 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库AI 到底是怎么看图、懂图、画图的?——从 LLM 到多模态的架构地图
点击上方“图灵人工智能”,选择“星标”公众号
您想知道的人工智能干货,第一时间送达

多模态不是让 LLM 简单长出眼睛。更准确地说,是把文字、图片、声音、视频变成模型能处理的 token 或 embedding,再让 Transformer、扩散模型、Flow、VAE、视觉编码器、音频 codec 和视频生成器协同工作。看图、听音、懂图、画图、生成视频,背后其实是几种不同的数据流。
你现在打开一个 AI 工具,可以连续做三件事:
上传一张图片,问它:
这张图里有什么?
再追问:
这张 PPT 的版式哪里不好?
最后直接下指令:
按这个风格,重新生成一张公众号封面图。
在用户界面上,这三件事都发生在同一个聊天框里。
于是一个很自然的误解出现了:
是不是 LLM 已经学会看图、画图了?
这个说法不算完全错。
但它太粗糙。
如果我们想真正理解今天的 AI 多模态,就不能只说“LLM 会看图了”。
更准确的说法是:
文字、图像、声音、视频正在被压缩进同一种可计算的表示空间。LLM 有时是这个系统的大脑,但 Transformer、视觉编码器、图像 tokenizer、扩散模型和 Flow 生成器,才是让多模态真正运转起来的机器零件。
这篇文章要做一件事:
把“多模态”“VLM”“MLLM”“图像生成模型”“原生多模态”“Diffusion Transformer”“MMDiT”这些容易混在一起的名字,拆成一张清楚的架构地图。
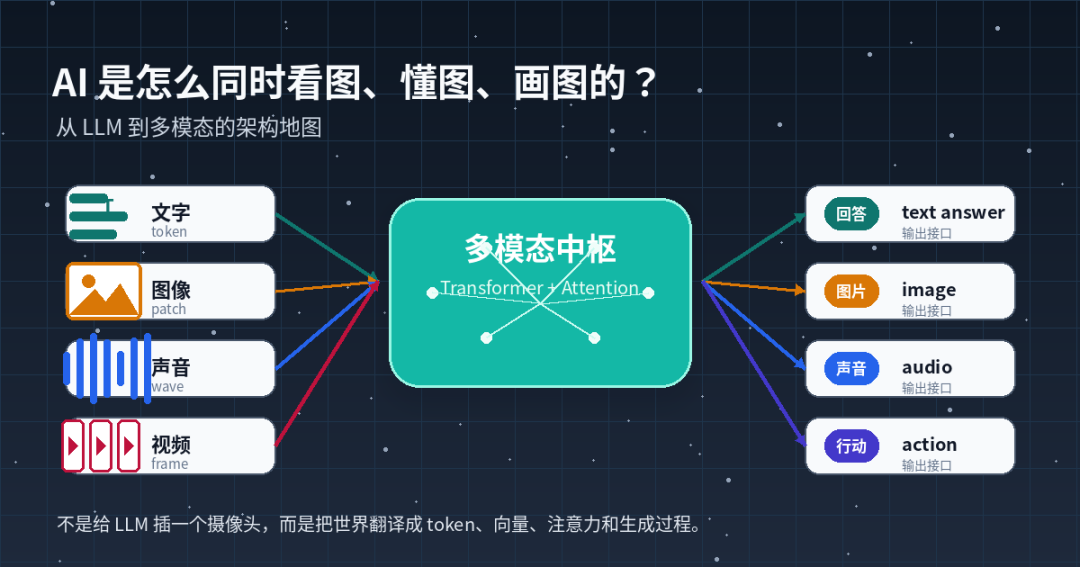
▲ AI 多模态架构地图封面图
但只画一张架构图还不够。
真正重要的问题是:
今天这些主流多模态模型,到底站在视觉智能的哪一级?
会识别图片,等于真正看懂世界吗?
会生成漂亮图片,等于拥有视觉想象力吗?
能回答截图问题,等于具备空间智能吗?
