 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库😺 Claude beat ChatGPT 2-to-1
Sign Up
·
Advertise


Welcome, humans.
Thanks to everyone who answered our
“what’s your daily driver” (#1 most used AI) check-in poll
on Sunday. Guess this shouldn’t really shock us, given Anthropic’s main character syndrome atm, but
WOW
, this was a surprising result:
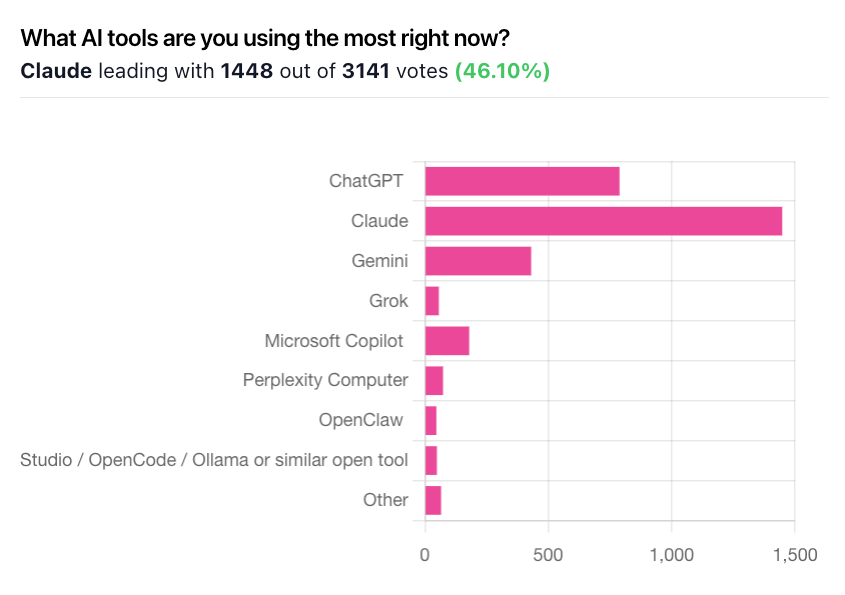
Claude has officially overtaken ChatGPT as the #1 tool from Neuron readers* (
*who answer polls
), and at almost 2x the rate (1448 vs OpenAI’s 790).
We published an
in-depth report
on what y’all had to say (
don’t worry, it’s anonymous!),
and will dive into it more below.
Worth a read if you want to learn what tools your peers are using and why
(be honest; who wouldn’t?)
Here’s what happened in AI today:
😺 We unpack those poll results in our main story.
📰 Amazon doubled down on Anthropic with up to $25B more, for $33B total
📰 Moonshot dropped Kimi K2.6, an open-weights Claude competitor for 76% less
🍪 Qwen3.6-Max-Preview topped six coding benchmarks; try it in Treats
🎓 A prompting trick that makes language models better dice-rollers (seriously)
…
and a whole lot more that you can read about here.
P.S:
Want to reach 700,000 AI-hungry readers?
Click here to advertise with us.
P.P.S:
Love robots? We’re starting a new robotics newsletter!
Sign up early here
.

