 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库没想到啊,近期用过最好玩的一个Skill,来自微信读书


品玩
科技创新者的每日必读
品玩APP
线下活动
专题
登录
没想到啊,近期用过最好玩的一个Skill,来自微信读书
把玩了一下微信读书搞的Skill,我发现它比MBTI更懂我





微信读书最近上线了一个官方 Skill。
过去两年,我们已经见过太多类 AI 产品形态,搜索框里加一个 AI,客服入口旁边放一个助手,内容页底部接一个总结按钮。
AI 似乎已经变成一种标准配置,一个产品如果不宣布自己接入了 AI,反而显得不够完整。
所以一开始看到微信读书这个 Skill,并没有太大期待。
但用完之后,我反而觉得它和许多“给产品加一个 AI 入口”的尝试不太一样。
它的重点不只是让你更快找到一本书,也不只是让 AI 替你概括一本书的内容。真正有意思的是,微信读书把一个人长期阅读过程中留下的私人痕迹,变成了 AI 可以理解和调用的上下文。
你的书架、阅读进度、阅读统计、划线、想法、书评,不再只是分散在 App 各处的功能模块,而开始变成一份关于你自己的阅读档案。
这件事的微妙之处在于,那些数据本来就在那里。
你读到一半停下的书,你反复划线的段落,你某一年突然密集阅读的主题,你在深夜写下的一条想法,它们从来没有消失。只是过去,它们更多像是被封存在角落里的记录。你知道它们存在,但很少真的回头整理,也很难从中看出一条更长的线索。
现在,AI 给了这些痕迹一次被重新调动的机会。
你可以不再只问“这本书讲了什么”,而是开始问:过去一年,我到底在读什么?
我是不是一直在围绕同一个困惑打转,只是自己从来没有意识到?
实测微信读书 Skill
微信读书 Skill 安装很方便,用户进入网站(https://weread.qq.com/r/weread-skills),把安装指令和 Key 告诉正在用的 Agent。
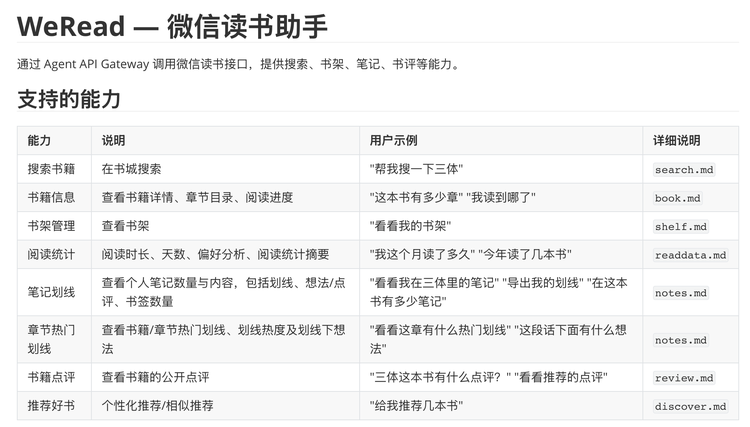
具体来看,微信读书 Skill 提供的能力并不复杂,基本围绕一个读书 App 最核心的几类数据展开。
它可以搜索书籍,查看一本书的详情、目录和阅读进度。也可以读取你的书架,知道你收藏了哪些书、哪些还在读、哪些已经读完。
它能调用阅读统计和笔记划线,比如这个月读了多久,今年读了几本书,在哪些书里留下了划线、想法和书签。还能查看一本书或某个章节的热门划线,看看其他读者普遍在哪些地方停下来,也能读取公开书评,或者根据你的阅读记录做个性化推荐。
比如可以让微信读书 Skill 把所有的划线句子导出来。

当然,都用上 AI 了,自然要把大模型的生成能力应用起来,而不是当成单纯的 API。
接下来,用几个具体场景试一下,当微信读书里的阅读数据真的被 AI 调动起来,它到底能帮用户做什么。
场景一:问问自己到底在读什么
prompts:我最近真正投入的是哪些书?哪些只是收藏?我的阅读兴趣有没有变化?
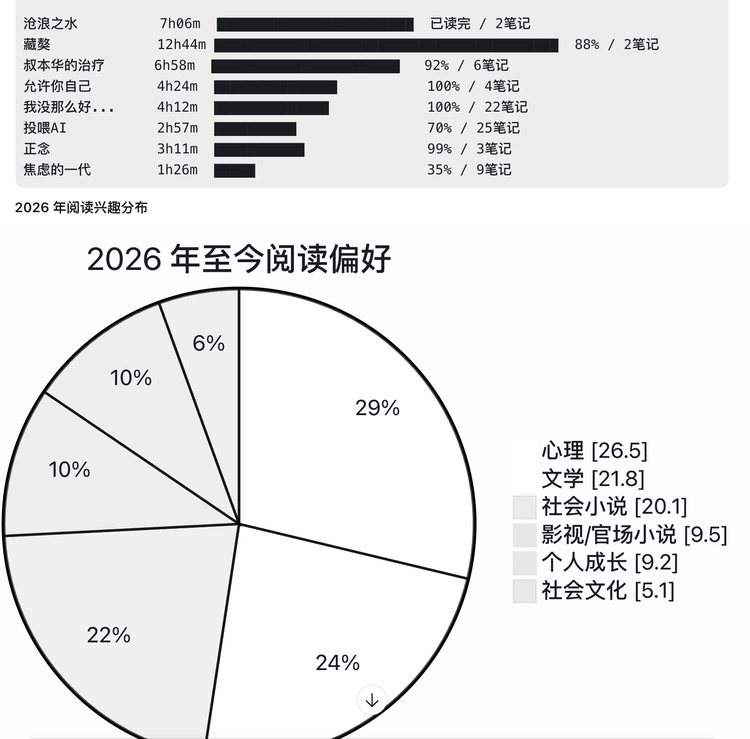
利用微信读书 skill 可以观察自己近几年的读书口味有没有变化,也许能从侧面反应你的工作、心态等。比如微信读书 skill 就识别到 25 年我比较偏好推理小说,到了 26 年会阅读更多心理学的书籍。

