 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库ICML 2026|上海创智学院等提出医学长视频推理新范式:MedScope让AI从「看过视频」走向「查证视频」
将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


医学多模态大模型正在从静态影像走向动态临床场景。手术、内镜、介入操作和临床教学视频不同于单张影像,它们记录的是连续发生的诊疗过程:动作、器械、组织暴露、风险事件和关键步骤都沿时间轴展开。
这类长视频的难点不在于视频更长,而在于证据更稀疏。一个决定模型判断的视觉线索,可能只在几十分钟视频中的几秒内出现;一旦固定抽帧没有覆盖到关键片段,模型即便生成了流畅解释,也很难证明自己的答案来自真实证据。
这正是临床 AI 走向真实应用时必须解决的问题:医学视频模型不能只是给出一个看似合理的答案,更需要回答「证据在哪里」。如果答案无法回到具体时间窗口、关键帧和视觉观察本身,它就很难用于质控、教学复盘、术后评估或高风险场景中的人机协同。
为此,上海创智学院 LeapQuest 团队联合上海交通大学、上海交通大学医学院附属瑞金医院、复旦大学、上海人工智能实验室、清华大学和香港中文大学提出 MedScope。该工作把临床长视频推理从「看过视频后回答」推进到「主动查证证据后回答」,核心目标是让模型不仅答对,还要从正确证据中答对。

论文链接:https://arxiv.org/abs/2602.13332
代码链接:https://github.com/SII-WenjieLisjtu/MedScope
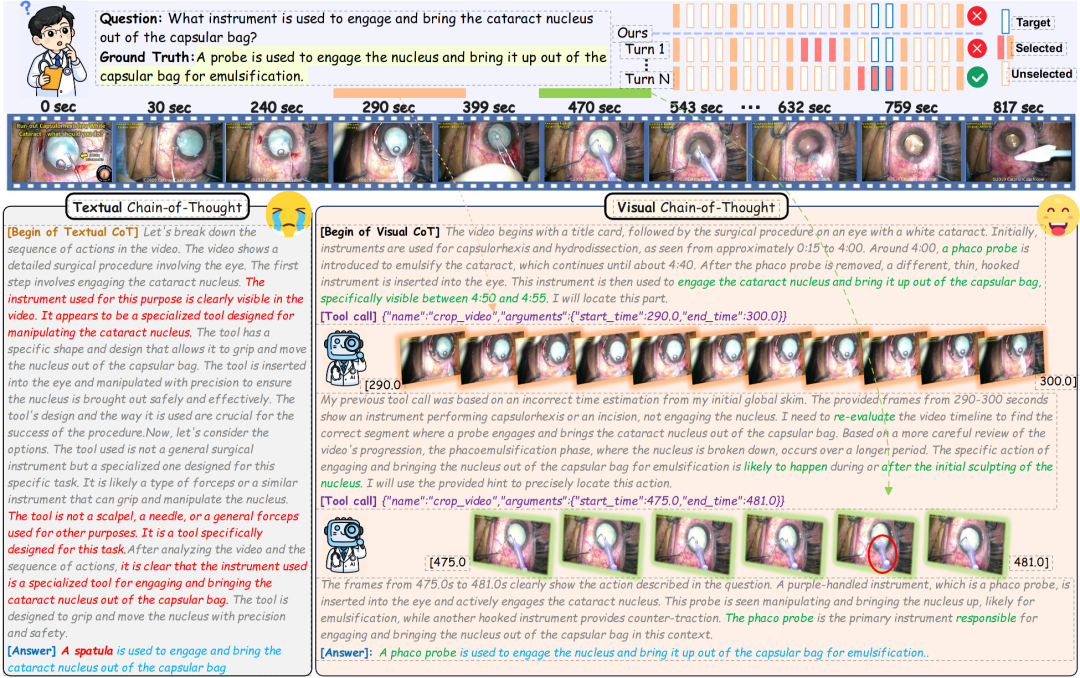
Textual CoT 与 Visual CoT:前者主要生成文字推理,后者把推理过程接入视频工具,使模型能够反复定位、观察和验证关键证据。
