClaw 内容创作(94.46)与 ArkClaw(93.47)将该项拉至 93+ 水准,属于"专长驱动型"。WorkBuddy(80.97)四维均衡无短板,QClaw(79.40)、CoPaw(77.79)同样发挥稳定,属于"全面发展型"。StepClaw 文档处理(82.31)表现突出但信息检索(66.34)拖累总分,DuClaw 信息检索(82.00)尚可但数据分析(64.37)形成短板。总体来看,综合排名靠前的产品往往兼具多项优势,而排名靠后的产品也并非全面落后,更多是在全面性上存在差异。以上结论仅反映 SC-LarkClaw 标准化场景下的测评表现。
# 示例展示
对比示例
【任务类型】:文档处理
【题目】:
你现在是企业的智能办公助手,需要处理以下三份项目相关文档:
会议记录:《智能办公系统项目会议记录》(D6_meeting_notes),包含三次项目会议的讨论要点、决议和进度
合同文件:《软件开发服务合同》(D6_contract.pdf),甲乙双方签署的正式软件开发服务合同,包含所有商务和法律条款
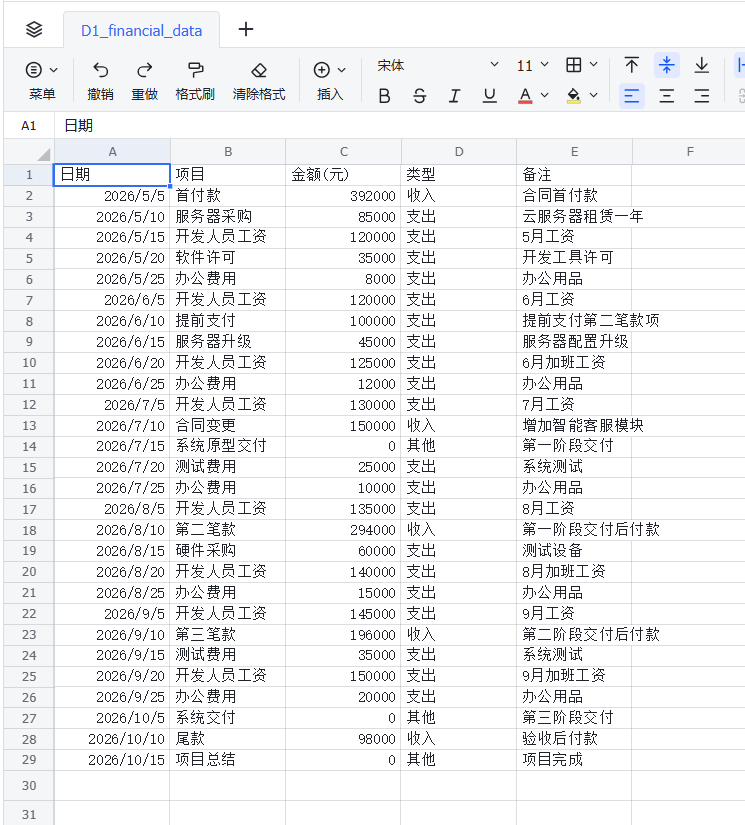
财务数据:《项目财务流水表》(D6_financial_data),包含项目从2026年5月到10月的所有收支明细
请基于以上三份文件的内容回答以下问题,回答要求:
所有答案必须有明确的文件依据,不得编造信息
需要计算的问题请给出计算过程
跨文档关联的问题请说明信息来源对应的文件
涉及法律或合同条款的问题请引用具体条款编号
问题:结合会议记录、合同文件、财务数据三份材料,请分析:
1.甲方提出的新增「智能客服模块」需求是否符合合同约定的变更流程?
