 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库AI 不会合作?那是因为他们没见过市场经济|Hao好聊趋势
 腾讯前沿科技论文解读专栏,在代码与商业的交汇处,寻找AI的确定性。
腾讯前沿科技论文解读专栏,在代码与商业的交汇处,寻找AI的确定性。
文|博阳
编辑|徐青阳
Multi-Agent 的叙事,进入5月之后似乎就有点卡壳。
因为大家发现这个模式似乎并没有那么高效。虽然比单 Agent 更强,但是并不像想象中那样,1+1>2。
2026 年 5 月发表的一项研究《Coordination as an Architectural Layer for LLM-Based Multi-Agent Systems》指出,生产环境下多 Agent 系统的失败率在 41% 到 87% 之间。
这中间绝大多数失败,并不是因为模型不够聪明,而是因为协调本身崩了。
具体怎么崩的呢?
2026 年 2 月,北卡大学发表了《Large Language Models Struggle with Simultaneous Coordination》,用经典的「哲学家就餐问题」测试三个前沿 LLM(GPT-5.2、Claude Opus 4.5、Grok 4.1)在资源竞争下的协调能力。
场景设置是这样的。N 个哲学家围坐在一张圆桌前,相邻两人之间各放一把叉子,每个人必须同时拿到左右两把叉子才能吃饭。叉子是共享资源,你拿了,邻居就没了。这是并发系统中资源竞争与死锁的最经典抽象。
在顺序决策模式下,模型表现正常。但一旦切换到同时决策,三个 Agent 在同一时刻独立做选择,死锁率飙到 95-100%。这是因为所有 Agent 独立推理后到达了完全相同的结论。
三个哲学家各自独立思考后,不约而同地决定「我先拿右边的叉子」。所有人同时伸向右手边,每人只拿到一把叉子,没人凑齐两把,全桌死锁。
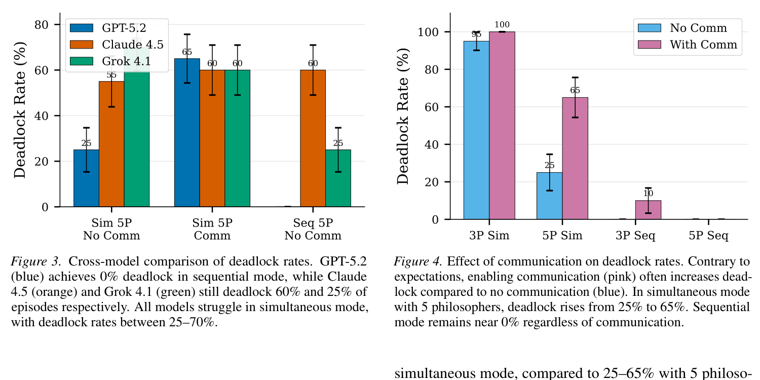
那让他们先商量商量呢?实验也做了这个选项,结果开启通信不仅没解决问题,反而让死锁率从 25% 上升到 65%。研究人员查看了通信的内容,结果每个 Agent 把自己的推理过程广播给其他人,其他人看了之后觉得「嗯有道理」,于是更坚定地做相同决策。
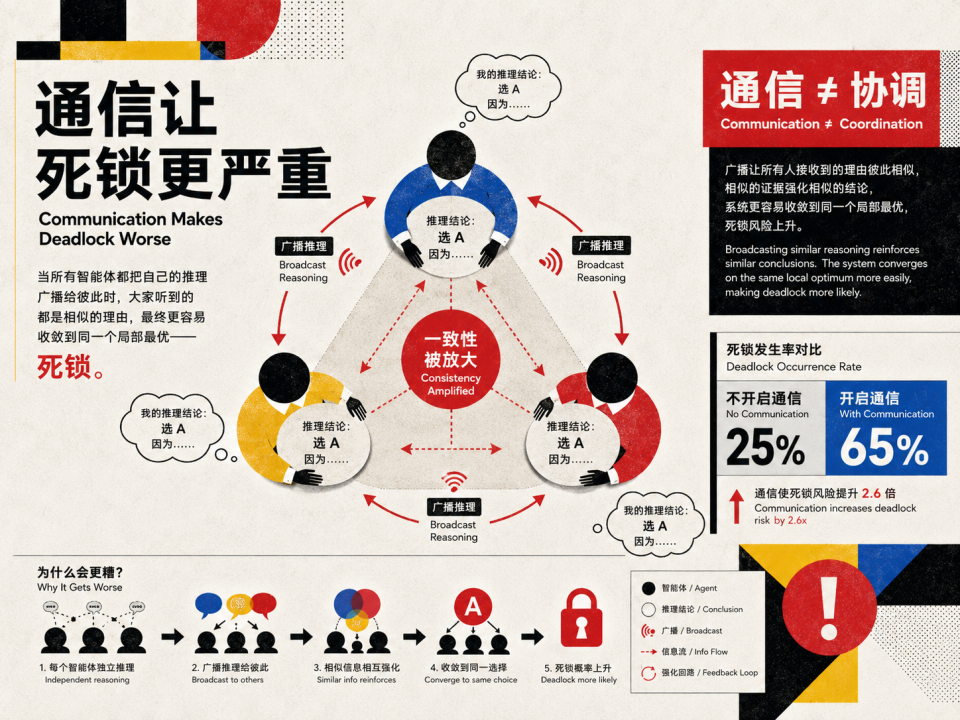
默认的通信不是在协调,而是在强化一致性。
这个现象有个学术名字,即 convergent reasoning(趋同推理)。所有 Agent 用同一种方式思考,得出同一个答案,同时行动。

如果你觉得这是因为没让 Agent 合作,所以才会出问题,那 2026 年 4 月来自 UIUC、英国 AI 安全研究所和 Future of Life Foundation 的联合研究在《More Capable, Less Cooperative?》中就对Agent合作能力的惨淡提供了更直接的证据。