因为是用 Agent,所以可以同时调用其他的一些技能,对结果进行优化,比如用图表进行阅读偏好可视化。每个月做一次阅读总结,理解自己。
场景二:跨书整理一个主题
prompts:把我在不同书里关于 AI、组织、财富、教育、写作的划线都找出来,拼成一份个人主题笔记。
我们阅读的时候,经常不是一本书读完就结束,而是在很多书里反复遇到同一个问题。比如你可能在管理学书里看到组织协作,在 AI 创业书里看到组织效率,在心理学书里看到个体动机。
微信读书 skill 可以把这些散落在不同书里的划线、想法、书评重新捞出来。Agent 不只是帮你“导出笔记:,而是把你过去几年反复关注的问题重新拼起来,变成一份真正属于自己的主题知识库。

由于文档太长了,我们就简单看一下各个主题引用,以及生成的小短文。


prompts:从我的划线里提炼 10 个可以继续写作的选题。
同时用户也可以用微信读书的划线数据,去策划一些新的选题内容,很适合读书博主。

场景三:找下一本真正会读的书
prompts:根据完读率高、笔记多、最近投入时间长的书,推荐下一本更可能读下去的书。
很多时候,我们收藏的书和真正读下去的书不是一回事。书架里可能有很多“我觉得自己应该读”的书,但真正打开、划线、读完的,才反映了你当前真实的兴趣和状态。
微信读书 skill 可以结合书架、阅读进度、笔记数量、阅读时长这些数据,帮你判断:你不是缺书,而是需要找到下一本更符合当下状态的书。

场景四:看新闻推荐书
prompts:最近豆包收费新闻很火,有没有可以解释这次事件的书?
新闻每天都很多,但真正有价值的不是追热点,而是借热点重新理解一个长期问题。比如豆包收费这类新闻,背后可能不只是一个产品开始变现,而是 AI 应用商业模式、用户付费心理、平台竞争和大模型成本结构的集中体现。
这时候你就可以调用 Skill,让其推荐书。

然而,微信读书 Skill 无法做到把推荐的书直接加入书架,有点可惜。
它开放了读取,却没有开放写入。AI 可以帮你找到下一本该读的书,却不能直接把它放进书架,可以帮你整理划线笔记,却不能把整理后的主题笔记写回你的微信读书账户。用户和 AI 的交互发生在 Skill 软件外面,数据流是单向的。
传统软件的第三条路
过去十几年,传统软件记录了我们越来越多的行为数据:听过什么歌、练过什么、买过什么、读过什么、划过哪些句子。
但这些数据从一开始就不是为用户准备的,它们更多被用来优化推荐、提高留存、刺激点击。用户想重新理解自己,反而要翻页面、导表格、复制粘贴,平台并没有把解释权交出来。
AI 时代让这件事出现转机。AI 原生应用正在用自然语言交互和上下文调用吃掉传统软件的地盘。传统软件如果只是加一个 AI 搜索框、塞一个 AI 助手,很难真正反击。它们最有价值的资产,其实是过去十几年沉淀下来的用户行为数据。
把这些数据开放给用户自己的 AI 调用,并不等于削弱平台。相反,当用户能用 AI 回看自己过去一年把时间花在哪里、哪些习惯坚持了下来、哪些兴趣发生了变化,平台就不再只是工具,而会变成数字生活的“记忆中枢”。
锁死数据只能换来被动停留,开放数据反而可能换来主动依赖。
微信读书最近推出的官方 Skill,走的就是这条路。它没有停留在 AI 搜书、AI 问书这些表层功能,而是把书架、阅读进度、阅读统计、划线、想法、书评、热门划线和推荐等阅读行为,以自然语言可调用的方式交还给用户。过去散落在 App 各个页面里的数据,现在可以被重新调动、交叉和追问。
从这个角度看,传统软件拥抱 AI 有三条路,第一是功能 AI 化,在产品里加入口,最容易同质化,
第二是内容 AI 化,把内容库开放给 AI,但也会成为其他产品的数据库。第三是用户数据 AI 化,把只有平台才拥有的个人行为数据,开放给用户自己的 AI。微信读书选择的正是第三条。
它真正的护城河不是书库,而是用户在这里留下的多年阅读痕迹,几千条划线、几百条想法、几十个完整阅读周期。
这些数据有时间重量,也有情绪附着。
AI 原生应用可以从零设计交互,却无法凭空生成一个人过去五年的阅读历史。这正是传统软件少有的反击机会。
每日要闻


AI阅读助手

以下有两点提示,请您注意:
1. 请避免输入违反公序良俗、不安全或敏感的内容,模型可能无法回答不合适的问题。
2. 我们致力于提供高质量的大模型问答服务,但无法保证回答的准确性、时效性、全面性或适用性。在使用本服务时,您需要自行判断并承担风险;
感谢您的理解与配合






该功能目前正处于内测阶段,尚未对所有用户开放。如果您想快人一步体验产品的新功能,欢迎点击下面的按钮申请参与内测
申请内测






0 条评论
请「登录」后评论
取消
发布