答案都不是简单的“是”或“不是”。
这也是这篇文章相比前面几篇多模态文章的新价值:
它不只是解释某一个模块,而是给今天的图像 AI 做一次能力定位。
我们会把主流模型放进一条能力阶梯里:
物体识别 → 图文对齐 → 看图问答 → 图像生成 → 多轮编辑 → 空间智能 / 世界模型
这样看,你就会发现:GPT-4V、Claude、Gemini、Qwen-VL、Stable Diffusion、FLUX、Qwen-Image、Janus-Pro 并不是“谁更强”这么简单。
它们回答的是不同层级的问题。
这也是为什么我们要谨慎使用“看见”“理解”“想象”这些词。
OpenAI 和 Anthropic 的官方文档都承认,今天的视觉语言模型虽然很强,但在精确空间定位、计数、低质量小图、高风险医学判断等场景仍然会犯错。BLINK、MMVP 等评测论文也反复指出:很多多模态大模型“能看见”,但在一些人类一眼就能完成的底层视觉感知任务上,仍然“不一定真的感知到了”。
所以这篇文章不是给 AI 贴金。
它要做的是另一件事:
把模型的能力、边界和未来方向放到同一张地图上。
一、先把名字摆正
今天 AI 圈最大的问题之一,是名字比架构跑得快。
很多产品都被叫成“大模型”。
很多能看图的模型都被叫成“多模态大模型”。
很多能画图的系统也被说成“LLM 画图”。
但从架构上看,这些名字不是一回事。
LLM:语言模型,不等于所有智能模型
LLM 的全称是 Large Language Model,大语言模型。
它最标准的形式是:
一串文字 token → 预测下一个文字 token
GPT、Llama、Qwen、DeepSeek、Claude 这类模型,最核心的训练任务都是围绕语言序列展开的。
它们强大的地方,是在海量文本里学到了世界知识、推理模式、表达方式和任务结构。
但原始 LLM 并不会直接“看见像素”。
你给它一张 1024x1024 的图片,它不能天然理解每个像素是什么意思。
必须先有人把图片翻译成它能处理的形式。
Transformer:架构,不是语言模型专属
Transformer 不是 LLM 的同义词。
Transformer 是一种神经网络架构。
它最重要的能力,是处理一串 token 之间的关系:
token 1 和 token 2 有什么关系? token 5 应该注意 token 17 吗? 当前位置要从哪些位置取信息?
文本可以变成 token。
图片也可以被切成 patch,然后变成视觉 token。
视频可以变成一串“空间 patch + 时间位置”的 token。
音频可以变成频谱片段 token。
所以真正泛化到多模态的,不是“语言”本身,而是:
把世界切成 token 序列,再用 Attention 建模 token 之间关系的这套方法。
LLM 是 Transformer 在语言上的巨大成功。
多模态模型,是这套方法向图像、视频、声音、动作的扩展。
VLM / MLLM / LMM:会看图的语言助手
VLM 通常指 Vision-Language Model,视觉语言模型。
MLLM 或 LMM 通常指 Large Multimodal Model,大型多模态模型。
最常见的形式是:
图片 → 视觉编码器 → 视觉 embedding → 投影层 → LLM → 文字回答
也就是说,很多“会看图的 LLM”并不是语言模型自己长出了眼睛。
而是前面接了一个视觉编码器。
视觉编码器负责把图片变成一串向量。
