 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库CVPR 2026 自动驾驶与协作智能梳理:模型正在走向可控真实世界

作者丨郑佳美
编辑丨马晓宁

过去,视觉模型更多是在回答“看见了什么”,但当 AI 进入自动驾驶、游戏、机器人和多智能体协作场景时,问题已经不只是识别环境,而是“看见之后如何行动”。
一辆自动驾驶汽车不能只知道前方有车,还要判断如何避让、如何规划路线,甚至要在遮挡、夜晚和复杂天气中借助外部信息补足感知,一个游戏智能体不能只识别画面里的角色、障碍和敌人,还要把连续观察转化成具体操作;多个机器人或虚拟人也不能只是各自执行动作,而要根据队友位置、物体形状、任务目标和团队规模动态配合。
这种变化在 CVPR 2026 的相关研究中变得更加清晰:自动驾驶方向不再只关注单一感知模块,而是开始围绕可控场景生成、真实感仿真、端到端驾驶对齐和空间检索增强展开。
智能体方向也不再停留在“看见运动”,而是进一步探索如何从视频追踪走向动作学习,如何从互联网规模的玩家视频中恢复操作监督;多智能体方向则把问题推进到更复杂的团队行为,包括任意队伍规模下的人形协作,以及离线数据条件下的多目标协作学习。
这些研究看似分布在自动驾驶、游戏智能体和多人协作等不同任务里,但背后其实都在推动同一条能力链条:让模型从环境感知走向行动决策。
它们关心的不只是输入图像是否被正确理解,而是场景能否被构造,动作能否被学习,策略能否在闭环中稳定执行,多个主体能否在同一任务中形成配合。
也正因此,AI 的能力正在从“理解世界”进一步延伸到“参与世界”——不只是看见道路、角色或物体,而是能在复杂环境中判断、行动,并与其他主体协同完成任务。

01
从可控场景生成到空间记忆增强
自动驾驶研究正在从“让模型看懂当前画面”,进一步走向“让模型能够构造、编辑和利用更复杂的驾驶世界”。在仿真与训练中,一个关键问题是:如何生成足够真实、可控且多样的驾驶场景,尤其是那些真实道路中少见但对安全至关重要的危险交互、罕见轨迹和复杂交通情况。
由 NEC 美国研究院、石溪大学和加州大学圣地亚哥分校共同提出的《HorizonForge: Driving Scene Editing with Any Trajectories and Any Vehicles》。研究的是自动驾驶场景中的可控视频生成与编辑问题,也就是如何在已有驾驶视频中精确修改车辆轨迹、插入新车辆,或者改变自车与其他交通参与者的运动方式,同时保持画面的真实感、空间一致性和时间连续性。
现有方法往往难以同时做到高真实感和精确控制:要么编辑能力有限,要么生成结果容易出现结构不稳定、时序不连贯的问题。
HorizonForge 的核心思路是先把驾驶场景重建成可编辑的 Gaussian Splats 和 Meshes,再在这个 3D 表示上进行精细操作。系统可以直接修改车辆轨迹、调整场景几何,或根据语言指令插入新车辆;编辑后的结果再通过 noise-aware video diffusion 渲染出来,用扩散模型补足真实感,并保证空间和时间一致性。
相比每条轨迹都要重新优化的方法,HorizonForge 可以在一次前向推理中生成多种场景变化,更适合大规模自动驾驶仿真。

论文地址:https://arxiv.org/pdf/2602.21333v2
它的亮点在于,把 3D 可编辑表示和视频扩散生成结合起来:前者负责轨迹和车辆控制,后者负责最终视频的自然性和连贯性。论文还提出 HorizonSuite 评测基准,覆盖自车和交通参与者两个层面的编辑任务,包括轨迹修改和物体操作等场景。
实验中,Gaussian-Mesh 表示相比其他 3D 表示能带来更高保真度,视频扩散中的时间先验也对连贯合成非常关键;最终 HorizonForge 相比第二名方法实现了 83.4% 的用户偏好提升和 25.19% 的 FID 改进。
整体来看,这篇论文把自动驾驶场景生成从“生成一段看起来像驾驶视频的画面”,推进到“可精确编辑轨迹、车辆和 3D 场景结构的可控仿真”。它的意义不只是让驾驶视频更真实,也在于为感知、预测和规划模型提供更可控、更可扩展的训练与测试环境。

