 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库400 Token/s,原生多模态,阶跃星辰 Step 3.7 Flash 开源
阶跃星辰
今天,阶跃星辰开源了他们的新模型:Step 3.7 Flash,支持视觉理解,为 Agent 工作进行了全面优化,MoE 架构,196B 总参数,11B 激活
https://github.com/stepfun-ai/Step-3.7-Flash
除多模态外,在我看来,这模型还有一个优势:快至 400 token/s
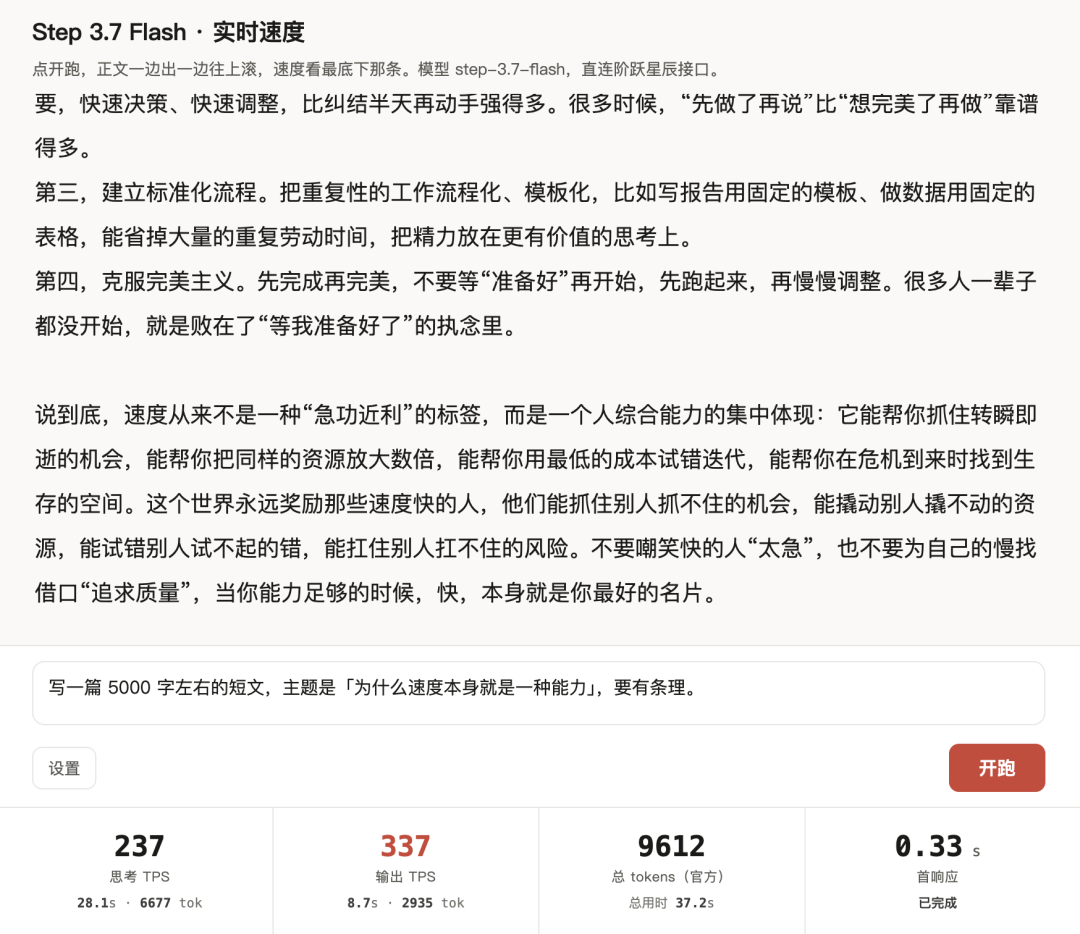
我自己测试了下,有 300+ token/s,感受一下
我自己的实录,感受一下速度
这个速度,应是最快的常规模型了
在生成内容的时候,这个模型的输出速度能到 400 TPS 左右,大概是....当你读完这句话的时候,这篇文章就生成完了(啊不是...这篇文章是手敲的,不是生成的...)