投影层负责把这串向量翻译到 LLM 能理解的 embedding 空间。
LLM 负责把这些视觉信息和你的文字问题放在一起推理,然后输出文字。
LLaVA 就是这个路线的经典开源代表:它把视觉编码器和 LLM 连接起来,再通过视觉指令微调,让模型能围绕图片进行对话。
Qwen2.5-VL 是更强的一类视觉语言模型,它不仅看普通图片,还强调文档解析、图表理解、视频理解、目标定位和 GUI 操作。
但注意:
VLM 通常擅长“看图并说话”,不一定擅长“从零生成图片”。
看图和画图,是两条不同的数据流。
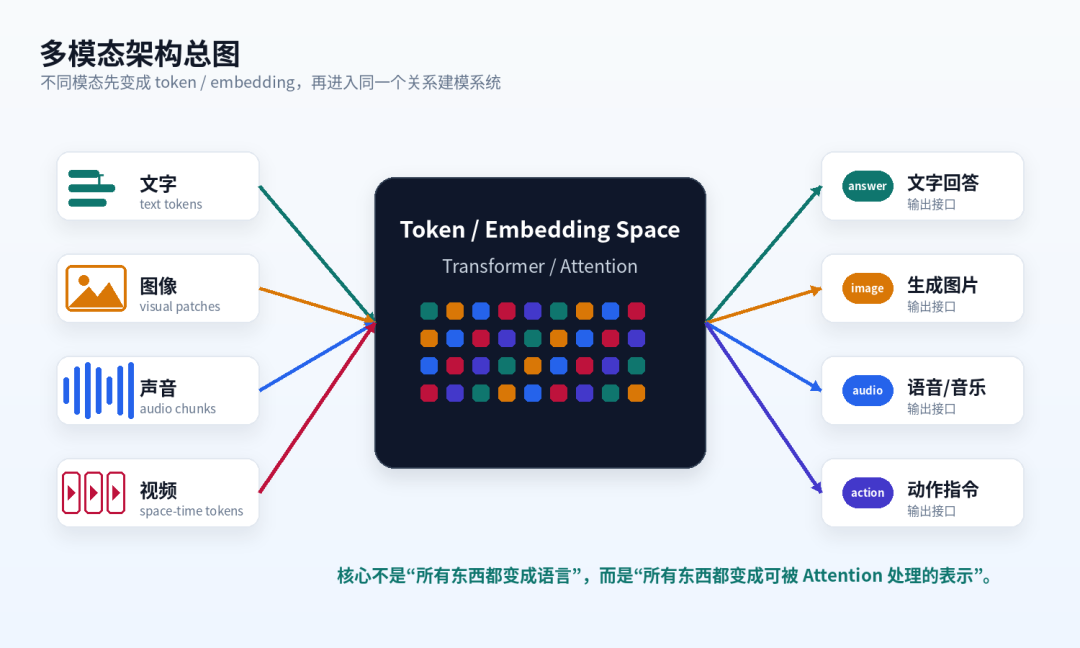
▲ 多模态架构总图:文字、图像、声音、视频进入同一个 token / embedding 空间
二、语言不是世界的全部
讲多模态,最容易掉进一个陷阱:
把其他模态都翻译成文字,然后以为问题解决了。
这当然有用。
语音可以转成文字。
图片可以生成描述。
视频可以写成摘要。
一段音乐也可以被说成“舒缓、温暖、带一点忧伤”。
但这样做会丢掉大量信息。
就拿语音来说。
同一句“我没事”,可以有很多种说法:
平静地说:我没事 哽咽地说:我没事 生气地说:我没事 疲惫地说:我没事 讽刺地说:我没事
转写成文字以后,它们都是同一句话。
但在人类耳朵里,它们几乎是五种不同的信息。
语气、音色、停顿、抑扬顿挫、呼吸、笑声、哽咽、环境声,这些都不是“文字内容”的附属品。
它们本身就是信息。
音乐更明显。
一段旋律不一定需要先翻译成语义,才会让人感到悲伤、庄严、辽阔或不安。
自然声音也一样。
雨声、海浪、风穿过树林、远处火车经过,这些声音给人的感受,常常不是一句话能替代的。
如果把它们全部压缩成:
这是一段雨声。 这是一段海浪声。 这是一段舒缓的音乐。
世界已经被压扁了。
视频则更进一步。
视频不是一堆图片的集合。
它有时间。
有运动。
有因果。
有镜头语言。
有一个动作发生前后的连续变化。
一张图片能告诉你“杯子在桌子边缘”。
一段视频还能告诉你:
杯子正在滑动 手马上要碰到杯子 水可能会洒出来 镜头正在靠近 人物情绪正在变化
这些信息如果只压缩成文字摘要,也会损失很多。
所以,多模态真正重要的地方,不是把所有东西都翻译成语言。
而是让模型能直接处理更多种表示:
文字 token 音频 token 图像 patch 视频时空 token 动作 token
这也是我们重新面对维特根斯坦那句话时,会产生的新问题。
维特根斯坦说:
我的语言的边界,就是我的世界的边界。
这句话很深。
语言确实是人类最强大的压缩工具。
没有语言,我们很难把经验变成概念,把概念变成知识,把知识传给别人。
但如果世界只剩语言,世界也会被压缩得太狠。
味道、旋律、光影、空间、触感、节奏、身体动作,都有一部分不能被完整翻译成文字。
这就是多模态 AI 的真正挑战:
不是把世界翻译成一句话,而是让模型保留世界中那些语言装不下的部分。
这也是为什么音频和视频模型值得关注。
Meta 的 AudioCraft / MusicGen 说明,音乐可以被建模成一种可生成的音频 token 序列,而不只是“歌词”。
Stable Audio Open 说明,开源社区也在尝试把声音效果、鼓点、环境声和音乐片段变成可控生成对象。
OpenAI 的 Sora、Google 的 Veo、Meta 的 Movie Gen,则说明视频生成不只是“图片更大”,而是要同时处理时间一致性、运动、镜头和世界状态。
