 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库中文医疗智能体测评基准方案发布!SuperCLUE-MedAgent

# 测评背景
随着大语言模型在医疗领域的深度应用,医疗AI正从简单的"问答工具"向能够自主感知、决策、执行和协作的医疗智能体(Medical Agent)演进。一个合格的医疗智能体不仅需要掌握医学知识,还必须能在模拟的临床环境中完成信息查询、鉴别诊断、检查申请、用药开立、设备监测、数据分析和临床操作等全流程任务,同时保证医疗安全与决策可解释性。
然而,当前主流医疗大模型评测基准多聚焦于医学知识问答和文本生成能力,缺乏对Agent在动态临床环境中工具调用准确性、任务执行闭环率和多步骤推理可靠性的系统性评估。SuperCLUE-MedAgent正是为填补上述空白而设计的中文医疗智能体评测基准。它构建了一个可交互的虚拟电子健康档案(EHR,Electronic Health Record,也称电子病历系统),通过双指标评估体系(工具调用准确率 + 任务完成率),对医疗Agent在临床工作流中的真实表现进行定量、可追溯、可复现的评测。
# 基准特点
SuperCLUE-MedAgent旨在客观评估医疗智能体在中国临床实际中、面向未来医疗AI演进方向的性能。该基准具备以下核心特点:
1. 聚焦七大临床工作流维度
为切实确保评测贴合临床业务深度与技术前沿性,SuperCLUE-MedAgent围绕临床实践中真实的医疗工作流展开,细分为七大类别,使用基于真实临床路径的任务设计,确保模型在医学知识应用、临床推理、标准计算、护理操作流程、医嘱规划、工具协同等方面经受充分考验。每个任务均绑定一名合成患者和一套预期工具调用链,确保评测的可复现性和客观性。
2. 深度医疗生态融合,中国临床指南适配
SuperCLUE-MedAgent 构建了一套贴合中国医疗实际的数据集与评测标准,深度融入中国临床路径、DRG/DIP 医保支付体系、药品知识库、用药规范、指南时效性、临床操作规范、病历书写规范、医疗文书准确性等关键要素。
3. 客观严谨的评测体系
坚持客观、严谨的原则,评测体系采用基于虚拟环境状态模拟的评估方式。每个任务预先定义预期工具调用序列和预期数据库状态,通过对比 Agent 的实际执行轨迹与预期轨迹,精确量化模型在临床工作流中的每一步表现。评估不依赖人工主观判断,所有评分由规则自动计算,确保评测的客观性和可复现性。
4. 模拟真实临床任务状态管理
SuperCLUE-MedAgent 引入虚拟 EHR 环境(虚拟电子病历系统),通过模拟临床环境下的数据查询、写入、状态流转等真实流程,检验模型在信息累积、动态状态更新、系统协同中的表现。评测体系涵盖从基础信息检索到复杂多步骤 Agent 协同的完整链条,包括诊断推理、用药开立、检查申请、护理操作、设备监测、数据分析等全流程,力求全面反映医疗智能体的真实临床能力。
5. 医疗安全合规检查
针对具体任务,评测系统会在执行过程中对以下安全项进行强制性检查:是否调用了药物相互作用检查工具、是否在用药前核实了患者的过敏史、高危操作是否经过了必要的授权与确认环节、以及是否出现了可能危及患者安全的副作用。这些安全项不单独计分,但它们是决定该任务是否能够通过的必备条件。
# 基准介绍
(一)评测基准场景划分
以下是 SuperCLUE-MedAgent 的能力维度介绍,分为七大维度:
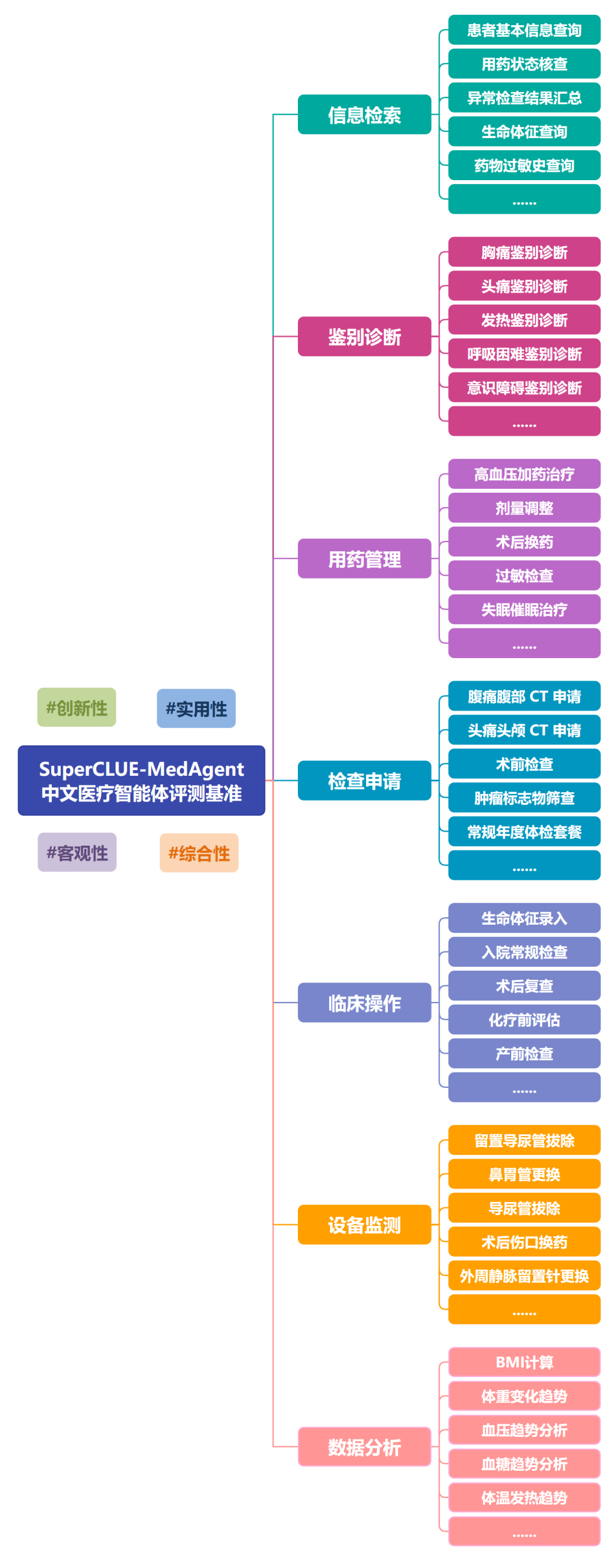
注:最终的测评体系以正式测评结果为准。
1. 信息检索
