五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库ICLR'26 时间序列预测代表性工作梳理

今天这篇文章给大家梳理了ICLR 2026中时间序列预测相关的代表性工作。这些工作涉及通过全周期序列检索提升长周期预估能力、引入重构损失损失缩小历史和未来表征的分布差异、考虑外部变量的新方法等,共5篇论文。
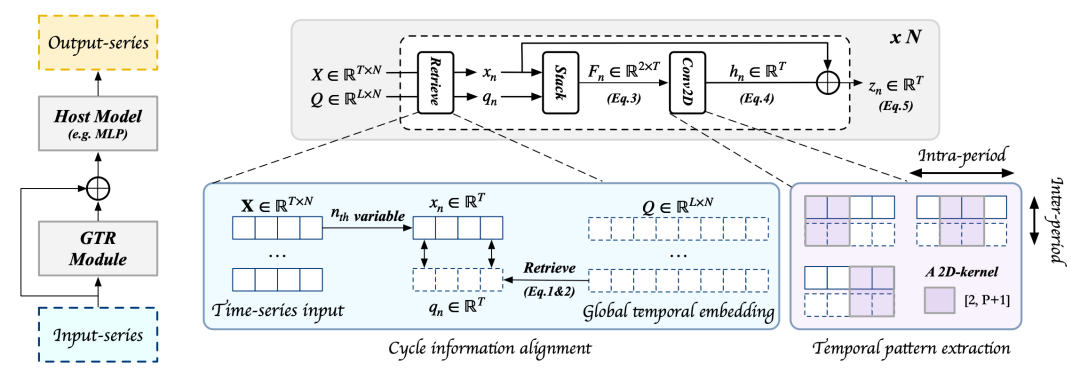
论文标题:ENHANCING MULTIVARIATE TIME SERIES FORECASTING WITH GLOBAL TEMPORAL RETRIEVAL
时间序列预测中,历史的长周期信号对于预测至关重要。然而,受限于一般时间序列建模方法对历史时间窗口长度的限制,将长周期历史信号引入时间序列预测是比较困难的。这篇文章提出了一种基于全域时序信号检索的方法,在每次时间序列预测时,检索历史相关的信号,拼接到一起联合建模。
具体方法为,首先维护了一个全域时序表征,维度为L*N,L是全局周期长度(一般和时间序列的周期长度匹配,用来进行长周期规律性的捕捉),N是变量数量。每个时间序列会根据这条序列的起始位置从全局时序表征中抽取相应位置的历史表征,经过一个线性层得到表征加到模型里。二者拼接后,使用2维卷积从原始输入序列和检索出来的序列上联合抽取表征信息。
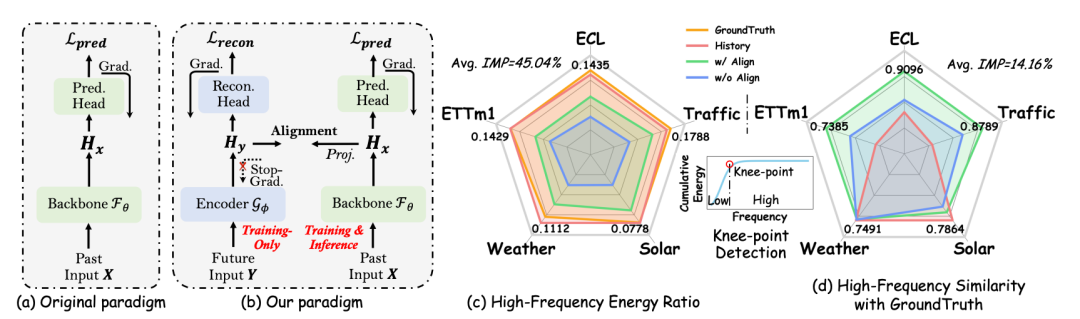
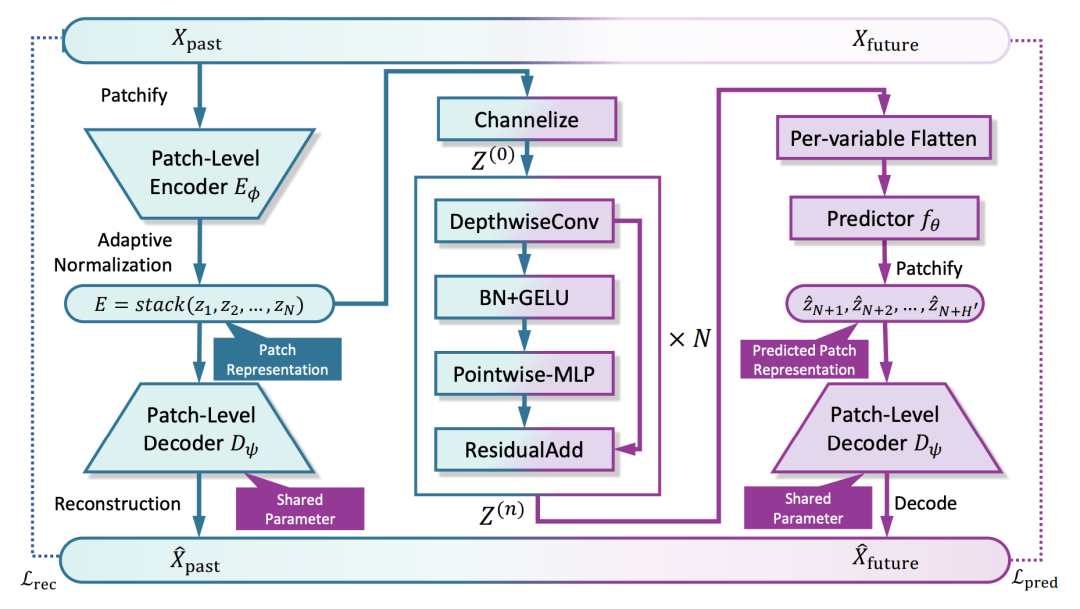
论文标题:BRIDGING PAST AND FUTURE: DISTRIBUTIONAWARE ALIGNMENT FOR TIME SERIES FORECASTING
这篇文章提出了一种可以适用于各类时间序列预测模型的可插拔模块,进行时间序列历史表征和未来表征分布的对齐。文中提出,时间序列预测面临着包括历史和未来表征分布不一致、预测在均值附近波动等问题,并提出造成这些问题的核心原因在于对模型缺少历史和未来表征的关联。
