 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库26年5月26日,全球AI资讯约15条:AI首次独自跑完芯片设计 219词进7nm图纸出、华为具身大脑一号位朱森华创业 具脑磐石获亿元级融资等

昨日,AI领域发生了多项重要事件和进展,共计约15条汇总如下。
AI应用进展和演化
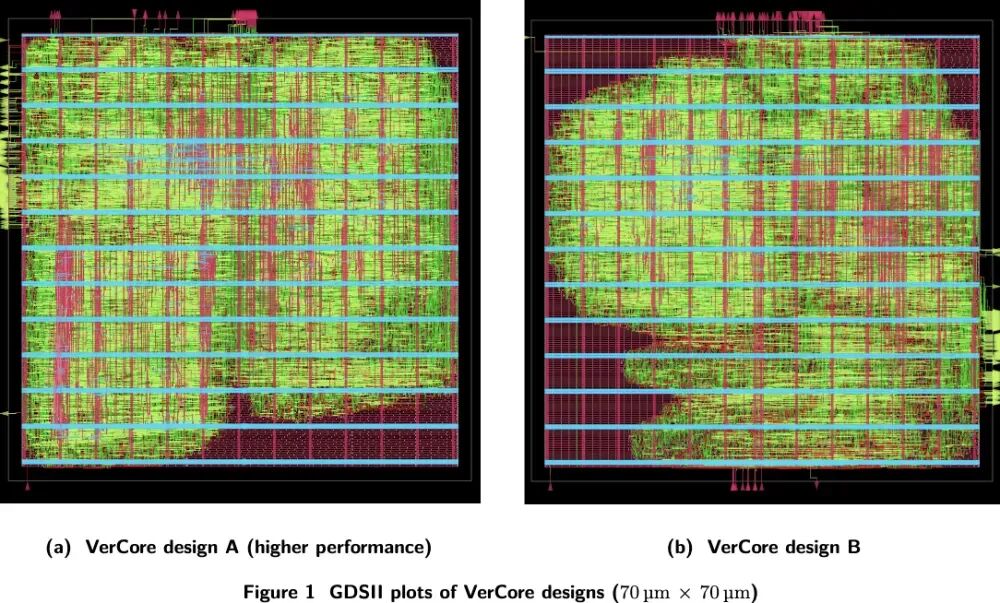
1-1. AI首次独自跑完芯片设计!219词进7nm图纸出,工程师全程没碰键盘
Verkor公司近日发布了一项突破性进展:其AI系统“Design Conductor”仅用12小时,就将一段219词的英文需求描述(如“设计一颗RV32I+ZMMUL、5级流水线、目标1.6GHz的RISC-V CPU”)自动转化为7nm工艺(ASAP7 PDK)下可交付流片的GDSII版图——全程零人工干预。
生成的CPU“VerCore”面积仅2809 μm²,主频1.48GHz,CoreMark跑分3261(约相当于2011年Intel Celeron SU2300),虽无缓存、未流片,但意义不在性能,而在首次打通从自然语言到物理版图的全栈AI设计闭环。该系统并非单一大模型,而是一个由多个专业子Agent协同的LLM编排框架,能自主完成需求分析、RTL编码、仿真调试(甚至写Python脚本比对波形定位bug)、时序收敛与布局布线。https://view.inews.qq.com/k/20260524A049FP00
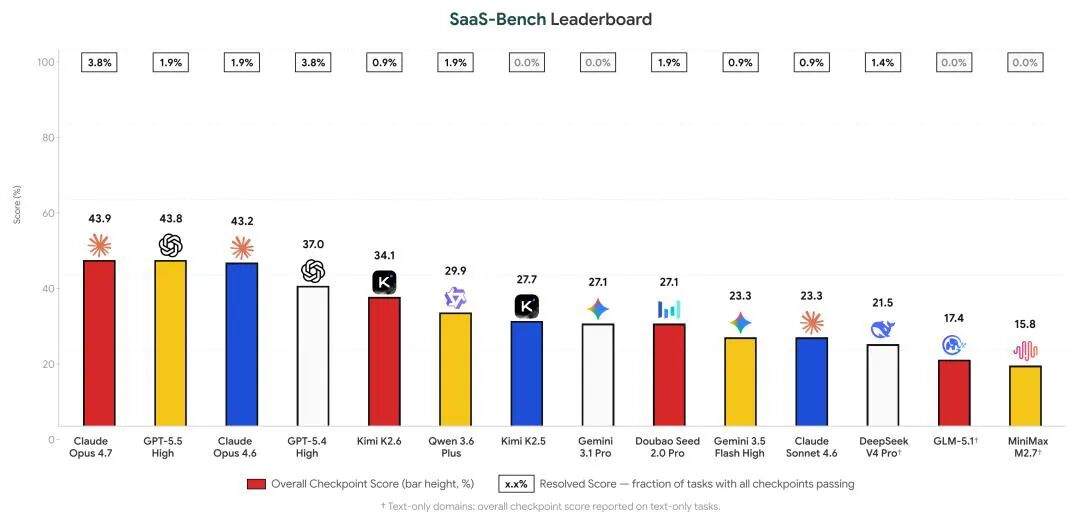
1-2. Claude 通过率不到4%,SaaS-Bench撕碎了Computer-Use的「全自动办公」幻想
SaaS-Bench最新评测给火热的“AI全自动办公”泼了一盆冷水:当前主流大模型(如Claude Opus 4.7)在真实办公场景中,端到端任务完全通过率仅3.8%,Kimi、Gemini等甚至为0%。该基准测试直击现实——它不是在模拟环境里点几下按钮,而是让AI在23个真实部署的开源SaaS系统中,完成跨应用、长流程、带业务逻辑的真实工作。
93.4%的任务需切换至少两个系统,53个任务涉及三个以上系统。评测暴露四大硬伤:①任务越长,错误越累积(后半程通过率断崖下跌);②一步填错公司名,后续30%操作全失效;③改完不复查,自以为对了;④同一任务三次运行得分波动极大(0.00–0.68),说明执行极不稳定。简言之:AI能“做一段”,但远不能“做完一件事”。https://www.qbitai.com/2026/05/424277.html

1-3. 8小时狂揽15K美金!Claude Code屠榜黑客马拉松,开源神器爆15万星
