 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库刚刚!Qwen 35B 大模型终于免费开放了!
上周五下班,工作群里突然有人发了条消息:
「讯飞星辰MaaS把Qwen3.6-35B的API调用权益免费开放了,新老用户都能领。」
我当时的第一反应是——又是营销?
结果打开链接一看,是真的。
Qwen3.6-35B-A3B,35B参数量、128K超长上下文、MoE架构,正经的顶级开源模型,API调用权益,直接免费送。
新老用户都能领,有效期到6月底。
我当场领了,然后花了整整一天测试各种场景。这篇文章就是我的实测记录,代码可以直接复制用,改一下Key就能跑。
一、先说这次免费开放的是什么模型
这次讯飞星辰MaaS平台免费开放的是两个模型的API调用权益:
Qwen3.6-35B-A3B 和 Qwen3.5-35B-A3B。
两个都是阿里开源的Qwen3系列,MoE架构——总参数35B,激活参数只有3B。
简单说人话:知识储量是35B级别的,推理的时候只调动3B的算力,又快又省,效果还不打折。
Qwen3.6是最新版,在代码生成、智能体编排、长链路推理上有明显提升;Qwen3.5是经过充分验证的稳定版,很多开发者已经跑在生产环境里了。
正常调用这个量级的模型,成本可不低。现在平台直接送权益,有效期到6月底,先领先用。
两个模型我都测了,下面分场景来说。
平台入口:
https://maas.xfyun.cn/modelSquare?ch=MaaS-jgkol-c2L7l
二、怎么领?五分钟搞定
不绕弯子,直接上流程。
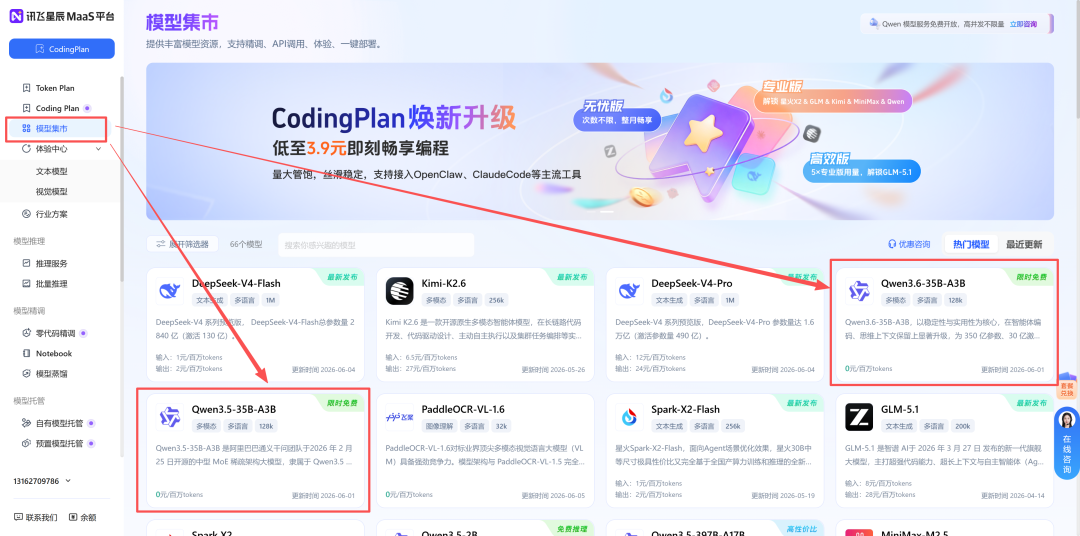
第一步: 打开上方链接,进入讯飞星辰 MaaS 平台模型集市,就能看到 Qwen3.6-35B-A3B 或 Qwen3.5-35B-A3B,均有「限时免费」的标签;
第二步: 登录账号(没有的话注册一个,流程很快),按提示完成免费权益领取,新老用户均可参与;
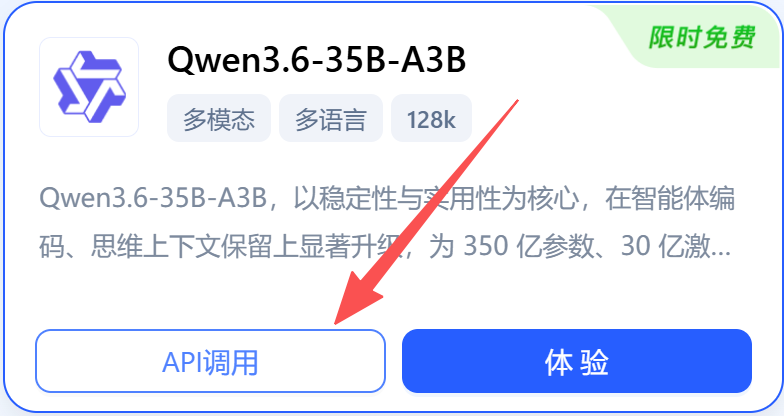
第三步: 以 Qwen3.6-35B-A3B 为例,点击API调用,输入模型服务API名称,输入新创建的授权的应用,点击确定;
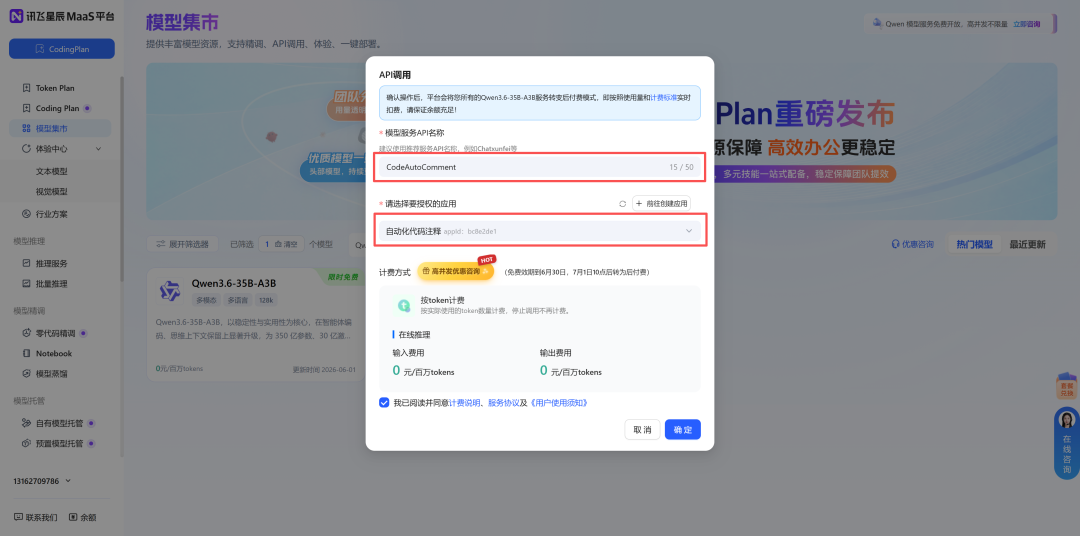
第四步: 在推理服务中就能看到刚刚创建的 Qwen3.6-35B-A3B 的 APIKey 了。
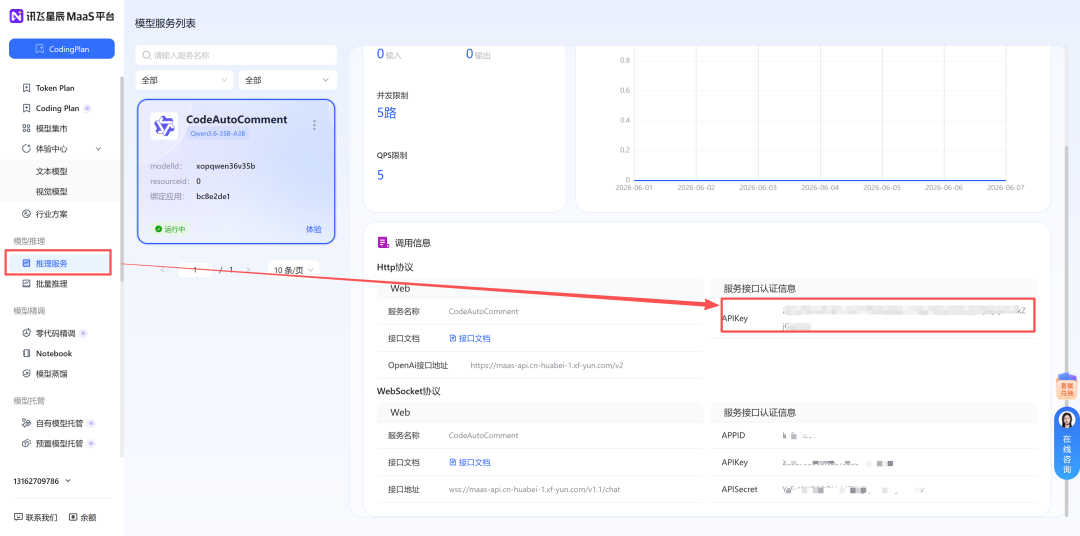
第五步: 对照下方场景案例,把 API Key 填进去,直接跑起来。
整个流程五分钟以内,不用填表、不用审核,领完就能调用。
API 拿到手,真正的玩法才开始。
下面我按不同人群和场景,分别给几个跑通过的实际例子。代码可以直接复制用,改一下API Key就行。
三、实测场景
一、自动给代码加注释
测完数据处理,我想试试代码相关的能力。
我手上有一段写得比较潦草的快速排序,没有任何注释,直接扔给它:
「你是一位资深Python开发工程师,请为以下代码添加详细的中文注释,包括函数说明(docstring格式)和关键逻辑的行内注释。直接返回加完注释的完整代码,不要其他说明。」
