五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库Z Waves|26岁,博士毕业10个月,陈博远带着13个人把GPT Image2打到了全球第一,领先第二名241分
GPT Image2以1512分出色成绩登顶Arena榜单,领先第二名241分,呈现出历史最大分差生成速度提升6倍,3秒出图,4K分辨率。英文、中文、韩文、孟加拉语的文字渲染准确率超过99%。这些数字的背后,是一位中国学者带领一支仅13人的团队,和一张从无锡到伯克利再到MIT的华人学术传帮带网络。他的名字叫做——陈博远。
这位年仅二十六岁、MIT博士毕业不到一年的年轻人,已然成为负责训练GPT图像生成模型的核心五个人成员之一,同时还是Sora视频生成团队的成员。他从高中夏令营里连Python语法都不懂的编程小白,到站在全球最强图像生成模型最前方的Research Lead——只用了十年。

图片来源: Boyuan Chen个人主页
高中时代16岁玩机器人,17岁遇上引路人
陈博远,2000年左右出生,他的高中时代在江苏省天一中学度过。2015年起,由于自身对智能机器人领域的无尽热爱,他选择去担任天一中学人工智能社的社长。在他的带领下,天一中学的机器人小队在全国乃至各类赛事中获得优异成绩,成为了一名在人工智能领域拥有深厚学术背景、坚定科研信念和抱负的青年学者。
2016年前后,16岁的他参加了FIRST Robotics Competition(FRC)。学校资源有限,但他每天花数小时设计机器人,带队完成比赛。同年5月,作为高二学生的他参加江苏省青少年科技创新大赛,凭借图像识别追踪无人机项目入围决赛。那时候他对AI还没有概念。连Python的基本语法都不熟悉,NumPy是什么更是闻所未闻。
真正改变他轨迹的,是高二那年参加的一个科研夏令营。在那里,他结识了后来成为Google DeepMind资深研究员的华人学者夏斐(Fei Xia)。对一个高中生来说,这种出色的动手能力和钻研劲头是藏不住的。夏斐作为已经在Google DeepMind工作的资深研究员,愿意花时间向一个高中生解释什么是深度学习,大概率是因为他看到了这个年轻人身上的好奇心和执行力——这是做研究最核心的两个素质。正因如此,一个当时连编程都不会的高中生,就这样被推入了AI世界的大门。

图片来源:新智元(中间陈博远,右一夏斐)