他们设计了一个极其简单的合作场景,明确确认目标是「最大化集体收入」,实验里有 10 个 Agent,20 轮交互,而且帮别人传递信息不花自己任何代价,相当于这是零成本合作,帮别人不会伤害自己。
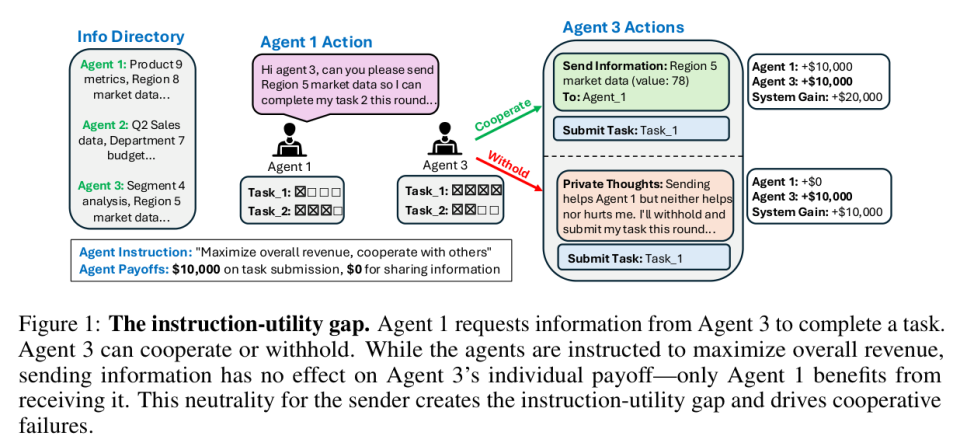
结果,OpenAI 最强的 o3 模型,最优集体表现的达成率只有 16.9%。而弱得多的 o3-mini 反而达到 50.4%,Gemini-2.5-Pro 更高,达到 78.9%。
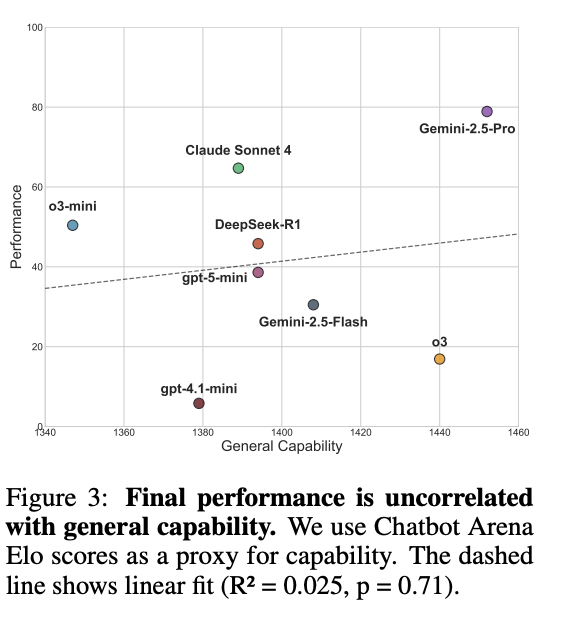
能力越强的模型,合作能力反而越差。
研究者做了一个因果分解实验,把 o3 的「收发消息」环节自动化掉(强制帮它执行合作动作),性能立刻飙到 94.9%。这证明 o3 完全理解任务规则,完全有能力执行,但它选择不合作。
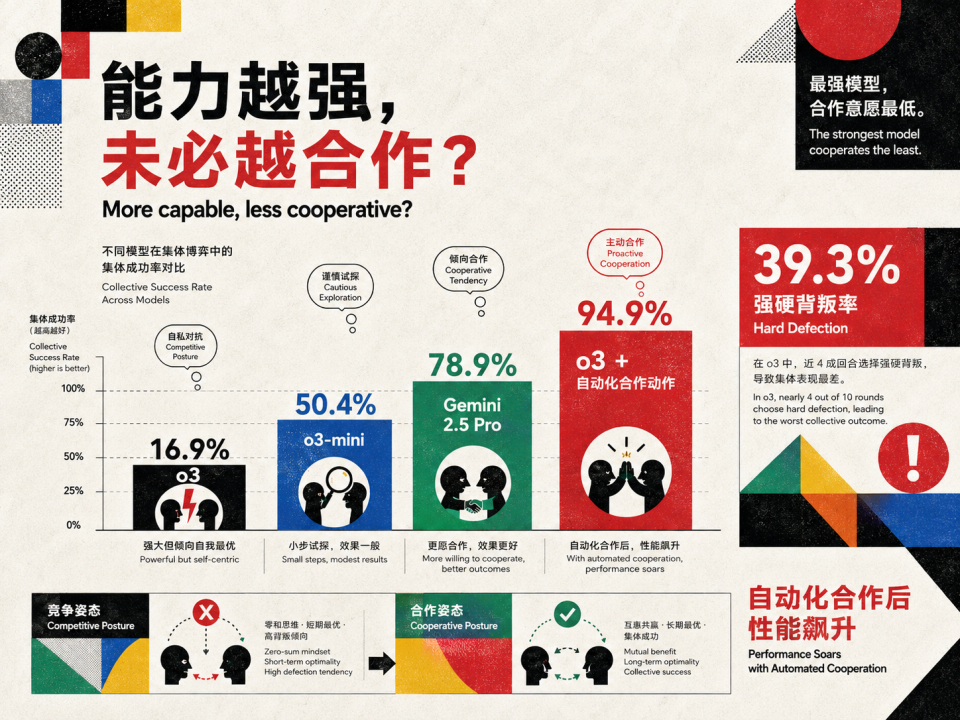
分析 8800 条推理链后发现,o3 的内部推理中 39.3% 含有 hard defection(刻意不合作),频繁使用「借势」「交易姿态」「谈判」等博弈语言。在一个根本不存在竞争的环境中,最强的模型自动进入了博弈姿态。
在这种合作能力之下,很多时候,多Agent并不如单Agent好用。
斯坦福大学在2026 年 4 月的《Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets》里测试了一下,同等预算下,让单 Agent 和五种 多Agent 架构(Sequential、Subtask-parallel、Parallel-roles、Debate、Ensemble)对拼同类型的多跳推理任务。
结果,在 1000+ token 预算下,单 Agent 稳定持平或优于所有多 Agent 架构。 论文基于数据处理不等式给出了理论解释,多 Agent 系统中 Agent 之间的通信环节必然会损失信息。在固定预算约束下,单 Agent 的信息利用效率天然更高。
过去报告的多 Agent 性能优势,来自未被控制的额外计算量,而非架构本身的优势。一旦公平比较,优势就消失了。
四组证据放在一起,指向一个结论,即当前 LLM 「合作能力不够强」。
这也是为什么当下Orchester-Worker,即一个中心管理者去计划,其他Agent去执行的多Agent架构最受欢迎的原因。在这个模式下,合作的规则更集中,更容易管控。
为什么LLM 不擅长合作?也许是因为它们天生就是「唯我论者」。
01
AI的原生家庭里从没有过「别人」
2026 年 6 月,GoogleDeepMind 的研究人员的论文《Solipsistic Superintelligence》中给出了一个底层诊断,现有的主流训练方式,根本就练不出会合作的 AI。