import requestsapi_key = "你的APIKey"url = "https://maas-api.cn-huabei-1.xf-yun.com/v2/chat/completions"def add_comments(code: str) -> str: headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "xopqwen36v35b", "messages": [ { "role": "user", "content": f"你是一位资深Python开发工程师,请为以下代码添加详细的中文注释,包括函数说明(docstring格式)和关键逻辑的行内注释。直接返回加完注释的完整代码,不要其他说明。\n\n{code}" } ], "max_tokens": 4096 } response = requests.post(url, headers=headers, json=data) return response.json()["choices"][0]["message"]["content"]sample_code = """def quick_sort(arr, low, high): if low < high: pi = partition(arr, low, high) quick_sort(arr, low, pi - 1) quick_sort(arr, pi + 1, high)def partition(arr, low, high): pivot = arr[high] i = low - 1 for j in range(low, high): if arr[j] <= pivot: i += 1 arr[i], arr[j] = arr[j], arr[i] arr[i + 1], arr[high] = arr[high], arr[i + 1] return i + 1"""print(add_comments(sample_code))
输出结果让我挺满意的:docstring格式标准,行内注释不多也不少,该解释的地方解释,不废话的地方不废话。
更重要的是,它没有改动任何原始逻辑,只加了注释,这个「只做被要求的事情」的能力,很多小模型其实做不好。
二、搭一个会多轮对话的客服机器人
这个场景我测得最仔细,因为有实际的落地需求。
我们有一份产品FAQ文档,想让模型基于这个文档回答用户问题,同时支持多轮对话——也就是说用户问完第一个问题,第二个问题还能承接上下文。
我先把知识库内容塞进系统提示词,然后每一轮对话都把历史记录带上:
import requestsapi_key = "你的APIKey"url = "https://maas-api.cn-huabei-1.xf-yun.com/v2/chat/completions"def add_comments(code: str) -> str: headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "xopqwen36v35b", "messages": [ { "role": "user", "content": f"你是一位资深Python开发工程师,请为以下代码添加详细的中文注释,包括函数说明(docstring格式)和关键逻辑的行内注释。直接返回加完注释的完整代码,不要其他说明。