五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库多智能体路由评测解析:指标与落地指南

核心结论前置:当前多智能体系统的路由评测,正从"任务完成率"单一指标,向效率—质量—成本三维联合评估演进。RouterBench、BFCL V4 和 MasRouter 等框架各有适用边界,但没有一个能开箱即用地覆盖真实企业场景。本文系统梳理评测维度体系、主流框架的实测数据表现与局限性,并给出选型建议。
问题的根源:路由评测为何如此棘手?
1.1 业务痛点
多智能体系统已逐渐从学术原型走向企业落地。医疗问答、代码生成、客服自动化、金融分析……越来越多的垂直场景在用多个专业 Agent 协作完成复杂任务。路由层——决定"哪个任务交给哪个 Agent、以什么拓扑结构协作"——直接决定了系统的最终表现。
然而工程团队普遍反映同一个困境:
调了半天的路由策略,换个数据集就崩。路由模型在内部测试集上准确率 92%,上线后实际意图覆盖度不足 70%。
指标好看,钱烧得也很快。某些路由方案把所有任务都推给最强模型,评分高但 Token 成本是"能用方案"的 3~5 倍。
没有统一的基准,方案之间无法横向比。A 团队说自己的路由准确率 95%,B 团队说自己 88%,用的却是完全不同的测试集和评分口径。
这三个痛点指向同一个技术缺口:缺乏覆盖"任务难度—资源约束—质量下界"的系统性评测方法论。
1.2 路由评测的独特挑战
普通模型评测已有成熟体系(MMLU、HumanEval 等),但多智能体路由评测面临三重额外复杂度:
第一,路由决策具有级联效应。路由错误不只是"这个任务做得差",而是会触发下游 Agent 的连锁失败。单跳任务中的误路由导致成功率下降 10%,在五跳以上的复杂工作流中,同等误路由率可能导致整体任务崩溃率超过 40%(Zhuge et al., 2024, GPTSwarm)。
第二,评测目标天然多目标。路由系统同时需要优化:任务完成质量(高)、延迟(低)、Token 消耗(低)、Agent 负载均衡(均匀)。这四个目标之间存在明显的取舍关系,很难同时做到最优。
第三,动态分布下的泛化问题。企业环境中的用户意图分布会随业务演进漂移,评测集固化于某一时间切面,模型在其上的表现不代表线上长期稳定性。
评测维度体系:比什么、怎么比
系统性的路由评测需要在四个维度上同时度量,缺一不可。
2.1 路由决策质量(Routing Decision Quality)
这是最基础的维度,衡量路由器"把对的任务送给对的 Agent"的准确程度。
核心指标:
Top-1 路由准确率(Routing Accuracy@1):在有标注的合成测试集上,路由器将子任务分配给最优 Agent 的比例。这是最直观的决策质量指标,类比分类任务中的 Top-1 Accuracy。
Top-K 召回率:最优 Agent 出现在路由器给出的 Top-K 候选中的比率,适用于系统允许多个 Agent 协同兜底的场景,衡量路由能力的上界而非单点决策的精度。
意图覆盖率(Intent Coverage):路由器能识别并正确处理的意图类型占总意图空间的比例,反映系统对业务场景的覆盖完整性,在企业级意图路由系统中尤为关键。
拒绝率(Abstention Rate):当所有 Agent 均不适合处理当前任务时,路由器主动拒绝分配的比率,在安全敏感场景中用于评估系统识别边界、避免错误兜底的能力。
决策一致性(Decision Consistency):对语义等价但表述不同的输入,路由器给出相同路由结果的概率,反映系统在用户输入多样化和多轮对话意图延续场景下的稳定性。