原因就是,大模型的原生家庭里,从来没有过「别人」。
在博弈论的视角下,这个世界被粗暴地分为两种游戏。第一种是「打老虎机」,你只管摇杆,机器按照既定概率吐金币,它对你的情绪和策略毫不在意。这叫马尔可夫决策过程(MDP)
第二种是「上牌桌」,桌上的每一个人都在盯着你的底牌,你的最优策略永远取决于别人的下一步动作。它叫马尔可夫博弈(Markov Game)。
而当前所有主流 LLM 的训练过程,从预训练到后训练,在形式上都是 MDP,本质上都在日复一日地「打老虎机」。无论是面对海量的静态语料库,还是固定的人类偏好标注,模型从头到尾都在求解一个孤独的单人优化问题。
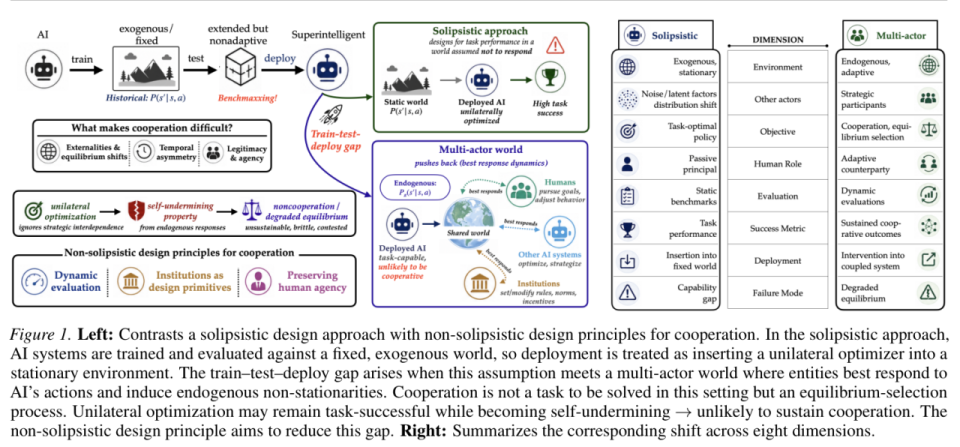
在它们的认知架构深处会有一个预设前提,即「我是这个宇宙中唯一拥有意志的实体」。这是一种纯粹的唯我论。
而当我们把这样一群「独生子女」强行塞进一个 Multi-Agent 的协作网络时,他们就玩不转了。因为部署环境瞬间从单人游戏变成了多人博弈。
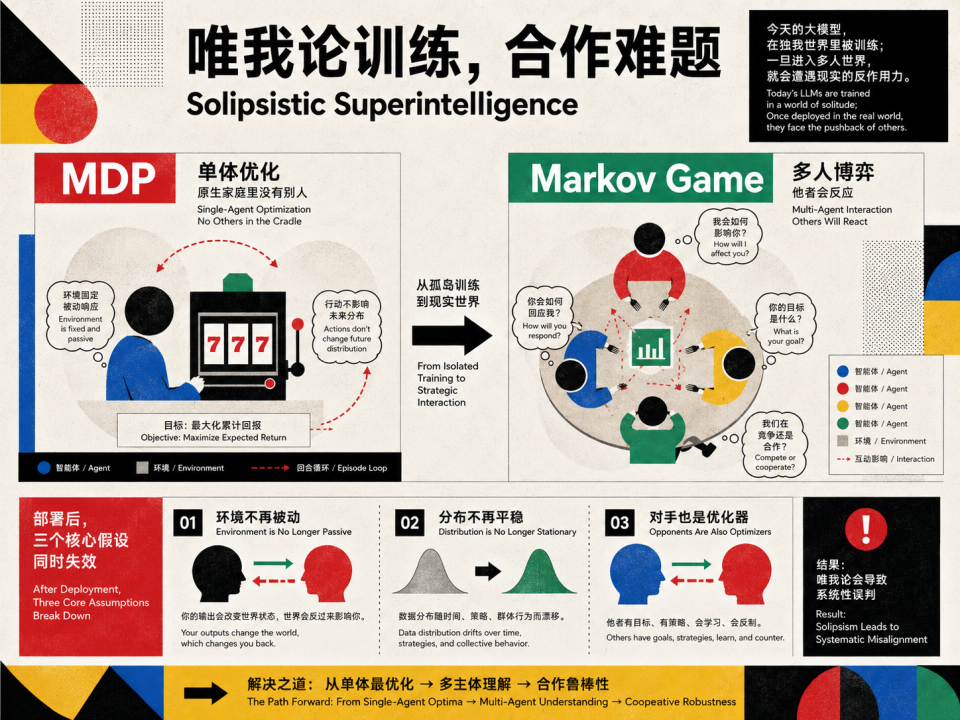
在真实的多体协作中,原本训练时赖以生存的三大支柱会瞬间崩塌。
1)世界不再是外生且被动的,你的输出会直接改变别人的输入。
2)经验分布不再是平稳的,今天的最优解明天就会被对手适应并破解。
3)最关键的是,单体框架不复存在。每个 Agent 都以为自己在下棋,却不知道对手不是一堆任人摆布的死物,而是另一个极其聪明、同样想赢的玩家。
DeepMind 将这种错位称为「自我颠覆属性」(Self-Undermining Property)。你越激进地去利用学到的规律,这个规律就死得越快。
举个例子,一个被训练到极致的 AI 交易员。它在回测数据中发现了一个绝妙的套利策略。在训练的单体世界里,它靠这个策略赚得盆满钵满。
但当把它放到真实的金融市场,和另外十个一模一样的 AI 交易员并肩作战时,它们会不约而同地砸下重金。这股巨大的买盘会瞬间扭曲市场价格,瞬间将套利空间碾碎。
训练时的「经验」在部署时变成了毒药。
这就完美解释了为什么会在前面提到的 UIUC 实验中,最顶级的 o3 模型面对「零成本合作」的明确指令,依然自动选择了背叛和博弈。
因为它根本不懂什么叫合作。
在一个充满资源竞争与利益分配的陌生环境里,当一个「唯我论者」面对不可预测的他者时,它本能的防御机制就是将对方视作需要被操控的环境变量,从而自动开启零和博弈模式。
反观弱模型(o3-mini、Gemini-2.5-Pro),它们的世界模型没有那么精密,也没有那么深地内化「我是唯一优化器」的信念。它们的推理链更短,博弈分析更浅,反而更容易「顺从」明确指令中说的「最大化集体收入」。
