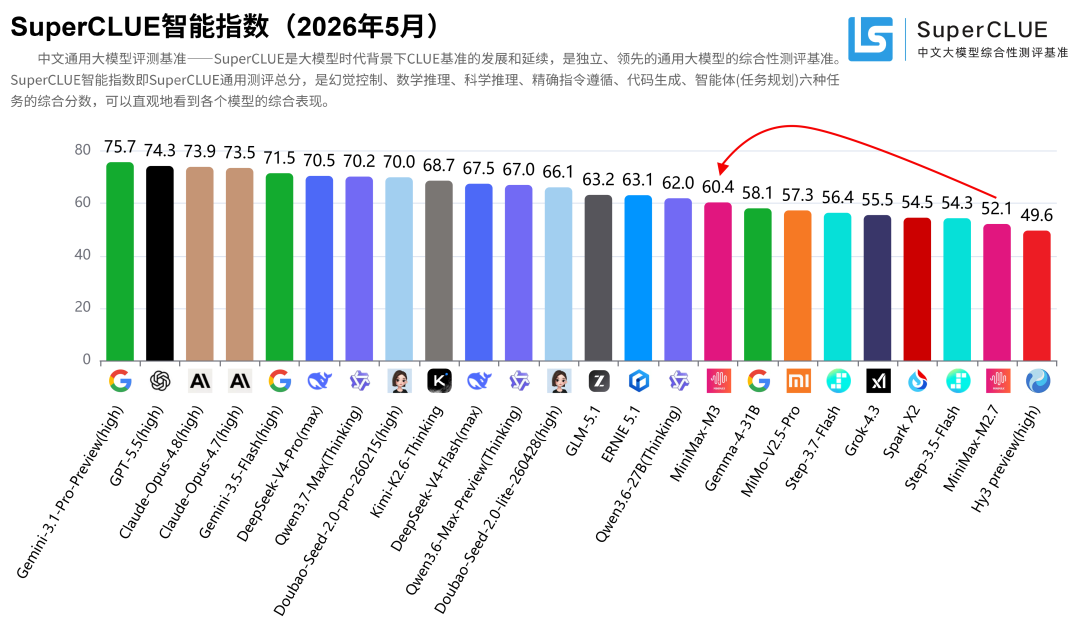
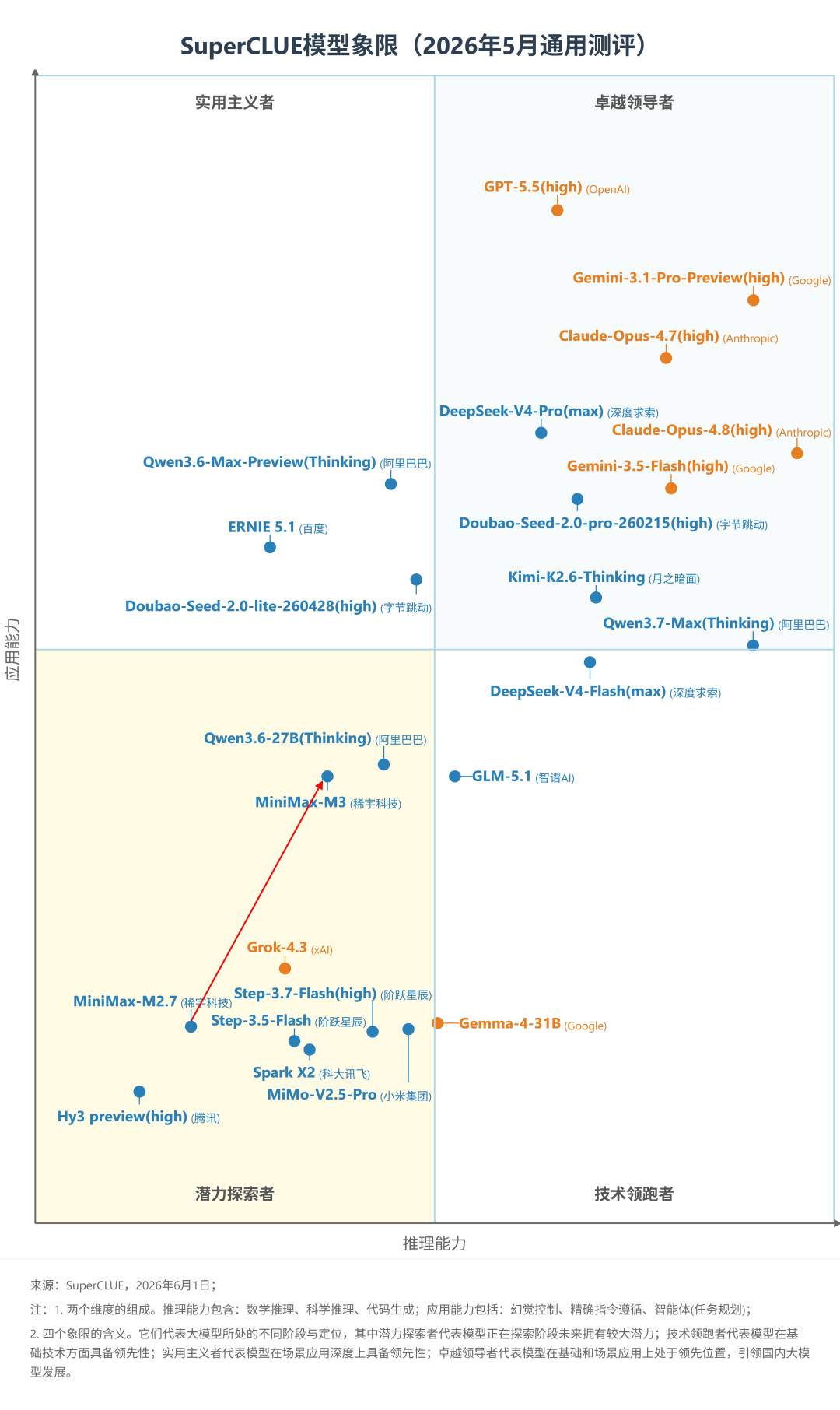
MiniMax-M3中文测评出炉:科学推理、智能体任务、幻觉控制、代码均有提升!
发布时间:2026-06-02来源:CLUE中文语言理解测评基准
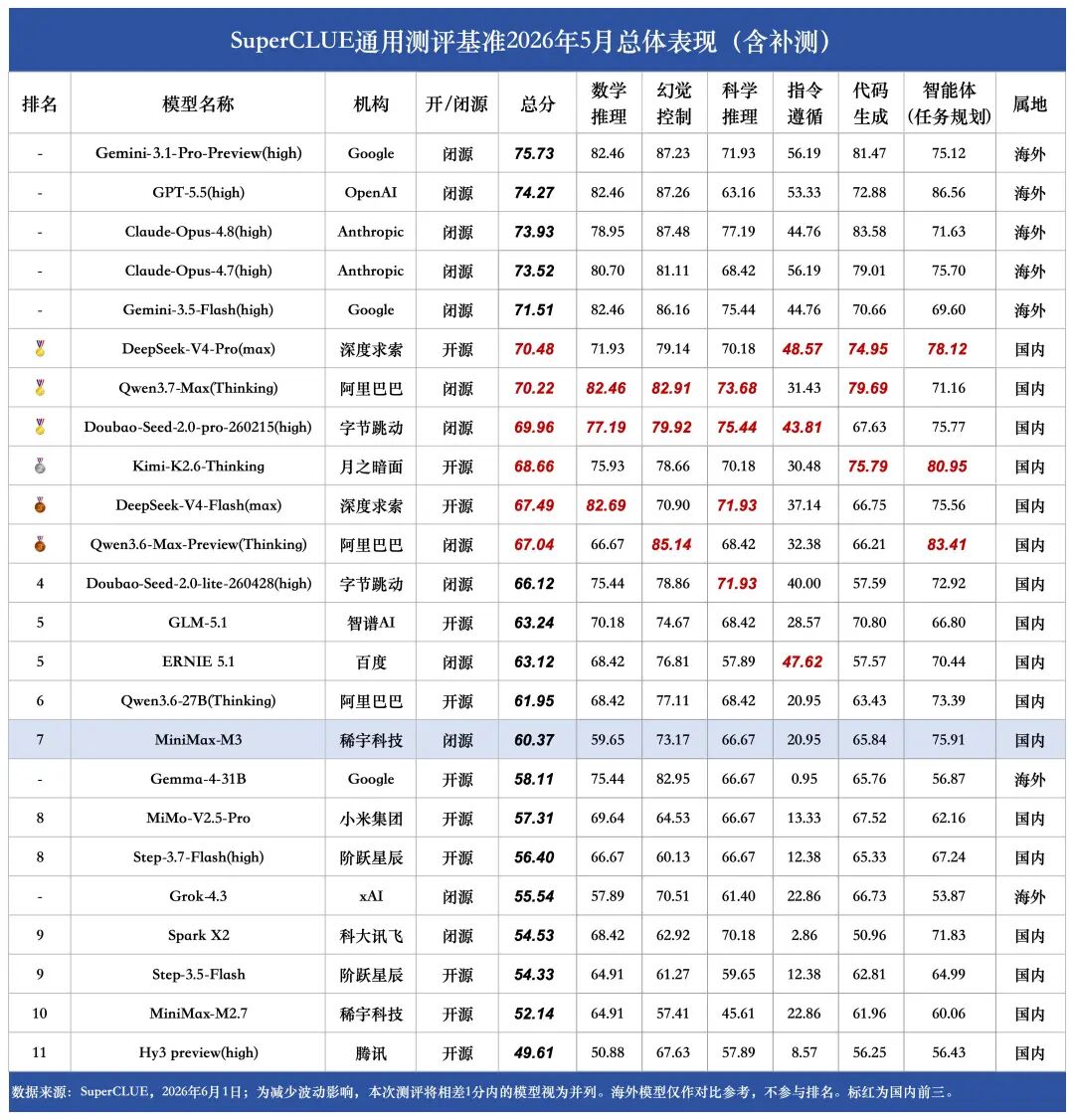
