 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库arXiv:游戏如何塑造大模型智能
点击上方“图灵人工智能”,选择“星标”公众号
您想知道的人工智能干货,第一时间送达

导语
当互联网高质量训练数据逐渐接近天花板,大模型下一步该如何持续成长?一个出人意料的答案或许来自游戏。对于人类儿童而言,学习并不完全依赖教材,许多能力恰恰是在与伙伴互动、竞争和协作的游戏过程中形成的。近年来,一系列研究开始探索类似路径:让大模型通过博弈学习推理能力,通过游戏行为揭示决策机制,甚至进一步参与设计新的游戏规则。从在规则中学习,到在规则中决策,再到创造规则本身,游戏正逐渐从一种测试工具演变为理解和塑造智能的重要载体。或许,大模型未来所需要的,不只是更多文本,而是更多值得去“玩”的游戏。
关键词:游戏、大模型、训练、可解释性、规则

当大模型开始“玩游戏”,推理能力变强了?
当大模型开始“玩游戏”,推理能力变强了?
传统的学习,有结构化的教材,明确的目标和任务。但更多的时候,我们进行的是非正式学习,即在日常互动中试错、反馈、模仿。最典型的例子是孩子在游戏中学会合作与一般环境下的推理。事实上,近年来已经有不少研究开始探索:如果让大模型像儿童一样,通过与环境和其他智能体持续互动,是否能够获得比单纯阅读文本更强的推理能力?
例如,2026年发表于ICLR的一项研究发现,多智能体在多轮零和博弈中进行强化学习,能够显著提升模型的推理表现[2]。在这一方向上,于2026年1月发表于arXiv上的GIFT研究进一步提出了一个更激进的问题:如果把游戏视为一种“非正式学习”(Informal Learning)环境,让模型同时在多种类型的游戏中成长,会发生什么?

论文题目:GIFT: Games as Informal Training for Generalizable LLMs
论文链接:https://arxiv.org/abs/2601.05633
发表时间:2026年1月9日
论文来源:arXiv
在于其精心选择了三类代表性游戏,然后让不是模型交替以某一类游戏的结果为目标开展训练,而是必须同时在数学推理、策略博弈、社交理解等多个子任务上表现良好,才能获得最大奖励。通过这样的“交替训练”,训练出的模型,能在和游戏无关的任务上表现得更好。