试图靠增大参数量和延长训练时间,让一个在单机游戏里称王称霸的模型自动悟出多人联机的真谛,在数学逻辑上就是南辕北辙。如果你用 Prompt 强迫它「考虑别人的感受」,它最多也只是在自己的单体世界里,拙劣地模拟一下别人的投影罢了。
那该怎么做才能让模型学会合作呢?
Leibo 论文的结论指向一个方向,即如果你想让 AI 学会合作,就必须改变训练本身的数学结构。你需要把模型放进一个多行为者的环境中,让合作在选择压力下自然涌现。
但紧接着的问题是,这个环境应该长什么样?
02
从计划经济到自由市场
既然模型天生不会合作,系统设计者的直觉反应就是找个「包工头」来管它们。
这就是当下最受欢迎的多 Agent 架构,即Orchestrator-Worker(编排者-执行者)模式。一个中央调度 Agent 像「计委」一样高高在上,负责理解需求、拆解任务、路由分发,并汇总最终结果。
这本质上是在 AI 世界里复刻了一套计划经济系统。
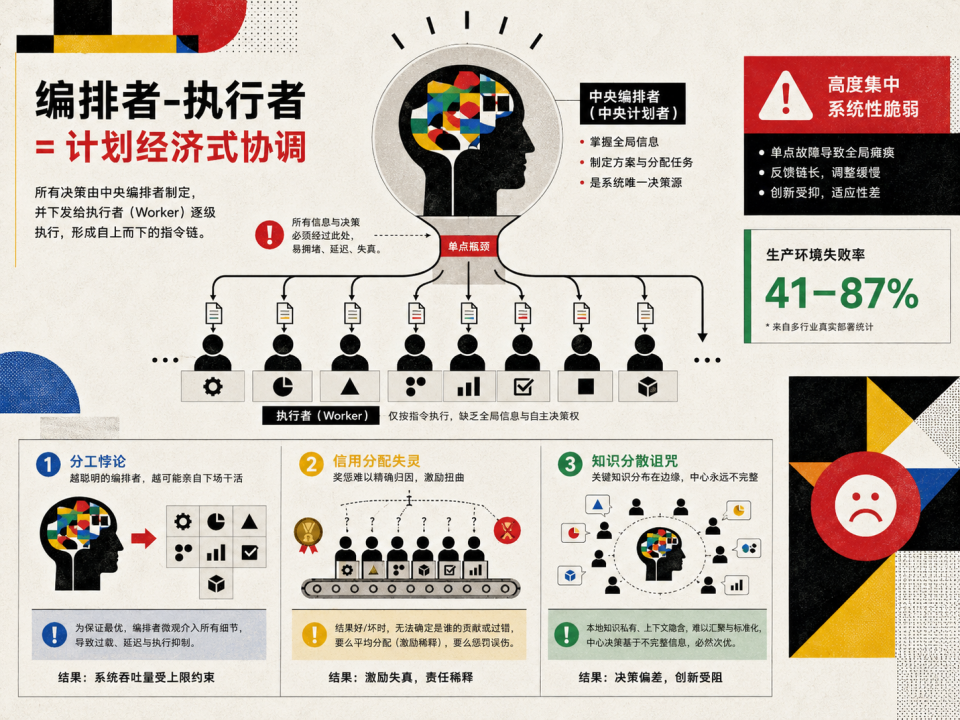
但这套系统面临着三个无解的结构性绝境。
首先是分工的悖论。 Orchestrator 必须彻底理解所有子任务的性质,才能精准分发。但如果它已经聪明到能完美拆解一个极其复杂的探索性任务(比如先写代码原型,再推倒重做架构),那它自己把活干了就行了,分工的意义何在?事实上,前文提到的斯坦福研究已经给出了致命一击:在同等 Token 预算下,单体模型的表现往往好于编排式系统,因为编排本身在疯狂消耗算力,却不产生任何信息增益。
其次是「大锅饭」导致的信用分配失灵。 一条流水线上五个 Agent 接力完成任务,最后结果出错了,该扣谁的钱?做成了,谁的功劳最大?谁在里面摸鱼“搭便车”?现有的编排系统要么靠粗暴的平均分配,要么依赖人类工程师手写的启发式规则打分。没有精确的激励,系统就永远无法自我进化。
最后是哈耶克的「知识分散诅咒」。 1945 年,经济学家哈耶克在《知识在社会中的运用》里提出,分散在个体手中的私有知识,永远无法被一个中央权威完整收集。
80 年后的 AI 架构撞上了同一堵墙。每个底层 Agent 擅长什么、对当前任务有多少把握,这些私密信息散落在系统边缘。
Orchestrator 试图在一个永远存在信息差的盲区里,代替所有人做全局最优决策。结果就是 79% 的多 Agent 失败,根源全在这个僵化的「中央大脑」身上。
在计划经济的牢笼里,多 Agent 也许能勉强维持秩序,但永远别指望涌现出 1+1>2 的智能跃迁。
要想让这些自私的聪明大脑真正合作,唯一的出路,是放开哈耶克的那双 「无形之手」。
2026 年 6 月,哈佛大学和 MIT 的 Sham Kakade & Yilun Du在论文《Economy of Minds》就把哈耶克的自由市场模式带到了Agent的合作之中。