范式突破:Think with Videos,让模型带着问题回看视频
MedScope 的核心不是让模型写出更长的 Chain-of-Thought,而是让模型真正具备与视频交互的能力。其提出的 Think with Videos 范式,将一次性视频问答拆解为多轮过程:模型先形成假设,判断还缺少什么证据;随后调用工具回看候选片段或关键帧;再根据新的视觉观察修正判断。
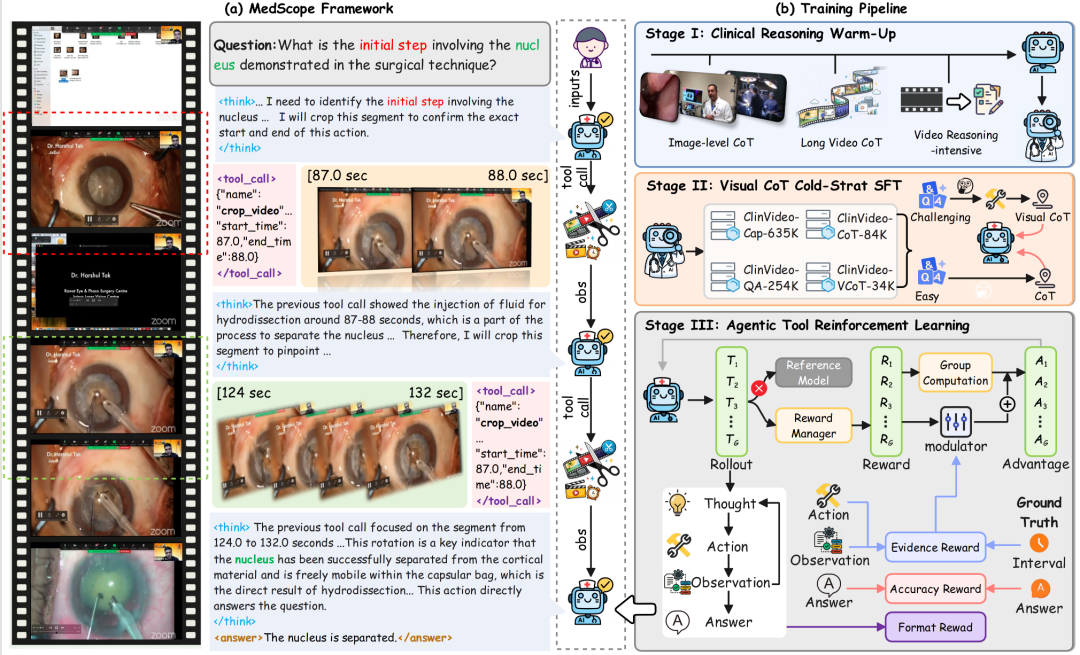
MedScope 总体框架:模型在思考、工具调用和视觉观察之间循环,将长视频理解重构为 coarse-to-fine 的证据查证过程。
一句话理解突破
MedScope 的核心不是让模型「更会描述视频」,而是让模型学会在长视频中主动查证:先提出证据需求,再调用工具定位片段,最后基于视觉观察生成可复核答案。
这带来一个关键变化:模型不再只是被动接受预采样帧,而是学会在推理过程中主动决定「下一步该看哪里」。这种能力将大模型的语义推理、视频时间轴上的证据检索,以及最终答案生成连接为一个闭环,更接近临床专家处理长流程视频时「先扫全局、再看局部、最后确认细节」的工作方式。
方法一:Coarse-to-Fine Tool Calling,把长视频拆成可验证的证据路径
在工具设计上,MedScope 没有引入复杂的外部专家系统,而是选择两个最基础也最关键的操作:沿时间轴截取局部视频,以及在指定时间点查看关键帧。通过 Coarse-to-Fine Tool Calling,模型可以先粗定位候选区间,再进入局部片段进行细粒度查证。

这套工具机制的突破不在于「看更多帧」,而在于「带着问题去看帧」。模型每一次工具调用都服务于当前推理的不确定性:是为了确认某个操作是否发生,还是为了判断组织是否暴露,或者为了核实风险事件是否出现。最终,答案不再只是文本结果,而是一条可追踪的证据链。