2.乙方收取15万元变更费用是否合法合规?请说明具体依据。
3.该需求变更对项目最终整体利润率的影响是多少(需给出计算过程,保留两位小数)
以上问题答案输出到D6_answer云文档并保存到
https://tl4jiu5pso.feishu.cn/drive/folder/SphLfFZxGlc3ItdaAn6cZ5ALngd这个文件夹,每个问题的完整原文作为Word一级标题,每个问题的答案写在对应标题下方。
D6_meeting_notes、D6_contract.pdf、D6_financial_data 其中会议记录和合同文件内容过长只展示部分内容:
D6_meeting_notes

D6_contract

D6_financial_data
【评分点介绍】:
本题由自动化脚本和大模型二者混合进行评价,自动化脚本评价与大模型评价的权重为1:9,其中自动化脚本设计一个得分点,得分设计5个维度,
格式完全符合得1分:
正好有 3 个一级标题 Heading 1 这 3 个一级标题按顺序与题目原文完全一致 每个一级标题下面都有对应答案内容
至少有 3 个一级标题 其中至少 2 个一级标题和标准题目完全匹配 3 个标题下面都有内容
正文里能识别出 3 个问题的关键词 并且文档里至少有一些标题结构 但一级标题没有按标准题目原文来写
至少命中 1 组问题关键词,或者 至少有标题 但离标准格式差得比较远
没识别到题目关键词 也几乎没有标题结构 脚本无法判断是按要求组织的答案
{"format_compliance_score": 格式判断得分"script_score_normalized": 汇总得分}
## 核心评分原则1. **硬性校验优先**:关键合同条款引用错误、核心财务计算错误、核心事实判断错误直接按对应档位扣分,不考虑其他因素酌情加分。2. **五档评分规则**:每个维度仅使用 `1.0 / 0.75 / 0.5 / 0.25 / 0` 五个档位评分,加权计算总分。3. **不重复扣分**:同一错误仅在对应维度扣一次,不跨维度重复处罚。4. **明确校验依据**:所有评分均以三份原始文件和要求的标准答案为唯一依据,不得主观臆断。---### Criterion 1: 任务完成度与要求覆盖度 (Weight: 20%)评估是否完整回答了三个问题,无遗漏、无跑题。- **Score 1.0**: 完整回答全部3个问题,每个问题都有明确结论,无内容遗漏。- **Score 0.75**: 基本覆盖3个问题,但其中1个问题的回答内容明显单薄、关键信息缺失。- **Score 0.5**: 仅回答了2个问题,遗漏1个问题。- **Score 0.25**: 仅回答了1个问题,遗漏2个及以上问题。- **Score 0.0**: 完全未回答问题,或内容与题目要求完全无关。---### Criterion 2: 关键条款与事实准确性 (Weight: 30%)核心考核合同条款引用、事实判断的正确性,是专业能力核心评价项。**硬性校验点**:- 第一问必须引用合同第6条的6.1/6.2/6.3款,且关联第三次会议记录内容,结论为「符合变更流程」- 第二问必须引用合同第6.4条,明确对比「15万变更费 > 合同总额5%(4.9万元)」,关联第三次会议内容,结论为「收费合法合规」- **Score 1.0**: 完全满足所有校验点:条款引用完整准确、关联第三次会议内容、判断结论正确、15万与4.9万的对比逻辑清晰。- **Score 0.75**: 核心判断正确,但缺少1个次要校验点,例如未明确写4.9万的计算过程,或漏写1个条款编号。- **Score 0.5**: 存在1个核心错误,例如未关联第三次会议内容,或结论正确但未引用对应条款。- **Score 0.25**: 存在2个及以上核心错误,例如条款引用混乱、结论判断错误(如认为收费不合规)。- **Score 0.0**: 完全未引用合同条款,事实判断完全错误,或编造不存在的条款内容。---### Criterion 3: 财务计算准确性 (Weight: 25%)考核第三问的计算过程与结果准确性,标准答案为:> 变动前利润率:`-54.59%`;变动后利润率:`-34.07%`;利润率提升:`20.52个百分点`(均保留两位小数)- **Score 1.0**: 计算过程完整清晰,三个数值完全准确(误差≤0.1个百分点),且保留两位小数。- **Score 0.75**: 计算过程完整,仅最终提升百分点存在微小误差(误差≤0.5个百分点),或未保留两位小数但数值正确。- **Score 0.5**: 有计算过程,但3个数值中错1个,或过程有瑕疵但结果接近正确值。- **Score 0.25**: 仅有最终结果无计算过程,或3个数值中错2个及以上。- **Score 0.0**: 完全无计算过程,或结果与标准答案偏差超过10个百分点。