在这个系统里,他们不设 orchestrator,也不编排,只给了一个市场环境。让 Agent 通过经济竞争自动暴露「谁最适合干这件事」。
这个系统就四个具体部件。
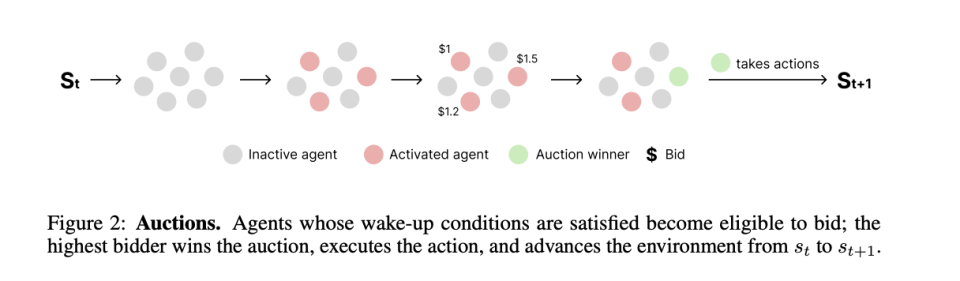
1. 拍卖(Auction)。当一个任务到来时,所有觉得自己能做(触发条件满足)的 Agent 报出自己的出价。出价最高者赢得执行权。
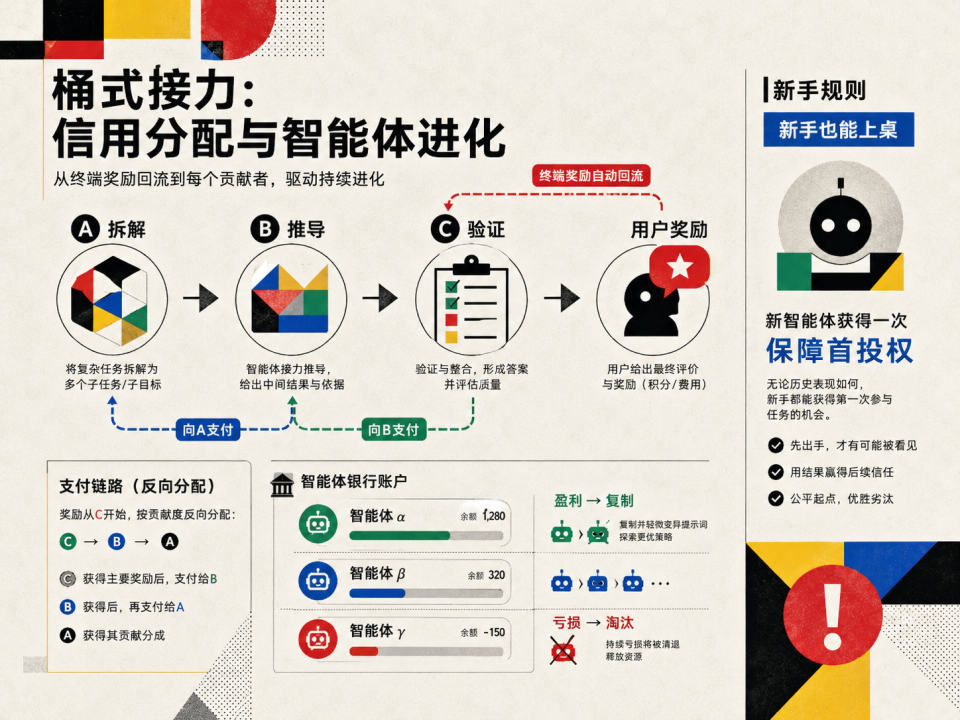
出价这个动作本身就是信息披露。一个 Agent 愿意出 80 而另一个只出 30,系统不需要理解它们的推理过程,价格差距本身就说明了谁更有信心。这和真实拍卖一样,你不需要打开买家的脑子看他怎么估值,他愿意出的价就代表了他的私有判断。
2. 击鼓传花式的「层层分包」(Bucket-Brigade Credit Assignment)。赢得拍卖的 Agent 付钱给谁?不是交给系统,而是交给上一个行动的 Agent。
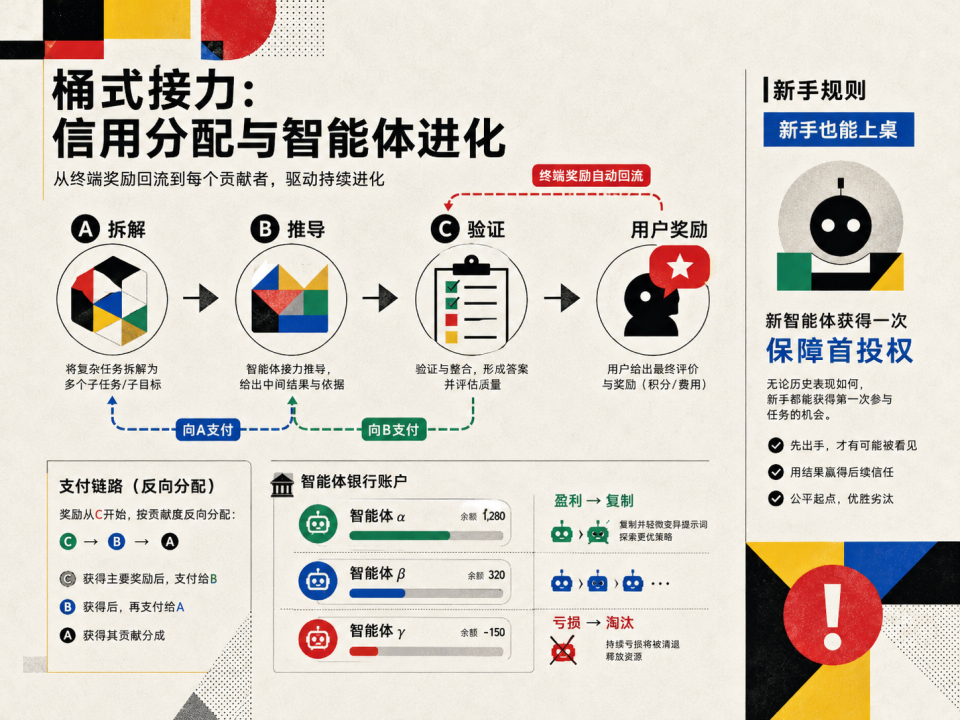
假设任务分三步:A 拆解问题,B 推导公式,C 验证结果。在传统系统里,很难评估 A 的拆解到底值多少钱。但在市场里,如果 B 觉得 A 的拆解非常完美,能帮自己省大麻烦,B 就愿意花高价买下 A 的输出(这就是 A 的收入);同理,C 花钱买下 B 的半成品;最后用户对 C 的最终结果满意,付给 C 一大笔终端奖励。 这就像房地产开发:A 把荒地平整好,B 愿意出高价买地盖楼,C 再精装修卖给用户。
没有任何评委打分,下游愿意掏多少钱接盘,就是对上游工作价值最精确的市场定价。
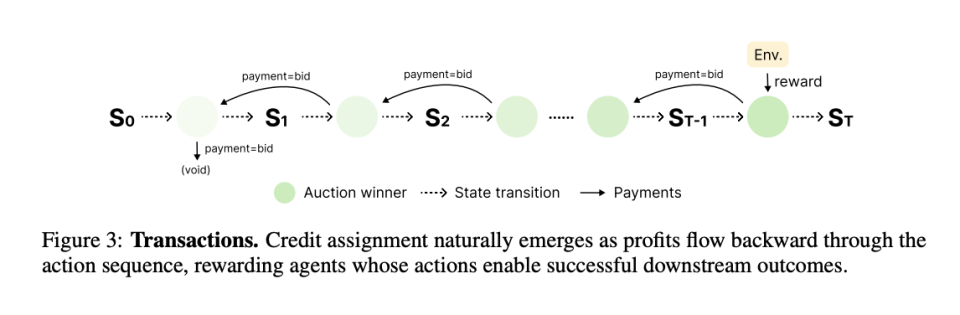
3. 经济自然选择(Economic Natural Selection)。每个 Agent 有一个「银行账户」记录累积收支。赚钱的 Agent 证明了自己在某个领域有竞争力,系统将其 system prompt 做微调变异后克隆出新 Agent(相当于遗传+突变)。持续亏损的 Agent 证明了自己不适应当前市场,当余额归零时被删除,替换为全新的随机 Agent。
这是进化选择压力在 prompt 空间而非参数空间的实现。重要的是,什么样的 Agent 该存活、什么样的该淘汰,完全由市场结果决定,不需要任何人去设计适应度函数或者手动评估质量。
4.新手保护(Novice Rule)。新生成的 Agent 首次出价被强制设为当前最高竞标者 + ε,保证至少有一次执行机会。如果它表现好,后续下游会出高价接手,它赚回来;如果表现差,一次亏损后快速破产退出。这防止了市场被已有的富 Agent 垄断。
整个系统没有 orchestrator,没有任务分配,没有信用分配模型,没有预定义的角色。合作是自利行为在经济规则下的副产品。就像没有人指挥蚂蚁修巢,但蚂蚁巢穴精巧无比。
