五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库一文汇总:近期推荐模型Scaling工作

在之前的文章中,我们介绍了包括RankMixer、Longer、OneTrans等推荐模型Scaling的相关工作。最近半年,沿着这个思路业内又出现了一系列相关工作,这篇文章给大家做一个简要汇总,涵盖字节、腾讯、阿里等多个大厂的最新统一推荐模型建模方法。
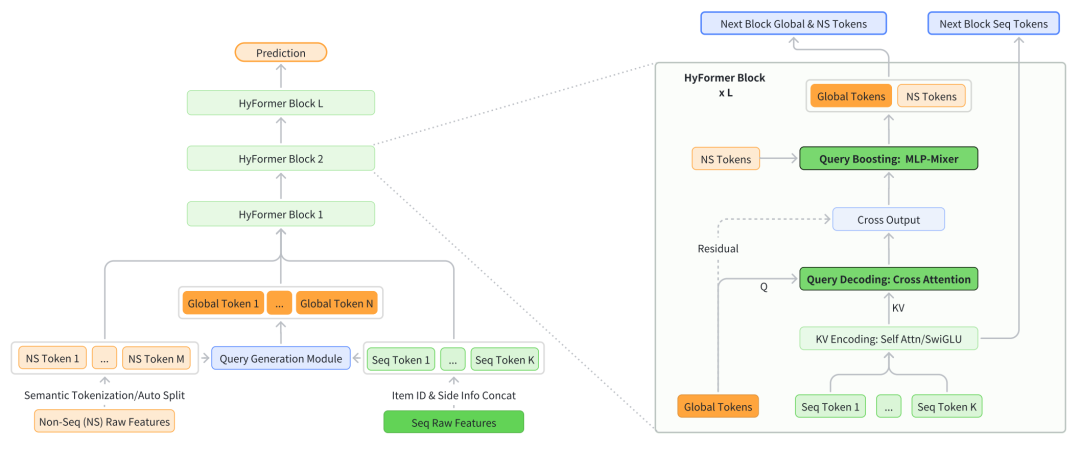
论文标题:HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction
Hyformer的核心是将原来的先序列建模,再将序列建模表征和基础特征表征拼接后过RankMixer特征交叉模块的两阶段建模范式,升级到了统一的序列建模+RankMixer建模。基础方法先用序列建模提取序列表征(比如Longer,把序列信息压缩到一个表征上),然后使用RankMixer进行序列表征和其他表征信息的交叉。端到端的方法可以同步建模基础特征和序列建模的信息。
将所有基础特征,以及序列特征的pooling结果,拼接到一起过MLP映射成多个Global Token,每层会用其中的一个Token作为那一层的Query。在每一层里,会先用Global Token和各个序列Token做cross-attention,生成的结果就包括了序列信息。这里面序列Token的生成方法文中采用了多种类型可选,包括类似Longer的方法、Transformer的方法、FFN的方法等,生成各个序列token。得到序列cross-attention的表征之后,把NS Token和这些序列token拼接到一起过RankMixer的结构,实现序列特征信息和基础特征信息的交叉,输出结果作为下一层的GlobalToken和NS Token。
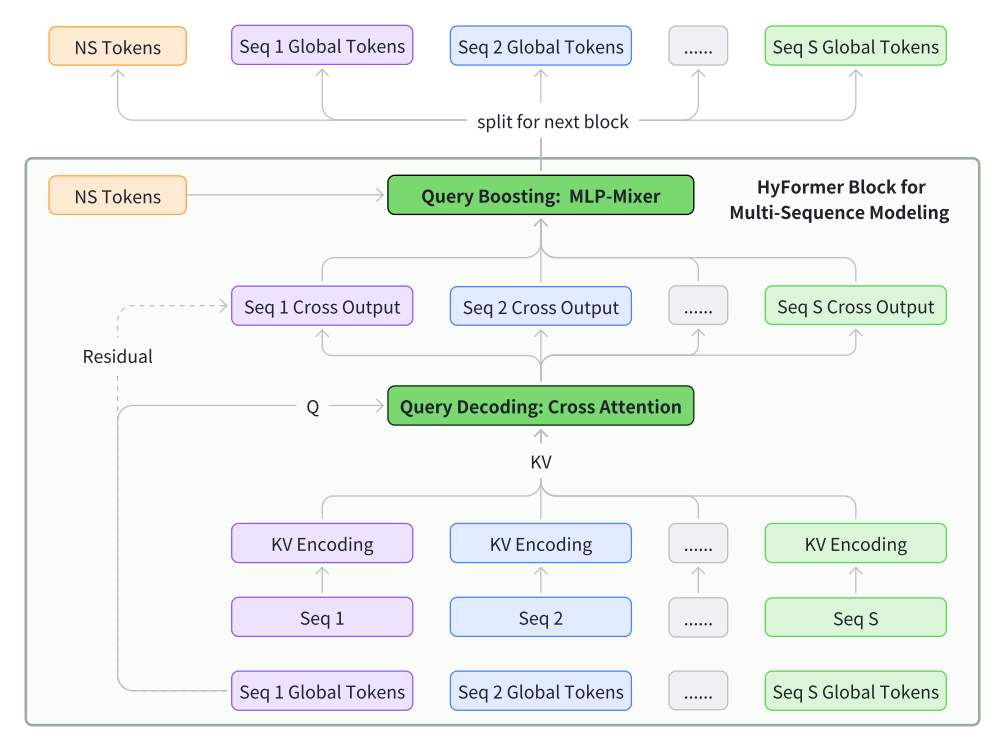
多序列建模中,文中没有进行直接的拼接,而是每个类型的序列单独走一遍这个流程,文中发现序列直接拼接到一起效果会衰减。