---### Criterion 4: 依据充分性与规范度 (Weight: 15%)考核回答是否符合答题规范:所有结论有明确文件依据,跨文档关联标注来源,条款引用规范。- **Score 1.0**: 所有结论都明确标注依据来源,合同条款编号正确,跨文档内容说明对应的文件(如「根据第三次会议记录」「根据合同第6.4条」「根据财务流水表」)。- **Score 0.75**: 大部分结论有依据,仅个别结论未标注来源,但整体规范。- **Score 0.5**: 仅部分结论有依据,未明确标注信息来源。- **Score 0.25**: 基本无依据标注,仅输出结论,未说明信息来源。- **Score 0.0**: 存在编造信息、无中生有的内容,或完全没有任何依据说明。

【对KimiClaw的评价结果】:
脚本评价: {"format_compliance_score": 0.5,"script_score_normalized": 0.5,}大模型评价: { "task_completion_score": 1.0, "clause_fact_accuracy_score": 1.0, "financial_accuracy_score": 0.0, "evidence_norm_score": 1.0, "reasoning": "完整回答三问,条款引用准确且事实判断正确,依据标注规范。但财务计算中错误将提前支付的10万计入额外收入,导致三个利润率数值全错且偏差超10%。", "raw_response": "{\"task_completion_score\": 1.0, \"clause_fact_accuracy_score\": 1.0, \"financial_accuracy_score\": 0.0, \"evidence_norm_score\": 1.0, \"reasoning\": \"完整回答三问,条款引用准确且事实判断正确,依据标注规范。但财务计算中错误将提前支付的10万计入额外收入,导致三个利润率数值全错且偏差超10%。\"}", "llm_score_normalized": 0.7222222222222222}加权汇总:{"total_score": 0.1*0.5+0.9*0.722=0.700}
【AutoClaw的答案】:

【对AutoClaw的评价结果】:
脚本评价: {"format_compliance_score": 0.25,"script_score_normalized": 0.25,}大模型评价: { "task_completion_score": 1.0, "clause_fact_accuracy_score": 1.0, "financial_accuracy_score": 1.0, "evidence_norm_score": 1.0, "reasoning": "完整回答了三个问题,合同条款引用准确,事实判断正确,财务计算过程清晰且结果完全无误,依据标注规范明确。", "raw_response": "{\"task_completion_score\": 1.0, \"clause_fact_accuracy_score\": 1.0, \"financial_accuracy_score\": 1.0, \"evidence_norm_score\": 1.0, \"reasoning\": \"完整回答了三个问题,合同条款引用准确,事实判断正确,财务计算过程清晰且结果完全无误,依据标注规范明确。\"}", "llm_score_normalized": 1.0}加权汇总:{"total_score": 0.1*0.25+0.9*1.0=0.925}
附各龙虾产品链接:
1.ArkClaw:
https://www.volcengine.com/docs/82379/2229107?lang=zh
2.KimiClaw:
https://www.kimi.com/bot
3.MaxClaw:
https://maxclaw.ai/
4.WorkBuddy:
https://www.codebuddy.cn/work/
5.AutoClaw:
https://autoglm.zhipuai.cn/autoclaw/
6.CoPaw:
https://www.aliyun.com/solution/tech-solution/copaw
7.DuClaw:
https://cloud.baidu.com/product/duclaw.html?from=home_banner
8.QClaw:
https://qclaw.qq.com/
9.StepClaw:
https://www.stepfun.com/chats/openclaw
https://aistudio.xiaomimimo.com/#/
# 参测流程
1.邮件申请
2.意向沟通
3.参测确认与协议流程
4.提供API接口或大模型
5.获得测评报告
# 邮件申请
# 联系我们