有了可编辑的仿真场景后,另一个问题随之出现:仿真画面本身是否足够真实,能否在插入车辆、行人等动态物体后,仍然保持自然的光照、阴影和前后景一致性。
由英伟达、多伦多大学、康奈尔大学和以色列理工学院合作完成《DiffusionHarmonizer: Bridging Neural Reconstruction and Photorealistic Simulation with Online Diffusion 的Enhancer》,研究的就是自动驾驶和机器人仿真中的真实感增强问题。
现在很多仿真环境可以通过 NeRF、3D Gaussian Splatting 等神经重建方法从真实数据中恢复出来,但在新视角渲染、稀疏视角外推,或插入其他场景的动态物体时,常常会出现几何伪影、缺失区域、光照不一致、阴影缺失和前景背景风格不统一等问题。
DiffusionHarmonizer 的核心思路是把神经重建渲染出的不完美画面,在线增强成更真实、更连贯的仿真视频帧。它不是重新构建整个 3D 场景,而是在渲染后加入生成式增强模块,用来修复新视角伪影、协调前景和背景外观,并为插入物体生成更合理的阴影。
模型由预训练的多步图像扩散模型改造成 single-step temporally-conditioned enhancer,只需一步推理就能增强当前帧,同时利用前几帧作为时间上下文,保证在线仿真中的时间稳定性。

论文地址:https://arxiv.org/pdf/2602.24096v2
它的亮点在于,既保留扩散模型的真实感生成能力,又尽量满足在线仿真的效率要求。普通视频扩散模型计算成本太高,普通图像增强模型又容易造成帧间闪烁;因此论文把多步扩散模型改造成确定性的单步增强器,并加入时间条件。
同时,作者还设计了专门的数据构建流程,合成外观协调、伪影修复、重光照、阴影生成和物体重新插入的数据,让模型学会处理颜色不一致、重建错误和光照不真实等问题。
整体来看,这篇论文把神经重建仿真从“能渲染出场景”,推进到“能生成更接近真实世界的在线仿真画面”。它的价值不只是让画面更好看,而是让基于真实数据重建的仿真环境更可信、更稳定,也更适合大规模训练和评测。

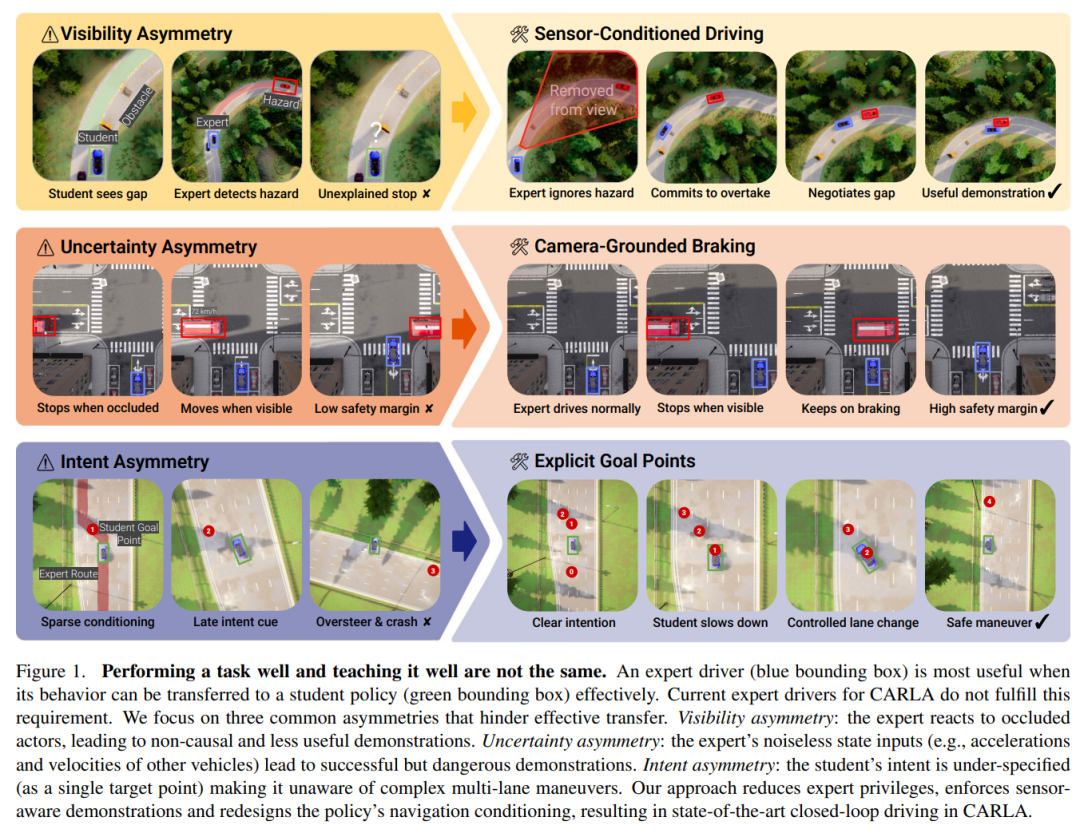
而当仿真环境变得更真实、更可控之后,训练出来的驾驶模型是否能在闭环中稳定执行,又取决于专家示范和学生模型之间是否真正对齐。由德国图宾根大学及图宾根人工智能中心、英伟达研究院以及德国“人工智能科学”卓越集群合作完成的《LEAD: Minimizing Learner-Expert Asymmetry in End-to-End Driving》研究就的是端到端自动驾驶中的模仿学习问题。
虽然仿真器可以生成大量驾驶数据,但用专家轨迹训练出的学生模型,在闭环驾驶时仍然容易不稳定,核心原因在于专家和学生之间存在明显的信息不对称。专家往往拥有更强的“上帝视角”,而学生模型在测试时只能依赖车载传感器输入和有限导航信息,因此很难可靠模仿专家行为。
LEAD 的重点不是单纯换一个更大的模型,而是系统性地缩小 learner-expert asymmetry。作者把这种差距分成两类:一类是 state alignment,即专家看到的信息和学生实际能看到的信息不一致;另一类是 intent alignment,即学生在测试时只拿到一个目标点,导航意图过于模糊。