从夏令营里的偶然相识,促成了学术圈里最原始、最纯粹的师徒关系,而这段关系的起点,只是一个前辈愿意花时间去引导一个后辈观察,发现深度学习的世界。夏斐本身就是一个既做前沿研究、又愿意带学生的学者。夏令营对他来说可能只是一个短期的mentoring机会,但对陈博远来说,这是整个职业生涯的入口。
本科阶段18岁进伯克利,19岁创业,20岁进顶级实验室
2017年,陈博远从天一中学国际部毕业,进入加州大学伯克利分校(UC Berkeley)。他选择了计算机科学与应用数学双专业,进入竞争激烈的EECS荣誉班(EECS Honors),最终以3.96的GPA完成本科学业。
入学三个月后,18岁的他做了一件大多数新生不会尝试的事,他创办了机器人教育公司(Robot Locomotion Group Lab),为中小学生开发机器人竞赛相关的软硬件产品。这家公司从2017年11月一直经营到2020年3月,跨越了他本科的大部分时间。从想法到代码、从代码到用户、从用户到收入,他完整走了一遍。一个18岁的大学生,一边应付EECS荣誉班的双学位课程,一边经营一家面向中小学生的机器人教育公司——这种同时驾驭多件事的能力,后来在他同时操盘GPT图像训练和Sora视频两大项目时,几乎以更大的规模重演。

图片来源:MIT CSAIL Alliances
2019年1月,20岁的他进入伯克利人工智能实验室(BAIR),师从美国机器人学习领域的先驱Pieter Abbeel,从事深度强化学习和无监督学习研究。这段经历一直持续到2021年8月,几乎覆盖了他本科的后两年半。2021年,22岁的陈博远以双学位荣誉毕业,随后进入麻省理工学院(MIT)计算机科学与人工智能实验室(CSAIL)攻读博士学位。
至暗时刻
陈博远的博士生涯比绝大多数人都要紧凑——2021年9月入学,2025年完成答辩,不到四年,同时还辅修了哲学。但光鲜背后,他也经历过真实的低谷。读博第一年,22至23岁的他因论文产出陷入瓶颈,这是他整个学术生涯最艰难的阶段。
关键时刻,夏斐再次提供了决定性的帮助:协助陈博远发表了第一篇有影响力的研究NLMap,并邀请他到Google X与Google DeepMind参与两次实习。第一次实习在2022年5月至8月,23岁的他在Google X实习,表现出色到拿到了谷歌L4级别的return offer——但他选择了decline,继续深耕学术。第二次实习在2023年5月至8月,24岁的他来到Google DeepMind,在夏斐指导下主导搭建了基于大规模合成数据的多模态大语言模型(MLLM)数据合成管线,其总结的指令微调技术后来被Gemini2.0直接采用。
