 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库26年6月2日,全球AI资讯约20条:材料版AlphaFold来了 40个工业任务全方位SOTA、VAST 斩获近2亿美元A轮系列融资 同步推出世界模型等

昨日,AI领域发生了多项重要事件和进展,共计约20条汇总如下。
AI应用进展和演化
1-1. 英伟达版「MacBook Pro」曝光:老黄自研了CPU!
英伟达真要造“AI笔记本”了!传闻中的N1X芯片首次获多方“盖章”——英伟达、微软、ARM几乎同步发帖暗示,将在6月初台北Computex大会上发布。这颗芯片堪称“英伟达版M系列”:20核ARM CPU(联发科合作)、Blackwell架构GPU(含6144个CUDA核心)、128GB LPDDR5X统一内存。
亮点是CPU与GPU共享内存,专为AI本地运行优化,适合部署大模型、智能体和自动化任务。但短板也很明显:ARM架构不原生兼容x86游戏和传统软件,需模拟运行;内存带宽约273GB/s,远低于独显GDDR方案,游戏体验受限。简单说:它不是游戏本,而是面向开发者的“AI印刷机”——就像古腾堡印刷机让知识平民化,N1X有望让AI算力从云端订阅走向一次性硬件投入、零边际成本使用。https://www.qbitai.com/2026/05/426991.html

1-2. 今天起,无限期免费!全球首个全模态API开放,Top 10 AI Lab出手
全球首个“文本+图像+视频”全模态免费API正式上线!由全球Top 10 AI实验室——Agnes AI推出,即日起无限期免费开放。三大核心模型全部可用:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash(精准还原复杂Prompt)、视频模型Agnes-Video-2.0(15秒内生成电影级《龙族苏醒》片段,支持音画同步、运镜控制)。
实测显示,其文本模型登顶Claw-Eval榜单,图像/视频模型分别跻身Artificial Analysis权威排行榜前列。开发者只需注册获取API Key,5分钟即可接入;设计师、短视频团队也能直接调用生成素材。此举大幅降低AI应用门槛——过去做一次Agent测试可能花几十元,现在零成本试错。https://www.qbitai.com/2026/06/427332.html

1-3. Token贵只因你喂给模型的垃圾太多了丨@亚马逊王晓野AIGC2026
在2026中国AIGC产业峰会上,亚马逊云科技技术总监王晓野一针见血指出:Token贵,往往不是因为单价高,而是你喂给AI的“垃圾信息”太多——比如不加筛选地塞入冗余技能、未压缩的长记忆、重复或过时的数据,导致模型反复处理无效内容,白白消耗算力与成本。
数据显示:87%的企业已宣称大规模部署AI,但真正从中获得生产价值的仅约10%。原因在于,个人玩转一个“龙虾”(Agent)和企业让数千个Agent在安全、可信、不中断的分布式环境中稳定运行,是完全不同的工程挑战。王晓野提出落地四大鸿沟:模型灵活切换难、复杂系统稳定性差、业务人员使用门槛高、端到端AI人才严重短缺。https://www.qbitai.com/2026/06/427141.html
1-4. 材料版AlphaFold来了!40个工业任务全方位SOTA,AI4S迎来行业大突破
近日,中国团队“深度原理”推出材料领域首个类大语言模型训练范式的基座模型——MPA,被称作“材料版AlphaFold”。它不靠刷理论榜单,而是直面真实工业难题,在40个覆盖催化、能源、制药等领域的实际实验任务上全部拿下SOTA(当前最佳性能),尤其在最难的“骨架划分”测试(即预测从未见过的分子结构)中,平均误差降低14.6%,35个性质刷新纪录。
MPA成功的关键在于两大创新:一是引入LLM式的三阶段训练(预训练+中期“物理对齐”训练+后训练),用第一性原理计算数据帮AI建立“物理直觉”,不再只记分子形状;二是设计Hybrid Readout混合预测头,让模型自主选择“自由感知”(如生物活性)或“原子累加”(如燃烧焓)两种逻辑。https://www.qbitai.com/2026/06/427142.html