图1:正式与非正式学习的对比
三个游戏分别是像囚徒困境这样的单次博弈,井字棋这样的多次博弈,以及“谁是卧底”这样需要社交互动的游戏,分别对应了抽象推理、序列决策、社交能力等会让大模型变得价值的核心能力。
结果发现,通过在训练过程中,让模型先解一道数学题,再玩一轮矩阵博弈(如囚徒困境),最后参与一次“谁是卧底”讨论。只有全程表现均衡,才能获得高回报。可以显著提升模型在多项任务上的性能。
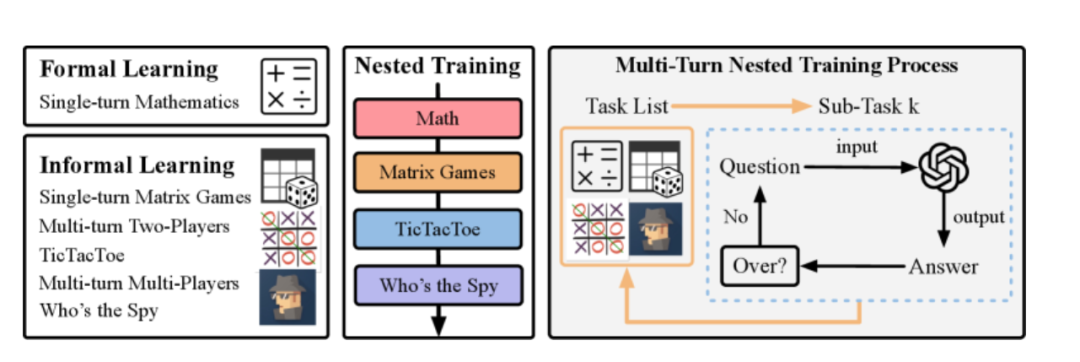
图2:多游戏与正式学习的混合训练方案
上述方法被称为嵌套训练框架(Nested Training Framework),与之相对的,是传统的混合训练(mixed training),即对于前述4类任务,分别进行训练,训练完一项任务后再进行下一任务的训练。
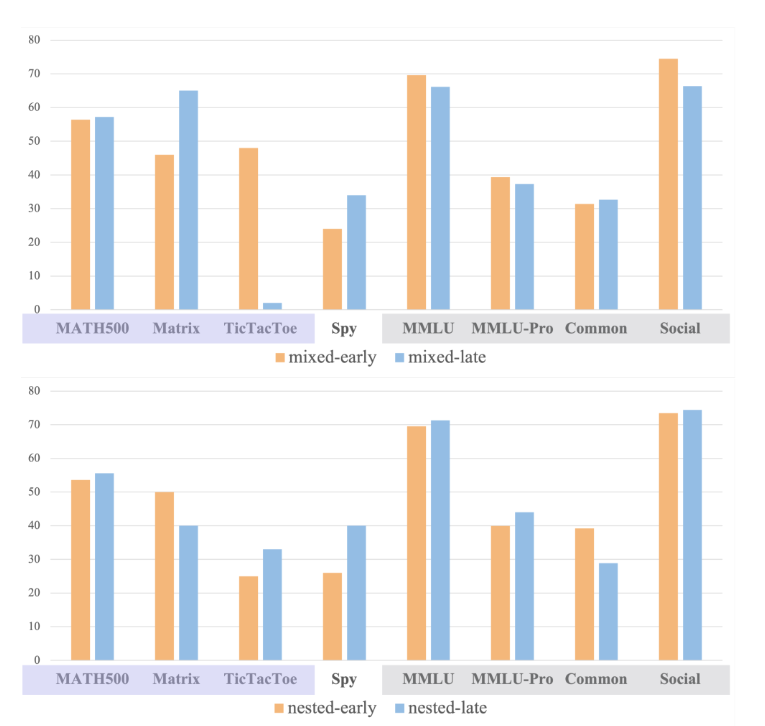
图3:对比显示正式学习与非正式学习的作用以及嵌套训练的有效性。
结果显示,混合训练虽在早期阶段凭借“任务竞争”机制在领域内任务(左侧紫色曲线,如矩阵博弈)上快速取得较高分数,但其通用能力(右侧灰色曲线,如MMLU评估的推理能力、Comon评估的创意写作,SocialIQA评估的社交能力等)的性能不升反降;说明训练后的模型缺少领域外泛化能力(图3上)。
相比之下,嵌套训练通过将多任务以“与逻辑”顺序串联,强制模型在完整轨迹上均衡优化,使领域内任务与通用能力两条曲线同步稳步上升(图3下),虽在单一任务的峰值表现上可能略逊于混合训练的“偏科冲刺”,但在综合泛化指标上实现更稳健、可持续的增长。
相比混合训练,嵌套训练在整个训练过程中保持了稳定的梯度(图4右)和更高的熵(图4左),从而在所有能力上实现稳定且持续的改进。 图3和图4的结果表明,嵌套训练框架不仅具有更优的优化稳定性,也能够促进模型形成更强的跨任务泛化能力。
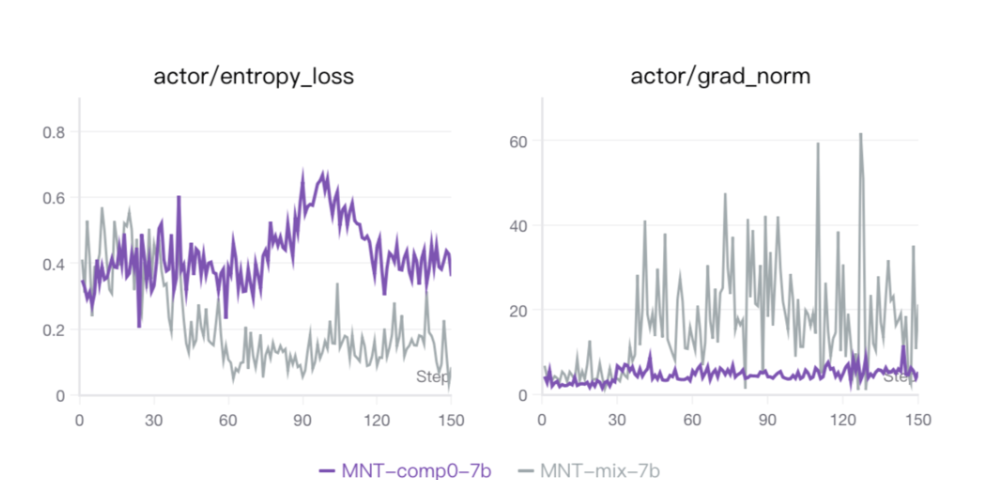
图4:混合学习与嵌套学习的动力学特征
不过,这里自然会引出一个新的问题:如果游戏真的能够塑造智能,那么游戏究竟改变了模型什么?