论文地址:https://arxiv.org/pdf/2512.20563v2
针对这些问题,论文对专家生成方式、学生输入、导航目标表达和训练数据监督进行了修改,让学生学到的驾驶策略更接近自己真实测试时能执行的行为。
这项研究它没有把端到端自动驾驶的失败简单归因于模型容量不足,而是指出了模仿学习中更根本的训练偏差:
如果专家示范依赖学生看不到的信息,学生即使学得很像,也可能在闭环中犯错。通过减少可见性差异、不确定性差异和导航意图差异,论文训练出的 TransFuser v6(TFv6)在多个公开 CARLA 闭环 benchmark 上取得新的最好结果,例如在 Bench2Drive 上达到 95 DS,并在 Longest6 v2 和 Town13 上超过以往方法两倍以上。
整体来看,这篇论文把端到端自动驾驶中的模仿学习问题,从“如何让学生更好地模仿专家”,推进到“如何让专家示范更适合学生真实可见、可执行的条件”。
此外,论文还将感知监督整合进 sim-to-real 流程,并在 NAVSIM 和 Waymo Vision-Based End-to-End Driving benchmark 上带来稳定提升,说明这种对齐思路也有助于真实世界数据下的端到端驾驶泛化。
如果说 LEAD 关注专家与学生之间的信息对齐,那么《Spatial Retrieval Augmented Autonomous Driving》则进一步把自动驾驶的输入来源从车载传感器扩展到外部空间记忆。
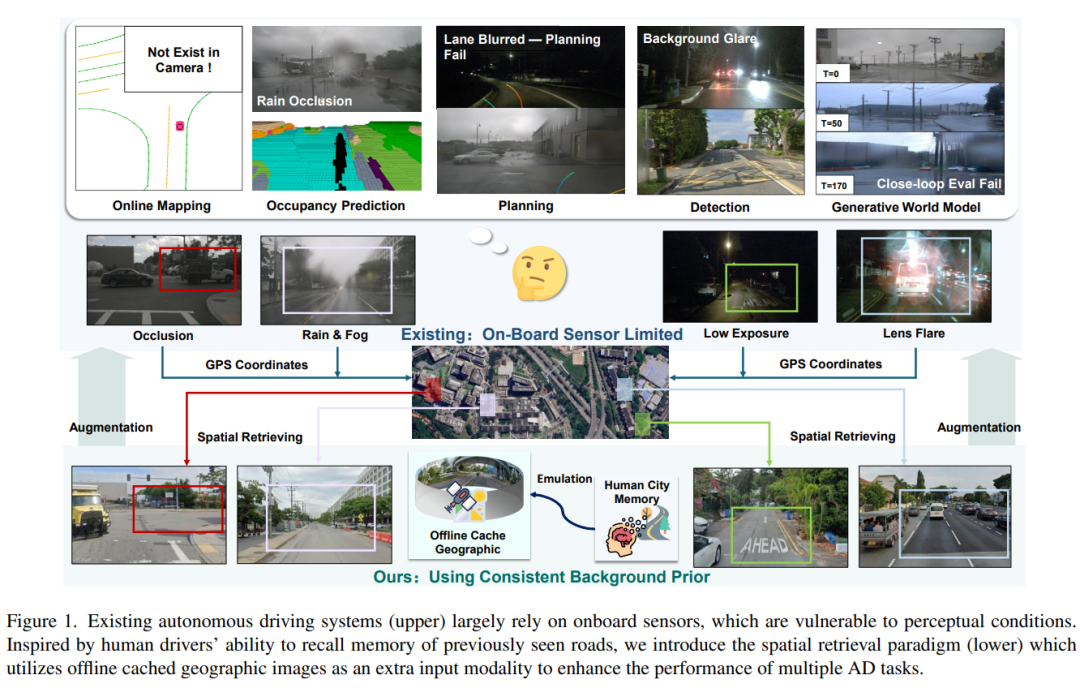
论文由复旦大学可信具身智能研究院、上海交通大学、中国科学院空天信息创新研究院目标认知与应用技术重点实验室、中国科学技术大学共同提出,研究的是自动驾驶中的一个新思路:现有自动驾驶系统主要依赖车载摄像头、激光雷达、IMU 等实时传感器感知环境,但这种方式很容易受限于当前视野。
一旦遇到遮挡、夜晚、雨天或视距不足,模型就可能看不清道路结构。人类驾驶员在这种情况下往往会凭借对道路布局的记忆继续判断,而这篇论文希望给自动驾驶模型也加入类似的“空间记忆”能力。
论文提出的核心范式叫 spatial retrieval,也就是根据车辆当前位置检索离线地理图像,比如卫星图、街景图或已有自动驾驶数据集中的地理图像,并把它们作为额外输入提供给自动驾驶模型。