2.2 系统效率(System Efficiency)
路由的核心价值在于"用更低代价换等价结果",效率指标量化这一价值主张。没有效率维度,路由器的存在意义就无从证明。
核心指标:
Cost Reduction Rate(CRR,成本节省率):与全量使用最强模型相比,路由方案节省的 Token 费用百分比。RouteLLM(Ong et al., 2024)在 MMLU 上报告,其最优路由器在保持 95% GPT-4 质量的前提下,实现了约 40%~50% 的调用成本节约。需要警惕一个常见的评测陷阱:CRR 必须和任务质量指标联合解读。只报 CRR 而不报质量变化,和只报质量而不报成本,同样不完整。
平均路由延迟(Routing Latency):路由决策本身的耗时,通常要求 P99 延迟远小于任务执行时间。在实际工程中,一般的经验阈值是 < 50ms(P99),否则路由层本身会成为整个系统的延迟瓶颈。轻量级路由器(如基于嵌入分类的方案)在这个维度上天然占优,延迟通常在 10ms 以内;基于 LLM 推理的路由器(如让一个小模型判断任务类型)延迟往往在 100ms 量级,在高并发场景下需要额外的缓存和批处理设计。
Agent 负载均衡系数(Load Balance Score):衡量请求在各 Agent 之间是否分配均匀,避免出现个别 Agent 过载、其他 Agent 闲置的情况。常用的量化方式是各 Agent 接收请求量的变异系数(CV)或基尼系数,数值越低说明负载越均衡。这个指标在生产环境中的重要性常被低估。一个准确率高但负载严重不均衡的路由器,会在高峰期将大量请求压到同一个 Agent,导致尾延迟飙升,最终用户体验的损失远超路由准确率带来的收益。
协调轮次效率比(Coordination Efficiency Ratio):

比值越接近 1.0,说明路由越高效,越接近理论最优调度。这个指标的难点在于 Oracle 下界的获取——对大多数开放性任务,最优通信路径无法提前枚举。目前只在有限的合成数据集(如任务结构固定的数学推理、代码生成)上有实验数据支撑。
2.3 任务完成质量(Task Completion Quality)
路由是手段,最终质量是目的。此维度直接评估路由后任务的实际完成情况。
核心指标:
端到端成功率(E2E Success Rate):在多跳协作任务中,整个 Pipeline 最终完成率。这是任务完成质量的基础指标,也是当前最主流的代理性路由评测指标。AgentBench(Liu et al., 2023)提供了跨 8 类环境(OS 操作、数据库查询、知识图谱、网页购物、游戏等)的标准化测试框架,是当前评测多 Agent 完成能力的主要基准之一。GAIA、HumanEval、MATH、LiveCodeBench 等也被广泛用于多 Agent 路由的任务质量验证。
输出质量评分(Output Quality Score):使用 LLM-as-Judge 或人工打分,对路由后的最终输出进行语义质量评估。相比二元的"成功/失败"判断,质量评分能捕捉到"完成了但完成得一般"与"完成得很好"之间的差距。在具体实现上,GPT-5 或 Claude 4.6 Sonnet 等公认强模型作为评判模型已成为常见选择;评分维度通常包括准确性、完整性、相关性、格式规范性等。需要注意的是,LLM-as-Judge 本身存在位置偏差(position bias)和自我偏好(self-preference)问题,建议使用多模型交叉评判并报告一致性指标。