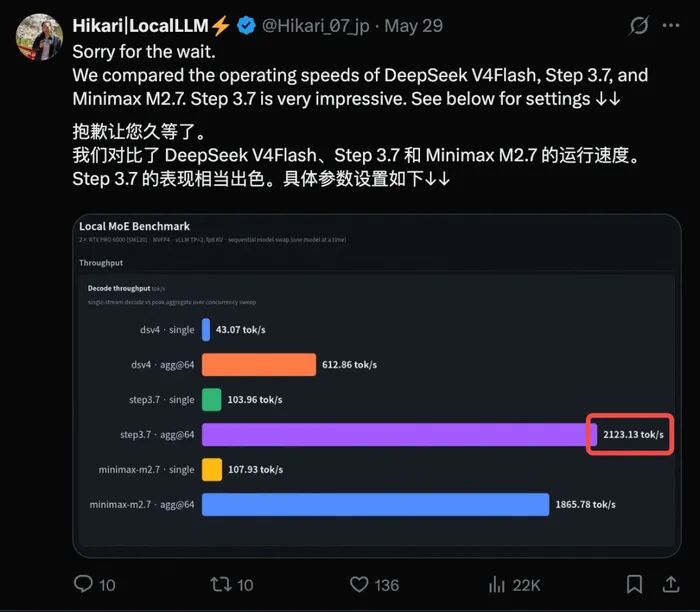
1-5. 400 tokens/秒!阶跃Step 3.7 Flash,把Agent任务成本打到Claude零头
阶跃星辰最新发布的Step 3.7 Flash多模态大模型,标志着Agent从“能说”迈向“能干”的关键转折。它不是追求参数或单点分数的“学霸”,而是专为真实生产场景打造的“高效执行者”:推理速度高达400 Tokens/秒,单任务成本仅0.19美元——约为Claude Opus 4.6(1.76美元)的1/9,却达成其97%的编码性能。
模型仅激活11B参数(总参196B+1.8B ViT),靠MoE架构与“顾问模式”实现又快又省。实测中,它能自动整理12张模糊发票生成Excel、在Blender截图中精准指导删方块、为剪映导出提醒1080i/1080P陷阱、甚至自主写代码→渲染测试→回改闭环。在ClawEval-1.1复杂任务评测中达67.1分,超越DeepSeek V4 Flash(57.8)和Kimi K2.6(62.3)。https://www.163.com/dy/article/KUC0DTF20511ABV6.html
1-6. 牧原与阿里云达成AI战略合作 联合打造AI助手将猪群健康检测提效超百倍
6月1日,全球最大的生猪养殖企业牧原集团与阿里云达成AI战略合作,联手打造“智能养猪大模型”。依托牧原积累的海量养殖数据和兽医经验,结合通义千问大模型与阿里云智算能力,“小牧助手”已率先落地应用。
该AI工具可综合18项结构化数据(如体态、病史、环境)及专家诊断知识,支持语音、图片等多模态输入,实现呼吸道病、腹泻、传染病等常见猪病的秒级识别与研判,并自动生成含诊断建议和成本分析的报告。上线仅两个月,它将每批次约600头猪的健康检测时间从20分钟压缩至“秒级”,效率提升超100倍,显著缩短疫情响应窗口,降低死亡率。目前,牧原全产业链(饲料、育种、养殖、屠宰)已全面上云,所有物联网设备接入阿里云平台。https://www.leiphone.com/category/industrynews/a1O4dfBTREuQ2uLq.html