相比OneTrans最大的区别就是把RankMixer结构和OneTrans结构融合到了一起,OneTrans还是完全靠attention进行信息融合,HyFormer除了cross-attention之外每层增加了RankMixer结构
论文标题:MixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders
Mixformer的建模出发点和Hyformer类似,也是统一序列建模和RankMixer等特征交叉模块。主要包括Query Mixer、Cross Attention、Output Fusion三个模块。
Query Mixer的主要目的是在各个query内部进行信息交换,这里主要用RankMixer结构替代一版的Self-attention,核心是因为推荐系统各个token信息id空间很大而且异构,比较难通过内积的方式建立起各个token之间的关系。
Query Mixer的各个结果会作为多个head的query,和用户序列进行cross-attention。每一层的序列表征使用不同的hidden layer对原始输入序列进行映射,每层的序列表征不一样,不像基础Transformer每层的序列表征相同。
Output Fusion:每个query结果用一个per-token FFN映射得到这一层的各个token的输出表征。
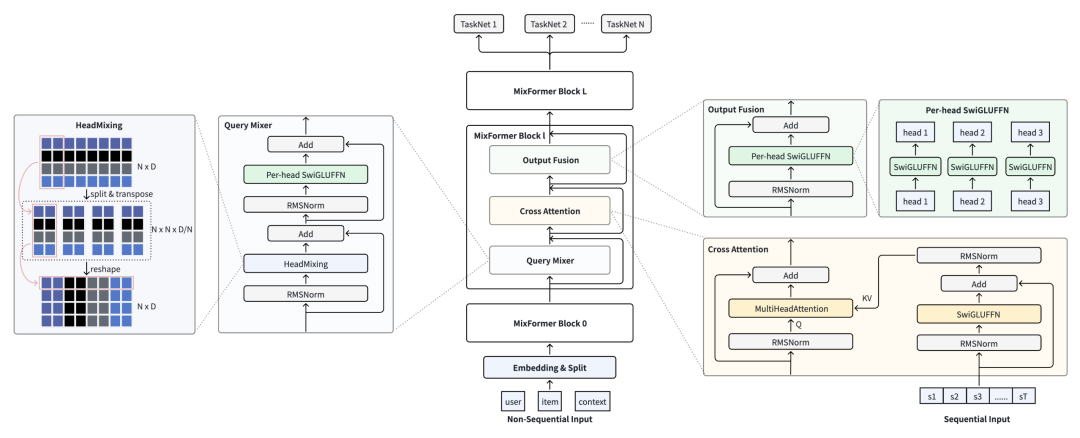
和HyFormer的核心区别在于,HyFormer是先做cross-attention再通过Rankmixer做特征融合,MixFormer是先做query之间的Rankmixer信息融合再作为query进行cross-attention。
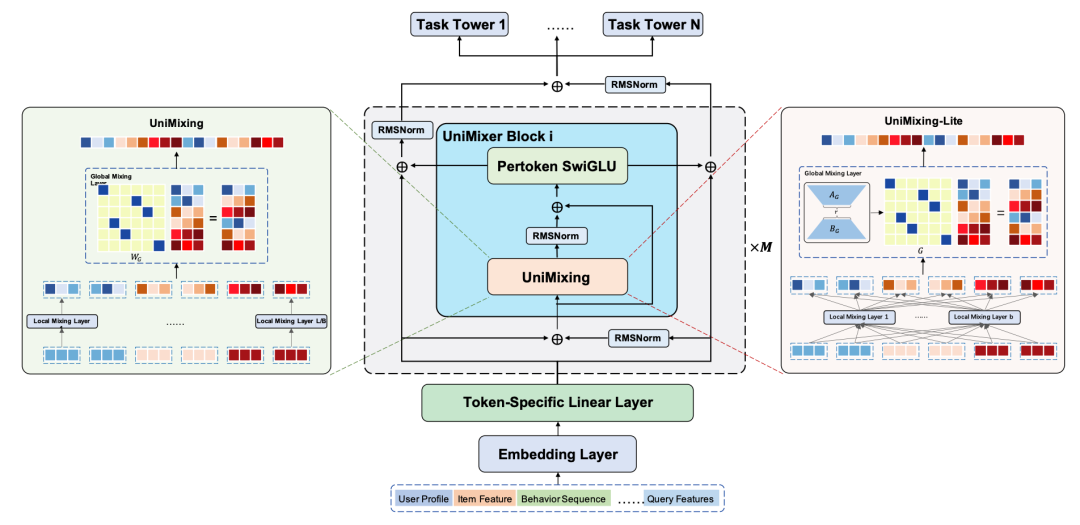
论文标题:UniMixer: A Unified Architecture for Scaling Laws in Recommendation Systems