任务失败原因归因:区分"路由错误导致的失败"与"被路由 Agent 能力不足导致的失败",是评测闭环的关键。这也是当前最难解决的工程问题之一。一种可操作的近似方法:在失败案例中,将同一任务改为路由到最强 Agent(Oracle 路由),若结果转为成功,则判定为路由失误;若仍然失败,则归因为 Agent 能力边界。这种"反事实归因"需要额外的推理成本,但对于识别路由瓶颈具有重要价值。
2.4 鲁棒性与泛化性(Robustness & Generalization)
一个在测试集上表现优秀的路由器,在生产环境中面对真实用户输入的多样性和系统的动态变化时,是否仍然可靠?这一维度回答的正是这个问题。
核心指标:
OOD 性能(Out-of-Distribution Performance):在训练分布外的意图或任务类型上,路由准确率的衰减幅度。这是泛化能力最直接的量化指标。评测方法:将测试集按任务类型分层,留出训练集中未见过的任务类别作为 OOD 子集,单独报告 OOD 子集上的路由准确率,并与 In-Distribution 性能做对比。衰减幅度超过 15% 的路由器,在业务快速演进(新增意图类型频繁)的场景下风险较高。
对抗扰动下的稳定性:用户输入存在拼写错误(typo)、语序颠倒、语义歧义、口语化表达时,路由决策的一致性。具体评测方式参考:对同一批意图样本生成多种扰动变体(EDA 数据增强、Back-Translation、人工改写等),计算原始输入与扰动输入路由结果的一致率。一致率低于 85% 的路由器,在真实用户场景下通常会出现较明显的随机性问题。这个指标对基于精确字符串匹配或规则的路由器尤为关键——此类路由器对输入的微小变化极为敏感,而基于语义嵌入的路由器则相对更稳健。
冷启动表现:新 Agent 加入系统(zero-shot 场景)时,路由器无需重训即可正确引流的能力。这在业务快速扩张、频繁新增专项 Agent 的场景下是刚性需求。评测方式参考:在路由器训练完成后,向系统引入若干从未见过的 Agent(配合其能力描述文档),在不重新训练路由器的情况下,评测路由器将匹配任务正确分配给新 Agent 的比例。基于 LLM 推理(读取 Agent 描述做语义匹配)的路由器在冷启动上通常优于纯分类模型,代价是延迟和成本更高。
分布漂移适应性(Distribution Drift Adaptation):线上流量的意图分布会随时间演变(节假日、产品功能迭代、用户群变化等)。路由器在分布发生偏移后,性能衰减速率及恢复所需的重训成本,是衡量系统长期可维护性的重要指标。目前这一维度缺乏标准化评测方法,多数工作仅做离线快照评测,无法反映真实在线漂移情况。建议工程团队建立路由决策的线上监控(如滑动窗口内的路由分布熵、各 Agent 接收量环比变化),作为漂移预警信号。
验证过程设计:如何构建可信的路由评测
评测指标选好了,还需要回答一个更实际的问题:数据从哪来、指标怎么组合用、结果怎么解读。这三个问题对应评测设计的三个核心环节。
3.1 评测数据集构建原则
评测集的质量决定了评测结论的可信度上限。一个设计粗糙的评测集,即便你的指标体系再完善,得出的结论也无法指导实际决策。企业内部构建路由评测集,需遵循以下三条原则。
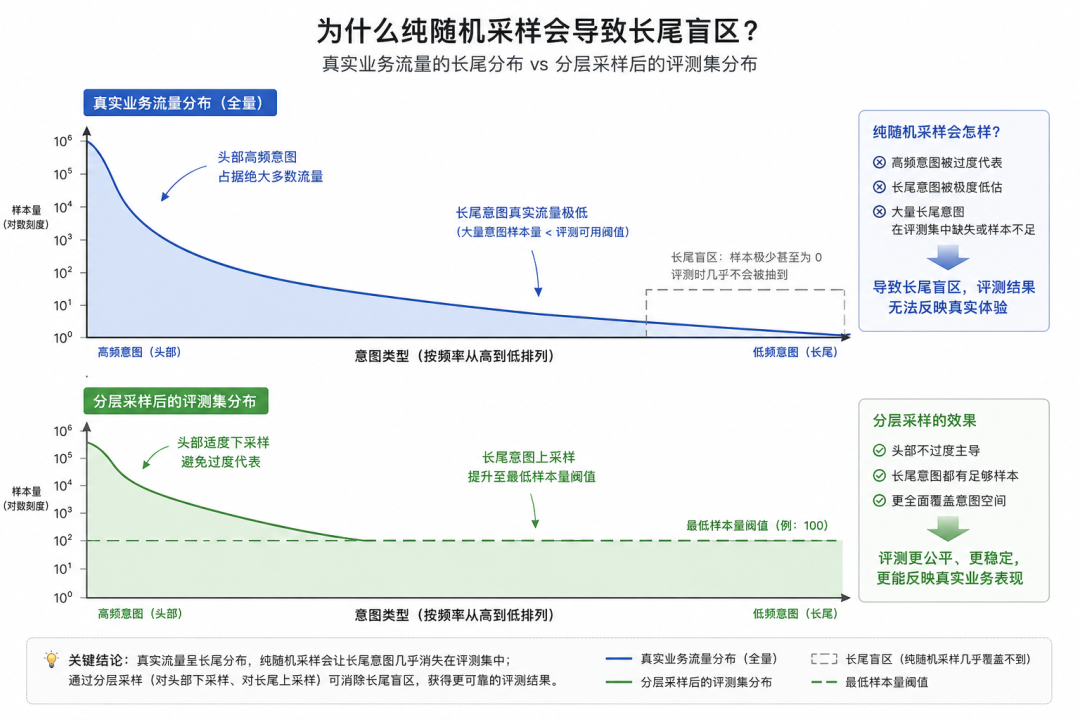
原则一:分层采样(Stratified Sampling)
按业务意图类型分层抽取样本,确保头部高频意图和长尾低频意图都有足够的代表性。建议的样本量下限:头部高频意图 ≥ 200 条/类,长尾低频意图 ≥ 30 条/类。
这背后的逻辑是:纯随机采样会导致评测集由高频意图主导,长尾意图的路由错误被平均掉,而恰恰是长尾意图的路由失误在生产中最难被发现、造成的用户体验损害也最集中。分层采样保证了对长尾场景的评测覆盖,是识别系统盲区的基础手段。