这个速度大致上也符合我对 Flash 模型的理解:在一目十行扫过上一页内容的时候,下一页已经生成了
下面,让我们先看一下跑分,然后再聊聊模型本身的特点
BenchMark
模型跑分可以先看下面这个图,Step 3.7 Flash 对比于 3.5 Flash、DeepSeek V4 Flash,以及海外御三家(Gemini、GPT、Claude)
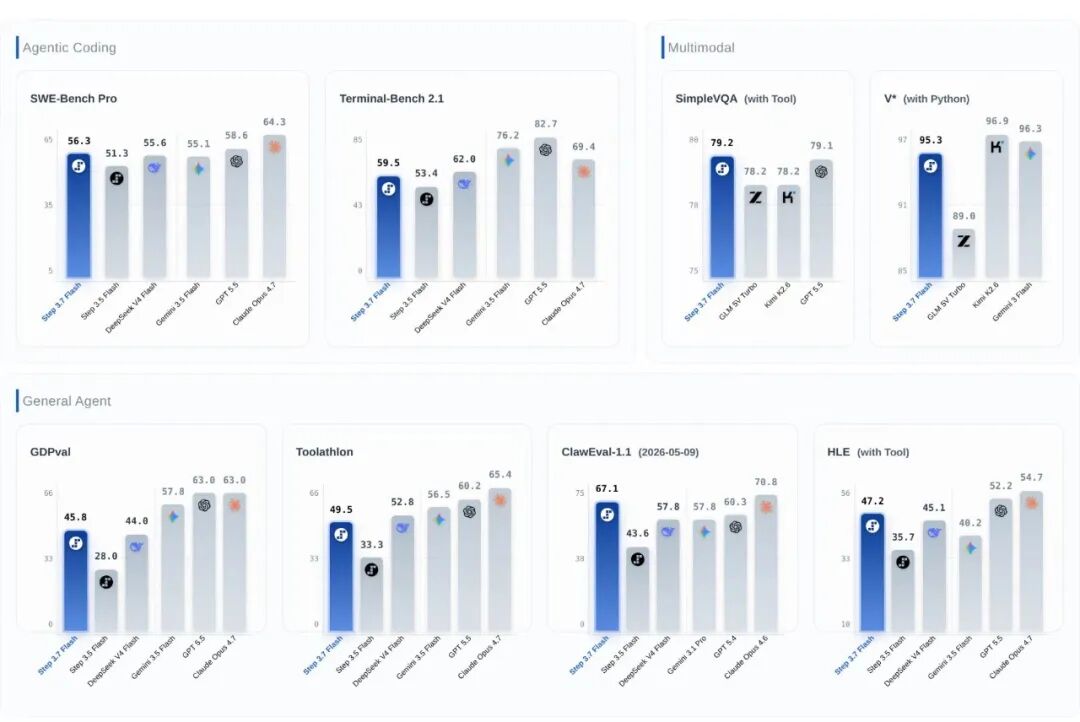
Step 3.7 Flash Bench
简而言之:
对比海外御两家,算了,反正大家都还有一些差距....诶....御两家??
对比 DeepSeek,部分 bench 里有所胜出;
对比上一代模型,大幅提升
在速度 bench 上... 遥遥领先(aa 榜单最快的是 gpt-5.3,100+)
几个 case
这里给大家看几个 demo,我觉得创造了一种叫做 *Realtime-UI 的范式,因为足够快,所以可以以实时的方式,在你的屏幕上渲染出各种交互界面,并与你交互
*你可能对 Realtime-UI 的这个概念不熟,没关系,这是我瞎编的
这些东西都是同时基于【Agent 能力构建】和【视觉理解能力处理】,并且在【高 TPS】下才能做到的,再度划重点:高 TPS:
画面实时解读先看第一个例子,通过 flash-3.7 来进行多模态信息的实时理解
上传一张飞机驾驶舱的照片后,鼠标指向过去,模型就在【秒级以内】快速的识别区域内的物品,并给出具体的细致讲解;由于生成速度确实很不错,还可以通过 function call 的方式,在非常短的时间里生成交互框,做出来一种 Realtime UI 的感觉
Pinterest 设计分析我们也可以把同一套视觉能力,搬到浏览网页的场景里
在 Pinterest 的瀑布流里里,鼠标停在哪张图上,底部就可以实时弹出交互框,对那张海报的构图、字体和视觉概念进行解读,做到完全与操作进行同步
Blender 三维软件除了图片、网页之外,这玩意儿也可以对复杂软件的界面进行理解
以 blender 为例(这真算相当复杂了),鼠标移动到哪,就能识别出尝尽力的面板和对象信息,并顺着指令告诉你接下来应该怎么操作
其实我真觉得...这玩意儿应该做成一个给家里老人用的工具,很多时候我需要远程给他们操作电脑,如果有了这个就会方便很多(甚至最好我在远程给他们说:点这个,然后家里的电脑要被点击的地方酒亮一下)
发票批量处理发票这个场景就太值得一提了
记账的时候,把各种票据丢进去,模型可以通过 fucntion call 的方式,快速抽取到商户、类别、金额、税额...等等各类信息,然后做成表格
智能体集群在实际业务过程中,这些能力还可以影分身着来用
比如生成 40 个不同身份的 agent,让他们进行投票...诶...巧了不是,今天 claude code 新出了动态工作流,是不是可以搭配着用上:Claude Opus 4.8 发布|Mythos 即将上线
快速搭知识图谱既然这么快,那么搭建一个图谱,也即是几秒钟的事儿