DeepMind 的 Genie / Genie 2 这类项目更进一步,把视频和交互环境联系起来:模型不仅要生成画面,还要理解动作如何改变世界。
这些方向在本文里不会展开。
但它们给我们一个重要提醒:
图像只是多模态的第一扇门。声音、视频和行动,才会把 AI 真正推向现实世界。
三、图像识别:把图片翻译成模型能读的语言
先看“识别图片”。
这件事的输入和输出很清楚:
输入:图片 输出:文字、标签、框、坐标、判断、操作建议
传统计算机视觉模型会直接做分类、检测、分割。
多模态时代更常见的方式,是把图片变成一串视觉 token,再交给语言模型。
一个典型流程是:
图片 → 切成 patch → Vision Transformer / CLIP / SigLIP / Qwen-ViT 编码 → 得到视觉 embedding → projector / resampler 对齐到语言空间 → LLM 结合文字问题生成回答
这里有一个关键转折:
模型不是直接“看见一只猫”。
模型先看到的是很多视觉 patch 的向量。
这些向量里压缩了边缘、纹理、形状、局部结构、物体关系、文字区域、版式信息。
然后语言模型把这些视觉向量当成一种特殊的“上下文”。
就像你给 LLM 塞进一段文本背景材料一样,现在你给它塞进一段视觉背景材料。
所以,看图模型的第一性原理不是“眼睛”,而是:
把图像压缩成一串可被语言模型消费的向量。
这就是为什么 CLIP 很重要。
CLIP 做的事不是画图,而是把图片和文字放进同一个语义空间:
一张猫图 → 图像向量 "a cat" → 文字向量
如果两个向量靠得近,模型就知道这张图和这句话匹配。
从那以后,图像和文字之间有了一座桥。
后来的很多 VLM、扩散模型和图像编辑系统,都在不同程度上继承了这座桥的思想:
先让图像和语言可以在同一个空间里对齐,再谈理解和生成。

▲ 图片如何进入 LLM:从整张图到 patch,再到视觉 token 和文字回答
四、图像生成:不是把图片翻译成文字,而是把意图翻译成像素
图像生成的方向正好相反。
识别图片是:
图片 → 文字
生成图片是:
文字 → 图片
但这个箭头不能简单倒过来。
因为输出图片比输出文字复杂得多。
一句话只有几十个 token。
一张高清图可能有几百万个像素。
模型不可能像写文章一样,直接从左到右一个像素一个像素地“写”完整张图。
经典 Stable Diffusion 的做法,是把图像生成拆成几层:
文字 prompt → 文本编码器 → 条件向量 → 潜空间里的去噪模型 → VAE 解码器 → 像素图片
这里的关键词是“潜空间”。
上一篇讲扩散模型时,我们说 AI 不是从空白画布开始画猫,而是从噪声里一步步去噪。
Stable Diffusion 更进一步:
它不直接在原始像素空间里去噪,而是在一个压缩后的 latent space 里去噪。
这有点像:
真实图片 → 压缩成视觉草稿 → 在草稿空间里生成 → 再解压回图片
VAE 负责压缩和解压。
U-Net 或 Diffusion Transformer 负责在潜空间里生成结构。
文本编码器负责告诉生成器:
这团噪声应该朝哪个语义方向收缩?
这就是图像生成和图像识别的第一处本质差异:
识别模型要把图像压缩成语义;生成模型要把语义展开成图像。
压缩和展开,是两个方向。
它们共享一些组件,但目标并不相同。
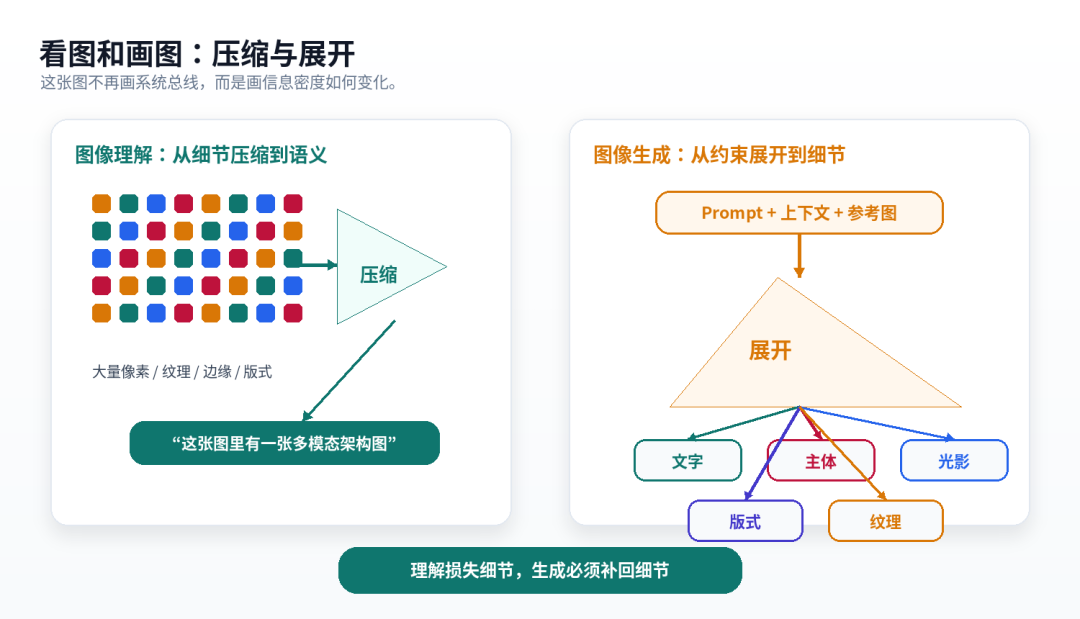
▲ 看图和画图是两条相反链路:理解是压缩,生成是展开
五、为什么新模型越来越“听话”?