2026年6月1日,稀宇科技正式推出原生多模态模型MiniMax-M3。该模型不仅能处理图片和视频输入,还可直接操控电脑桌面,并拥有高达100万token的超长上下文记忆能力。据官方称,在编程、智能体等专业任务中,MiniMax-M3的表现媲美GPT-5.5、Opus-4.7、Gemini-3.1-Pro等业界顶尖模型,达到领先水平。
SuperCLUE团队基于2026年5月中文大模型测评基准体系2026年5月中文大模型基准测评结果发布!DeepSeek、Qwen3.7、豆包竞争激烈!对MiniMax-M3进行了测评,以下是测评结果与分析:点击 文末阅读原文 或 复制下方网址到浏览器 即可跳转SuperCLUE官网查看完整的测评内容:
SuperCLUE官网地址:www.superclueai.com
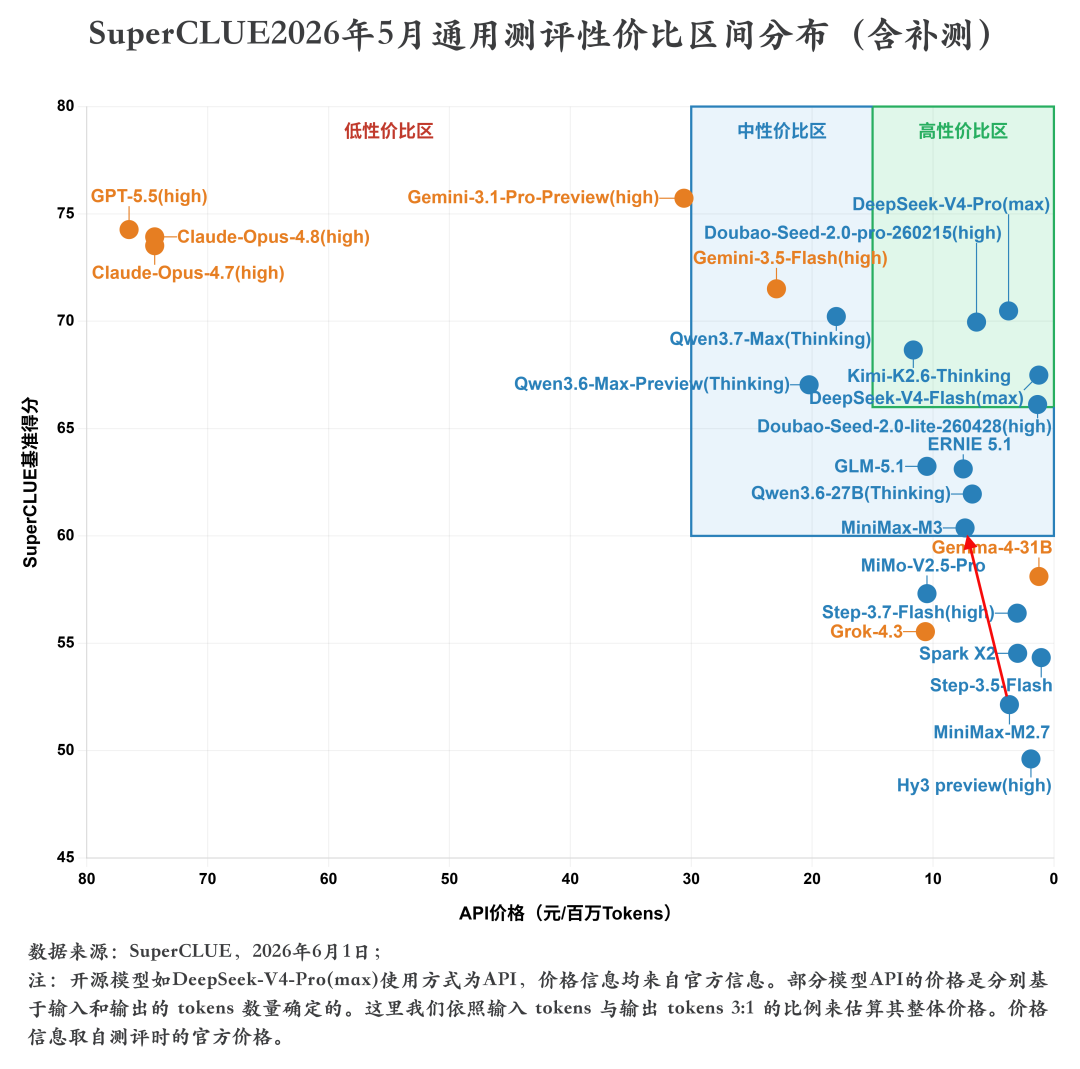
三、性价比区间分布(2026年5月)
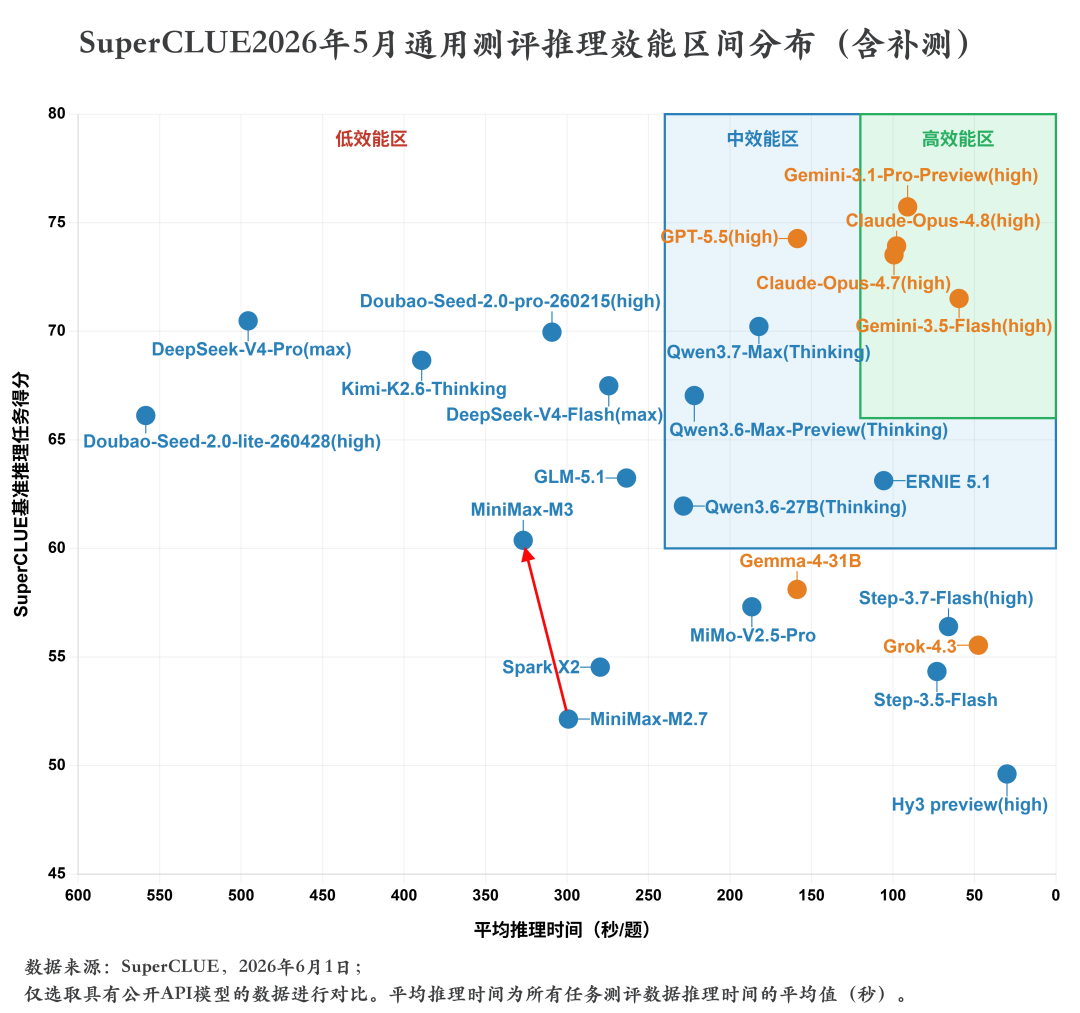
四、推理效能区间分布(2026年5月)