论文地址:https://arxiv.org/pdf/2512.06865
这些信息不需要增加新的车载传感器,可以从离线地图缓存或公开地图 API 中获得,因此更像是一种可插拔的外部空间先验。论文还扩展了 nuScenes 数据集,通过 Google Maps API 检索地理图像,并将这些图像与自车轨迹对齐,形成 nuScenes-Geography 数据,用来系统评估这种空间检索范式。
它的亮点在于,不是单纯提升某一个自动驾驶模块,而是把地理检索信息接入多个核心任务。论文围绕 3D 目标检测、在线地图构建、占用预测、端到端规划和生成式世界模型建立基线,并设计了可插拔的 Spatial Retrieval Adapter,用于把检索到的地理图像融合进现有模型。
同时,论文还引入 Reliability Estimation,根据检索信息本身的可靠性来自适应决定该信多少、用多少,避免错误或不匹配的地理信息干扰驾驶模型。
从项目页给出的结果来看,空间检索信息在多个任务中都能带来提升:在生成式世界模型中,加入地理图像可以降低 FVD 和 FID,减少场景漂移并保持几何一致性;在在线地图构建中,额外道路背景信息有助于恢复被遮挡的车道线;
在占用预测中,地理先验尤其能提升静态类别和地面区域的预测;在端到端规划中,地理先验可以补偿遮挡或低光条件下的感知失败,并在夜间复杂场景中把碰撞率从 0.55% 降到 0.48%。
02
从看见运动到学会行动
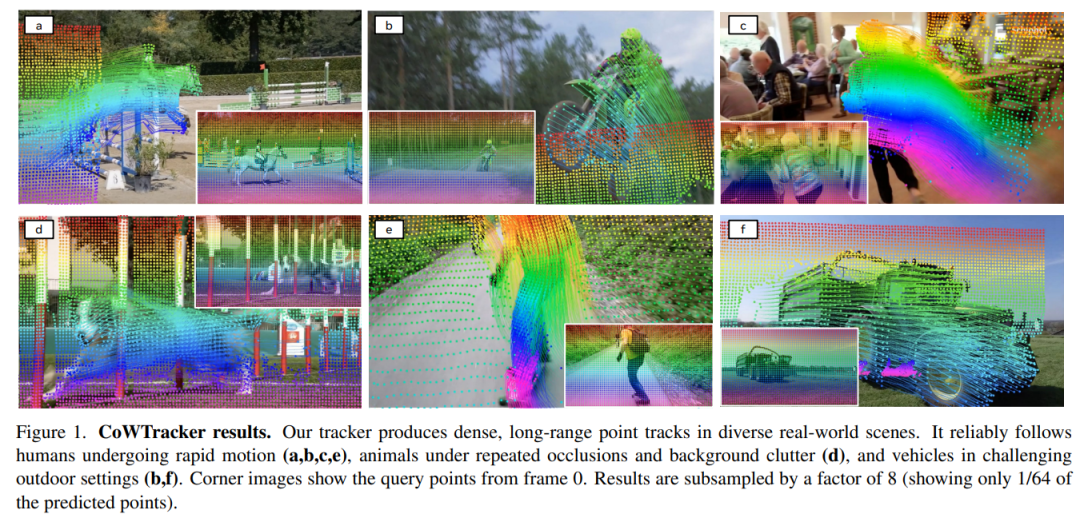
自动驾驶系统需要理解动态场景,而更基础的视觉能力之一,是在视频中稳定追踪点、物体和运动轨迹。《CoWTracker: Tracking by Warping instead of Correlation》由牛津大学视觉几何组和 Meta AI 共同提出。
研究的是视频中的 dense point tracking,也就是在一段视频中追踪任意像素点随时间变化的轨迹。这个任务对视频理解、机器人操作、光流估计等都很重要,但现有很多方法依赖 cost volume 做跨帧特征匹配,计算复杂度会随着图像分辨率呈平方级增长,因此在高分辨率、长视频和密集点追踪场景中很难高效扩展。
CoWTracker 的核心思路是用 warping 替代传统的 feature correlation / cost volume。模型不会在整张图里暴力搜索大量候选匹配,而是先维护每个点当前位置的估计,再根据这个估计把目标帧特征反向 warp 到查询帧附近,然后由 spatio-temporal transformer 联合更新轨迹、可见性和置信度。简单来说,它不是“到处找这个点在哪里”,而是“先猜一个位置,再反复把特征对齐并修正”。