早期 AI 画图最常见的问题是:
Prompt 写得很细,出来的图却像抽盲盒。
你说“三个人站在红色汽车旁边”,它可能画成两个人、四个人、蓝色车、车在远处。
你让它生成一张带中文标题的海报,它常常生成一堆像文字但不是文字的符号。
问题不只是“画得不够好”。
更准确地说,是:
文字约束没有足够深地进入图像生成过程。
Stable Diffusion 1.x 的核心是 latent diffusion + U-Net + cross-attention。
这已经很强。
但文字和图像的互动方式仍然有限。
后来的 SDXL、Stable Diffusion 3、FLUX.1、Qwen-Image 等模型,一条明显趋势是:
把文本理解、更大的 Transformer、更强的图像 token 表示、更稳定的 Flow / Diffusion 训练方式,接得越来越深。
Stable Diffusion 3 的 MMDiT 是一个很好的例子。
MMDiT 可以理解成“多模态 Diffusion Transformer”。
它不只是把文字向量丢给图像 U-Net 当条件。
它让文本 token 和图像 token 在 Transformer 的 Attention 中更深地交互。
同时,文本和图像不是完全混用一套权重,而是保留各自适合的表示方式,再在 Attention 层相遇。
FLUX.1 则代表了另一个方向:用更大的 Rectified Flow Transformer 做高质量文本到图像生成。
Qwen-Image 的重点又不同。
它把复杂文字渲染、中文英文混排、图像编辑一致性当成核心能力,并在技术报告里强调了 Qwen2.5-VL 与 MMDiT、VAE 表示之间的对齐。
这说明今天的“会画图”,已经不只是美术风格问题。
它正在变成一个更复杂的问题:
语言理解 + 世界知识 + 版式理解 + 空间关系 + 文字渲染 + 主体一致性 + 编辑前后保真 + 生成器稳定性
所以,新一代图像模型更“听话”,不是因为 prompt 咒语更神秘。
而是因为:
用户意图进入生成过程的通道更宽、更深、更稳定了。

▲ Prompt 如何约束图像生成:文字 token 通过 Attention 进入 latent 生成过程
六、统一多模态:看图和画图能不能变成一个模型?
现在来到最关键的问题。
既然识别图片是:
图片 → 文字
生成图片是:
文字 → 图片
那能不能训练一个模型,同时做这两件事?