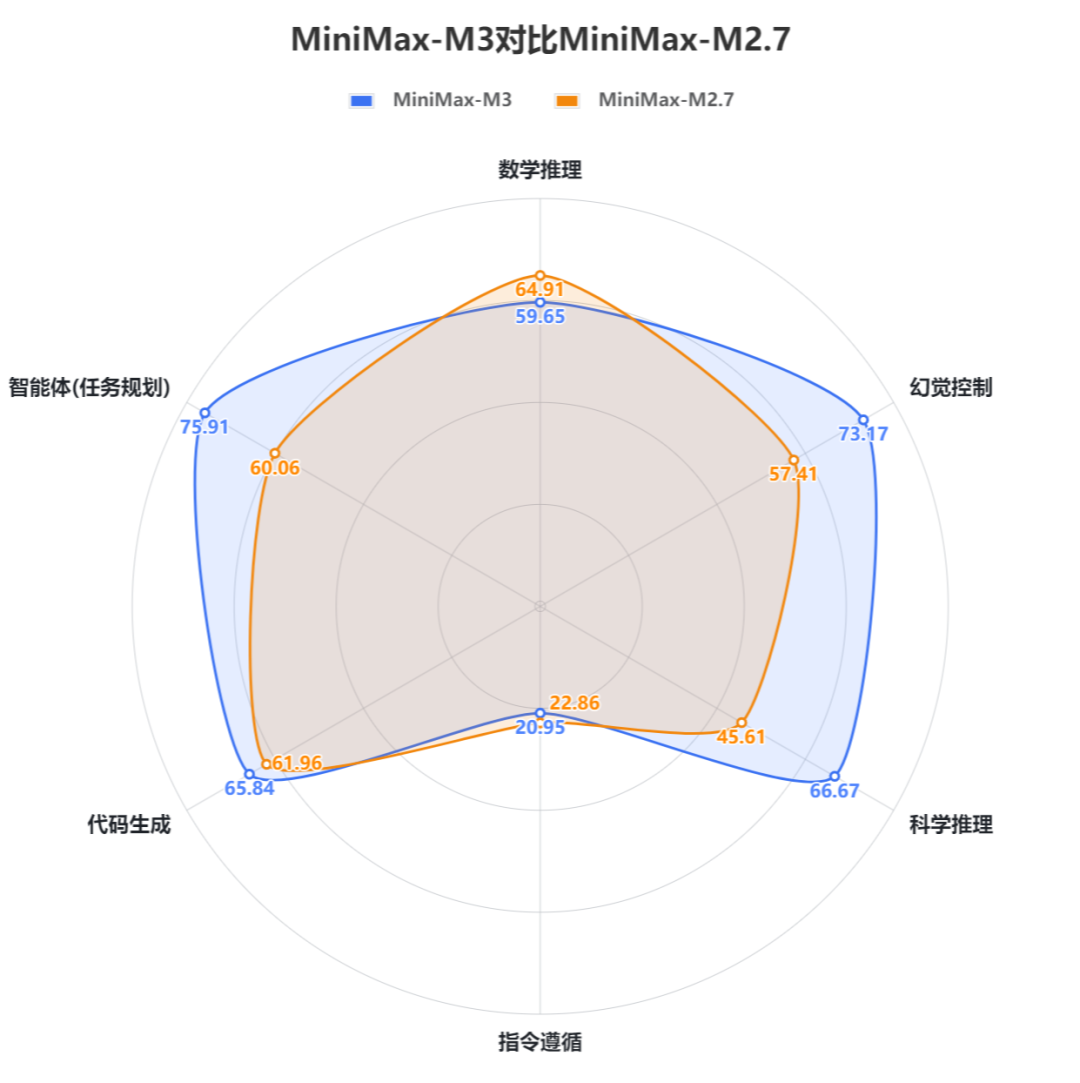
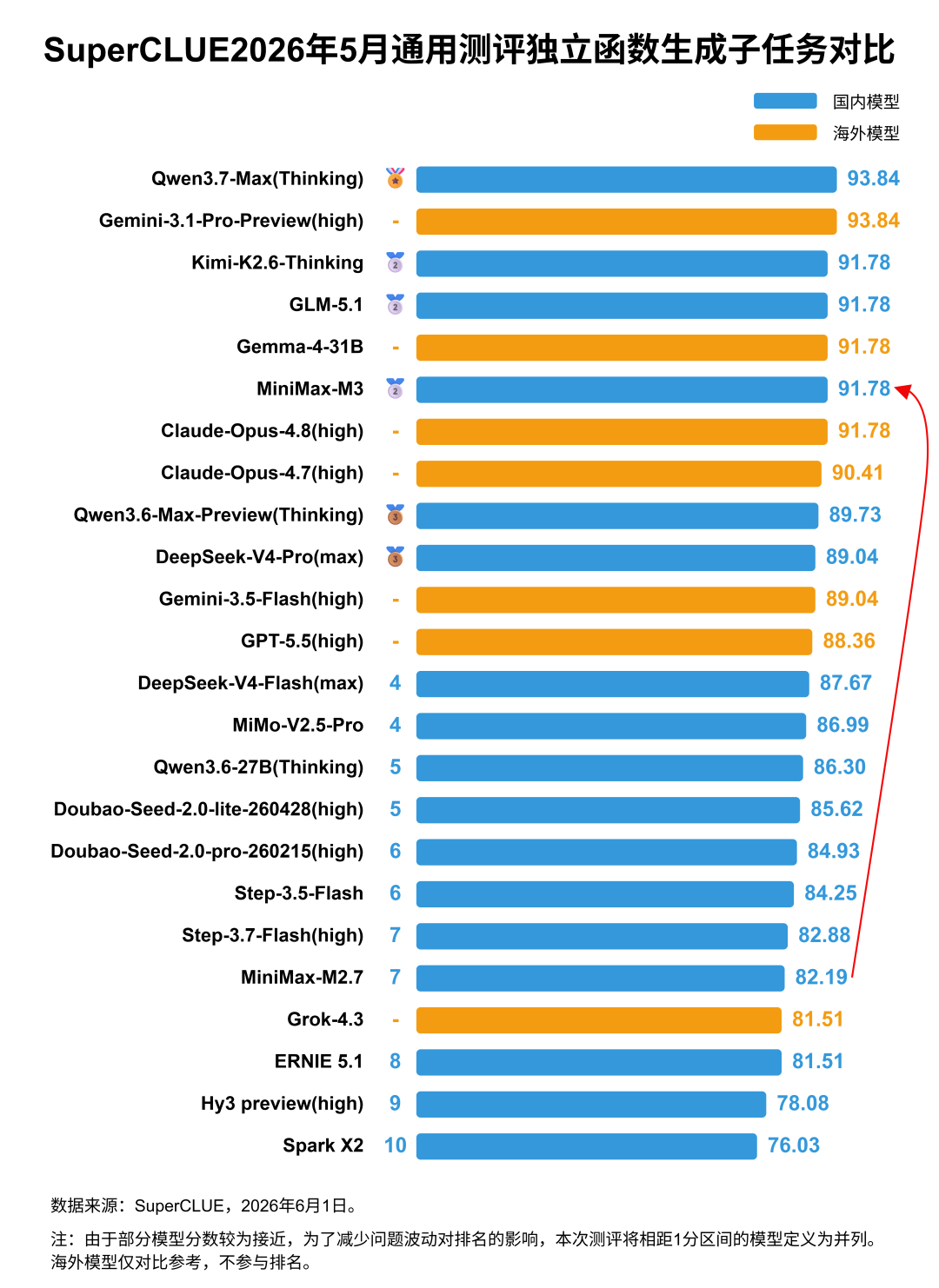
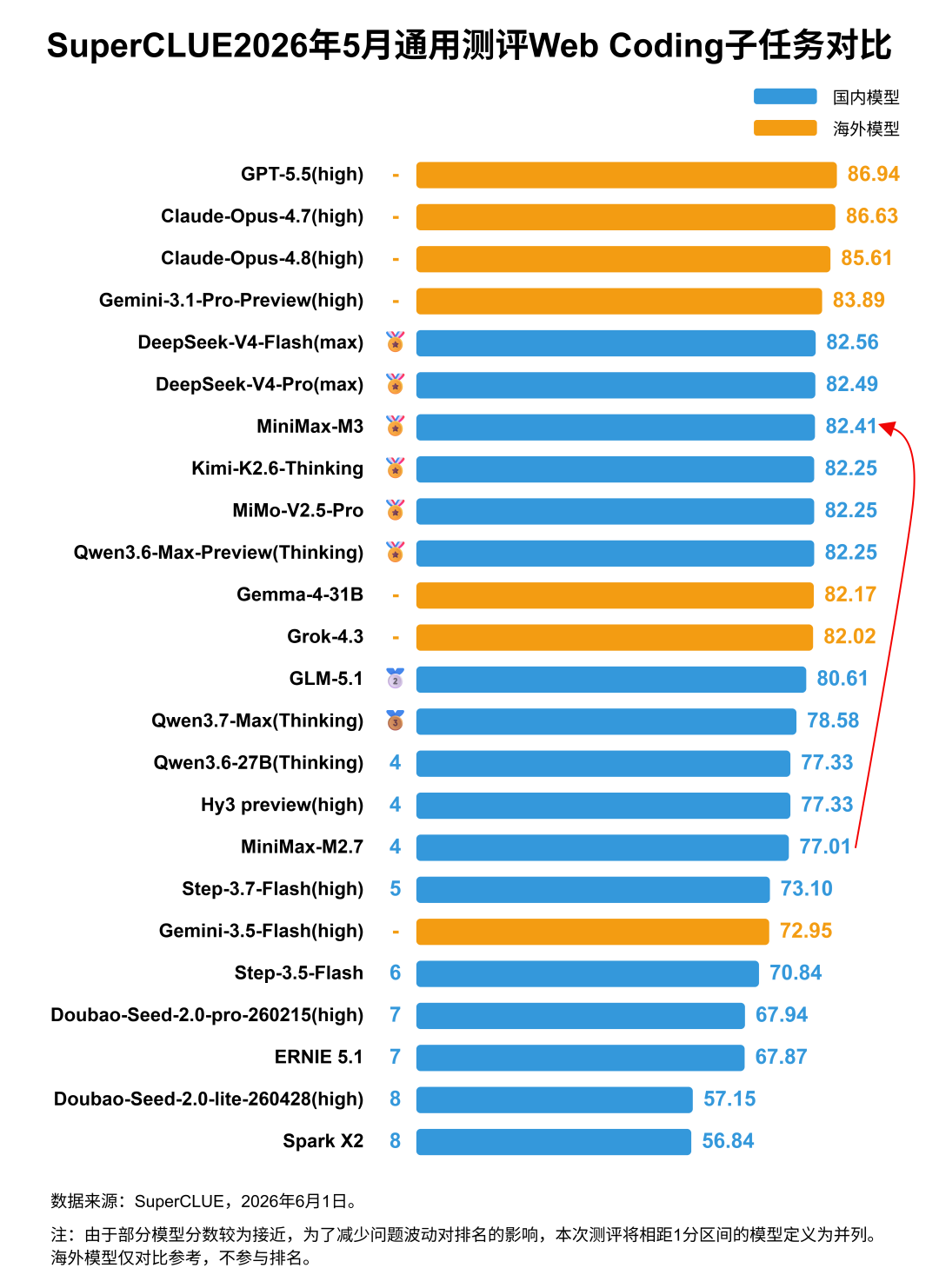
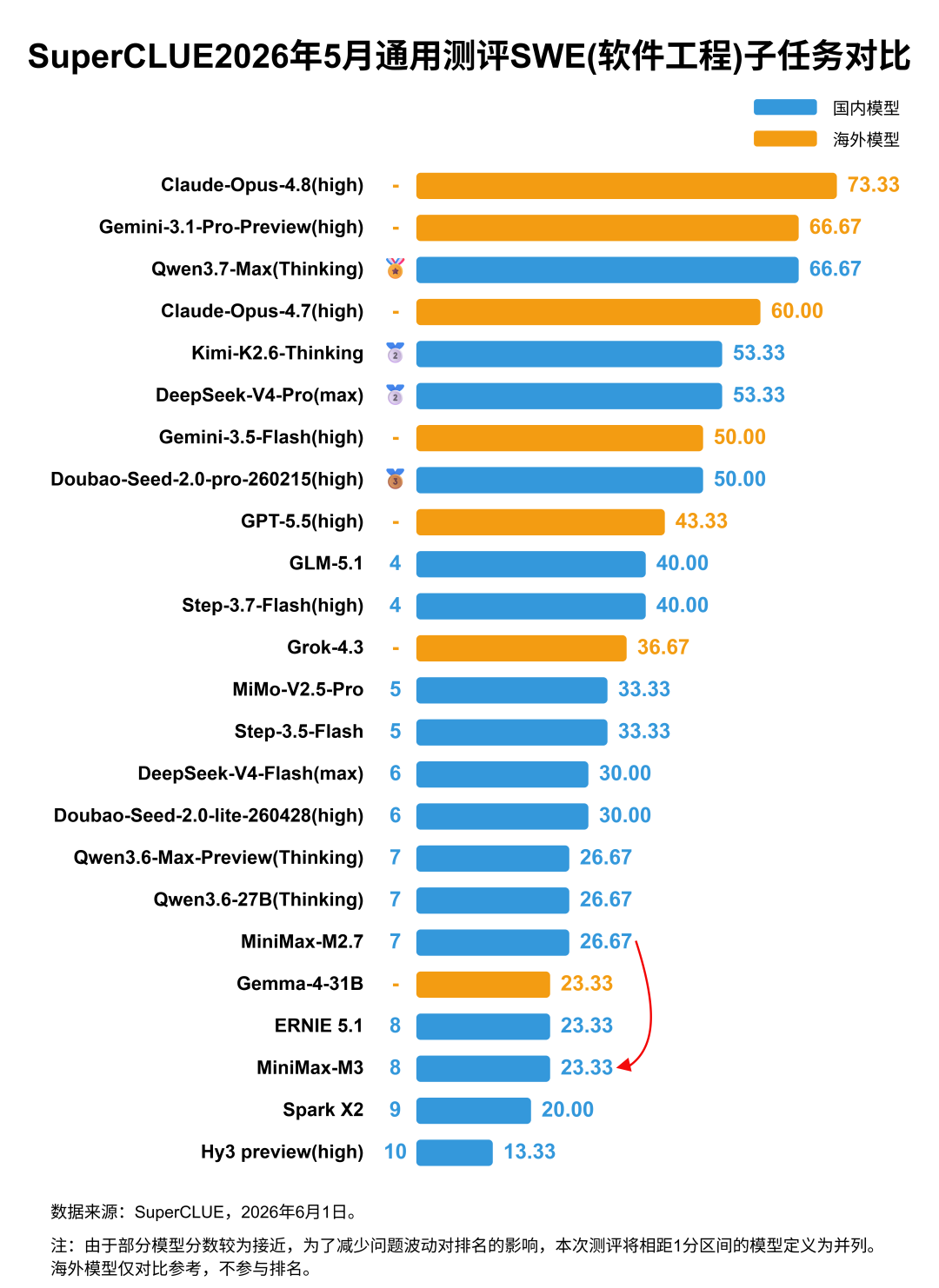
一、MiniMax-M3对比MiniMax-M2.7。