 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库26年6月3日,全球AI资讯约15条:Anthropic抢先交表 冲击AI史上最大IPO、韩国AI推理芯片商XCENA完成1.35亿美元B轮融资等

昨日,AI领域发生了多项重要事件和进展,共计约15条汇总如下。
AI应用进展和演化
1-1. Cosmos 3 : 英伟达开源的全模态物理 AI 基础大模型
英伟达在台北GTC大会发布Cosmos 3——全球首个完全开源(Apache 2.0)的全模态物理AI世界模型。它用一个混合Transformer架构,原生打通文本、图像、视频、环境音效、动作五大模态,首次实现“理解物理规律→预测未来状态→生成真实动作”的一体化闭环。
相比过去需多个模型串联、训练耗时数月,Cosmos 3将物理仿真与任务训练压缩至数日内完成,在开源模型中物理生成精度、动作策略、视觉理解三项均排名第一。目前已推出Super(机器人/自动驾驶高精版)、Nano(秒级视频+动作推理)和即将上线的Edge(边缘端)三版本,并深度集成Omniverse,支持极端天气仿真、机器人虚拟训练等。超20家头部企业已加入“英伟达宇宙联盟”。https://blogs.nvidia.cn/blog/nvidia-launches-cosmos-3-the-open-frontier-foundation-model-for-physical-ai/

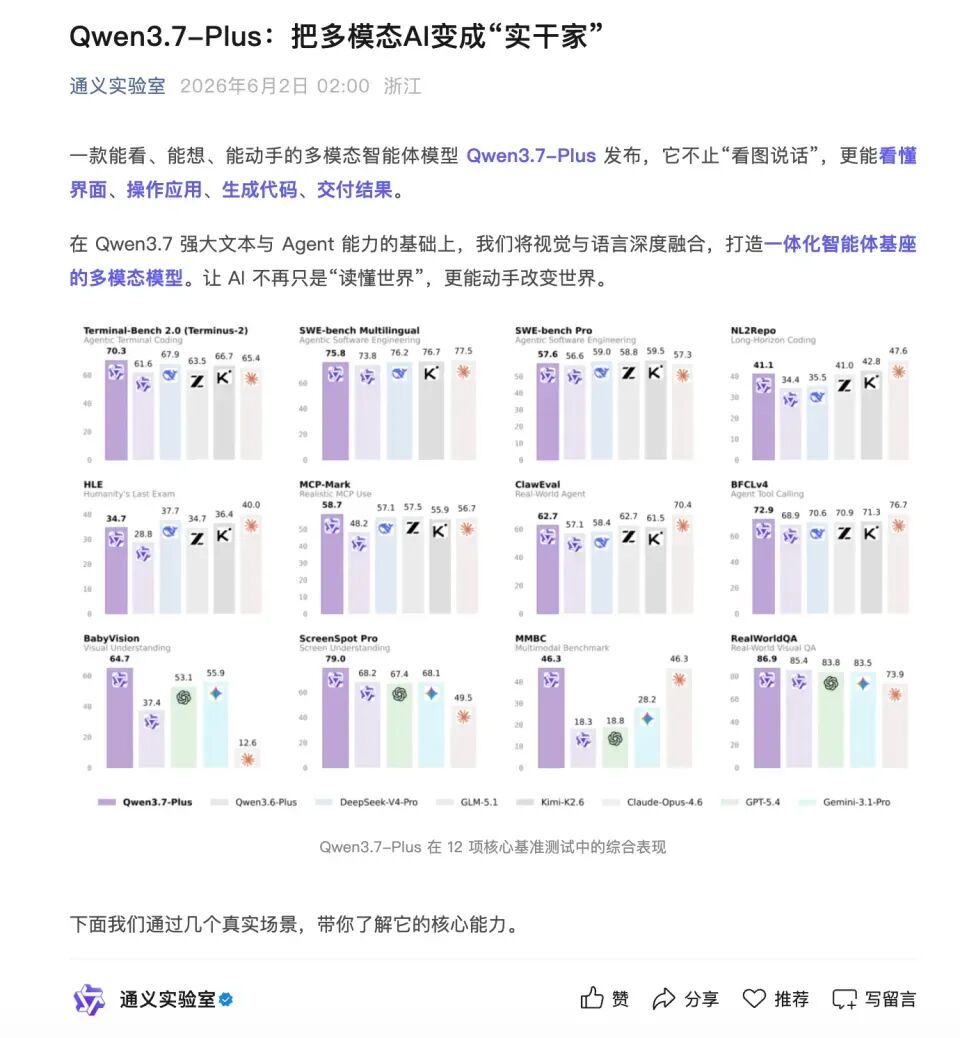
1-2. Qwen3.7-Plus上线!多模态智能体新基座,一键复刻桌面端专业软件
阿里最新发布的Qwen3.7-Plus大模型,6月2日正式上线阿里云百炼平台,标志着国产多模态智能体迈入新阶段。它不仅能“看懂”图片、视频、网页和屏幕截图,还能“想清楚、写代码、做操作、验结果”,实现“看—想—写—做—验”全链路闭环。在权威视觉大模型榜单Vision Arena中,它位列全球前五、中国第一。
实测显示,它可一键复刻手机APP或桌面软件,支持GUI控件识别、SVG/网页自动生成、OCR文档解析、驾驶场景理解等真实任务。相比前代,其视觉推理与工具调用能力提升显著,已开放API服务,开发者可通过百炼平台或Qwen Studio直接调用。作为千问3.7系列的主力版本,它为AI从“对话助手”升级为“动手干事的数字员工”提供了强大基座。https://www.qbitai.com/2026/06/427730.html