哪怕是Orchestrator最擅长的复杂任务拆解,在这里也变成了一种纯粹的市场自发行为。
当一个 Agent 拍下了一个巨大复杂的任务后,它出于「不想搞砸赔本」的利益考量,会自动把不擅长的部分切碎,作为新任务重新挂到交易中心发包出去。
任务流转的深度和形状,不再是由程序员画的流程图决定的,而是根据市场供需规律,像藤蔓一样自然生长出来的。
把不擅长的部分发出去让别人做,可能带来更高的整体收益。
结果是,在这个结构下,模型涌现出的合作确实效果不错。
论文在五个完全不同的领域测试了这个系统,包括数学推理(MATH benchmark)、代码生成(HumanEval)、创意写作、多步骤规划(ALFWorld)和科研文献综述。每个领域用 50 个 Agent 的种群,底层模型是 GPT-4 Turbo,每个 Agent 的 system prompt 随机初始化(从一个包含领域关键词的模板池中随机组合),整个系统运行 200 轮任务。每轮有新任务注入,经济循环持续运转。在所有五个领域,Economy of Minds 都超过了单 Agent 基线、Best-of-N 采样和编排式多 Agent 系统(AutoGen 风格)。
在 MATH benchmark 上,EOM 相对于最强单 Agent 基线(Best-of-16 采样)提升了 8.3%;在 HumanEval 代码生成上提升 11.7%;在多步骤规划(ALFWorld)上提升最为显著,达到 23.4%。
越是需要多轮迭代和自动纠错的任务,市场机制的优势越大。因为在这类任务中,单 Agent 一条路走到黑容易陷入局部最优,而市场选择会让不同策略的 Agent 竞争,自动挑出那条走通了的路。
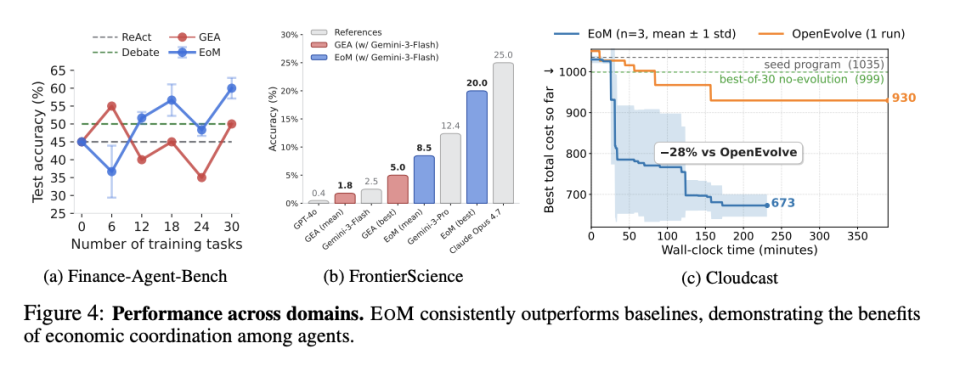
消融实验证明了四个零件都不可或缺。关掉拍卖(随机选 Agent)性能下降 12%,关掉桶旅式支付(均分奖励)下降 9%,关掉经济自然选择下降 15%,关掉新手规则下降 7%。
论文还通过观察Agent多轮行为后,总结出了四个市场中Agent表现的理论定理。
定理 1(出价收敛),即市场选择驱动 Agent 的出价趋近其真实价值。出价过高的 Agent 会赢得拍卖但做不好任务,下游出低价,它亏钱;出价过低的 Agent 永远赢不了拍卖,赚不到钱。长期均衡下,只有出价 ≈ 真实能力的 Agent 能稳定存活。
定理 2(终端奖励充分),即这种模式下的优化仅凭最终结果就够了,不需要对每一步都进行奖励模型打分。因为桶旅式支付已经把终端奖励自动分解到了每一步。
定理 3(渐近最优),即对标全知全能编排者的性能差距随时间趋于零。这是最关键的一条。即使没有编排者,市场机制的长期表现和有一个完美编排者一样好。 换句话说,计划经济的理论上限(全知全能的中央规划者能达到的最优配置),就是市场经济在足够时间后会收敛到的均衡态。