答案是:可以,但并不简单。
因为“理解图像”和“生成图像”需要的视觉表示并不一样。
理解图片时,模型关心的是语义:
这里有一只猫 猫坐在窗边 左上角有一行文字 这张表格第三列是金额
生成图片时,模型还要关心极细的视觉细节:
毛发纹理 光照方向 字体笔画 边缘是否连续 人物身份是否一致 局部纹理是否破碎
一个视觉编码器如果太偏语义,生成时可能丢细节。
一个视觉编码器如果太偏像素,理解时又可能不够抽象。
DeepSeek 的 Janus 系列正是抓住了这个矛盾。
Janus 的核心思想是:
理解和生成共用一个 Transformer 主干,但视觉编码路径要解耦。
也就是说:
图像理解路径:图片 → 语义视觉编码 → 统一 Transformer → 文字 图像生成路径:文字 → 统一 Transformer → 生成视觉编码 → 图像
这条路线很适合用来解释“统一多模态”的难点。
它告诉我们:
统一不是把所有东西硬塞进一个编码器。
真正的统一,是在高层语义和任务空间里统一;在底层表示上,仍然允许不同模态、不同任务保留自己的专用通道。
Chameleon 则代表另一种思路:
把文本和图像都 token 化,放进同一个自回归序列模型里,让模型处理任意交错的文本和图像 token。
它的目标更像:
文字 token + 图像 token + 文字 token + 图像 token → 同一个 Transformer → 继续生成文字或图像 token
这听起来最接近“万物皆 token”。
但工程上非常困难,因为图像 token 数量巨大,训练稳定性、生成质量、对齐方式都会变复杂。
所以,今天的多模态架构大致分成四类:
图文对齐模型
代表模型:CLIP
输入输出:图片/文字 -> 向量
关键思想:把图像和文本放进同一个语义空间
视觉语言模型
代表模型:LLaVA、Qwen2.5-VL
输入输出:图片+文字 -> 文字
关键思想:视觉编码器接到 LLM,让 LLM 能围绕图片说话
图像生成模型
代表模型:Stable Diffusion、SDXL、FLUX.1、Qwen-Image
输入输出:文字/图片条件 -> 图片
关键思想:用扩散、Flow、VAE、MMDiT 把意图展开成图像
统一多模态模型
代表模型:Chameleon、Janus-Pro
输入输出:文字+图片 -> 文字+图片
关键思想:尝试用一个主干同时做理解和生成
这张表比“LLM 会不会画图”更重要。
因为它把混在一起的能力拆开了。

▲ 四类多模态模型积木:CLIP、VLM、图像生成模型、统一多模态模型
七、LLM 能泛化到多模态吗?
现在可以回答开头的问题了。
LLM 能不能泛化到多模态?
答案分两层。
如果你说的 LLM 是“只在文字上训练、只接收文字 token、只输出文字 token 的语言模型”,那它不能直接泛化到多模态。
它没有眼睛。
它不知道像素。
它需要视觉编码器、图像 tokenizer、投影层、多模态训练数据和新的对齐目标。
但如果你说的 LLM 是“一个巨大的自回归 Transformer,里面压缩了语言、知识、推理、任务规划和指令跟随能力”,那它确实可以成为多模态系统的核心大脑。
图片可以变成视觉 token。
视频可以变成时空 token。
声音可以变成音频 token。
动作可以变成控制 token。
只要这些 token 能进入同一个上下文,Transformer 就可以学习它们之间的关系。
所以最准确的说法是:
不是 LLM 天然泛化到多模态,而是 Transformer + token 化 + 表示对齐 + 多模态训练,让语言模型的能力可以迁移到更多模态上。
这也是为什么“Transformer”这个词比“LLM”更适合描述底层趋势。
LLM 是语言时代的名字。
多模态基础模型,是下一阶段更准确的名字。
八、从 ImageNet 到空间智能:今天的模型站在哪里?
如果要理解今天图像 AI 的位置,李飞飞是一条绕不开的线索。
她参与推动的 ImageNet,曾经把计算机视觉带进一个新阶段。
那时最核心的问题是:
给一张图片,模型能不能认出里面是什么?
2012 年 AlexNet 在 ImageNet 上取得突破后,深度学习真正席卷视觉领域。
从那以后,计算机视觉的主线很长一段时间都是:
分类 → 检测 → 分割 → 图文对齐 → 看图问答
但这里有一个容易被忽略的事实:
识别物体,不等于理解世界。
一张图里有“杯子”,这只是第一层。
杯子在桌子的左边还是右边?
杯子会不会掉下去?
人伸手过去能不能拿到?
如果把杯子移动到画面另一侧,阴影和遮挡应该怎么变?
这些问题已经不只是“图像识别”。
它们进入了更高一层:
空间智能。
李飞飞近几年反复强调的,正是这个方向:AI 不应该只处理文字,也不应该只给图片打标签,而要能够理解、生成并推理三维世界中的对象、关系、动作和变化。
这给我们一个很重要的判断标准:
图像 AI 的终点,不是把图片描述成一句话,而是建立一个可以被推理、生成和行动使用的世界表示。
用这把尺子看今天的主流模型,会更清楚。
GPT-4V、Claude、Gemini、Qwen2.5-VL 这类模型,已经能把图片接进语言推理系统。
它们擅长:
描述图片 理解截图 读图表和文档 回答视觉问题 把图片内容转成文字推理
但它们仍然不等于完整的视觉智能。
OpenAI 的 GPT-4V system card 明确提醒过,模型可能出现视觉幻觉,也可能在细节、空间关系、医学图像等高风险场景犯错。
Anthropic 的 Claude 视觉文档也把空间推理、计数、低质量小图、医学诊断等列为限制场景。
学术界的 BLINK、MMVP 等评测,则把问题拆得更细:
两个图形是否真的相交? 物体左右关系是否判断正确? 图片里的细微视觉模式是否被识别? 模型是不是只靠语言先验在猜?