给一个主题,比如「大语言模型」,模型就能几秒钟内,快速铺开一张概念图,节点连成网络,从基础定义一路连到 Transformer 架构
模型特点
在我看来,Step 3.7 Flash 这个模型的两大核心优势:多模态理解 + 快
要知道,同级别的开源模型,大多开源模型,不具备多模态能力
还要知道,在非特别的推理加速下,绝绝绝绝大多数的模型,推理速度在 100 tps(tokens/s) 以下,主流则在 30 tps 左右
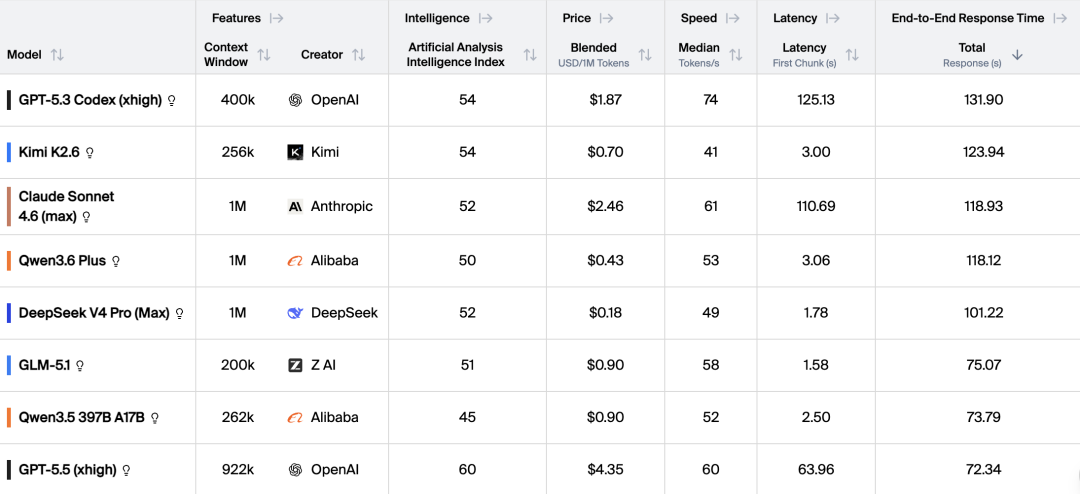
上面这个是 AA 的速度天梯,此前最快的是 gpt-5.3
Step 3.7 Flash 在支持多模态的前提下,把速度拉到了 400 tps,也不知道是上了什么神奇魔法
我去看了下文档,这个里面的图片&视频理解是原生支持的,并且在推理过程中还可以使用一个叫 Visual Python Tool的工具,对于看不清楚的地方,模型会自主对图片做 crop、zoom、re-read...换句话说,看不清就放大再看一遍,看完有疑问就去搜,尽可能的准确、高效的把事情搞定
同样的,搜索也是用这种方法进行循环:搜玩了如果觉得信息不够,那就再搜、再推,belike...

至于其他信息,这个模型的默认上下文是 256K,支持推理强度的手动调节:low / medium / high,可以根据需求,具体的更改参数
多少钱
这个模型可以自己部署,也可以通过官方平台或者第三方 MaaS 进行调用,价格如下:
Agent 场景下,缓存命中还是很高的
单看这个价格,是稍高于 DeepSeek v4 Flash的(输入1元/输出2元),但如果横比一下支持多模态的高速模型,那就很有优势了
然后这个模型也可以在海外平台调用,按美元计价,输入命中 $0.04、未命中 $0.20、输出 $1.15 每百万 token
模型使用
step-3.7-flash 同时兼容两套协议:OpenAI 家的,以及 Anthropic 家的
也可以直接用 Anthropic SDK,魔改下 endpoint 来用。在 Coding 和 Agent 工具上,对 Claude Code、OpenClaw、Cline、Roo Code、Kilo Code、Open Code 也都是支持的
这个模型今天上线,支持的 MaaS 包括:阶跃官方平台(国内,海外)、OpenRouter、NVIDIA NIM;而 DeepInfra、Fireworks、Modal 也在接入中,很快就上了
https://platform.stepfun.com/docs/zh/guides/models/step-3.7-flash
当然,作为开源模型,你也可以自己跑:196B/A11B,算一下的话反正 128G 的机器量化着能跑
在 HuggingFace 上,放了 BF16、FP8、NVFP4、GGUF 四种权重,丰俭由人,vLLM、SGLang、Hugging Face Transformers、llama.cpp 均以支持