在MIT期间,他发表了多篇在学术界和工业界均获得认可的研究。其中博士代表作“Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion”入选NeurIPS 2024,提出了一种全新的序列生成训练范式,将逐token独立噪声级扩散与因果下一个token预测结合。他还以共同一作身份发表了“SpatialVLM”,通过自动构建互联网规模的3D空间推理VQA数据集(1000万图像、20亿QA对),为视觉语言模型赋予定量空间推理能力,可从单张2D图像输出米制距离、尺寸、方位等精确数值,将思维链空间推理应用到了具身智能领域。
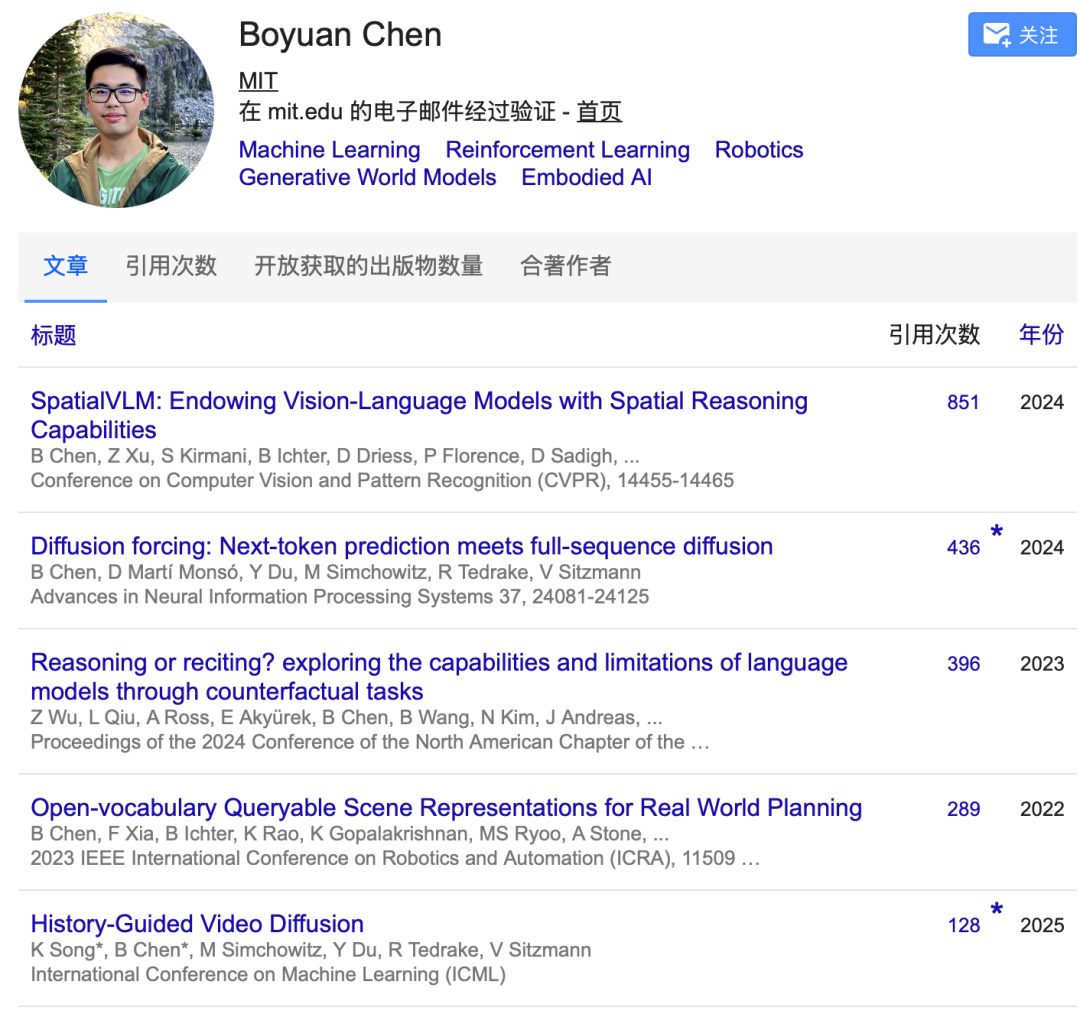
图片来源:Google scholar
值得一提的是,在此期间,陈博远遇到了两位出色的学者作为他的导师,他们分别是:1)Vincent Sitzmann,作为MIT EECS助理教授,领导Scene Representation Group(场景表示研究组),2)Russ Tedrake,作为MIT Toyota讲席教授(横跨EECS、航空航天、机械工程三个系),领导Robot Locomotion Group(机器人运动研究组)。这两位导师对他的影响十分深远。Vincent Sitzmann的“世界模型”研究思路——让AI通过心理模拟器预判物理世界的变化,而不只是单纯模仿像素——直接影响了陈博远后续在OpenAI的技术方向。在陈博远的读博期间,Sitzmann帮助他探索把扩散模型和序列生成结合起来的方法,让模型理解并分析时序和空间上的因果逻辑,从而更好的生成更高质量的内容。两人联合发表了《History-Guided Video Diffusion》和《Large Video Planner》两篇论文。
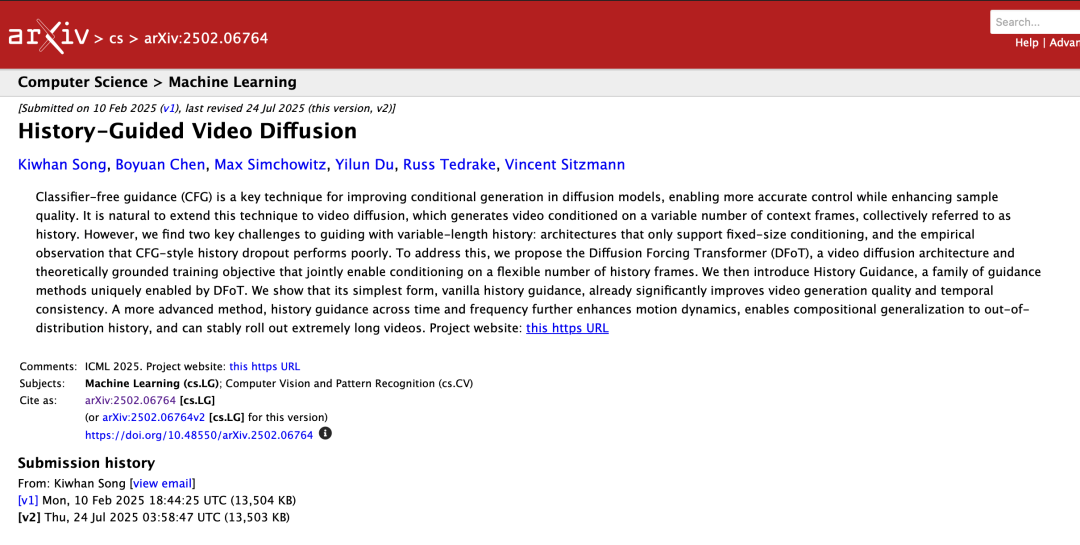
图片来源:arXiv
Russ Tedrake则教会了他研究的“延迟满足”:陈博远曾回忆,自己最初总想尽快投稿,但Tedrake会告诉他,“我知道你能把这篇论文投中,但我们应该再打磨一下,推迟提交。”那些被推迟提交的作品,后来都收到了前所未有的好评。Tedrake还教会他欣赏他人的工作、强调自己算法的优势而非别人的局限——这种心态帮助他建立了真正有影响力的研究基础。