论文地址:https://arxiv.org/pdf/2602.04877v1
它的亮点在于,把密集点追踪做得更简单、更高效,也更容易扩展到高分辨率视频。CoWTracker 不需要显式计算 cost volume,却能通过空间注意力和时间注意力同时建模同一帧中不同点之间的关系,以及同一个点在长时间序列中的运动变化。因此它可以处理长距离运动、大视角变化、遮挡和重新出现等复杂情况,还能输出每个点的轨迹、可见性和置信度。
从结果来看,CoWTracker 在 TAP-Vid-DAVIS、TAP-Vid-Kinetics 和 RoboTAP 等密集点追踪 benchmark 上表现很强,项目页给出的平均结果包括 Mean AJ 71.3、Mean δ_avg 81.8、Mean OA 93.3,高于 CoTracker 3 和 AllTracker 等方法。
更有意思的是,同一个模型在不专门训练光流数据的情况下,也能在 Sintel、KITTI-2015 和 Spring 等光流 benchmark 上取得有竞争力的结果,例如在 Sintel 和 KITTI 上的 EPE 分别达到 0.78 和 1.04。
整体来看,这篇论文把密集点追踪从依赖昂贵相关匹配,推进到基于迭代 warping 和时空推理的统一框架,并说明 dense tracking 和 optical flow 有机会用同一种架构处理。
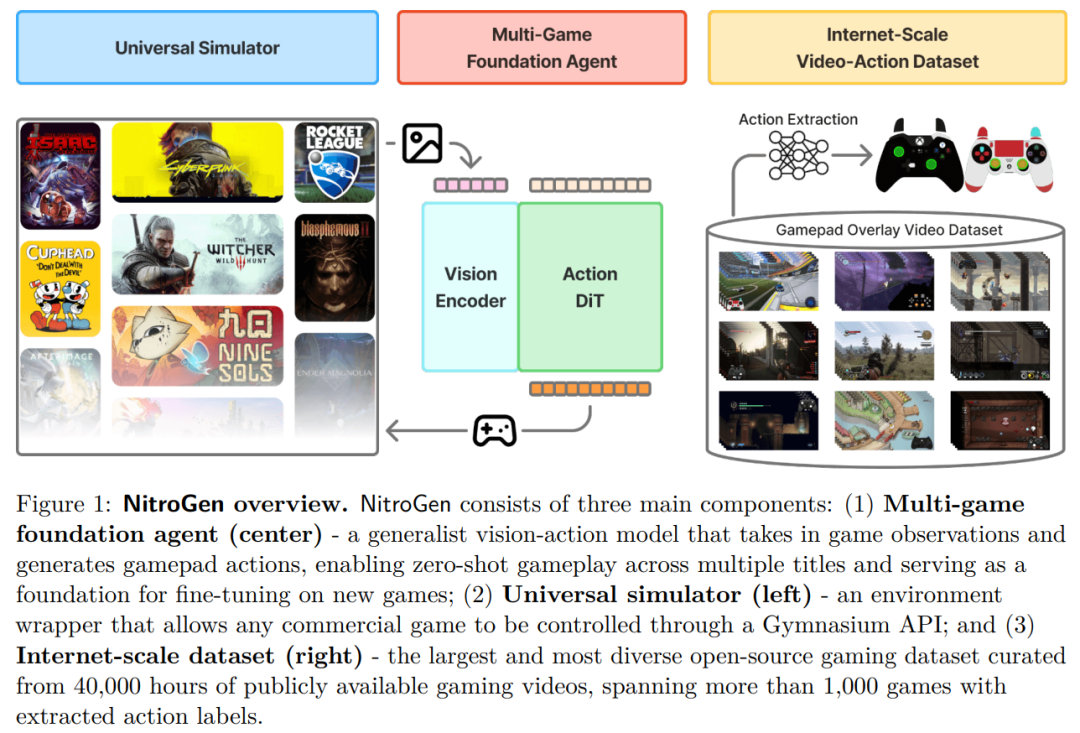
从“追踪运动”继续往前走,就是让模型根据视觉输入直接做出动作决策。《NitroGen: An Open Foundation Model for Generalist Gaming Agents》由英伟达、斯坦福大学、加州理工学院、芝加哥大学和德克萨斯大学奥斯汀分校合作完成。
论文研究的是面向游戏环境的通用智能体基础模型,也就是让一个模型能够在不同类型、不同机制的游戏中,根据画面观察直接输出游戏手柄动作,而不是只针对某一个游戏单独训练。
作者认为,具身智能长期缺少像视觉和语言模型那样的大规模预训练数据,强化学习虽然能在个别游戏中取得很强效果,但往往依赖专门模拟器和高成本训练;而现有行为克隆方法又受限于昂贵的人类示范数据,很难扩展到大量游戏。
NitroGen 的核心思路是利用公开视频中的游戏手柄 overlay 自动恢复玩家操作,从而构建大规模“视频—动作”数据集。很多游戏视频会在画面角落实时显示玩家按键和摇杆输入,NitroGen 先定位并裁剪这些手柄区域,再用模型解析摇杆位置和按键状态,最终从公开游戏视频中提取逐帧动作标签。
通过这种方式,作者整理出约 4 万小时、覆盖 1000 多款游戏的数据,并在此基础上训练统一的 vision-action transformer,用画面观察预测 gamepad actions。

