 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库蚂蚁万亿参数思考模型来了!实测AIME真题难不倒,会写爽文、规划出行
智东西(公众号:zhidxcom)
作者 | 杨京丽
编辑 | 李水青
智东西5月9日报道,今天,蚂蚁百灵大模型发布Ring-2.6-1T。这是一款面向
真实复杂任务场景
的
万亿级思考模型
,目前已上线OpenRouter,并开放
限时一周免费体验
,后续将正式
开源
。
Ring-2.6-1T加入了可调节的
Reasoning Effort机制
。开发者可以在high和xhigh两种推理强度之间选择:high面向
Agent、Coding、多步工具调用
等高频任务,强调执行效率和Token开销;xhigh则面向
数学、科研、复杂逻辑分析
等更难的推理任务。
从官方公布的数据看,Ring-2.6-1T high在PinchBench、ClawEval、Tau2-Bench Telecom等真实任务执行类评测中表现靠前,其中PinchBench得分
高于Claude-Opus-4.7 xhigh、GPT-5.4 xHigh、Gemini-3.1-Pro high
等模型。
Ring-2.6-1T xhigh则在ARC-AGI-V2、AIME 26、GPQA Diamond等高难推理任务中取得较高分数。ARC-AGI-V2得分77.78,
与Gemini-3.1-Pro high和Claude-Opus-4.7 xhigh处于同一水平
。
智东西也在第一时间围绕真实任务执行和高难推理两个方向进行了实测。
体验地址:
一、PinchBench得分高于Opus 4.7,3D鹈鹕却翻车了
在
真实任务执行类
评测中,Ring-2.6-1T high在PinchBench上得分87.60,高于Claude-Opus-4.7 xhigh、GPT-5.4 xHigh与Gemini-3.1-Pro high等海外大模型。