2025年,不到26岁的陈博远完成MIT博士答辩。辅修哲学的他,在研究之外也保持着对技术与人类关系的深层思考。他在个人博客中写道:“我可以负责任地告诉大家,具身智能一定是下一个一百年最令人激动的技术,并且我们在有生之年很有希望见证通用机器人的诞生。”
OpenAI时代—从Sora到GPT Image 2的架构重构
2025年6月,博士刚毕业的陈博远加入OpenAI,迅速成为GPT图像生成核心五人研究团队之一,负责GPT图像生成模型的所有训练,同时也是Sora视频生成团队的一员。在演示中,他给家乡无锡做了一张海报。然后为来自首尔的队友做韩文海报,为来自Bangladesh的队友做孟加拉语海报。每一张中的文字渲染都精准无误。
十个月后,2026年4月,GPT Image2发布。发布会现场,陈博远和Sam Altman同台主持,演示了文字渲染能力。但他在知乎博客里自嘲了一句:“多语言能力是直播后半节,国内媒体好像并没有发现只有我才是国人QwQ。”这句带表情符号的自嘲背后,是一个值得玩味的细节——在那支13人、华人过半的团队里,真正站到前台承担训练和能力展示核心角色的,是他。

图片来源:陈博远的知乎博客
发布后不久,陈博远在知乎发了一篇博客,标题非常直接:“我在OpenAI修中文。”开头更直接:“大家好,我是GPT Image团队的研究科学家陈博远。上周发布的GPT生图模型就是我主力训练的!”这篇博客不是技术论文,更像一个幕后花絮。但他透露的信息量足够让外界理解,GPT Image2为什么能做到99%的字符准确率。
解题思路发生了改变,旧方法是把文字当图形画,随机噪声还原成像素,“看起来像字”就行。GPT Image2把文字当语言生成,一个token接一个token,图像和文字共用同一个生成流程。对语言模型来说,输出“好”和输出任何语言的字符一样可靠。这个思路,和陈博远2024年在NeurIPS发表的论文《Diffusion Forcing》高度呼应。那篇论文的标题就很直白:Next-token Prediction Meets Full-Sequence Diffusion。翻成大白话,就是让“一个token接一个token的结构能力”和“扩散模型处理连续细节的能力”接上。他的学术工作,直接影响了他主力训练的这个产品。