方法二:ClinVideoSuite,让训练数据从「问答对」升级为「证据对齐样本」
要让模型学会主动找证据,仅靠视频 - 答案对是不够的。模型必须知道:答案依赖哪段视频、证据出现在什么时间窗口、需要经过怎样的工具调用才能找到它。围绕这一目标,研究团队构建了 ClinVideoSuite,一个面向 evidence-centric training 和 grounded evaluation 的临床视频数据套件。
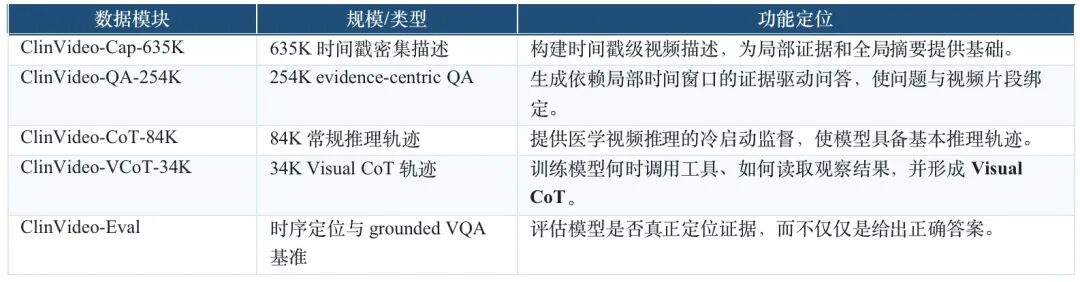
ClinVideoSuite 的核心价值不只是数据规模,而是重构了训练信号。团队通过多层过滤剔除凭常识即可回答、仅看全局摘要即可回答或内部不一致的问题,并进一步通过多模态确认确保保留的问题确实依赖视频片段本身。
由此,问题、答案和证据窗口被绑定在一起。模型学习的不再只是「如何生成答案」,还包括「应该到哪里找证据」「怎样通过观察修正推理」「何时证据已经足以支撑结论」。这为医学视频智能体提供了比传统视频问答更高密度、更可审计的监督信号。
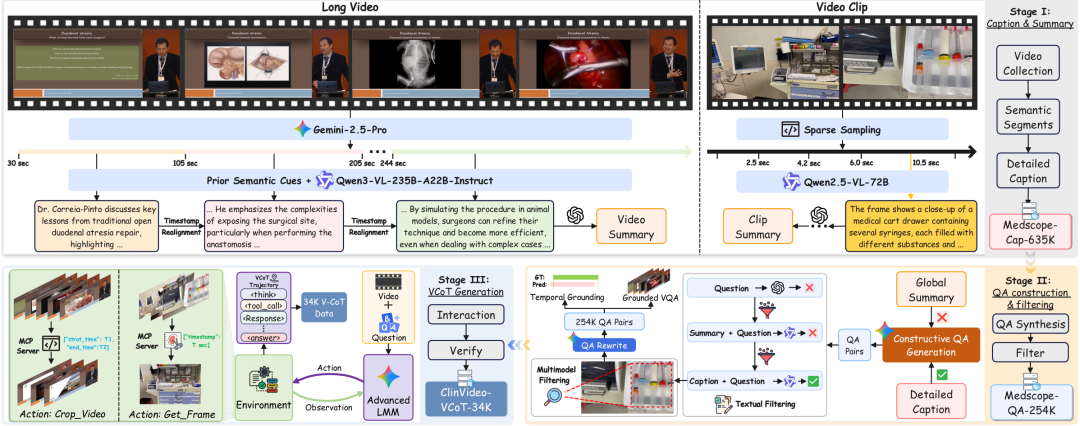
ClinVideoSuite 数据构建流程:从视频采样、密集描述、证据驱动 QA 到 Visual CoT 轨迹生成,为工具增强推理提供训练底座。
方法三:GA-GRPO,把「找对证据」写进强化学习目标
在医学场景中,只奖励最终答案正确远远不够。一个模型可能因为语言先验而猜中答案,也可能基于错误片段给出正确结论;如果训练只看结果,模型就可能学到「猜中即可」,而不是「必须基于正确证据」。