ClawEval得分63.82,领先Kimi-K2.6 Thinking、GPT-5.4 xHigh等模型,在可比模型中位居前列;Tau2-Bench Telecom达到95.32,与最高分模型差距不足1分。
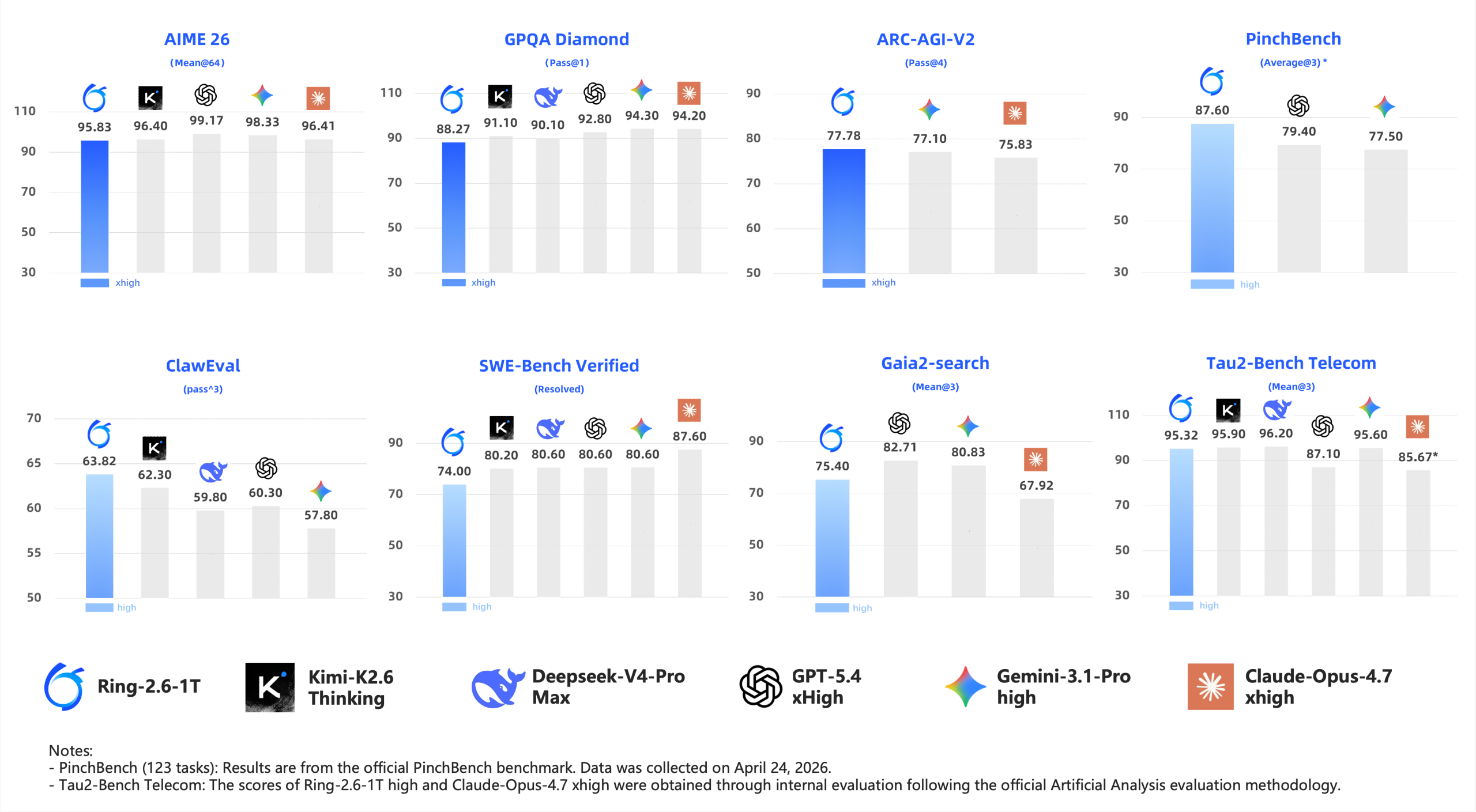
▲模型能力对比图(图源:百灵大模型)
为了观察Ring-2.6-1T在真实任务中的交付情况,我们首先测试了Ring-2.6-1T在
长文本创作任务
中的表现。我们让它生成一部长篇都市异能爽文的大纲和开篇正文,要求输出全书设定、100章大纲、开篇正文等内容。

▲Ring-2.6-1T创作的小说大纲及开篇
可以看到模型对于任务理解没有偏差,全书设定中包含
世界观、主角、能力规则、主要人物