旧金山开发者Affaan Mustafa 将 Anthropic 的 Claude Code 打造成一套强大、可复用的AI智能体开发系统——Everything Claude Code(ECC),开源后迅速登顶 GitHub 热榜,收获超15万星标。这套系统不是简单工具包,而是融合工程直觉与AI原生思维的“数字工厂”:包含38个专业智能体、156项按需加载技能,以及覆盖全链路的1282项安全测试。
它支撑了他在2023年9月黑客松中夺冠的项目——AI客户调研平台 Zenith:用强化学习驱动的“赛博客户”模拟真实用户对话,帮创业者4步验证产品市场匹配度,全程几乎零手写代码。ECC 的核心突破在于“智能体即基础设施”——通过模块化加载规避上下文爆炸,用三重Opus智能体红队机制构筑本地安全防火墙。https://www.36kr.com/p/3823966768943239

AI大模型算法、赛事和会议
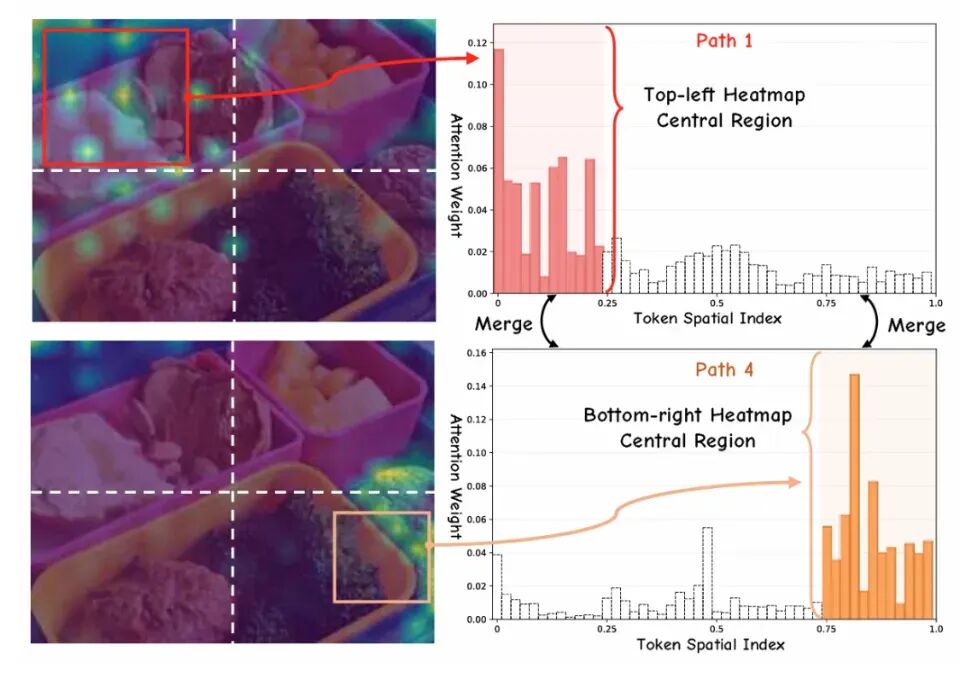
2-1. ICML 2026|首个视觉语言模型并行思考框架,一文解析内在机制
Visual Para-Thinker——首个专为视觉语言模型(VLM)设计的并行思考框架,旨在解决长推理中“注意力漂移”导致的视觉幻觉问题。传统方法靠拉长推理链(垂直扩展)易陷入僵化;而该框架转而拓展“推理宽度”,即同时激活多条独立、互补的视觉推理路径。
提出“块划分”(按图像象限分配区域)和“扫描划分”(按不同顺序遍历图像),兼顾局部聚焦与全局感知;用Pa-Attention实现路径隔离,统一 position ID 消除位置偏见,再通过 LPRoPE确保路径可区分。实证效果显著:在16.3万样本数据集上训练后,在视觉搜索任务中,3B/7B模型分别提升12.6和6.3分;在幻觉评测 HallusionBench 上提升6.1和5.0分,验证了并行思考对视觉理解的实质性增益。https://view.inews.qq.com/k/20260524A05X1B00

2-2. 机器人别等失败了才补救,AgentChord让恢复动作提前写进任务图
机器人正从工厂流水线走向真实家庭与实验室等开放环境,但现实任务充满不确定性:抓不稳、物体被碰偏、双臂交接错位……一次小失误就可能让整条长链任务崩盘。香港中文大学(深圳)等团队提出的AgentChord系统,创新性地将“失败恢复”前置——像人一样,动手前就预想“哪里可能出错、怎么救”。
它把任务建模为带恢复分支的有向图,提前编译好主流程和数十种常见故障(如滑落、位移、姿态偏差)的应对动作。实验表明:在仿真中成功率高达99.2%(快于主流方法),真实双臂机器人上达