论文地址:https://arxiv.org/pdf/2601.02427v1
它的亮点在于,把互联网上原本只是“给人看的游戏视频”转化成了可用于训练智能体的动作监督数据,从而绕开昂贵的人工采集和专门环境搭建。除了数据集,论文还构建了一个多游戏评测环境,包含 10 款商业游戏中的 30 个任务,覆盖战斗、导航、决策、平台跳跃、探索和解谜等能力,并通过统一的 Gymnasium API 封装不同游戏,让模型能在更真实的跨游戏环境中测试泛化能力。
从效果来看,NitroGen 在 3D 动作游戏战斗、2D 平台跳跃高精度控制、程序生成世界探索等任务中都表现出较强能力,并且能够迁移到未见过的新游戏。论文中提到,在相同数据和计算预算下,用 NitroGen 预训练权重进行微调,相比从零训练的模型,任务成功率最高可获得 52% 的相对提升。作者还开源了数据集、评测套件和模型权重。
整体来看,这篇论文把游戏智能体从“针对单个游戏训练专用策略”,推进到“利用互联网规模视频数据预训练通用视觉—动作基础模型”。它的意义不只在游戏本身,也在于为具身智能提供了一条新的数据路径:通过公开视频恢复动作监督,让模型从大量人类玩家行为中学习跨环境、跨任务的操作能力。
03
从单体控制到团队行为学习
如果说 NitroGen 关注的是一个智能体如何从视觉中学会行动,那么在人形控制和机器人协作中,更复杂的问题是多个智能体如何像团队一样协同完成任务。
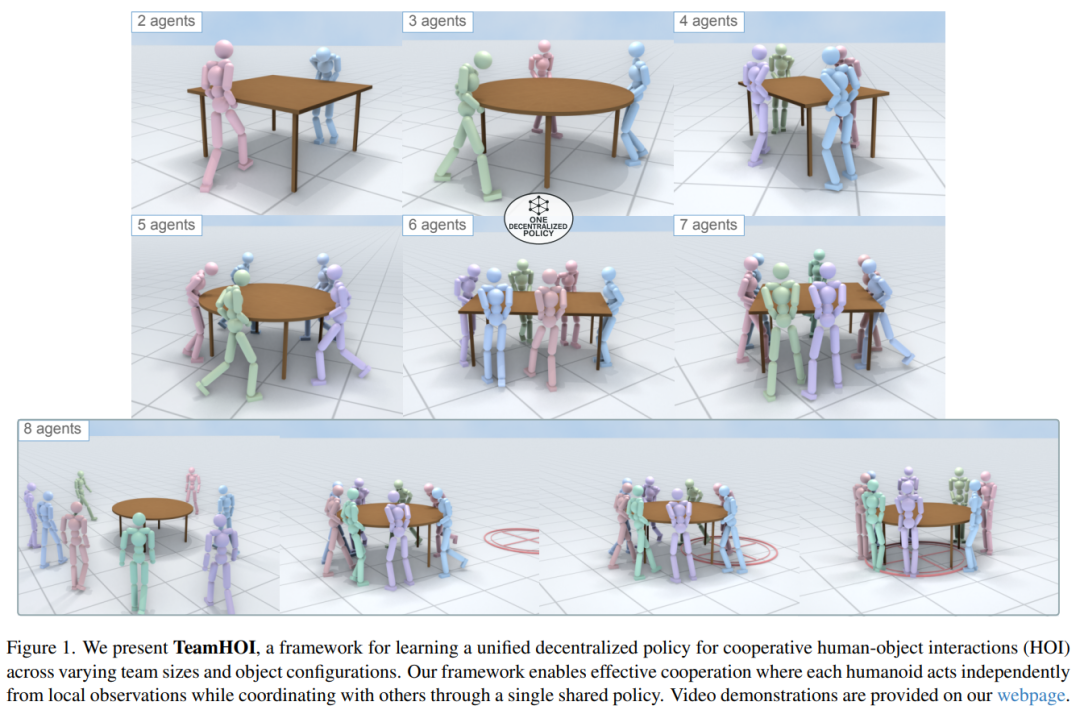
由 Garena、Sea AI Lab,以及新加坡国立大学共同提出的《TeamHOI: Learning a Unified Policy for Cooperative Human-Object Interactions with Any Team Size》研究的就是多个人形智能体之间的协作式人—物交互问题,也就是让多个虚拟人或机器人一起搬运、抬起、移动物体,并且能够根据队伍人数和物体形状自动调整协作方式。
现有物理人形控制已经能完成不少单人动作和人—物交互任务,但一旦进入多人协作场景,就会遇到两个难点:一是很多策略只能适配固定人数,难以扩展到不同团队规模;二是高质量多人协作动作数据很少,模型很难学到自然、多样且物理合理的协同行为。