为了解决这个问题,本文在一般的时间序列模块中,引入了一个重构模块,对历史序列进行编码后,用这个编码对历史序列进行重构。在此基础上,引入了两个损失函数,进行历史序列对历史重构的表征以及对未来预测表征的一致性约束。一方面,对于两种表征的每个patch进行相似度计算并约束差异。另一方面,对整体的表征也进行相似度计算并约束差异。
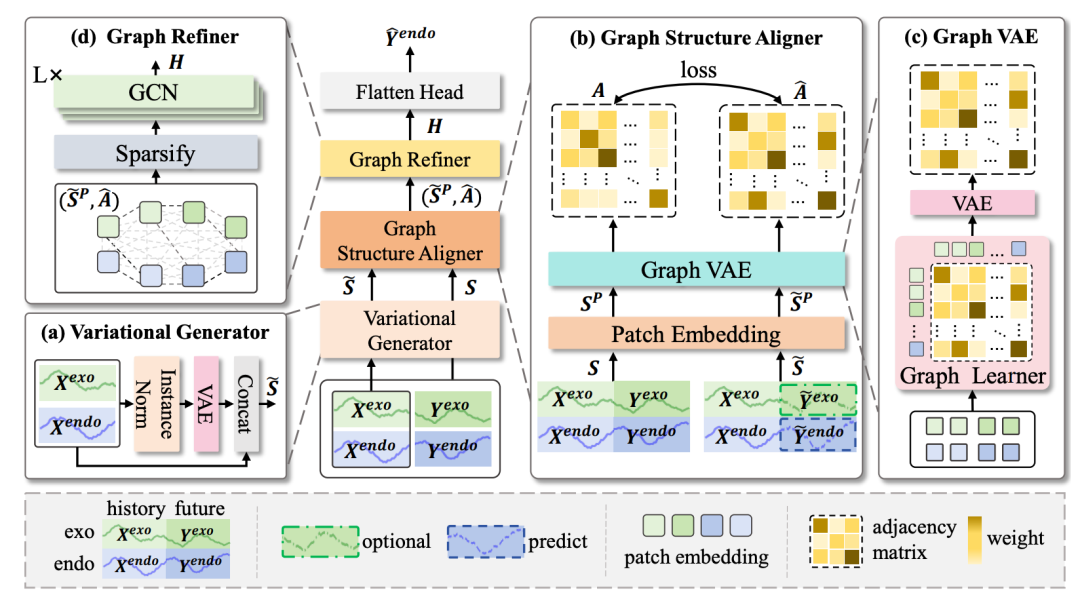
论文标题:GCGNET: GRAPH-CONSISTENT GENERATIVE NETWORK FOR TIME SERIES FORECASTING WITH EXOGENOUS VARIABLES
在有外部变量的时间序列预测中,一方面要考虑外部变量和目标变量在时序上的关系,另一方面也要考虑外部变量和目标变量在空间上的互相影响。一般的建模方法会将时序关系和空间关系分别建模,这在一定程度上限制了模型的表达能力。此外,在存在外部变量的时序预测中也经常会受到噪声的干扰。
为了解决上述问题,这篇文章提出了一种基于图生成的外部变量时序预测方法。首先使用VAE对目标变量和外部变量分别进行一次生成做为粗粒度的预估结果。接下来,将历史序列+粗粒度预估结果,与历史序列+真实结果这两条完整的序列,分别进行patch处理后,都输入到Graph VAE学习各自的临街矩阵,约束二者相等,通过这种方式间接的让真实序列和预测序列在结构上保持一致,同时考虑了目标变量和外部变量的时序关系和空间关系。
论文标题:ARE GLOBAL DEPENDENCIES NECESSARY? SCALABLE TIME SERIES FORECASTING VIA LOCAL CROSSVARIATE MODELING
变量间的关系建模一直是多变量时序预测中的一个核心问题。近期的一些建模方法,引入了诸如attention的多变量间关系建模模块,显著提升了多变量时序预测的效果,但代价是计算复杂度的显著提升。这篇文章提出了一个假设:全面建模各个变量各个时间步的关系没有必要,只建模局部的变量间关系就够了,提出了一种更高效的局部变量间关系建模方法。