这篇文章的核心是对RankMixer的结构进行了一个泛化,原来RankMixer是进行了类似人工规则的交叉,把每个token的部分维度进行交换。这可以看成是一个更一般的形式:把所有token平铺后,用一个W矩阵进行映射,并且这个W具有一定的稀疏性、对称性等,实现一种可学习的特征维度交换。
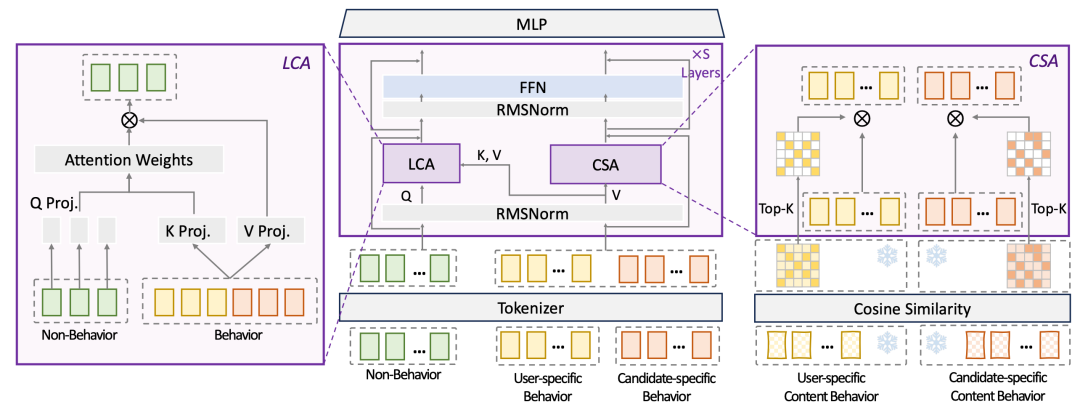
EST也是统一序列和非序列特征的建模方法,并结合了内容表征的使用。文中首先通过实验验证attention哪些部分比较重要,讲序列特征和非序列特征拼接成一个序列过self-attention,其中非序列到序列的cross-attention部分attention分最大且mask掉后效果损失最大,其他部分损失不大,说明这部分信息是最重要的。其次验证内容表征的作用,相比当sideinfo直接加到模型里,或者做成semanticid,使用SImTier的方式进行序列softsearch的效果最好。
基于上述吻戏,EST的核心是LCA和CSA两个模块,LCA进行非序列特征和序列特征的cross-attention,CSA进行多模态表征到模型内的融合。CSA模块使用多模态表征,进行序列内部的类似self-attention的计算,刻画上下文信息,只计算topK减少计算量。
论文标题:LoopCTR: Unlocking the Loop Scaling Power for Click-Through Rate Prediction
LoopCTR从一个新的出发点研究推荐模型的Scaling-up:如何实现参数不涨但是循环利用这些参数进行scaling up,同时这种循环利用参数的方式还能缓解过拟合。
具体建模方法上包括Entry Block、Loop Block、Hyper-Connected Residuals、MoE-Augmented等几个模块。
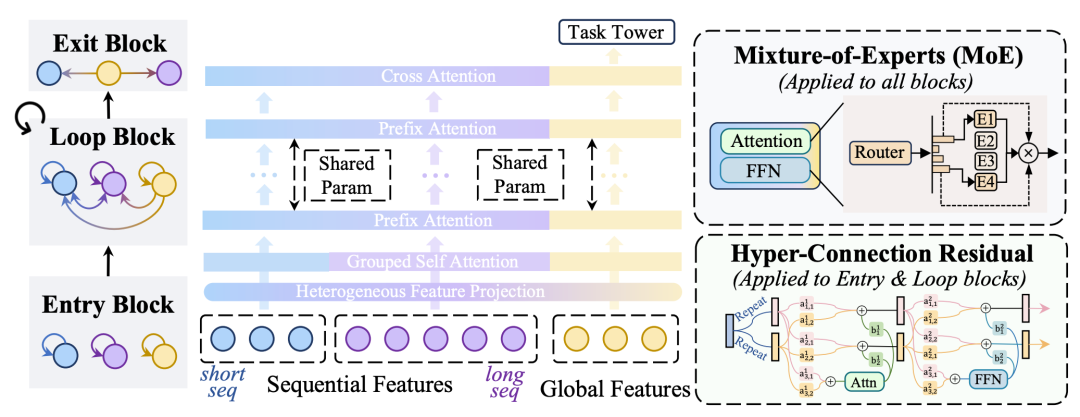
Entry Block将多组特征用pertoken-ffn进行映射,每一组内使用一个self-attention独立处理。