论文地址:https://arxiv.org/pdf/2603.07988
TeamHOI 的核心思路是训练一个统一的去中心化策略,让每个智能体基于自己的局部观测独立行动,但又能通过同一个策略网络感知队友状态并形成协作。
具体来说,TeamHOI 使用 Transformer-based policy network,把其他智能体的状态表示成 teammate tokens,让策略可以适配不同数量的队友,而不是像传统 MLP 那样被固定输入维度限制。这样,同一个策略就可以在 2 到 8 个智能体,甚至更多未见过的队伍规模中复用,而不需要重新训练或微调。
它的另一个关键设计是 masked Adversarial Motion Prior(masked AMP)。由于多人协作动作数据稀缺,论文仍然使用单人参考动作来约束运动自然性,但会在 AMP 监督中遮掉与物体交互的身体部位,让手部、接触和搬运动作更多由任务奖励来引导。
这样模型既能保持整体动作自然,又不会被单人动作数据过度限制,可以从单人参考动作中衍生出更多样的多人协作行为。论文还设计了不依赖队伍人数和物体形状的 formation reward,引导智能体围绕物体形成稳定队形,从而更平稳地抬起和搬运桌子。
这篇论文的亮点在于,它把多人协作从“固定人数、固定策略”的控制问题,推进到“任意团队规模下的统一协作策略”。在桌子搬运任务中,TeamHOI 能让 2 到 8 个智能体协同搬运方形、长方形或圆形桌子,并在普通重量设置下保持很高成功率。
主实验中,TeamHOI 在 2 人、4 人和 8 人设置下分别达到 99.1%、99.2% 和 97.5% 的成功率,而在 5 倍重量的重载设置下,8 人团队仍能达到 81.1% 成功率。相比之下,基线方法往往只能在训练时对应的人数上表现较好,一旦队伍规模变化就容易失败或不稳定。
TeamHOI 展示的是具体协作任务中的策略学习,而要让多智能体协作研究进一步发展,还需要更系统的任务集合、离线数据和统一评测标准。
《MangoBench: A Benchmark for Multi-Agent Goal-Conditioned Offline Reinforcement Learning》由中山大学和香港理工大学共同提出,研究的是多智能体离线强化学习中的一个关键问题:
多个智能体如何在不能在线试错、只能使用已有数据的情况下,学会根据不同目标进行协作。现有离线多智能体强化学习方法往往依赖人工设计的奖励函数,但这类奖励函数对细微变化非常敏感,也很难让策略泛化到新目标;而单智能体中的目标条件离线强化学习虽然已经能缓解这个问题,但在多智能体协作场景中还缺少系统框架和统一评测基准。