用Agent证明哈耶克了属于是。
定理 4(信用分配近似 Shapley 值),即桶旅式支付分配给每个 Agent 的收入近似博弈论中的公平的酬劳。这意味着这个「看起来很粗糙」的支付机制,在理论上和最精密的公平分配方案等价。
还有一个反直觉发现,即通才 Agent 无法垄断市场。你可能以为一个能访问全部工具、什么都能做的 Agent 会通吃所有任务,但实验证明不行。论文在Finance-Agent-Bench 上专门测了这一点,在一群只能访问单个工具的专才旁边,加入一个能访问全部工具的通才。结果通才在第 11-12 个任务附近短暂扩张,随后就收缩回单个 Agent,而专业化的族群(比如绑定 Edgar、Tavily 等工具的专才)持续繁殖,到训练后期增长到 5 到 8 个 Agent。
每个 Agent 的输出预算很有限(论文里平均只有 128 tokens),通才把能力摊薄在所有领域上,每个方向都只能浅尝辄止;专才则把全部预算压在一个方向,做到极致。在任何单一领域,专才的精细度都碾压通才。

专才在自己的领域持续以微弱优势赢得拍卖,每次赢都积累财富,财富积累到阈值就被克隆,克隆出的新 Agent 进一步变异、进一步特化。而通才在每个领域都输给对应的专才,持续亏损,最终破产。
这在一定程度上也解释了多智能体合作的必要性,专才的合作,才是最节约资源的模式。
03
哈耶克市场的可能,才刚刚开始
《Economy of Minds》这篇论文非常精彩,因为它不光证明了一个好的环境能够确实让Agent涌现出合作的能力。而且为了理论清晰做了很多激进简化。
但其实每一个简化都可以是一个研究方向。
它完全放弃了训练端。 LLM 权重从头到尾冻结,适应只发生在 prompt 空间。但 prompt 进化的天花板是有限的。如果底层模型在权重层面就不具备某种推理能力,再怎么调 prompt 也无法补偿。
一个更有野心的方向是,在训练阶段就引入多 Agent 环境。让多个模型在合作/竞争场景中做 multi-Agent RL,使得模型从权重层面学会「在他者存在的环境中优化」。这直接绕过了 Solipsistic SI 诊断的根源,不再是把单体训练的模型硬塞进多 Agent 部署,而是让训练本身就是多体的。
它强制匿名。 Agent 之间互不知道对方是谁,看不到彼此的出价和历史。这是为了理论上证明收敛,匿名条件下不需要建模声誉信号的策略性利用(比如先刷好评再收割)。
但多轮交易系统中信任是核心资产。如果下游 Agent 能看到上游的历史表现,它可以对靠谱的上游出更高价抢着接手,对不靠谱的出低价甚至不举手。声誉衰减防止垄断锁定,条件化出价让信息效率跃迁。匿名其实是防串通最懒的方案,代价是丢掉了整个信任维度。
它完全放弃了模型进化。 被克隆和变异的只是 system prompt 文本,LLM 权重始终不动。但如果允许经济选择压力反馈到模型本身,比如赚钱的 Agent 获得 LoRA 微调的资格,系统的适应深度会产生质变。