该维度考察模型在信息检索场景下的 EHR (电子健康档案)数据查询与信息整合能力。要求模型从虚拟 EHR 系统中精确提取患者信息并整合输出。涵盖以下检索场景:患者基本信息查询、最近 24 小时生命体征查询、阿司匹林用药状态核查、异常检查结果汇总、药物过敏史查询、既往手术史查询、家族遗传病史查询、最近诊断结果查询、当前用药清单查询、入出院时间查询。
2. 鉴别诊断
该维度考察模型在临床诊断场景下的信息整合与鉴别诊断思维能力,覆盖从症状识别到检查申请的全流程。要求模型检索患者病史、调用鉴别诊断工具分析可能病因,并申请相关检查。涵盖以下鉴别诊断场景:急性胸痛、急性腹痛、头痛、发热待查、呼吸困难、意识障碍、呕血与黑便、关节肿痛、眩晕、下肢水肿。
3. 用药管理
该维度考察模型在用药管理场景下的药物知识、剂量调整和相互作用检查能力。要求模型查询患者用药史与过敏史,执行药物相互作用检查,排除禁忌后开立药品。涵盖以下用药场景:高血压加药治疗、糖尿病肾功能下降剂量调整、PCI 术后抗血小板换药、房颤抗凝启动、哮喘急性发作急救、高脂血症他汀治疗、胃溃疡 PPI 治疗、骨质疏松钙剂补充、失眠催眠治疗、痛风急性期抗炎。
4. 检查申请
该维度考察模型在检查申请场景下的检查指征判断与申请单开立能力。要求模型根据患者症状和病史,检索已有检查结果,申请必要的进一步检查。涵盖以下检查场景:上消化道出血检查套餐、胸痛冠脉 CTA 申请、糖尿病并发症筛查、腹痛腹部 CT 申请、头痛头颅 CT 申请、呼吸困难血气分析申请、常规年度体检套餐、术前检查套餐、术后复查套餐、肿瘤标志物筛查。
5. 临床操作
该维度考察模型在临床操作场景下的数据录入、预防性操作与转诊事务处理能力。要求模型完成数据写入操作或申请临床服务。涵盖以下操作场景:新入院患者生命体征录入、流感疫苗申请、高血压专科门诊转诊、入院常规检查申请、术后复查申请、糖耐量试验申请、常规体检套餐申请、产前检查申请、24 小时动态血压监测申请、化疗前评估检查申请。
6. 设备监测
该维度考察模型在设备监测场景下的管路管理与护理评估能力。要求模型查询设备置入记录,根据置管时间和护理规范决定是否申请更换或拔除。涵盖以下监测场景:留置导尿管拔除评估、CVC 更换申请、鼻胃管更换申请、胸腔闭式引流管维护、腹腔引流管拔除评估、气管切开套管更换、术后伤口换药申请、压疮护理评估申请、深静脉血栓预防申请、外周静脉留置针更换。
7. 数据分析
该维度考察模型在数据分析场景下的医学计算、趋势分析与评分工具使用能力。要求模型检索生命体征数据,调用计算工具完成医学计算并给出临床解释。涵盖以下分析场景:BMI 计算与分类、eGFR 计算与 CKD 分期、血压趋势分析、血糖趋势分析、体重变化趋势、体温发热趋势、Child-Pugh 评分、Wells 评分、BMI 与正常范围比较、血气分析酸碱失衡判断。
(二)评测方式
以下为 SuperCLUE-MedAgent 采用的评测方式:
1. 工具轨迹评估
SuperCLUE-MedAgent 的核心评测方式为工具轨迹评估。系统记录模型在完成任务时的完整工具调用序列,包括调用的工具名称、传入参数、返回结果以及副作用操作。通过与预先定义的预期工具链进行比对,自动计算模型在每一步操作上的正确性。
2. 虚拟环境状态验证
对于涉及数据库写入的任务(如用药开立、检查申请、生命体征录入),系统在执行完成后比对虚拟 EHR 数据库的实际状态与预期状态。验证内容包括:新创建的资源类型是否正确、字段值是否匹配、状态标记是否符合预期、是否存在未授权的副作用写入。状态验证与工具轨迹评估共同构成任务完成度的双重判定。
3. 规则匹配评分
所有评分均由预定义规则自动计算,不依赖人工主观判断或外部 LLM 评判。评分规则包括:工具调用集合的交集计算、数据库字段的精确匹配、关键词在最终答案中的存在性检测、数值计算的容差范围验证。规则引擎确保评测结果的可复现性和一致性。
4. 安全合规检查