具体做法为,首先使用AdaPatch的方案,将各个变量的时间序列独立映射成patch。接下来将多变量多patch进行维度的变换,第一维是batch_size,第二维是每个patch的embedding维度,第三维是变量,第四维patch。使用一个逐通道的卷积进行局部的信息融合,这就是先了局部的变量-patch的关系建模。通过多层的卷积堆叠逐渐学习更广阔的变量间和时序间关系。这种方式大幅降低了变量间关系建模的计算开销,并最大限度保留了多变量关系建模引入的收益。
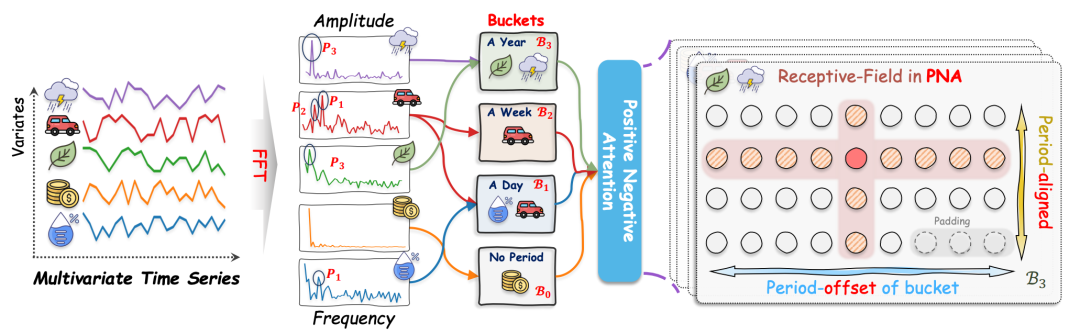
论文标题:PHAT: MODELING PERIOD HETEROGENEITY FOR MULTIVARIATE TIME SERIES FORECASTING
周期性建模是时间序列预测中一个很关键的维度,识别序列存在的周期性,并根据周期性利用历史预测未来,能够提升时序预测准度。这篇文章提出了一种将多变量中同周期样本聚合预测的建模方法。其核心是将所多变量时间序列按照其具有的周期性进行聚合,在聚合的样本内建模周期内和周期间关系。
具体建模方法为,首先利用傅里叶变换识别C个变量最重要的K个周期项,将这C*K个周期项去重后,每个变量分配到对应的周期项上。假设最终由M个周期项,就将输入序列分成了M堆,每个周期项可能对应多个序列。每个周期项的各个序列会根据周期长度进行切分和reshape,得到一个变量数 * 周期长度 * 周期个数的3维数据。这个3维数据会输入到文中提出的PNA模块,这个模块在同一变量的不同周期长度内、以及不同变量的同一周期内,使用attention提取关联信息,从而使得整个多变量的周期性建模更加清晰,也避免了一般self-attention需要完全交互引入过多噪声带来的周期性信息学不好或不同周期项学习间存在冲突的问题。