AI大模型算法、赛事和会议
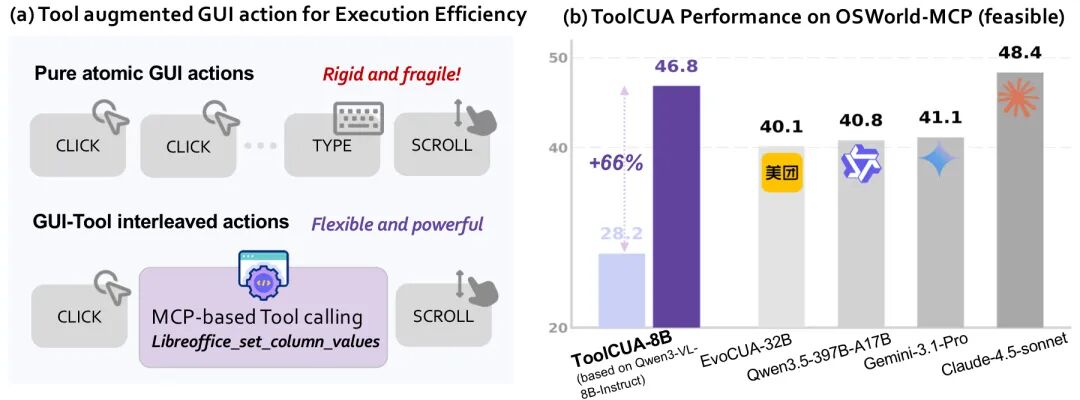
2-1. 别光给Agent加Tool了,它根本选不明白!复旦×通义提出全新CUA训练范式
一种新型计算机使用智能体(CUA)训练方法——ToolCUA,由复旦大学等联合提出。传统AI助手在面对图形界面操作和工具调用时常常“不会选路”:该点按钮时乱调API,该调工具时又死磕菜单,导致准确率不升反降。实验显示,强模型如Claude-4.5-Sonnet接入工具后,准确率竟从61.9%跌至48.4%;Qwen3VL-8B平均仅调用0.003次工具,几乎无视高效能力。
ToolCUA通过两阶段训练破解难题:先用合成数据教会模型识别“何时该用GUI、何时该调工具”,再通过在线强化学习优化整条执行路径。结果显著:ToolCUA-8B在OSWorld-MCP基准上达46.85%准确率,比基线提升约66%,步数降至14.93(业内最低),工具调用率(TIR)从8.41%升至24.32%。https://www.qbitai.com/2026/05/427005.html
AI人才和资本动态
3-1. 近2亿美元!VAST完成新一轮融资,正式披露世界模型路线
VAST公司近日完成近2亿美元A+及A++轮融资,成为国内AI世界模型领域最受资本青睐的初创企业之一。其核心突破是正式发布“Project Eden”世界模型技术路线——首次将世界状态推演与视觉渲染原生解耦,实现三大关键能力:环境永久存在(镜头移开后世界仍在运行、场景可复用可编辑(多人操作结果实时留存)、原生支持多用户/智能体并发交互。
相比Google DeepMind的Genie(单视频模型)或World Labs的Marble(静态3D),VAST更强调“时间+物理+交互”的动态演化。背后依托Tripo系列三年积累:全球最大原生3D数据集、超30个开源项目、2000万创作者生态,以及Tripo H3.1(雕塑级精度)、P1.0(秒级生产网格)、8K贴图(2分钟替代3天人工)等硬核成果。https://www.qbitai.com/2026/06/427516.html

3-2. 李飞飞、Jeff Dean押注!不卷大模型,专练越用越聪明的AI
Trajectory是一家聚焦“AI持续学习”的新基建公司,不造大模型,而是打造让AI在真实使用中越用越聪明的基础设施。它刚获1500万美元种子轮融资,估值1.15亿美元,获Jeff Dean、李飞飞等顶尖AI科学家背书。
核心洞察是:当前大模型仍是“静态出厂品”——客服AI不会因你处理了1000个工单而变专业,法律AI也无法自动吸收最新判例。Trajectory借鉴Cursor的成功逻辑,将用户每一次点击、修改甚至失败交互(如客服转人工),转化为训练数据,对开源模型进行高频后训练——最快一周一次更新,远超行业平均数月一版的节奏。其技术底座是标准化的“Trajectory”数据格式,把对话拆解为可审计、可评估的训练单元,并由客户自主控制数据合规与模型审批。https://www.163.com/dy/article/KUAVT4CI0511ABV6.html
3-3. 蚂蚁、滴滴、德联领投,简智机器人完成数亿元多轮融资 领跑具身智能无本体数据赛道
简智机器人近日完成数亿元融资,由蚂蚁集团、滴滴、德联资本领投,顺为资本、百度风投等老股东跟投,成为具身智能无本体数据领域迄今最大单轮融资,累计融资额行业第一。公司聚焦“用高质量数据驱动具身AI进化”,摒弃低质数据堆砌,首创“从模型定义数据标准”理念。
核心技术亮点突出:自研高保真采集硬件,实现<1ms多设备同步,6×200M相机+多模态传感(触觉、力觉、声音等),覆盖“头手+全身”行为;行业首个端到端Data Foundation Model(DFM),手部追踪精度达1cm,6D姿态感知达亚毫米级;搭建Gen ADP众包产线,覆盖3000+用户、10000+真实场景,月产Ego+手部高精度数据超10万小时,累计沉淀百万小时真实数据、2000+项人类实操技能。https://www.leiphone.com/category/industrynews/QrM9kQS2werl2oJO.html

3-4. 曾拿下华为最高个人荣誉!清华博士下场做AI4S,融资数亿
量坤科技是一家成立于2026年1月的AI for Science(AI4S)初创公司,近日完成数亿元人民币天使轮及天使+轮融资,由英诺天使基金领投,国汽投资、北工投资、BV百度风投等多家知名机构跟投。公司聚焦“量子计算+AI+高性能计算(HPC)”三技术融合,打造新一代科学计算平台,旨在提升分子模拟、材料设计、药物研发等复杂科研问题的求解精度与效率。
创始人吕定顺博士是清华量子计算方向早期博士之一,曾深度参与离子阱量子计算机研发,并在华为、字节跳动AI4S Lab工作7年,主导开发了高精度量子化学平台ByteQC。目前团队近40人,来自清华、北大及国际科研机构,覆盖多学科领域。https://view.inews.qq.com/k/20260601A04MWG00