1-3. 云端模型如何落地物理世界?招商局狮子山人工智能实验室用LiOS打通具身智能全链路
衣物柔软、状态随机,考验机器人对柔性物体的感知、双臂协同、精细控制和长程任务执行能力。招商局狮子山人工智能实验室在ICRA 2026 LeHome挑战赛中,用自研操作系统LiOS,成功让SO101双臂机器人在真实家庭场景中稳定叠衣:从皱成一团的T恤、长袖到裤子,覆盖多形态、多初始状态,甚至完成甩平、拉直、对齐、压边等精细动作。
关键突破在于LiOS构建了“端—云—协同”智能基座:云端支撑百亿参数大模型训练与高并发仿真;端侧保障实时安全执行;而独创的低延迟图传技术,实现“相机到云端显存”仅30ms延迟(比通用方案快2–7倍),使云端大模型能实时指导真机操作。团队还开源了LiOS图传模块和首个高质量真机叠衣数据集LeFold,助力行业共建。https://www.qbitai.com/2026/06/427472.html

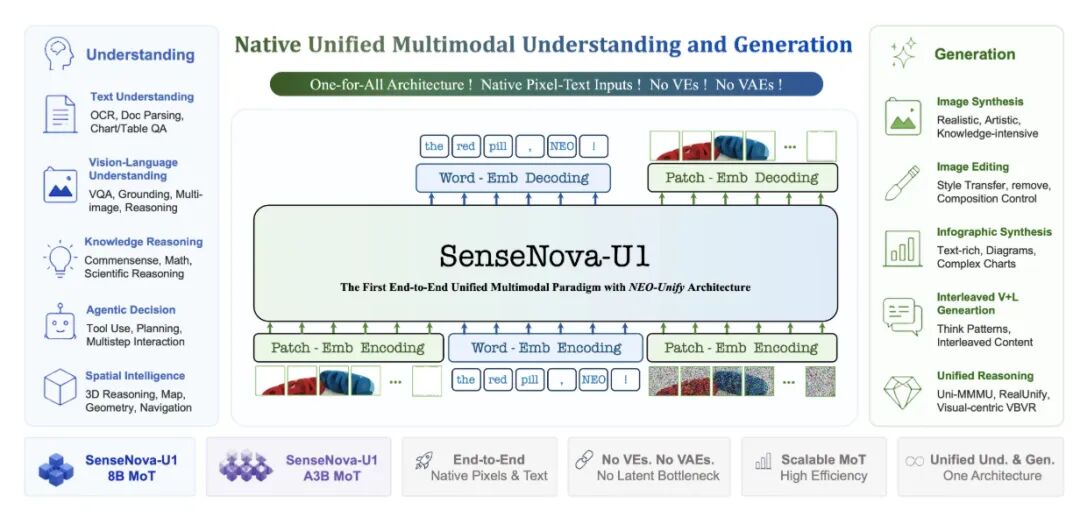
1-4. SenseNova-U1-8B-MoT-Infographic : 商汤科技开源的信息图增强模型
商汤科技于2026年5月底发布开源信息图生成模型SenseNova-U1-8B-MoT-Infographic(简称“信息图增强版”),这是全球首个全链路专为信息图优化的80亿参数开源模型。它在三大痛点上实现突破:高密度文字(如脚注、表格小字)清晰可读;多模块版式稳定不挤压;图表数据100%准确(柱高、刻度、百分比零错误)。
其在权威基准IGenBench上Q-ACC达69.5分,大幅超越GPT-Image-1.5(55.0)。模型采用Apache 2.0协议完全开源,支持商用,仅需10–12GB显存,成本约为闭源方案的十分之一。它还是唯一支持arXiv学术排版的开源模型。虽在视觉质感和长文本速度上略有不足,但以极小规模打赢大模型,标志着开源社区在专业可视化领域迈出关键一步。https://aiguide.cc/23706/
AI大模型算法、赛事和会议
2-1. 牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离
2026年,AI大模型正疯狂“拉长”上下文窗口——Gemini 3 Pro支持100万token,Llama 4 Scout号称达1000万token,相当于一口气读完7部《哈利·波特》。但数字背后藏着硬伤:上下文越长,模型越“记不住”。根源在于Transformer架构的KV Cache随长度线性膨胀,百万token输入可占用数百GB显存,远超单卡容量。
传统方案靠后期压缩KV缓存,效果有限。牛津、英伟达等团队提出新思路:训练时就让模型学会“压缩友好”的记忆方式,命名为KV-CAT。实验显示:在Qwen2.5-0.5B/1.5B模型上,KV-CAT不损基础能力,却大幅提升压缩后性能——“大海捞针”任务准确率最高提升近68%,长文本问答平均提升达39%。https://m.163.com/dy/article/KUDMBL7O0511AQHO.html