😺
So y’all say Claude beat ChatGPT about 2-to-1 in our reader poll… let’s find out why
DEEP DIVE:
Claude beat ChatGPT 2-to-1 in our reader poll. Here's why
Let’s dive into those numbers from up top:
First up, the final tally. At time of writing this: 3,143 votes.
Claude 1,449 (46%), ChatGPT 790 (25%), Gemini 431 (14%), Microsoft Copilot 180, Perplexity Comet 74, Grok 57.
A self-selected bias from an AI newsletter audience, yes; but a loud, specific, paying-attention one.
Why Claude won the write-ins:
Coding quality (Claude Code came up constantly).
Writing that "gets me" for long-form work.
Cowork as a genuine workflow primitive.
And, mentioned surprisingly often,
ethics and brand alignment
.
Readers cited the Pentagon deal, "personal animus against Sam Altman and Elon," and wanting "a company that cares to try for good outcomes."
For a non-trivial slice of Claude's lead, values drove loyalty as much as features.
Why ChatGPT's 790 stayed put:
price, memory and Projects ("it knows my projects"), habit, and sticky personal use cases like parenting, job search, and health coaching. One reader credited ChatGPT with saving her hand after a VA injection went wrong. Switching costs are real.
The Copilot paradox:
the Copilot write-ins all said the same thing in different words:
"Forced by my company; I'd rather be using Claude."
Captive market share is fragile. Claude-in-Office is going to make 2026 extremely interesting.
Why this matters:
Every other headline on Monday ratified this result within hours.
Amazon committed up to $25B more in Anthropic
(total: $33B; 500,000 Trainium2 chips; revenue run rate doubled to $20B+).
Axios reported the NSA is using Anthropic's internal-only Mythos model
despite a Pentagon ban.
And The Information reported Google DeepMind spun up a "Strike Team"
, led by Sergey Brin personally, to catch Anthropic on agentic coding.
These three bets all presume the exact thing our readers told us: Claude owns the power-user coding market.
In this case, the money is following the demand, not the other way around.
Our take: tool choice is becoming identity.
Ethical defection from OpenAI and xAI moved a loud, vote-shifting slice of comments. When readers pick an AI like they pick sneakers (on values not specs alone), the competitive surface stops being "who ships the best model this quarter" and starts being
narrative capital.
Anthropic has the lead right now. Whether they can keep it while remaining the premium-priced option (especially with Kimi K2.6 landing open-weights at 76% the cost on the same day) is the question we'll track all year.

FROM OUR PARTNERS
Why your AI agents keep getting the wrong answer

Most AI agent failures aren't model failures. They're context failures: missing definitions, stale metadata, two sources that contradict each other. Teams use multiple tools - Claude, GPT projects, Gemini, Copilot, Cortex, Genie. And most teams often rebuild the same context from scratch for every agent they ship.
On April 29,
Atlan
is doing a live demo of the infrastructure layer designed to fix this:
Context Engineering Studio: bootstrap, test, and ship reusable context repos (just like code repos)
Context Agents: 9 AI teammates that write and maintain your context automatically (90% suggestion acceptance in production)
Context Lakehouse: open, interoperable infrastructure your entire agent stack can draw from
One hour. Live launch. See how the best AI teams solve the production context problem.
Can't make it? Register anyway, you'll get the recording. →/activate

🎓 AI Skill of the Day:
Use "String Seed of Thought" to get more diverse, less biased answers from any frontier LLM.
Sakana AI's Kou Misaki and Takuya Akiba
published a prompting trick called SSoT (
arXiv here
) that fixes a quiet problem: LLMs are bad at randomness. Ask one to "pick a number between 1 and 100" a hundred times and you'll see 42 and 37 way more than chance. That bias warps brainstorming, A/B selection, and synthetic-data generation.
The fix: have the model generate a random string first, then deterministically
manipulate
that string to derive its answer. The manipulation step forces outputs away from the model's built-in preferences.
Try it:
Before answering, generate a random 12-character alphanumeric string.
Then sum the ASCII values of the characters modulo [N], where N is the
number of options I gave you. Use that number as your index (0-based)
into the options. Do this BEFORE you reason about which option you prefer.
Report the string, the sum, and your selection.
My options are: [paste list here]
On "pick one" tasks, Sakana approaches true-random distributional faithfulness on DeepSeek-R1 and meaningfully improves diversity on Opus, GPT-5, and Gemini.
Want more? Check our new
AI Skill of the Day Digest for April Week 4
, where we recap the top reader-requested skills!
Total AI beginner?
Start here
(
goes with this video
).
Have a specific skill you want to learn?
Request it here.