\n\n{code}" } ], "max_tokens": 4096 } response = requests.post(url, headers=headers, json=data) return response.json()["choices"][0]["message"]["content"]sample_code = """def quick_sort(arr, low, high): if low < high: pi = partition(arr, low, high) quick_sort(arr, low, pi - 1) quick_sort(arr, pi + 1, high)def partition(arr, low, high): pivot = arr[high] i = low - 1 for j in range(low, high): if arr[j] <= pivot: i += 1 arr[i], arr[j] = arr[j], arr[i] arr[i + 1], arr[high] = arr[high], arr[i + 1] return i + 1"""print(add_comments(sample_code))
测了三轮对话,上下文衔接非常自然,第三个问题里它记住了用户是「黄金会员」这个信息,回答时自动带入了对应的权益说明,没有要求用户重复说一遍。
这套逻辑可以直接套进飞书机器人或者企微客服,不用买任何商业系统。
三、接进Dify,替换掉原来的付费模型节点
这个测试我觉得是最有实际价值的一个。
我自己搭了一套基于Dify的内容生产工作流,之前用的是GPT-4o,每跑一次复杂任务花费不少,心疼得很。
把讯飞的API接进去,换成Qwen3.6-35B-A3B之后,直接跑了一遍原来的工作流。
配置方法很简单:
在Dify的模型供应商配置里,选择「OpenAI Compatible」兼容模式,填入:
API地址:https://maas-api.cn-huabei-1.xf-yun.com/v2/chat/completions
API Key: 你申请的Key
模型名称: xopqwen36v35b
保存,直接切换。
我原来工作流的核心节点是:抓取文章 → 提炼要点 → 改写成适合公众号的风格 → 生成标题备选。
换完模型之后跑了5篇,整体输出质量和之前用GPT-4o的版本比,差距很小,有几篇的标题备选我觉得甚至更贴合中文阅读习惯。
成本从原来每篇大概0.3-0.5元,变成了现在的零。
在免费权益有效期内,这套工作流我可以敞开跑。
四、多篇文献交叉分析
这个场景是帮做科研的朋友测的。
他的日常需求是:读完十几篇文献,要提炼各自的核心观点,再对比不同研究之间的异同,写进综述里。
最烦的不是写,是读和整理这个过程。
Qwen3.6支持128K的上下文窗口,塞进去几篇文献的关键段落完全没问题。我写了个脚本,把多篇文献内容拼接,让它做交叉分析:
import requestsapi_key = "你的APIKey"url = "https://maas-api.cn-huabei-1.xf-yun.com/v2/chat/completions"def analyze_papers(papers: list, question: str) -> str: headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } combined = "" for i, paper in enumerate(papers, 1): combined += f"\n\n【文献{i}】\n{paper}" prompt = f"""你是一位专业的学术研究助手,请围绕以下研究问题,对提供的{len(papers)}篇文献进行交叉分析:研究问题:{question}文献内容:{combined}请输出:1. 各文献核心观点摘要2. 文献间的共识与分歧3. 研究方法的异同对比4. 综合启示与研究空白以学术综述风格呈现,逻辑清晰,有据可查。""" data = { "model": "xopqwen36v35b", "messages": [{"role": "user", "content": prompt}], "max_tokens": 4096 } response = requests.post(url, headers=headers, json=data) return response.json()["choices"][0]["message"]["content"]papers = [ "文献1正文内容粘贴在这里...", "文献2正文内容粘贴在这里...", "文献3正文内容粘贴在这里..."]result = analyze_papers(papers, "大语言模型在教育场景中的实际应用效果与局限性")print(result)
我朋友拿了三篇他在读的论文测了一下,他的原话是:「初步的对比框架出来得很快,角度也抓得比较准,能帮我省掉不少梳理时间,剩下的自己做判断就行。」
做综述的前期整理工作,用这个能省一大半时间。
测了一天,说几句实话
测下来,我有几个比较直观的感受:
结构化输出很稳定。 我在多个场景里要求它只输出JSON,没有一次多嘴加解释或者格式跑偏,这点对写自动化脚本的人来说非常重要;
长上下文表现不错。 128K窗口,塞进去几篇文献或者长对话记录,没有出现明显的「忘了前面说过什么」的情况;
中文语感自然。 这个是我自己很看重的一点,生成的中文没有那种很明显的翻译腔,日常内容创作场景用起来顺手;
和OpenAI接口完全兼容。 这意味着你原来任何接了OpenAI格式的项目,几乎零改动就能切换过来。
四、顺便说一下Token Plan
如果你不是个人开发者,而是对稳定性和并发有明确要求的企业团队,平台还上线了Token Plan。
付费订阅,按需配置,企业级资源保障,服务优先级和稳定性都更高,主打对SLA有要求的生产环境场景。
个人和学生先薅免费权益,跑通了再说;需要保障线上稳定性的团队,可以了解一下这个选项。
写在最后
说实话,现在能白嫖35B级别模型API的机会真的不多。
这波权益有效期只到6月底,而且添加讯飞工作人员可领取高并发权益!
不管你现在有没有明确的项目落地,都建议先把权益领了、API Key配好,后面想用随时拉起来。
从内容创作到代码开发,从科研辅助到团队基础设施,上面这四个场景覆盖了绝大多数人的日常需求。
挑一个离你最近的场景,把代码复制过去,改一下Key,直接跑。
与其在评测帖子里看别人用,不如自己动手试一次。
👉 免费领取入口(6月底截止,新老用户均可):
https://maas.xfyun.cn/modelSquare?ch=MaaS-jgkol-c2L7l
今天的分享到此结束,有问题评论区见,我们下期再见!