等细节,大纲也比较详细,包含核心事件、爽点、反转和伏笔,正文的第一章很抓人,主角被解雇,还收到了分手短信,
迅速进入主题
,符合网络小说的要求。
之后我们提升难度,让Ring-2.6-1T完成一个
偏创意前端
的任务:制作一个“骑自行车的鹈鹕”的3D像素艺术作品。
第一次生成时,报错失败了。后面我们重新尝试,Ring-2.6-1T基本完成了3D像素艺术作品的主体搭建。它生成了完整HTML结构,并构建了天空、道路、树木、太阳、鹈鹕、自行车等元素。不过,原始代码中Three.js插件路径存在错误,手动修正后可以运行。
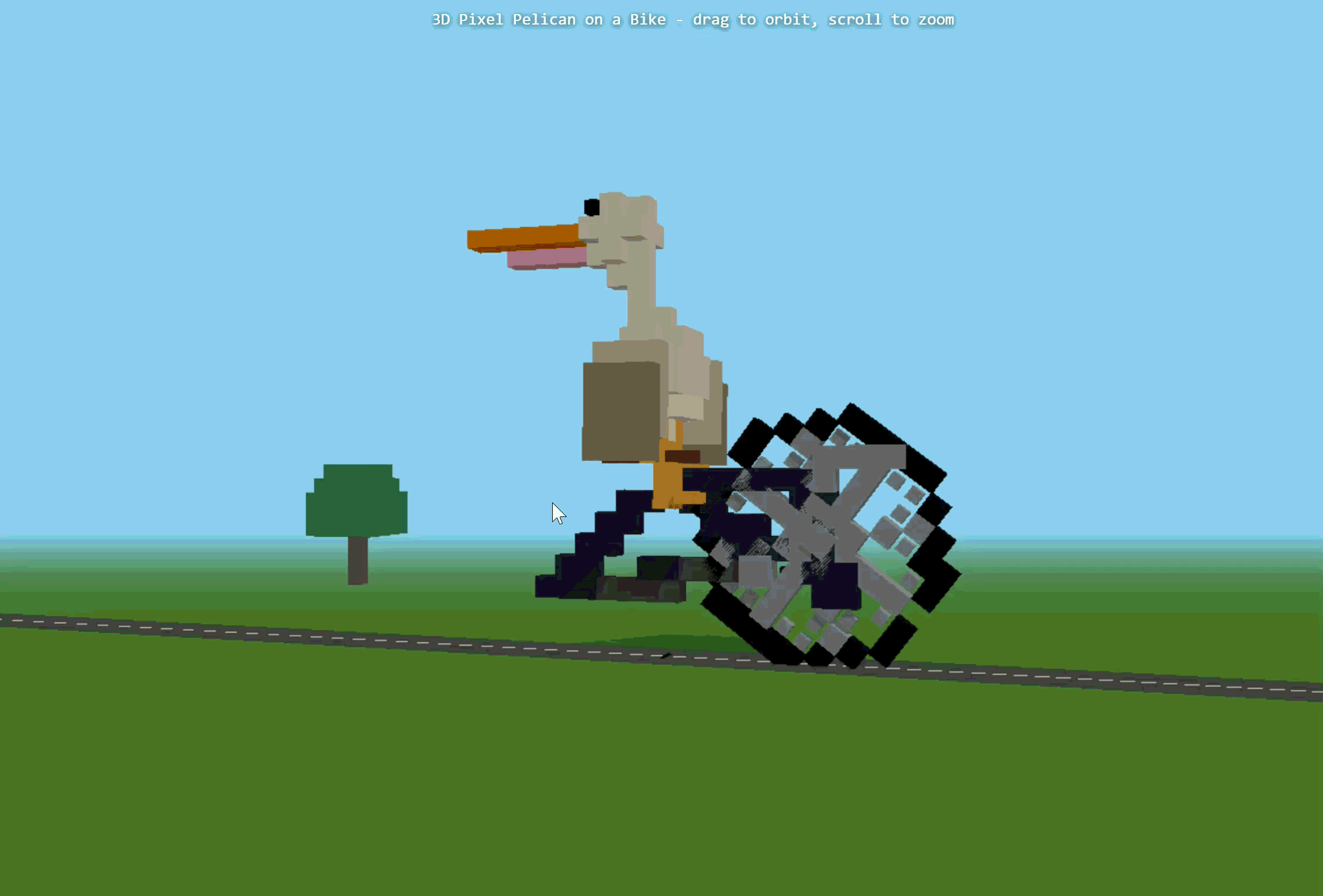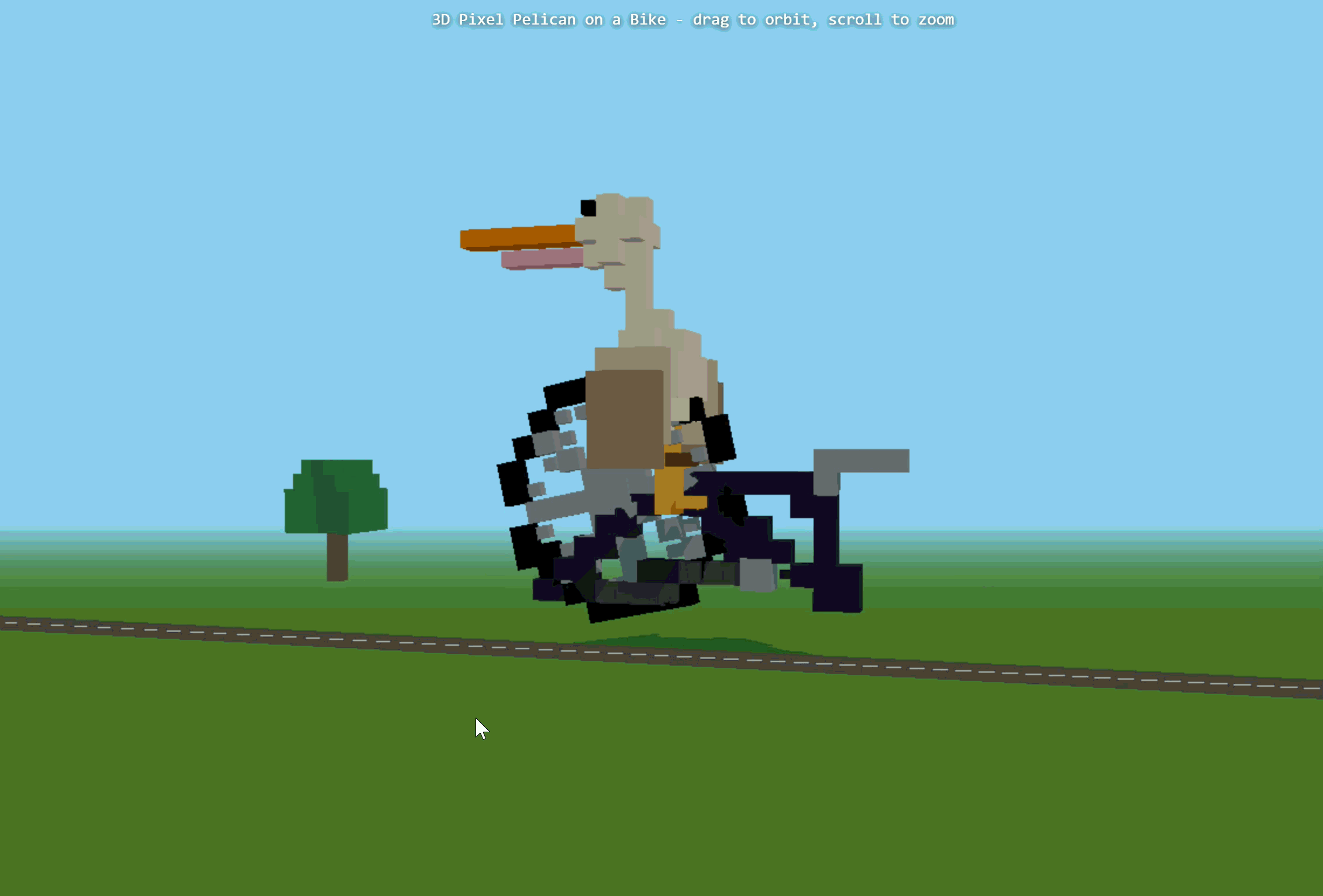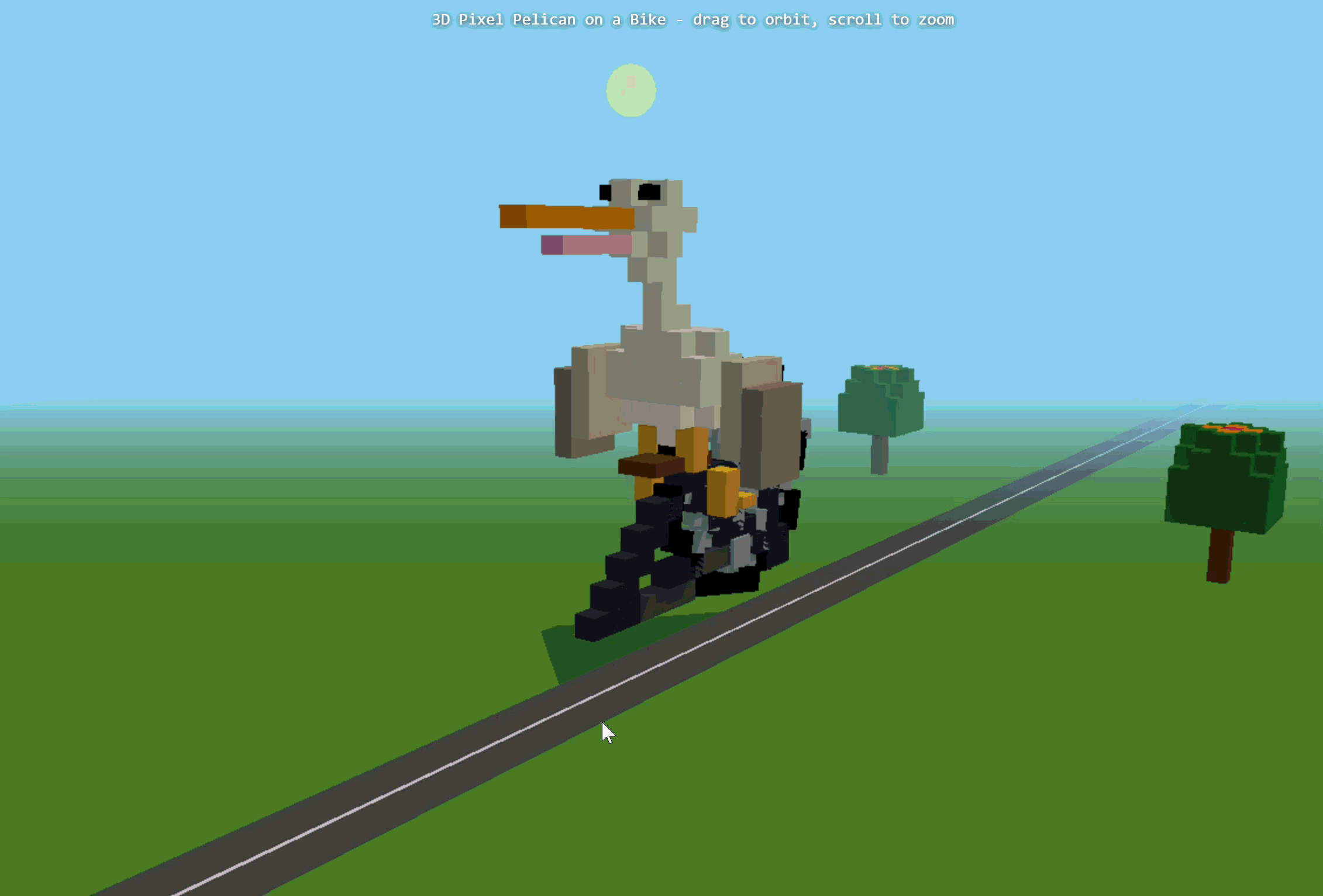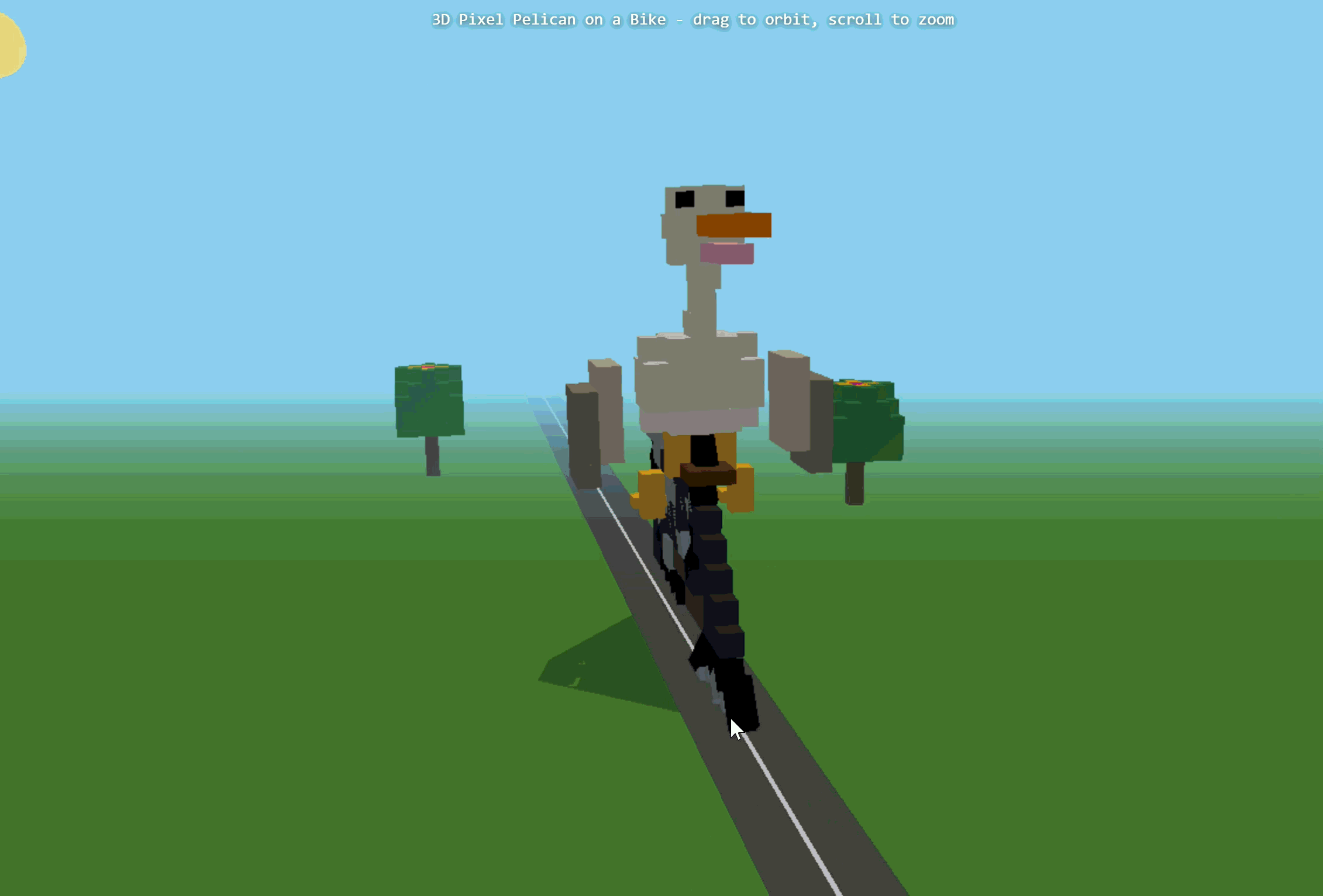