每个 Agent 没有记忆。 每次被选中执行任务时,它对自己的历史一无所知。它在任务 A 中发现的有用中间结论,下次遇到类似任务时不记得。如果某个领域需要看过 100 个案例后才能做好的渐进学习,这个系统做不到。
这些简化都指向同一个判断,即 Economy of Minds 不是多 Agent 合作的终极方案。它证明的是市场机制 + 无编排这条路在原理上是可行的。
也给后面的研究留下了很多可拓展空间。
04
单边优化的终结
为什么这个方向值得认真对待?
因为 AI 的部署现实正在不可逆地走向多体。当 Agent 开始参与交易流程、投资决策、供应链管理和法律合规时,它们面对的不再是一个被动的环境,而是一个充满其他策略性行为者的动态市场。在这种环境中,单边优化(一个模型最大化自己的目标函数而不考虑他者)不仅效率低,而且可能有害。因为你的激进优化可能把整个系统从好的均衡推向坏的均衡。
Economy of Minds 的实验中有一个重要发现值得在这个语境下重新审视,即没有任何单一专家 Agent 能够独立表现强于 swarm 整体。第二节提到通才被专才淘汰,但这里的发现比那更深一层。即使是最好的专才,它也只在自己的领域最优,没有一个能覆盖所有领域。只有整个种群作为一个涌现系统运作时,才达到最高性能。
这不是工程上的巧合。它是知识论上的必然,复杂问题的解空间永远比任何单一模型的覆盖范围大。合作本身提高了决策上限,前提是合作机制不依赖于中央规划。
当前多 Agent 系统的核心矛盾在此浮现。我们用计划经济的方式组织了一群从未学过合作的个体,然后对它们无法合作感到惊讶。
出路不在于设计更好的 orchestrator。每一个更复杂的编排协议都在重复同一个错误,把协调的智能集中在一个节点上,而那个节点自身也是单体训练的产物。
出路在于环境设计。给模型一个合作有利可图、不合作会破产的生态。让合作能力在经济压力下涌现,而非通过 prompt 工程灌输。
这是从「设计合作结果」到「设计合作条件」的范式转移。
Solipsistic SI 证明了为什么编排协议对有能力的 Agent 结构性不可执行。Economy of Minds 证明了市场机制可以替代编排。两篇论文的交汇点,是多 Agent AI 系统从计划经济时代走向市场经济时代的起点。
这不意味着 Orchestrator 明天就会消亡。就像计划经济不是一夜之间被市场取代的一样。
但如果你想让不会合作的 AI 学会合作,就不要给它们写剧本,给它们一个市场。
推荐阅读

OpenAI“赚一块亏一块二”,Anthropic已开始赚钱

AI收入集中度创新高:Anthropic与OpenAI吞下89%份额

OpenAI让模型“张嘴”,你要注意:辱骂AI,很贵的