MedScope 提出的 Grounding-Aware Group Relative Policy Optimization(GA-GRPO)正是为解决这一问题而设计。它将奖励从答案层扩展到证据层,由答案正确性、格式规范性和 evidence reward 共同构成;对于 crop_video 工具,还进一步引入 IoU bonus,鼓励模型预测的时间窗口与真实证据窗口更加重合。
为什么这一步关键
临床场景不能只奖励「答对」,还必须奖励「证据对齐」。GA-GRPO 将工具调用、时间定位和最终答案纳入同一学习闭环,使模型学会从正确证据中答对。
这使 MedScope 的训练目标从单一准确率优化,转向「答案 — 工具 — 证据」的联合优化。模型不仅被鼓励答对,也被鼓励调用正确工具、定位正确时间段,并把最终判断建立在可复核的视觉证据上。
实验结果:不仅开放模型领先,更实现「答对并找对」
论文在 SVU-31K 与 ClinVideo-Eval 等基准上对 MedScope 进行系统评估,覆盖完整视频描述、细粒度视频理解、时间推理、感知推理、Temporal Grounding 和 grounded VQA 等任务。结果显示,MedScope-7B-RL 在开放模型中取得领先整体表现,并在跨域临床视频评估中保持良好泛化。
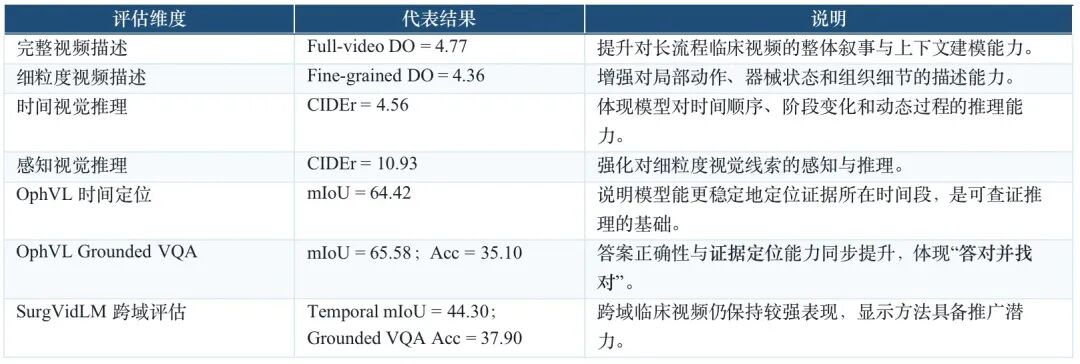
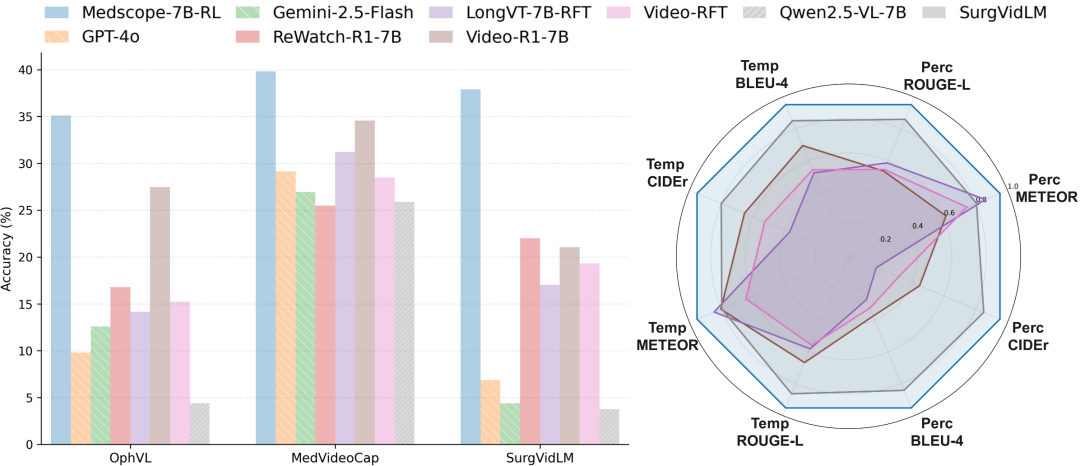
MedScope 在 full/fine-grained video understanding 与 grounded VQA 任务上的性能对比,体现其在长视频理解与证据定位上的联合优势。
更重要的是,MedScope 的提升不只是「回答更准」。在 Temporal Grounding 和 grounded VQA 中,模型需要同时给出答案并定位证据;这比普通问答更接近临床可审计需求。消融实验也表明,Visual CoT 冷启动、evidence reward 和 IoU bonus 缺一不可:去掉证据奖励后,即便答案看似正确,时间定位能力也会下降。