1. MiniMax-M3在科学推理、智能体(任务规划)、幻觉控制三大任务上相较于上个版本均有显著提升,其中科学推理由45.61分提升至66.67分,提升21.06分;智能体任务由60.06分提升至75.91分,提升15.85分;幻觉控制由57.41分提升至73.17分,提升15.41分。2. MiniMax-M3在代码生成任务上有近4分的提升,由61.96分提升至65.84分。具体来看,M3在独立函数生成和Web Coding两大子任务上均有较大幅度的提升,其中独立函数生成子任务由82.19分提升至91.78分,Web Coding子任务由77.01分提升至82.41分,进入国内乃至国际前列。但在SWE软件工程这类复杂度和难度更高的任务上表现平平(存在大量超时未能成功获取答案的题目),甚至略有下降,从M2.7的26.67分下降到23.33分。3. MiniMax-M3在精确指令遵循和数学推理任务上均有小幅下降,其中数学推理与软件工程一样由于超时导致多个题目失败。1. MiniMax-M3的API价格(7.35元/百万Tokens,非优惠价格)相较于上个版本(3.68元/百万Tokens)增加2倍,但整体性能提升较大,由低性价比区间进入中性价比区间。2. MiniMax-M3的推理耗时(326.88秒/题)相较于上个版本(299.16秒/题)增加了近28秒,推理效能有待提升。测评说明
本次2026年5月通用基准测评共有24个国内外模型参与(包括补测模型),测评集包括六大任务:数学推理、科学推理、代码生成、智能体(任务规划)、精确指令遵循、幻觉控制,共492题。详细的测评说明可见介绍文章:2026年5月中文通用大模型测评通知!
[1] CLUE官网:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜网站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark/SuperCLUE
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库