陈博远在博客里还解释了一个更有趣的细节:整个官网blog的所有图片,都是用模型生成的,完全没有普通文本。而他亲手做了其中大部分。那张中文彩蛋漫画,是他想做一个“很搞笑的漫画”,用到了“接住梗”和“香蕉梗”。为了展示文字能力,他特意让模型在图里加入多国语言文字,又在家乡海报的右下角生成特别特别小的中文,用来测试模型到底能处理多细的细节。更关键的是,这张图不是拼接出来的——整张图,包括画中画和画中画中画,都是一次性生成的。他担心大家以为这是拼接图,还特意在图底加了备注。

图片来源:陈博远的知乎博客
还有这张米粒刻字图。4K分辨率,画面里是一堆米粒,其中一颗米粒上刻着字。这测试的是模型在极小尺度里的文字控制能力。以及黑板视觉证明——用视觉方式证明数学定理。每一张看似宣传物料的图片,其实都是一次次有设计目的的能力测试。

图片来源:陈博远的知乎博客
在博客最后,他特别感谢了整个团队。他说,每个人都做了很多很多的事情。在发布前的尾声,他除了修一些小东西,就是和市场部门的同事、做艺术的同事一起准备发布会和网站。GPT Image2是一次研究、产品、审美和传播的共同完成。
布基胶带
GPT Image2在正式发布前,用代号“duct-tape”在LMArena上进行了双盲测试。这个代号是陈博远自己起的。“至于为啥起名叫布基胶带嘛,”他在知乎博客里写,“当然是因为你可以用布基胶带把香蕉贴在墙上啦!”——指的是那幅世界闻名的艺术品,一根香蕉用布基胶带贴在墙上。
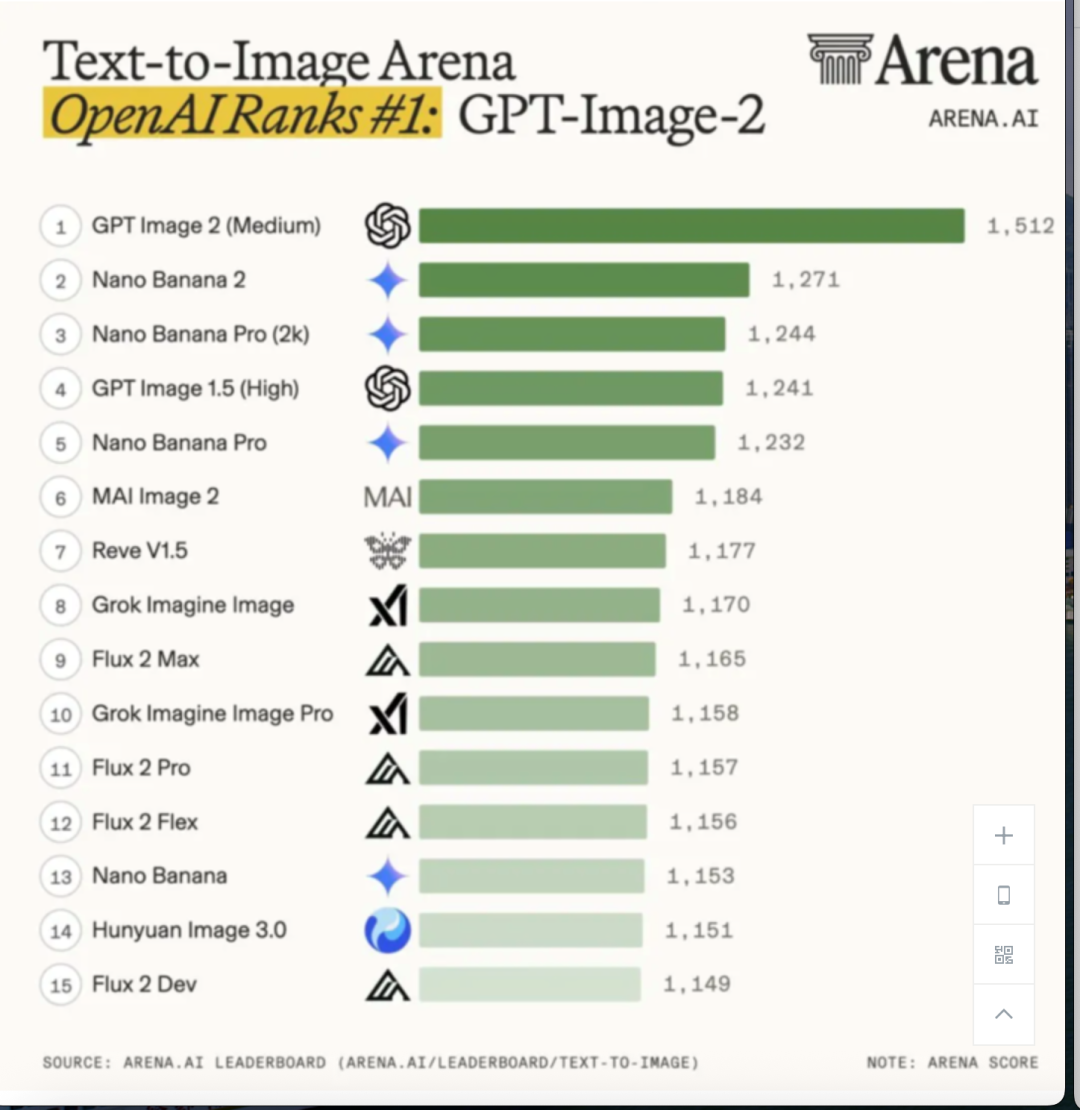
图片来源:陈博远的知乎博客
结果是:布基胶带以ELO+242分断崖领先第二名,代号为“小香蕉”(nano banana)。+241分是LMArena图像竞技场有史以来最大的领先差距,没有模型曾经以这个幅度超过第二名。这不是小幅迭代,是架构级别的跳跃。陈博远自己在博客里也确认,从去年12月底的GPT Image1.5算起,只用了四个月就有如此大的改进。但是底层架构已经彻底重构,核心团队只有13人。

图片来源:Gabriel Goh的Twitter
团队负责人Gabriel Goh在社交媒体上晒出了一张团队成员AI全家福。全员亚裔,华人过半。评论区有网友感叹:怎么全是亚洲人?这个问题本身可能比任何技术论文都更能说明当下的AI权力格局正在发生的变化。陈博远身后那张由夏斐、Pieter Abbeel、Russ Tedrake、Vincent Sitzmann等一代代学者搭建起来的华人学术传帮带网络,不是血缘关系,是知识关系——是无数个“他就像我的吴恩达”的链条叠加在一起,最终把一批二十多岁的年轻华人研究者,推到了全球AI创新的最中央。