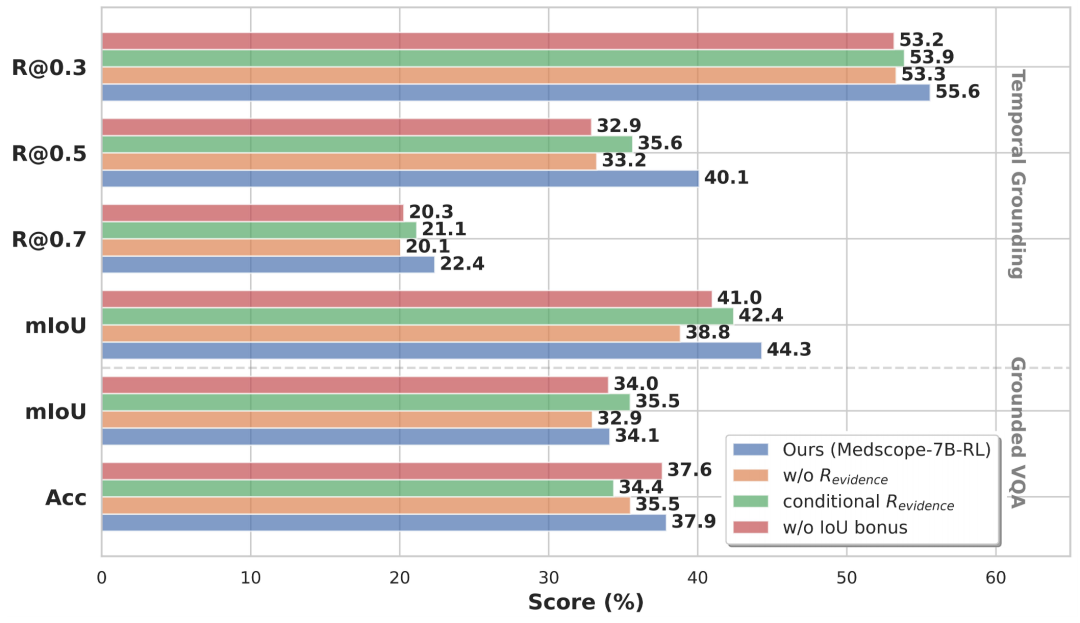
奖励设计消融:去除 evidence reward 或 IoU bonus 后,模型对关键时间窗口的定位能力下降,说明证据对齐奖励是方法提升的重要来源。
影响力:医学视频智能体的下一步,是把推理交还给证据
MedScope 的意义不止是刷新若干基准指标,而在于提出了一种面向临床视频智能体的新能力定义:模型不应只会理解视频内容,还应能主动提出证据需求、调用工具回看视频、定位关键片段,并把推理依据呈现给人类专家复核。
这种能力对于未来医学 AI 的落地尤为关键。无论是手术培训、术后复盘、医疗质控、机器人辅助手术,还是实时决策支持,模型的可信度都不能只依赖「它答对了」。更重要的是,它必须知道自己在哪里看到了证据、为什么这些证据足以支撑结论。MedScope 将医学视频推理从结果生成推进到证据查证,也为可审计、可交互、可部署的临床视频智能体提供了方法基础。
作者团队简介
第一作者李文杰为上海创智学院 LeapQuest 团队负责人,上海创智学院、上海交通大学、上海交通大学医学院附属瑞金医院联合培养在读博士生,主要研究方向为 Visual Reasoning、Multimodal Large Language Models 与 Medical AI Agents,共同第一作者张钰杰为上海创智学院、复旦大学联合培养博士生,主要研究方向为 Vision-Language Model Reasoning、Reinforcement Learning 与 Large Language Models。LeapQuest 团队目前在读博士 16 人,致力于以医学智能体驱动医疗场景效率跃迁。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。