2-2. GUI Agent「记与学」双修,长程任务有了专属记忆增强型自进化框架
当前GUI智能体(能操作手机/电脑界面的AI)面临两大痛点:“记不住”和“学不会”——受限于短上下文窗口,容易遗忘早期关键操作;又因策略静态固化,无法从自身成功或失败经验中学习。天津大学与上海交大团队提出SE-GA新框架,一举突破瓶颈。
它包含两大核心:TTME分层记忆,以及MASE自我进化机制,尤其创新性地将失败轨迹“变废为宝”——通过Hindsight Goal-Shifting,把中途卡住的尝试重新标注为子目标的成功案例,大幅提升数据利用率。基于Qwen2.5-VL-7B训练仅4K条轨迹,SE-GA在多项权威基准上反超72B大模型:ScreenSpot定位精度达89.0%,GUIOdyssey动作类型准确率96.5%,AndroidWorld动态环境成功率39.0%(超GPT-4o近15个百分点)。https://aitntnews.com/newDetail.html?newId=25747
AI人才和资本动态
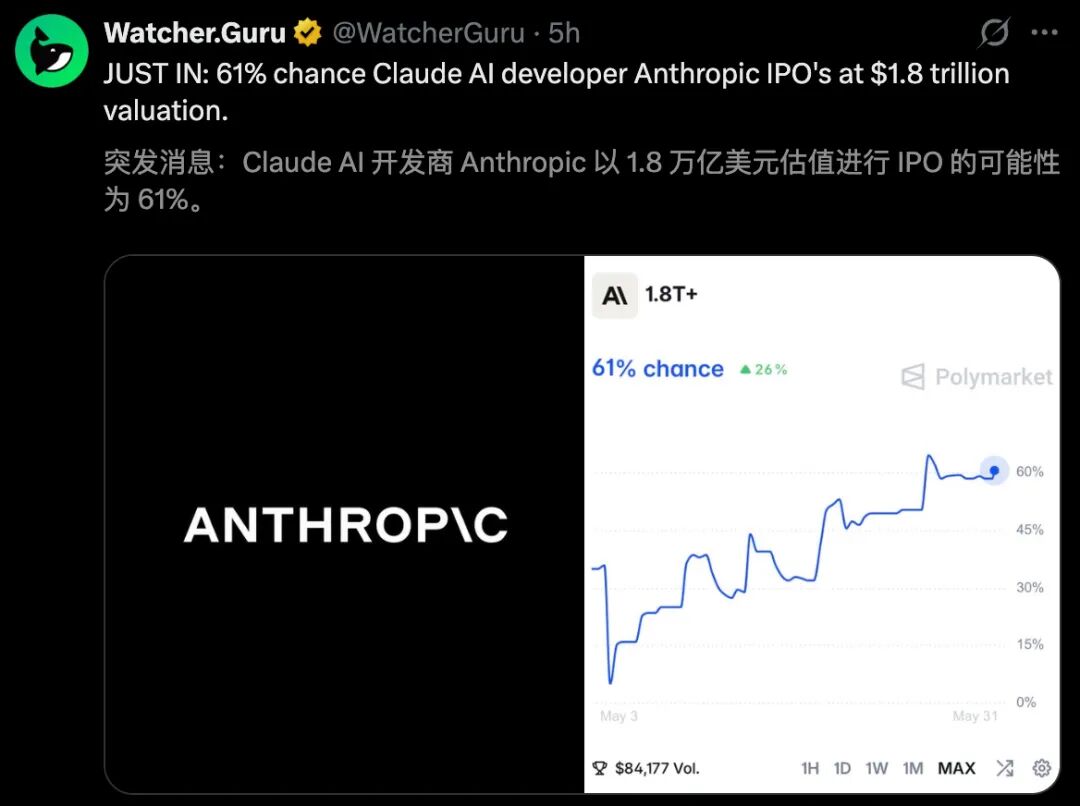
3-1. 刚刚,Anthropic抢先交表!冲击AI史上最大IPO
Anthropic——这家2021年成立的AI新锐,仅用5年就杀入“万亿俱乐部”:上周刚以9650亿美元估值完成650亿美元H轮融资,首次反超OpenAI(约8520亿美元);年化收入更从2025年底的90亿美元飙升至当前470亿美元,半年暴涨5倍!
如今,它已秘密向美国SEC递交IPO申请(S-1文件),冲刺史上最大AI IPO,最早或于2026年10月上市。与SpaceX、OpenAI并列“三巨头”,共同掀起2026年华尔街史上最密集、最高额的AI上市潮。Anthropic逆袭关键不在“大而全”,而在于极致聚焦——放弃图像生成等热门赛道,靠Claude Code自动编程工具狂揽开发者,把“写代码”做到全球顶尖。但挑战同样严峻:算力缺口巨大,每月向SpaceX支付12.5亿美元租用22万块AI芯片。https://www.163.com/dy/article/KUDMALMG0511ABV6.html