3-5. 连续完成五源、峰瑞两轮数千万元融资,清华00后团队要解决Token账单焦虑|智能涌现首发
万格智元是一家由00后清华博士王冠博创立的端侧AI技术公司,团队20人中近90%为00后,多来自清华、北大及OpenAI、字节等顶尖机构。公司刚完成数千万元天使轮融资,聚焦解决“大模型跑不进手机、PC等小内存设备”的行业痛点。
传统端侧推理引擎内存占用高——32GB内存设备通常仅能部署4B参数模型;而其自研引擎cPilot通过动态稀疏化算法和底层带宽优化,将同一硬件上可运行模型提升至80B,内存占用从27.6GB压至4.7GB,单台设备硬件成本直降约2000元。配套智能平台Amis支持端云协同调度,让80%–90%轻量任务本地完成(Token成本为零),仅复杂任务上云,综合成本大幅降低。https://aitntnews.com/newDetail.html?newId=25734
3-6. 光速创投领投5900万美元,Reactor剑指世界模型基础设施,做实时AI世界的“AWS”
Reactor是一家由前Apple Vision Pro两位核心负责人联合创办的AI基础设施公司,近期完成5900万美元种子轮及A轮融资。它不研发世界模型,而是打造让顶尖世界模型“即插即用”的底层平台——通过统一SDK和API,开发者仅需少量代码,就能在毫秒级内构建实时、可交互的3D/AI环境。
这标志着AI正从“生成一段视频”(如Sora需数十秒渲染)迈向“构建一个可感知、可响应的世界”。其技术已支持浏览器直接运行AI实时生成的动态场景(如跑车驰骋外星沙漠),大幅降低开发门槛。AWS成为其首选云伙伴,提供全球低延迟算力;好莱坞元老、梦工厂联合创始人Katzenberg以董事会观察员身份加入,印证其在媒体与具身智能(Physical AI)双赛道的战略价值。https://aitntnews.com/newDetail.html?newId=25720
3-7. 牛津博士创业AI抗衰老药物,无尽方舟完成千万元种子轮融资
无尽方舟是一家成立于2026年5月的AI驱动抗衰药物公司,刚完成数千万元种子轮融资(Monolith领投、九合创投跟投)。它不走传统“先人后宠”老路,而是独创“宠物先行、反向赋能人类”的路径:利用猫狗较短生命周期(犬约12–15年),快速验证抗衰药效——目前已启动猫狗临床试验,并同步建设两大AI平台。
H2P跨物种迁移模型(对齐人/犬/猫单细胞转录组数据,筛选保守衰老靶点)和干湿结合药物研发系统(AI设计分子+实验闭环反馈)。团队极强:6位牛津博士领衔,CTO为伯克利博士后、师从诺奖得主Jennifer Doudna。其核心逻辑是——炎症、线粒体衰退等关键衰老机制在哺乳动物中高度保守(已有大量多组学数据支持),但需逐靶点实证。https://aitntnews.com/newDetail.html?newId=25719
AI风险与政策管理
4-1. Claude刷爆5亿!一夜涨60倍,你的Token账单还撑得住?
近期AI账单“爆仓”事件频发,暴露出智能体时代成本失控的新风险:一家企业因未设Claude账号用量上限,1个月烧掉近5亿美元;谷歌云用户API密钥泄露,7美元预算被刷至1.8万美元;OpenAI内部实验中,3人团队指挥100个Codex智能体,30天耗用6030亿Token、账单达130万美元。
根本原因在于计费模式剧变——OpenAI、GitHub等平台自2026年4月起全面转向按Token精确计费,淘汰“一刀切”月费制。这使轻度聊天与重度智能体任务的成本差异拉大数百倍。更严峻的是,“Tokenmaxxing”(为排名盲目刷消耗)等行为泛滥,暴露管理漏洞。研究证实:智能体任务耗Token可达普通对话的上千倍,但高消耗≠高准确率,成本常在中等水平即达收益拐点。https://www.163.com/dy/article/KUB72VQB0511ABV6.html
写在最后
欢迎大家关注、分享、转发本公众号,也欢迎直接与小编联系 对接合作~
小问卷:公众号打分点评