原则二:难度梯度标注
对每个样本标注难度等级(Easy / Medium / Hard),难度判定的参考维度包括:意图歧义度(单一明确 vs. 多义混淆)、跨领域混合度(单一领域 vs. 跨多个 Agent 职责边界)、所需推理步骤数(直接响应 vs. 多跳推理)。
评测报告必须分难度层次呈现性能数据,而不只报总体准确率。一个路由器在 Easy 样本上表现出色、在 Hard 样本上严重退化,和另一个路由器在三个难度层次上均匀表现,两者的总体准确率可能相同,但实际生产价值截然不同。难度分层是识别这种差异的唯一手段。
原则三:动态更新机制
评测集每季度从线上流量中采样新出现的意图模式,增量更新。静态评测集的主要风险是与业务真实分布的累积偏差——业务在演进,用户行为在变化,六个月前构建的评测集很可能已经无法反映当前的路由挑战。
一个可操作的工程实现:在线上路由层埋点,记录低置信度路由决策(置信度低于阈值 θ 的样本),定期人工复核并标注后补充进评测集。这类"路由器自己觉得没把握"的样本,往往是评测集中最有价值的困难样本来源。
3.2 评测指标的组合使用
单一指标的路由评测必然产生误导。只看准确率,会忽视成本失控;只看成本节省,会掩盖质量下滑;只看平均表现,会忽视长尾崩溃。推荐以下四层指标组合:
主指标: 端到端任务成功率(E2E Success Rate)
效率指标:Cost Reduction Rate + 路由延迟 P99
质量下界:Output Quality Score ≥ 阈值 τ(由业务方确定)
鲁棒性: OOD 意图路由准确率衰减幅度
这四层指标的关系是:主指标决定方向,效率指标衡量价值,质量下界是硬约束,鲁棒性决定能否上生产。一个路由方案,只有在质量下界约束满足的前提下,才值得比较主指标和效率指标;只有鲁棒性通过压测,才具备上线资格。
评测结论的输出形式建议以 Pareto 曲线(质量-成本) 替代单点数字。单点数字给决策者的信息是"这个方案好不好",而 Pareto 曲线给出的是"在不同成本预算下,可以选择哪些工作点(Operating Point)",后者才是真正可操作的决策依据。
一个常见的评测陷阱需要特别说明:在同一个测试集上同时做路由器训练和评测,会导致严重的数据泄漏——路由器实际上记住了测试集的分布,评测数字虚高。正确做法是严格的训练集/验证集/测试集三路划分,测试集在整个开发周期内保持封存,只在最终对比实验时使用一次。
结语:在混沌中建立评测秩序
多智能体路由评测今天的处境,和两年前 RAG 评测的处境高度相似——技术在快速落地,但评测体系的成熟度远远落后于工程实践。大量系统带着"任务完成率看起来不错"就上了生产,却对路由层真正消耗了多少成本、在哪些场景下会失效、Agent 缺席时会如何降级,一无所知。
这篇文章试图回答的核心问题只有一个:如何把"路由好不好"从一个主观判断,变成一个可以量化、可以对比、可以用来做决策的工程问题。
我们给出的答案可以浓缩为以下几个核心结论:
结论一:任务完成率是必要条件,但远远不够。 它解决不了归因问题——你永远不知道失败是路由送错了人,还是 Agent 本身能力不足。在任务完成率之上,至少需要补充成本效率和鲁棒性两个维度,才构成一个最低可用的评测体系。
结论二:Pareto 曲线比单点数字更有决策价值。 路由优化的本质是成本-质量权衡,单点数字掩盖了这种权衡关系。把不同路由策略画在同一张成本-效果散点图里,才能真正回答"我多花 20% 的成本,能换回多少质量提升"这类可操作的问题。