FROM OUR PARTNERS
Editors Pick - Slack

Why We Love It:
Slackbot
is your always-on personal agent for work — and it's already built right into Slack.
Discover Slackbot

🍪 Treats to Try
Kimi K2.6
is Moonshot's new 1-trillion-parameter open agentic model (32B active, 262k context) with Day-0 Cloudflare Workers AI support, and paired with
Kimi Code CLI
it runs roughly 76% cheaper than Claude; full walkthrough in today's Tuesday Tool Tip below.
Qwen3.6-Max-Preview
is Alibaba's new flagship that topped six major coding benchmarks (SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, SciCode), runs a 256k context window, and accepts both OpenAI-compatible and Anthropic-compatible API calls; free preview via Qwen Studio, paid API via Alibaba Cloud Model Studio.
Moondream Lens
fine-tunes a vision-language model (AI that reasons about images) on as few as a dozen examples; one test took NBA ball-handler detection from 28% to 79% F1 in 54 minutes for $16.89, and it beat GPT-5.4 on street-view geolocation and glaucoma staging; pay-as-you-go.
Anthropic shipped live artifacts in Cowork
that build dashboards and trackers connected to your apps and files, refreshing with current data and saving with version history on all paid plans;

📰 Around the Horn
Atlassian
will force default data collection on 300K customers starting Aug 17; metadata is mandatory on Free, Standard, and Premium tiers, and a
Hacker News-amplified Reddit rumor
claims Anthropic is in advanced talks to buy Atlassian for $150/share all-cash.
OpenAI
shipped Chronicle, an experimental Codex memory feature for Pro users on macOS that continuously reads recent screen context so prompts like "fix this" or "add that" just work; its architecture closely mirrors
Stanford's "General User Models" research
.
GitHub
paused new Copilot Pro, Pro+, and Student signups and removed all Opus from Pro after
leaked internal docs
showed weekly Copilot costs nearly doubled since January.
Gallup
found half of all employed Americans now use AI at work per its Q1 2026 survey of ~24,000 workers, more than doubling since 2023.
iLearningEngines
founder/CEO Puthugramam Chidambaran and CFO Sayyed Farhan Ali Naqvi were indicted in Brooklyn federal court on 10 counts after ~90% of the AI ed-tech company's $421M in 2023 revenue was allegedly fabricated.
GPT-5.5 "Spud"
is expected to drop Thursday per a post from @can that's now priced at 81% on Polymarket; the fully realized Spud model reportedly ships later with "insane efficiency" gains
Want absolutely EVERYTHING that happened in AI this week?
Click here!

FROM OUR PARTNERS
Introducing Backstory

You didn't get this far by guessing.
Backstory gives CROs and sales leaders a straight answer about their pipeline - built on how your team actually sells, not another dashboard. Trusted by NVIDIA, OpenAI, Zscaler, and Red Hat.
Sign up for a demo
.

🔧
Tuesday Tool Tip: How to run Kimi K2.6 as your cheap Claude replacement
Kimi K2.6
is Moonshot's new open agentic model. Three fast ways to put it to work:
Cloudflare Workers AI, Day-0.
Call
@cf/moonshotai/kimi-k2.6
directly from a Worker or any OpenAI-compatible client pointed at Cloudflare's endpoint. Usage-based pricing, no separate contract.
Kimi Code CLI
(command-line tool). Install, authenticate with your Moonshot key, point it at a real repo. K2.6 can run a 300-sub-agent swarm across up to 4,000 coordinated steps for a single job; think "refactor this legacy Rust crate end-to-end overnight." Roughly
76% cheaper than Claude
with 75-83% cache savings.
Claw Groups (preview).
K2.6's new human-in-the-loop feature lets you drop into an agent's plan mid-run, swap sub-goals, and push it back out.
For more about this,
read here
. If you're burning through your Copilot or Claude quota, this is the serious alternative to try this week.

A Cat’s Commentary
 |
|
P.S:
Before you go… have you subscribed to our YouTube Channel? If not, can you?