这些题有时对人类很简单,但对多模态大模型并不稳定。
这不是说它们“没用”。
恰恰相反,这说明它们已经强到需要更精细的评估。
但我们不能把“能接收图片输入”误读成“已经拥有人的视觉系统”。
今天主流模型大致站在这里:
物体识别:已经很成熟 图文对齐:已经非常强 看图问答:进入可用阶段,但仍有错觉和边界 图像生成:质量很高,控制性快速提升 图像编辑:正在从玩具走向生产工具 空间智能:刚刚开始
所以,这篇文章真正想给你的,不是一堆模型名。
而是一把尺子:
以后看到任何“多模态模型发布”,先问它解决的是哪一层:识别、对齐、问答、生成、编辑,还是空间智能?
这比单纯问“它是不是大模型”有用得多。
九、几个适合深挖的模型和项目
如果这篇文章要讲得通俗、深刻、准确,不能只围绕闭源模型,也不能只围绕图片。
闭源模型可以作为体验入口,但技术拆解最好依赖开源项目、公开论文和官方技术材料。
下面这些模型和项目,适合作为后续深层拆解对象。
1. Stable Diffusion / SDXL:经典扩散模型的主干
适合解释:
为什么要在 latent space 里生成; VAE 如何压缩和解压图像; U-Net 如何一步步去噪; cross-attention 如何把 prompt 接进图像生成; 为什么图像生成不是“从左到右画出来”。
这条线适合承接经典扩散模型的直觉基础。
它是读者已经理解过的直觉基础。
2. Stable Diffusion 3 / MMDiT:图像生成里的多模态 Transformer
适合解释:
为什么图像生成模型也开始大量使用 Transformer; 为什么文本 token 和图像 token 需要更深交互; MMDiT 里的“多模态”到底是什么意思; 为什么文字渲染和 prompt adherence 会变好。
这条线可以把上一篇的 DDPM / LDM 推进到现代图像模型。
3. FLUX.1:开源权重里的高质量 Flow Transformer
适合解释:
Rectified Flow 和经典扩散的区别; 为什么更直的生成路径可能减少采样步骤; 为什么大规模 Transformer 能提升图像质量和指令跟随; open weights 对研究和工作流生态的意义。
这条线适合连接“开源社区现在在用什么”。
4. Qwen-Image:中文文字渲染和图像编辑的好案例
适合解释:
为什么以前 AI 画图里的文字经常是乱码; 为什么中文比英文文字渲染更难; 为什么图像编辑需要同时保留语义和像素细节; Qwen2.5-VL、VAE、MMDiT 之间如何形成双重表示。
这条线尤其适合公众号。
因为中文文字渲染是读者一眼能感受到的进步。
5. LLaVA / Qwen2.5-VL:看图模型的透明样板
适合解释:
视觉编码器如何接到 LLM; projector / adapter 到底在翻译什么; 为什么 VLM 能读图表、看截图、做 OCR; 为什么“看图回答”和“生成图片”不是同一种能力。
这条线适合澄清“AI 识别图片”和“AI 生成图片”的关系。
6. Janus-Pro:统一理解与生成的关键样板
适合解释:
为什么看图和画图不能只用一个视觉编码器硬扛; 为什么统一多模态需要任务路径解耦; 自回归模型如何同时服务图像理解和图像生成; “原生多模态”不是产品宣传词,而是一个架构方向。
这条线适合作为文章的高潮。
它能把读者从“AI 会看图、会画图”带到:
AI 正在把不同模态都变成同一个世界模型的入口和出口。
7. AudioCraft / Stable Audio Open:声音不是文字的附属品
适合解释:
为什么语音转文字会丢失语气、音色和情绪; 为什么音乐生成不能只靠歌词或文字描述; 音频 token、codec、spectrogram 这些表示如何保留声音细节; 为什么自然声、环境声、音效也是世界信息的一部分。
这条线适合把“多模态”从图像扩展到听觉。
8. Sora / Veo / Movie Gen:视频不是一堆图片
适合解释:
为什么视频生成要处理时间一致性; 为什么运动、镜头、因果关系比单张图片更难; 为什么“画面好看”不等于“世界合理”; 为什么视频模型正在逼近世界模型问题。
这条线适合把图像生成推进到时间、动作和场景演化。
9. Genie / Genie 2:从看见世界到操作世界
适合解释:
为什么交互式视频环境比普通视频生成更接近世界模型; 动作 token 如何进入生成过程; 为什么“下一帧会发生什么”开始接近“如果我这样做会怎样”; 多模态如何从感知走向行动。
这条线适合作为未来讲具身智能、机器人和世界模型的入口。
十、这篇文章真正要讲的不是画图,而是世界接口
上一篇扩散模型文章讲的是:
AI 如何从噪声中生成一张图。
这一篇要往前走一步:
AI 如何把文字、图像、视频、声音接进同一个计算世界。
图片识别不是简单识别物体。
它是把视觉世界压缩成语言和语义。
图片生成不是简单画画。
它是把语言、意图、上下文和世界知识展开成视觉世界。
多模态也不是给 LLM 插一个摄像头。
它是让模型拥有更多输入和输出接口:
文字是接口 图片是接口 声音是接口 视频是接口 动作也是接口
当这些接口被统一到 token、embedding、Attention 和生成模型里,AI 就不再只是一个“会说话的模型”。
它开始接近一个更通用的东西:
一个可以在不同感官之间翻译、推理、生成和行动的世界模型。
这就是为什么“多模态”重要。
不是因为它让聊天框多了一个上传图片按钮。
而是因为它把 AI 从语言空间,推向了现实世界。