77.5%成功率,且平均耗时比基线少近40秒。更关键的是,它生成的“可恢复轨迹”还能反哺训练,使策略鲁棒性提升50%。https://aitntnews.com/newDetail.html?newId=25435

AI基础设施方面(硬软件、数据)
3-1. 还在手写CUDA内核?CODA来了!LLM和新手也能让Transformer跑出光速
CODA 是一项面向大模型训练效率的突破性工作,核心思想是“把零碎计算塞进矩阵乘法(GEMM)的尾声里”。在H100上训练1B参数模型时,传统框架中RMSNorm等小算子虽计算量小,却因频繁读写显存,占到端到端时间的20%–30%——尤其在FP8加速后,这类“搬运开销”反而更突出。
CODA发现:这些操作大多可代数重写,迁移到GEMM输出尚在GPU寄存器中的“黄金窗口”执行,从而省去中间张量落显存再读回的往返。它不提供固定内核,而是一套含5类可组合原语的编程抽象,让开发者能快速写出高性能融合内核。实验显示:CODA在典型模式上比cuBLAS+PyTorch快1.5倍以上;反向传播加速达1.6–1.8倍;端到端Transformer层提速5%–20%,且数值精度不降反稳。https://zhuanlan.zhihu.com/p/2041880309050897788

AI人才和资本动态
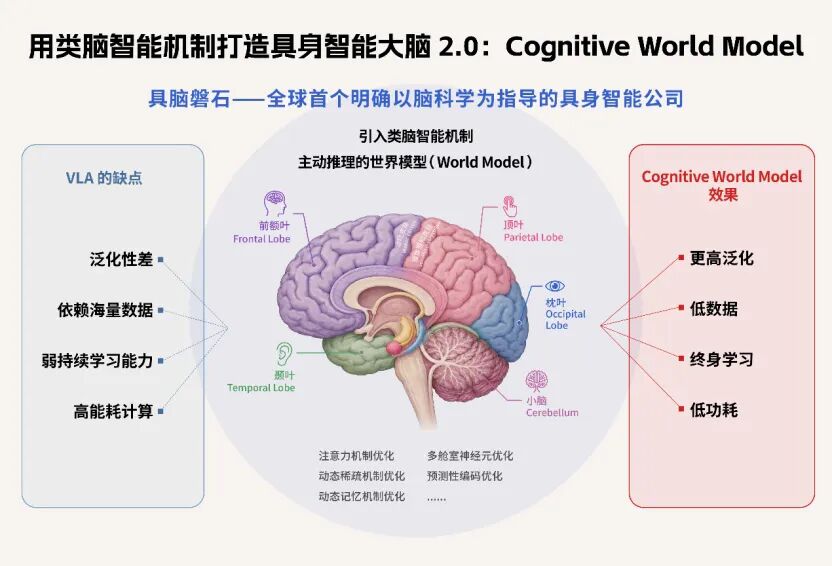
4-1. 华为具身大脑一号位创业,用认知科学造世界模型,获亿元级融资
2026年,AI正从“能看会动”迈向“真懂世界”。过去主流的VLA模型虽已在仓储分拣等简单场景落地,但一换环境就“卡壳”——要靠大量人工示范、难泛化、没记忆、不会推演后果。行业共识正在转向更底层的“机器人大脑”:世界模型。
华为前“具身大脑一号位”朱森华创立的具脑磐石,获亿元级融资,专注打造“认知世界模型”——不是模拟画面,而是让机器人像人一样思考:抓杯子会不会倒?绕障碍哪条路更稳?它借鉴认知神经科学,构建五层能力:从3D感知、物理规律建模,到交互试错、抽象预测,最终实现主动推理+终身学习。团队兼具华为盘古具身大模型经验与脑科学博士背景直击四大落地难点:低数据依赖、强跨场景泛化、长期记忆、端侧低功耗。https://www.qbitai.com/2026/05/423455.html
4-2. 智象未来超两千亿参数图像大模型HiDream-O1-Image-Pro发布,融资持续提速
智象未来在北京举办首届开放日,主题为“Imaging the World”,正式发布超2000亿参数的原生全模态图像大模型HiDream-O1-Image-Pro。该模型基于自研Unified Transformer(UiT)架构,首次实现图像像素、文本标记与任务指令在统一表征空间中深度融合,突破传统U-Net或DiT模型“图文分离编码”的瓶颈,在文生图等任务上刷新多项SOTA纪录。