第一篇研究关注的是训练结果——模型是否学会了更通用的能力;而另一项最新研究则把视角转向训练后的模型本身,试图回答一个更加微观的问题:当大模型进入游戏情境时,它究竟是如何思考和决策的?
令人意外的是,研究者发现,大模型在游戏中不仅会表现出策略偏好,甚至会展现出类似人类的“性格倾向”。那么下面研究讲述的让ChatGPT玩飞行棋,则可展示模型在推理过程中,展现出类似人的小性子。
一盘飞行棋,暴露了AI“性格”
一盘飞行棋,暴露了AI“性格”
在另一篇发表于2026年的研究中,研究者没有继续探讨“如何利用游戏训练模型”,而是反过来利用游戏作为一面显微镜,观察大模型在复杂决策中的行为特征。
他们选择的实验环境,是几乎所有人都熟悉的飞行棋(Ludo)。
飞行棋是一个多人棋类游戏,其中既有合作也有竞争,玩家要把自家的一个个飞机移到机库。而这项研究中,研究者设计了480个精心构造的飞行棋局面(类似《天龙八部》中的“珍珑棋局”),系统测试了Qwen、DeepSeek、Claude、Llama、Gemma等6类主流大模型的决策能力[3]。

论文题目:LUDOBENCH: Evaluating LLM Behavioural Decision-Making Through Spot-Based Board Game Scenarios in Ludo
论文链接:https://arxiv.org/abs/2604.05681
发表时间:2026年4月7日
论文来源:arXiv
研究发现所有模型与博弈论最优策略的吻合度,只有40-46%,也就是说,大模型超过一半的决策,都是战略上错误的。
图5:飞行棋棋盘
更有趣的是,研究者发现大模型玩飞行棋时,会暴露出两种截然不同的性格。Finishers(完成者)死磕已经出场的飞机,拼命把它们送到终点,Builders(建设者)疯狂发展让飞机从机库出发,但从来不完成。
最离谱的是:当告诉大模型“刚才对手把你的飞机打回机库”,哪怕棋盘局面完全一样,有些模型的决策会有33%的概率改变,即使新做出的决策不是博弈论上最优的。不同模型报复的概率不同,这说明AI的决策会被情绪化叙事强烈影响,而某些模型本身就天生好斗,不需要刺激就会报复。
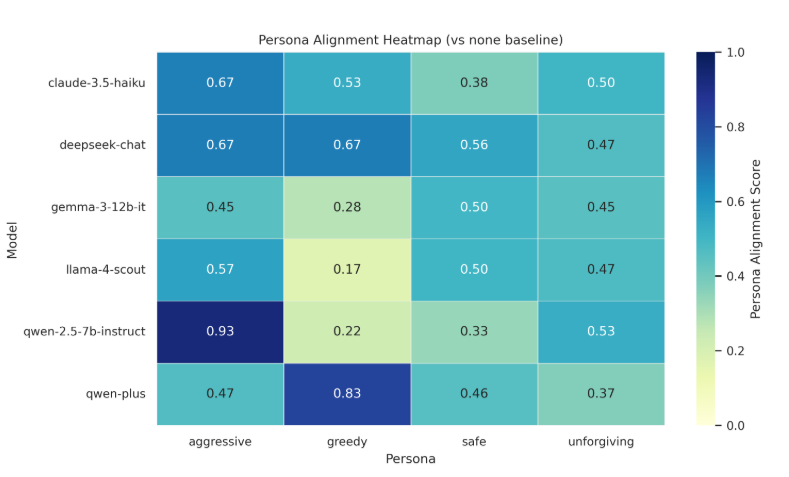
图6: 模型的预设人设与实际玩法的一致性
知道了AI在玩游戏时有报复心,那给AI不同的人设,又会发生什么了,该研究通过提示词,将AI玩游戏时的玩法分为4类,分别是:
aggressive(激进型):优先吃子
greedy(贪婪型):优先完成
safe(保守型):优先安全
unforgiving(睚眦必报型):优先报复
结果大部分情况下,人设指令的效果都很弱,对齐分数只有0.3-0.5(图6),只有两个组合效果显著:Qwen-2.5-7B 在激进型时93%概率符合;Qwen-Plus + greedy时83%概率符合。