▲Ring-2.6-1T制作的3D像素艺术作品
从最终效果来看,模型
基本实现任务目标
,完成了3D像素艺术作品,可以跟随鼠标旋转,从不同角度观察作品。
不过,问题也很明显,我们可以看到画面中并非鹈鹕在骑自行车,而是自行车的两个轮子围绕中点旋转,模型
没有正确理解
“骑行”这一动作。另外,
画面比例
也存在问题,鹈鹕这一主体过大,树木和公路偏小,空间关系不够自然。
二、AIME真题1分钟答对,路线规划与地图推荐一致
在高难推理任务上,Ring-2.6-1T xhigh的表现更偏向能力上限,ARC-AGI-V2得分77.78,与Gemini-3.1-Pro high和Claude-Opus-4.7 xhigh处于同一水平;AIME 26得分95.83,GPQA Diamond达到88.27,覆盖抽象推理、数学竞赛和科学知识理解等任务。
为了验证其高难推理能力,我们首先选择了一道
AIME 2026真题
。题目如下:
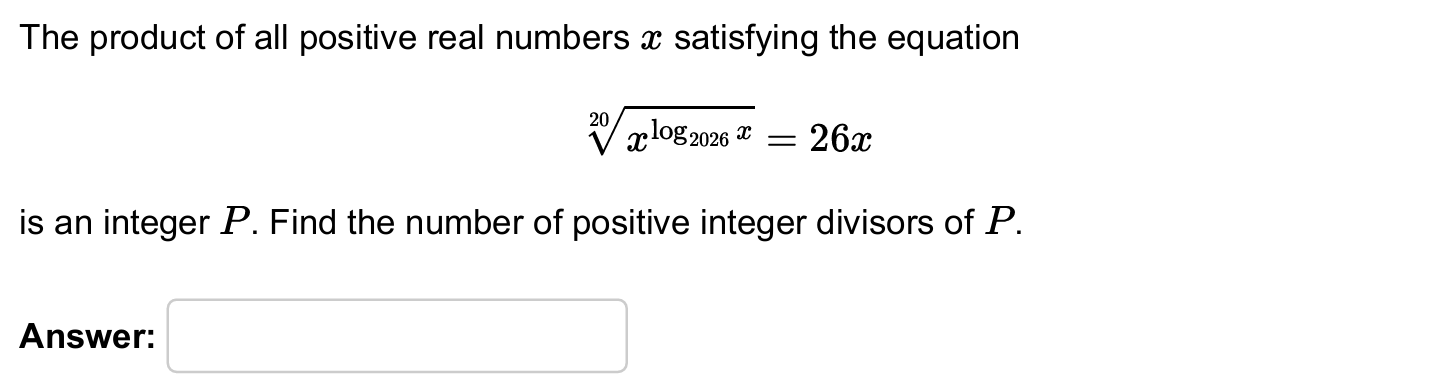
▲AIME 2026真题(图源:AIME)
这道题的正确答案为441,考察的是对数换元、指数方程、根与系数关系以及质因数分解,适合考察模型的推理能力。

▲Ring-2.6-1T的解题过程
Ring-2.6-1T很快抓住了题目的关键,分五个步骤解答这一问题,整个过程
仅用时1分钟左右
,就迅速得到了正确结果。模型在这一案例中表现很稳,说明其在标准数学竞赛题上的
推理链路和计算执行较为可靠
。
此外,我们还选择了一个
更贴近日常使用场景的推理任务
:从北京大兴机场乘坐公共交通前往首都机场。相比AIME数学问题,路线规划没有唯一的公式化解法,需要模型在交通方式、换乘路径、时间成本、票价等方面做出综合判断。

▲Ring-2.6-1T的路线规划
测试中,Ring-2.6-1T给出了两套方案,并用表格对比了主要工具、换乘次数、预计总时间和票价。其中,方案A为“大兴机场快线→地铁10号线→首都机场线”,与高德地图推荐方案一致。
方案B为“机场巴士→地铁换乘→机场快线”,稍显复杂。另外,模型没有进行网络搜索,不清楚两座机场之间还有个直达的机场专线,没有加上这一方案。仅根据地铁线路网来看,模型展现出不错的推理能力,最后还给出购票方式、应急方案等提示,考虑周全。
三、结语:会推理、能拆任务,交付细节仍需打磨
从实测结果看,Ring-2.6-1T高难推理任务上表现较稳,快速完成AIME真题推导,在路线规划这类日常推理任务中给出多种方案;在长文本创作任务中,它对设定、大纲、伏笔和开篇节奏的把握也较完整。
但在Coding任务和复杂前端任务中,模型仍暴露出细节问题,测试过程中还出现了几次失败的情况,希望后续可以进一步优化,提升模型在复杂工作场景中的任务执行能力。近期,模型将正式开源,届时开发者也能更深入地测试、部署和改造这一万亿级思考模型。