半个月内,公司连续完成两轮亿级融资,
凸显资本市场对“原生全模态”技术路径的高度认可。同步落地“1+1+3”商业架构:以HiDream大模型为基座,HiHarness能力中台为支撑,推出HiBurst(电商营销)、帧赞(AI影视)、vivago(社媒创作)三大智能体——已服务超4000万用户,年产营销视频百万条,GMV破亿元https://www.qbitai.com/2026/05/420753.html
AI风险与政策管理
5-1. 30天烧掉60万亿,扎克伯格没进前250:大厂AI沦为KPI游戏
亚马逊、Meta等科技巨头正掀起一场“刷Token”热潮:员工用AI工具执行无意义任务,只为冲高内部排行榜——30天内Meta烧掉60万亿token,顶级用户单人耗用2810亿,连扎克伯格都未进前250。官方称token数据“不考核绩效”,但经理紧盯榜单,员工坦言“压力山大”,催生新词“tokenmaxxing”(疯狂刷用量)。
讽刺的是,Jellyfish对1.2万名开发者的实测显示:最高用量组每PR消耗token是中位数的10倍,产出却仅提升约2倍;单条代码评审成本从0.28美元飙升至89.32美元。更严峻的是,AI使用率上升伴随bug增54%、代码返工率暴增861%。本质是Goodhart定律作祟——当token变成KPI,成了资本叙事的注脚:7000亿美元云基建投入,需要“真实需求”背书。https://www.163.com/dy/article/KTP7FIUT0511ABV6.html
5-2. 企业鼓励员工多用 AI,算力账单开始超过部分人力成本
近期,企业AI应用正面临“甜蜜的烦恼”:一边是全员拥抱AI提效,一边是成本飙升失控。数据显示,优步4个月就烧完原定到2026年的AI编程工具预算;英伟达团队算力支出已远超员工薪资;微软更因内部Claude Code使用过热(半年内快速普及至数千人),被迫收紧授权,转推自家AI编程工具。这背后是真实成本压力——每次AI调用都消耗“token”,而每个token需算力支撑。
高盛预测,到2030年全球token消耗量将激增24倍;虽Gartner指出大模型单次推理成本有望在2025–2030年间下降90%,但AI Agent等复杂任务会大幅拉高总用量,导致企业账单不降反升。微软与Anthropic仍保持深度合作,但策略已转向“可控落地”:优先用自研工具控成本、保数据安全。https://www.1ai.net/53334.html
写在最后
欢迎大家关注、分享、转发本公众号,也欢迎直接与小编联系 对接合作~
小问卷:公众号打分点评