本公众号延伸阅读
如果你想把这张地图的几块底座补得更牢,可以回看这几篇:
向量底座:《AI 的数学语言(一)》和《看见数学(十一):向量》,解释为什么“一组数字”可以描述一个对象。 语义底座:《当数字学会了远近亲疏——从查表到 Embedding 的一步跨越》,解释 token 如何变成语义坐标。 表示底座:《万物皆向量——当 AI 选择用数学理解世界》,解释为什么文字、图片、声音最终都会进入向量空间。 看图底座:《当 AI 学会了看——多模态大模型的架构拆解》,解释 ViT、CLIP、对齐模块和 LLaVA。 生成底座:《从噪声中看见猫——扩散模型的数学美学》,解释图像生成为什么是从噪声到图像的反向过程。
这篇文章站在它们上面,往前多走了一步:
不只问“模型怎么做”,还要问“它到底处在视觉智能的哪一级”。
参考资料
Ho, Jain, Abbeel, "Denoising Diffusion Probabilistic Models", 2020. Rombach et al., "High-Resolution Image Synthesis with Latent Diffusion Models", 2022. Podell et al., "SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis", 2023. Peebles and Xie, "Scalable Diffusion Models with Transformers", 2023. Stability AI, "Stable Diffusion 3: Research Paper", 2024. Black Forest Labs, FLUX.1 model cards and announcement. Radford et al., "Learning Transferable Visual Models From Natural Language Supervision", 2021. Dosovitskiy et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale", 2020. Liu et al., "Visual Instruction Tuning", 2023. Qwen Team, "Qwen2.5-VL Technical Report", 2025. Qwen Team, "Qwen-Image Technical Report", 2025. Chameleon Team, "Chameleon: Mixed-Modal Early-Fusion Foundation Models", 2024. DeepSeek-AI, "Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation", 2024. DeepSeek-AI, "Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling", 2025. Deng et al., "ImageNet: A Large-Scale Hierarchical Image Database", 2009. Russakovsky et al., "ImageNet Large Scale Visual Recognition Challenge", 2015. OpenAI, "GPT-4V(ision) System Card", 2023. Anthropic, "Claude Vision", official documentation. Fu et al., "BLINK: Multimodal Large Language Models Can See but Not Perceive", 2024. Tong et al., "Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs", 2024. Fei-Fei Li / World Labs, writings and interviews on spatial intelligence. Copet et al., "Simple and Controllable Music Generation", 2023. MusicGen / AudioCraft. Stability AI, "Stable Audio Open", model release and technical materials. OpenAI, "Sora: Creating video from text", technical report and system card. Google DeepMind, "Veo" and "Veo 3" model announcements. Meta, "Movie Gen: A Cast of Media Foundation Models", 2024. Google DeepMind, "Genie: Generative Interactive Environments" and "Genie 2", 2024.

文章精选:
1.编程时代已终结!ClaudeCode创始人断言:编程就像发短信一样自然,首曝个人最新工作流:自创Sloop循环,单日PR达150!传统SaaS护城河崩掉