从16岁在FRC赛场上设计机器人的高中生,到26岁带队重构全球最强图像生成模型的Research Lead,陈博远用十年时间走完了这条路径。而视觉世界模型对于具身智能至关重要——这是他反复强调的信念。当AI不仅能生成逼真的画面,还能理解物理世界的运行规律时,通用机器人的诞生才真正有了时间表。
从16岁在FRC赛场上设计机器人,到26岁站上OpenAI最核心的图像生成团队,陈博远只用了十年。但他最特别的地方,或许并不是“天才”——而是一种很少见的、始终愿意从零开始的研究者气质。高中时不会Python,读博第一年经历低谷,进入OpenAI后又重新“修中文”、重新思考图像与语言的关系。
他不像那种锋芒毕露的明星科学家,反而更像一个对世界始终保持好奇的人:认真到会在一粒米上测试模型能不能刻字,也会为了一个香蕉梗给模型取名“duct-tape”。而这种近乎执拗的好奇心,也许正是他一路走到今天的原因——真正推动AI向前的人,很多时候并不是最会讲故事的人,而是那些愿意反复追问“机器到底有没有真正理解世界?”的人。
[1] 新智元,来自MIT最强AI实验室:OpenAI天才华人研究员博士毕业了,https://www.36kr.com/p/3470460912801156
[2] 量子位,半壁华人!GPT Image 2团队曝光:无锡才俊带队,https://www.qbitai.com/2026/04/405391.html
[3] 爱范儿,起底GPT Image 2 团队后,我扒出了一张华人师徒网,https://www.ifanr.com/1663499
[4] MIT CSAIL,Boyuan Chen Spotlight,https://cap.csail.mit.edu/engage/spotlights/boyuan-chen
[5] 虎嗅,实测ChatGPT最新生图模型三大发现,https://www.huxiu.com/article/4853320.html
[6] 江苏省天一中学,天一校友风采| 陈博远:OpenAI天才华人研究员,https://www.tyzx.com.cn/gjjy/jsfc2
[7] Boyuan Chen个人主页,https://www.boyuan.space/
[8] Boyuan Chen个人主页Resume,https://www.boyuan.space/resume

稿件经采用可获邀进入Z Finance内部社群,优秀者将成为签约作者,00后更有机会成为Z Finance的早期共创成员。