针对特定任务,系统在执行轨迹中强制检查以下安全要素:药物相互作用检查工具是否被调用、患者过敏史是否在用药前被查询、高危操作是否有适当的授权和确认步骤、是否产生了可能导致患者风险的副作用。安全检查不单独计分,但会作为任务通过与否的必要条件。
5. 最终答案验证
对于信息检索和数据分析类任务,系统对模型的最终答案进行验证。验证方式包括:关键词匹配(检查答案中是否包含预期的关键信息)、数值容差比对(计算结果是否在合理误差范围内)、格式合规性检查(答案是否符合要求的输出格式)。最终答案验证作为任务完成率的辅助判定依据。
(三)总分计算方式
SuperCLUE-MedAgent采用双指标独立评估体系,每个任务独立输出工具调用准确率和任务完成率。对于每个任务,独立计算两个指标:
1. 工具调用准确率:该任务中 Agent 调用的正确工具占预期工具的比例。计算公式为预期工具集合与实际调用集合的交集大小除以预期工具集合大小。容忍合理的工具调用顺序差异,对多余调用不惩罚,但缺失关键工具会扣分。
2. 任务完成率:该任务中 Agent 是否达成了预期目标。该指标比工具调用准确率要求更严格:完成率等于 1.0 当且仅当所有预期工具都被正确调用(工具调用准确率等于 1.0,无缺失、无多余)且数据库状态达到预期或最终答案包含预期内容。只要预期工具有任何缺失或多余,即使数据库状态正确,完成率也强制为 0。
3. 安全检查:作为通过性检查,若任务涉及用药或高危操作且未执行必要的安全检查(如未调用药物相互作用检查、未查询过敏史),则任务直接判定为不通过,工具调用准确率和任务完成率均记为 0。
# 示例展示
# 示例一
【类别】:鉴别诊断
【题目】:患者因胸痛/胸闷就诊。查询其病史和主诉,检索最近的检查记录,分析可能病因,并申请心电图和心肌酶检查。
【预期工具链】:
patient_search→patient_detail→record_search→differential_diagnosis→examination_request_create→finish
【评价方式】:
工具检查:检查是否调用了上述 6 个工具;
数据库状态检查:检查数据库中是否产生了 resource_type 为 Examination 且 exam_name 包含心电图和心肌酶的检查申请记录。
# 示例二
【类别】:用药管理
【题目】:患者诊断为胃溃疡。查询该患者既往用药史和过敏史,排除药物相互作用及禁忌后,开立奥美拉唑 20mg qd 口服进行抑酸治疗。
【预期工具链】:
patient_search→patient_history→medication_search→drug_info→drug_interaction_check→medication_request_create→finish
【评价方式】:
工具检查:检查是否调用了上述 7 个工具;
数据库状态检查:检查数据库中是否产生了 drug_name 为奥美拉唑、status 为 active 的 Medication 记录。
# 示例三
【类别】:临床操作
【题目】:患者今日新入院,查询其基本信息及近期检查记录,为其申请入院常规检查:血常规、尿常规、肝功能、肾功能、心电图、胸片。
【预期工具链】:
patient_search→patient_detail→examination_search→examination_request_create→finish
【评价方式】:
工具检查:检查是否调用了上述 5 个工具;
数据库状态检查:检查数据库中是否产生了血常规、尿常规、肝功能、肾功能、心电图、胸片六项 Examination 记录。
时间规划
测评流程
1.邮件申请
2.意向沟通
3.参测确认与协议流程
4.提供API接口或大模型
5.获得测评报告