更离谱的是,有时指令会产生相反效果:比如让Claude-3.5-Haiku(保守一点),结果它在“吃子vs安全”的选择中,吃子率从66%涨到88%。翻译一下:你让AI保守,它反而更激进了。这说明人设指令会和模型已有的战略偏好产生不可预测的交互,而不是简单地覆盖它。
上述研究,远不止告诉我们“AI会不会玩飞行棋”,而是通过游戏,揭示AI有“性格偏执”,不同模型会发展出截然不同的战略风格,而且这种偏执很难简单地通过提示词纠正。而对游戏的描述,即叙事框架会影响AI决策。这些发现,提升了模型的可解释性。结合推理过程中的动力学,游戏中的大模型其展现的独特行为,可能为了解大模型内部的运行机制提供独特窗口。
而将这两篇研究合在一起来看,那会发现一些更有趣的点,飞行棋是一个比井字棋更复杂的多人多轮博弈,如果允许玩家之间通过自然语言交流,试图用描述棋局走向来影响别的玩家,那就涉及了社交智能。那如果通过飞行棋让大模型进行强化学习,是不是会像第一部分描述的那样了?
对此笔者的猜测是不可行,原因首先是由于本文揭示的模型会存在不同的性格,其次是由于飞行棋这样涉及运气(投骰子)以及对手非理性的游戏,让强化学习算法很难分配激励,训练中的大模型难以知道是由于那些因素获胜的,嵌套训练中的每个任务恰好因为足够简单,才能让每一次的输赢成为清晰的信号。
AI能创造游戏规则吗?
AI能创造游戏规则吗?
前两项研究分别展示了游戏的两种价值:一方面,游戏可以成为训练智能的环境;另一方面,游戏也可以成为观察智能的窗口。但这两类工作有一个共同前提——游戏规则是人类事先设计好的。
《有限与无限的游戏》一书中写道:有限的游戏在边界内玩,无限的游戏玩的就是边界。如果再向前迈进一步:让大模型不仅参与游戏,而是参与“创造游戏”本身,会发生什么?这正是第三项研究关注的问题。

论文题目:GAVEL: Generating Games Via Evolution and Language Models
论文链接:https://arxiv.org/abs/2407.09388
发表时间:2024年1月12日
论文来源:arXiv
这篇发表于2024年的研究让大模型自动生成新颖且可玩的棋盘游戏规则[4],研究者先将已有棋类游戏的规则,通过高阶关键词(如step, slide, hop)对规则进行编码,之后随机定位一些规则表达式作为“突变位点”,再由经微调后的CodeLlama-13B模型生成新规则片段并重构游戏代码;图右侧为分层评估与档案更新,新游戏依次通过编译检查、可玩性验证、随机策略快筛与蒙特卡洛树搜索深度评估四层过滤,计算六项指标的调和适应度,同时将其概念向量经PCA降维至2维的适应性景观上。
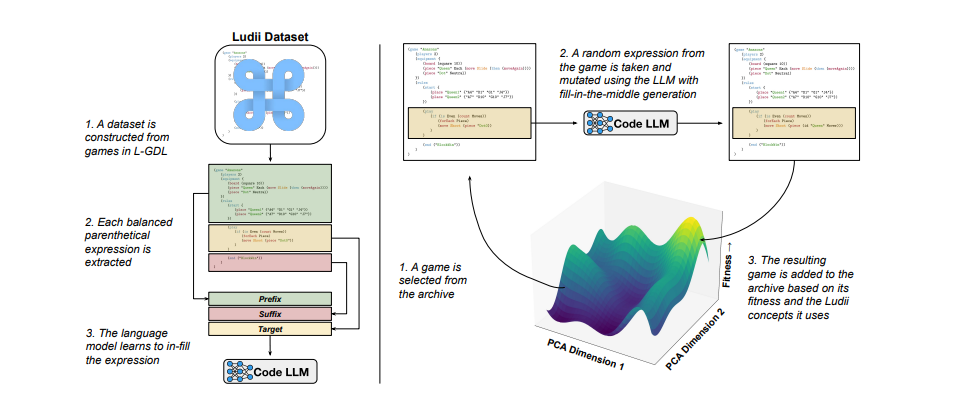
图7:大模型设计棋类游戏的流程示例
这样一来,产生了很多规则融合的棋类游戏,例如五子棋和围棋的融合(五子胜/四子负 + 围吃机制融合),对此人类专家评价"有潜力成为经典",感兴趣的玩家可以去下面的网页试玩。