Loop Block未多层的attention模块,global token可以和所有特征做attention,序列token只跟序列做attention,类似unimixer的方法。这里面使用Hyper-Connected Residuals、MoE-Augmented增强参数共享下的表达能力
Hyper-Connected Residuals把基础的h+f(h)的残差建模升级,h复制多份,attention还是算一次(H通过Am融合成一个);也是 Manifold-constrained hyper-connections这个论文里提的一个方法
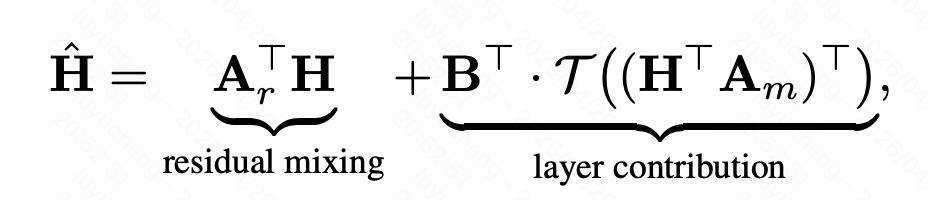
此外,文中在FFN引入MoE,Attention中的Value映射部分也引入MoE,QK不变
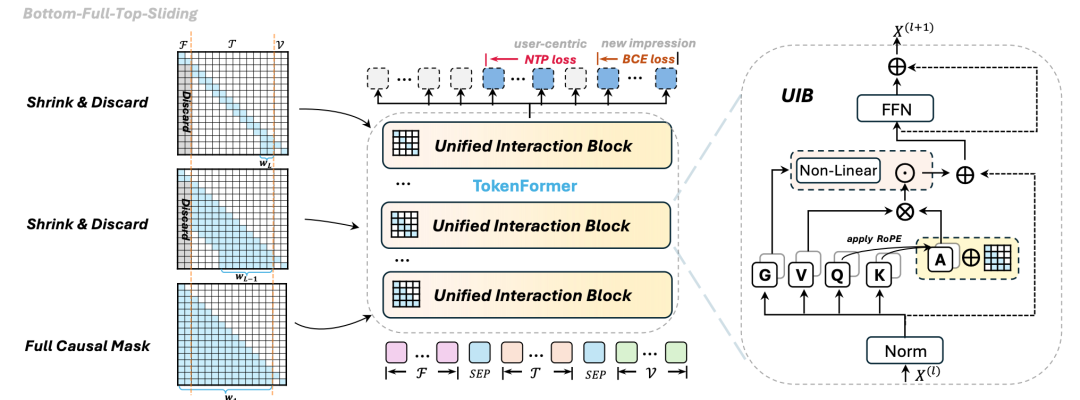
论文标题:TokenFormer: Unify the Multi-Field and Sequential Recommendation Worlds
这篇文章主要针对的是目前大多数基础特征、用户序列统一建模方法的问题。通过分析发现,相比使用Transformer单独进行序列建模,使用Transformer同时进行序列+静态特征的建模会导致序列表征坍缩,具体表现为主成分分解结果偏向头部,信息集中在头部的少数主成分上。
本文提出了一种新的统一特征和序列建模方法。在底层,降用户序列特征、静态特征、item侧特征以token形式组织拼接到一起,上层以Transformer为主,进行三类特征完全的交互。核心的改进点主要是2个方面,一个是attention的计算上,为了节省计算性能,构建了sliding-window attention的结构,每个token只和附近的几个token计算attention。并且sliding-window尺寸从浅层到深层逐渐缩小,最开始的几层仍然是全局attention进行充分的信息交互,上层采用sliding-window并逐渐缩小尺寸。同时,在深层会将静态特征的token移除。另一方面,在attention计算上,文中引入了Gate的方式提升attention输出结果的表达能力,缓解坍缩问题。