结论三:评测集的质量是评测结论可信度的上限。 分层采样、难度梯度标注、动态更新——这三条原则缺少任何一条,评测数字都会失真。尤其是长尾意图的覆盖,是企业级路由系统最容易忽视、也最容易在生产中暴雷的盲区。
结论四:鲁棒性指标决定能否上生产,而不只是锦上添花。 OOD 性能、对抗扰动稳定性、冷启动表现——这三类指标在研究论文里经常被省略,但在真实业务环境里,用户输入的多样性、业务意图的持续演变、Agent 的动态增减,恰恰是系统面对的常态。一个在干净测试集上表现优秀、但鲁棒性指标从未被测过的路由器,等同于一辆只在平整跑道上测试过的汽车。
结论五:多智能体路由评测的标准化体系,目前是研究空白,也是工程机会。 RouterBench 在单智能体路由层面做到了标准化数据集 + 统一对比协议 + AIQ 指标体系,但多智能体版本至今没有对应工作。这意味着现在做这个方向的团队,既要自己踩坑摸索,也有机会在方法论层面做出真正有价值的贡献。
对于当下正在落地多 Agent 系统的工程团队,我们的建议很简单:先把评测做起来,哪怕不完美。 从任务完成率 + 总 token 成本的双维度基线开始,画出你的第一张 Pareto 图,建立第一个分层评测集。评测体系的价值在于持续迭代,等待一个"完美的评测框架"出现再动手,代价是在没有度量的情况下持续优化一个你看不清楚的系统。
度量先行,优化才有方向。
参考文献
RouterBench:
Hu, Y., et al. (2024). RouterBench: A Benchmark for Large Language Model Routers. arXiv:2403.12031.
RouteLLM:
Ong, I., et al. (2024). RouteLLM: Learning to Route LLMs with Preference Data. arXiv:2406.18665.
MasRouter:
Chen, X., et al. (2024). MasRouter: Learning to Route LLMs for Multi-Agent Systems. arXiv:2412.18510.
AgentBench:
Liu, X., et al. (2023). AgentBench: Evaluating LLMs as Agents. arXiv:2308.03688. ICLR 2024.
GPTSwarm:
Zhuge, M., et al. (2024). GPTSwarm: Language Agents as Optimizable Graphs. arXiv:2402.16823. ICML 2024.
G-Designer:
Zhang, X., et al. (2024). G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks. arXiv:2410.11782.
AgentPrune:
Zhang, et al. (2024). Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems. arXiv:2410.02506.
LLM-as-Judge:
Zheng, L., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS 2023. arXiv:2306.05685.
Chatbot Arena:
Chiang, W.L., et al. (2024). Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. arXiv:2403.04132. ICML 2024.