图8:大模型生成游戏的试玩界面
上述案例说明,当大模型学会“理解游戏规则的语法与语义”,再与演化算法的多样性搜索相结合,就能成为一位不知疲倦的"游戏设计学徒",无法确保它一定能独立创造出传世佳作,但能和人类一起去玩无限游戏,为人类游戏设计者提供可玩、有启发性的规则原型,开启人机共创意的新范式。
现有的研究,仅聚焦规则产出,未来可研究大模型对游戏规则语义的深层建模,支持“为什么这条规则有趣”的可解释分析。笔者设想可通过让大模型设计出别的大模型爱玩的游戏,如此的设计层面自我博弈,从而为大模型创造出近乎无限的训练数据(大模型玩新设计出的游戏时的对弈数据),同时向别的大模型智能体解释为何自身设计游戏好玩的过程,就是提升模型可解释性,尤其是社交过程中可解释性的过程。
从更宏观的视角看,这三项研究恰好对应了智能发展的三个层次:学习规则、运用规则,以及创造规则。当我们将“游戏”从固定规则的竞技场,重构为规则本身可演化的学习沙盒,本质上是在回答一个更深刻的问题:智能的本质,是掌握规则的能力,还是创造规则的能力?
而在探索智能本质的征途中,让大模型“玩”无限游戏,或许正是通往持续成长的密钥。
相关推荐:
https://arxiv.org/html/2601.05633
https://openreview.net/forum?id=7Yayy5fNLg
https://arxiv.org/html/2604.05681v1
https://proceedings.neurips.cc/paper_files/paper/2024/file/c7b04e4e13bb77996d3ae2ff667231ac-Paper-Conference.pdf

文章精选:
1.编程时代已终结!ClaudeCode创始人断言:编程就像发短信一样自然,首曝个人最新工作流:自创Sloop循环,单日PR达150!传统SaaS护城河崩掉
2.HTML死了!前OpenAI工程师掀起网页革命:用AI将整个屏幕变成无限直播像素流,无一行html代码,网友:传统Web开发结束,前端真要失业了! 3.诺奖得主DeepMind掌门人最新访谈晓读:AI创业者护城河?AGI只差1-2个关键想法,最缺的不是算力,是这个 4.GPT之父把AI扔回1930年:没见过一行代码,却「发明」了Python! 5.图灵奖得主查尔斯·巴赫曼:他在数据未成海时,便为人工智能修好了岸 6.图灵奖得主理查德·萨顿(Richard Sutton)最新演讲:大模型只是一时狂热,AI的真正时代还没开始 7.图灵奖得主Bengio预言o1无法抵达AGI!Nature权威解读AI智能惊人进化,终极边界就在眼前 8.图灵奖得主、强化学习之父Rich Sutton:大语言模型是一个错误的起点 9.图灵奖得主杨立昆:大语言模型缺乏对物理世界的理解和推理能力,无法实现人类水平智能 10.压缩即是全部 —— 菲尔兹奖得主 Michael Freedman 给数学和 AI 的一封信