3-2. 188家医院、8亿营收、2.9亿亏损:微脉的“AI+全病程管理”故事,卡在了“人”上
微脉时隔近十个月再度冲刺港股,目标是成为“AI全病程管理第一股”。2023–2025年,其营收从6.28亿元增至8.63亿元,毛利率由18.9%升至21.7%,表面稳健;但净亏损却从1.50亿元扩大至2.90亿元,三年累计亏损6.33亿元,经营现金流连续为负,资产负债率超400%,已资不抵债。
关键转折在于:剔除优先股公允价值变动等非现金影响后,2025年经调整净亏损仅2380万元,较2023年收窄75%;经调整EBITDA首次转正,显示经营质量边际改善。然而,现金流仍未“造血”——2025年经营现金净流出3336万元,账上现金1.6亿元,略低于1.69亿元借款。其AI平台CareAI覆盖120+病种、语料超20亿token,但研发费用三年均不足4000万元,远低于翻倍增长的驻场人力成本。https://aitntnews.com/newDetail.html?newId=25750
3-3. 蓝驰高瓴下注硅碳互联黑马SiClink,脑机接口从"读懂大脑"走向"重建感知"
SiClink(曦涟科技)是一家侵入式脑机接口新锐公司,近期连续完成数千万元种子轮与天使轮融资。不同于当前主流聚焦“运动控制”的单向读取路径(如用意念操控机械臂),SiClink选择最具挑战性也最具潜力的方向——视觉重建:即同时实现“读懂大脑所见”与“写入虚拟信息”,构建真正双向、高带宽、低延迟(<50ms)、长期稳定的硅碳神经接口。
创始人何飞博士深耕该领域十余年,在超柔电极材料(2022)、低阈值刺激(2023)、动态视觉解码(2025发表于Nature Communications)等关键环节取得多项突破。SiClink认为,只有攻克视觉这一信息密度最高、通路最复杂的感知系统,脑机接口才能从“医疗康复工具”跃升为“下一代人机交互基础设施”。https://aitntnews.com/newDetail.html?newId=25745

3-4. 韩国AI推理芯片商XCENA完成1.35亿美元B轮融资,估值5.7亿美元
XCENA是一家成立四年的韩美初创公司,直击AI算力的“隐形瓶颈”——内存墙。当前,每次ChatGPT式提问都要让数据在CPU、GPU和DRAM内存间反复“跑马拉松”,耗电高、延迟大、成本贵。XCENA反其道而行之,把计算单元直接嵌入内存附近,推出首款内存内计算芯片MX1:它通过CXL高速接口连接CPU,在DRAM模块内完成预处理、KV缓存管理等繁重任务,省去90%以上数据搬运。
官方称,原需10台服务器的任务,未来1台即可承担。公司刚获1.35亿美元B轮融资,估值达5.7亿美元,累计融资1.85亿。MX1基于开源RISC-V架构,自研数千个专用小核+内存控制器,2026年底由三星代工量产,2027年预计营收。XCENA不争GPU训练高地,而是扎根AI推理的底层内存革命。https://news.qq.com/rain/a/20260601A07DFN00

写在最后
欢迎大家关注、分享、转发本公众号,也欢迎直接与小编联系 对接合作~
小问卷:公众号打分点评