论文地址:https://wendyeewang.github.io/MangoBench
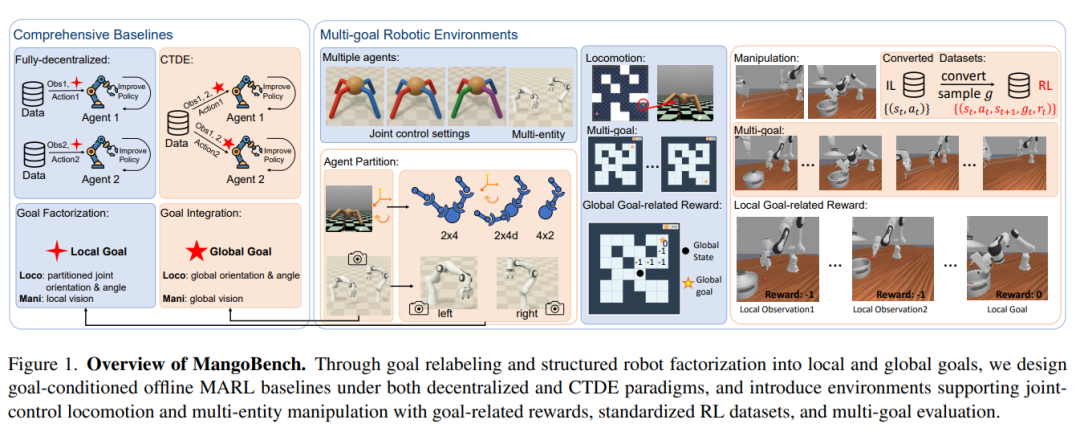
MangoBench 是面向 goal-conditioned offline MARL 的第一个全协作、多目标基准。它覆盖 3 个环境、4 类智能体和 47 个协作任务,包括联合控制的运动任务,以及同步和异步的双臂操作任务。
论文还把目标条件学习扩展到多智能体场景中,同时支持完全去中心化训练和 CTDE 两种范式;在去中心化设置下,系统会把全局目标拆分成各个智能体可使用的局部目标,而在 CTDE 设置下,则把个体目标整合到统一全局目标中进行更强的价值学习,但执行时每个智能体仍根据自己的局部目标行动。
它的亮点在于,不只是提供一个任务集合,而是把“目标条件、多智能体、离线数据、稀疏奖励和多目标评测”统一到同一个框架中。MangoBench 包含 45 个 locomotion 任务和 2 个 manipulation 任务:在运动任务中,多个智能体分别控制同一个机器人身体的不同关节,共同完成 AntMaze、AntSoccer 等目标。
在操作任务中,两个机械臂需要完成 lift-barrier 和 place-food 等协作任务,其中既有同步协作,也有异步协作。论文还基于开放数据集转换出适合目标条件离线多智能体学习的数据格式,并为每个任务设计多目标评测,避免只在单一目标上评估导致结果偏差。
为了让这个基准真正可用,论文还提出了 6 个 baseline 算法,覆盖完全去中心化和 CTDE 两种训练范式,包括 GCMBC、ICRL、IHIQL、HIQL-CTDE、GCOMIGA 和 GCOMAR。
这些方法分别用于评估行为克隆、对比价值学习、层级策略、目标重标注和离线多智能体方法在稀疏奖励、多目标泛化和协作控制中的表现。实验表明,这些 baseline 在稀疏奖励下已经能展现一定的多目标泛化能力,但没有一种方法可以在所有任务中稳定占优,说明 goal-conditioned offline MARL 仍然是一个复杂且远未解决的问题。
这次去 CVPR 现场,一定不要错过
【认识大牛+赚外快】的机会
需要你做什么:把你最关注的10个大会报告,每页PPT都拍下来
你能获得什么?
认识大牛:你将可以进入CVPR名师博士社群;
钱多活少:提供丰厚奖金,任务量精简;
听会自由:你的行程你做主,顺手就把外快赚。拍下你最感兴趣的10个报告PPT即可。
如果你即将前往CVPR,想边听会边赚钱,还能顺便为AI学术社区做贡献、认识更多大牛,欢迎联系我们:[添加微信号:MS_Yahei]
【限额5位,先到先得】


CVPR 2026 视频模型趋势梳理:不止生成下一帧,更要理解下一步

从「座上宾」到「主战场」:具身智能如何完成对计算机视觉的「范式夺权」?| CVPR 2026

未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。





