 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库Cursor扒了自己18个月数据,还原出最真实的Vibe Coding现状
AI Coding 正在从“工具红利”走向“系统重构”。过去两年,开发者最直观的感受是代码补全更快、写样板代码更省力。但现在,变化已经越过了单点提效阶段。模型开始读取整个代码库、理解项目结构,甚至参与 PR 和审核流程。
软件开发正在从“人主导、AI 辅助”,转向“人设定目标、AI 执行流程”。
这背后也意味着行业竞争逻辑正在变化。
早期 AI 编程产品比的是模型能力和交互体验,谁生成得准、响应得快。但随着任务变复杂,真正的护城河会逐渐转向上下文管理、缓存效率和成本控制等。
换句话说,AI 编程不再只是“更聪明的代码编辑器”,而是在逼近一套新的软件生产基础设施。
此外,与共识相悖的是,AI 并不会天然抹平开发者差距。相反,它可能先放大高手的优势。
懂架构、会拆任务、能判断模型输出质量的开发者,会把 AI 变成杠杆。而只把 AI 当成问答工具的人,获得的提升会有限。
Cursor 作为在 AI Coding 行业起起伏伏的公司,发布的开发者习惯报告展现了AI Coding 真实的趋势变化。它不是又一篇关于 AI 编程的概念文章,而是用真实产品数据记录了这场变化。
以下是 Cursor 发布的《2026 年春季 Cursor 开发者习惯报告》编译文字。(原文链接:https://cursor.com/insights)

一场深刻的变革
软件开发正在经历一场惊人的变革。这份首期开发者习惯报告,基于 Cursor 的真实数据,从五个角度记录了这一切:
开发者在加速:代码编写速度同比增长一倍,每次提交的代码量更大、更深,AI 生成的代码通过审核后保留下来的比例也达到了历史新高。
智能的经济账:我们对比了 7 个模型系列,看每行代码花多少钱、每次提交花多少钱,发现不同模型之间的性价比差异非常大。
顶尖用户的领先优势:AI 让所有人的效率都提高了,但最顶尖的 1% 开发者提升最为明显。
上下文的崛起:模型读取的信息量急剧增加,"缓存读取"的占比也在上升,这让 AI 有能力处理更复杂的任务、写出更高质量的代码。
迈向自动化:AI 编程正从"辅助单个开发者"的工具,演变为一套端到端自动化软件开发流程的完整系统。
本报告用数据清晰呈现了:AI 编程今天处在什么位置,下一步可能走向哪里。
开发者加速
开发者工作得更快、产出的代码更多,但变化远不止"量"的提升。AI 也在改变工作的"形态":每次提交的代码量更大、AI 对话的轮次更深、AI 生成的代码在代码库里存活的时间也更长了。
1.1 代码产出速度加快
开发者每周新增的代码量在持续增加,且自 2026 年初以来增速还在加快。虽然代码行数不是完美的衡量标准,但它为理解开发者工作正在发生怎样的变化,提供了一个有方向性参考价值的方向。
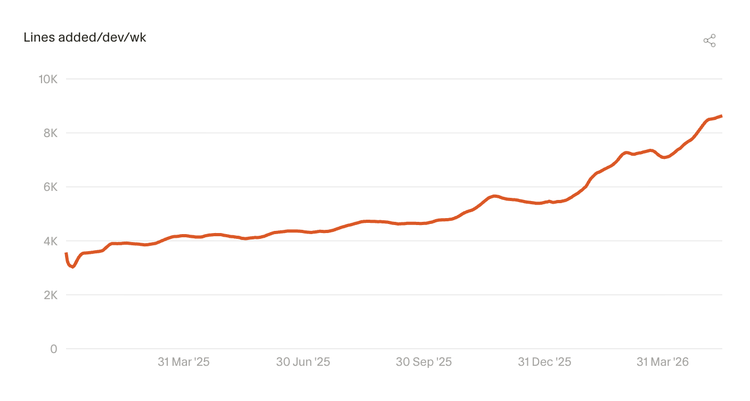
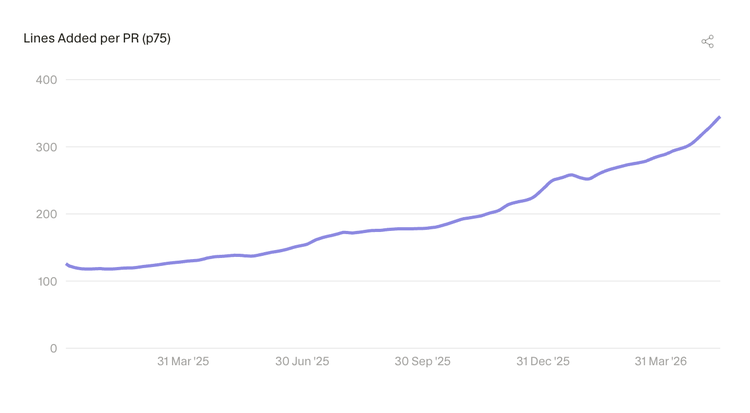
1.2 每次提交的代码量在增长
每次提交(PR)新增的代码行数,同比增长约 2.5 倍,且增速还在加快。
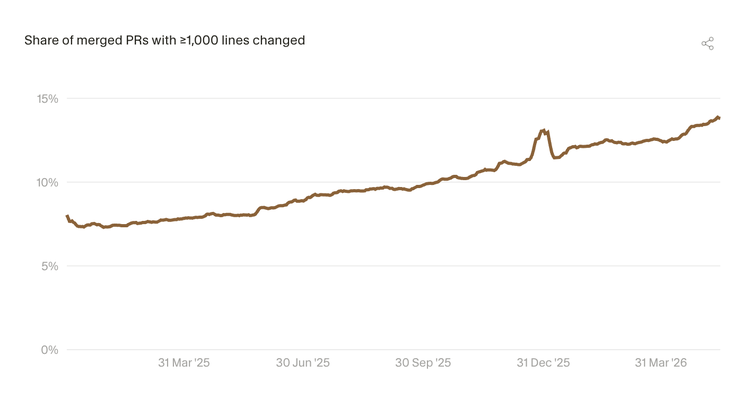
1.3 开发者在处理更大的任务单元
"超大型提交"(指改动至少 1,000 行代码的提交),变得越来越常见,因为开发者开始借助 AI 在单次提交中完成更大的任务。值得注意的是,2026 年 1 月超大型提交出现跃升——当时许多开发者正在试用最新的 AI 编程能力和模型。(OpenClaw)
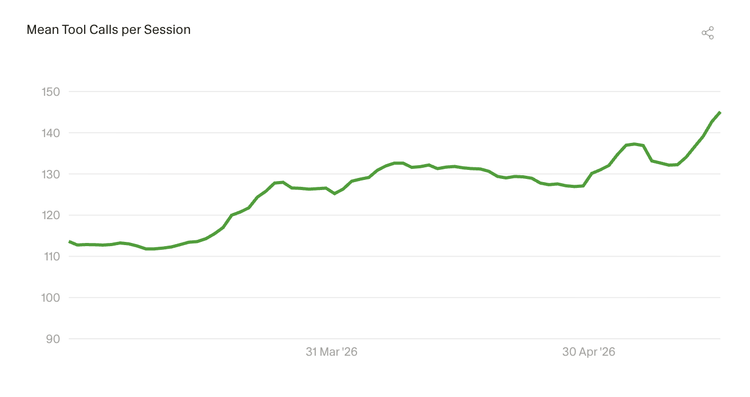
1.4 AI 对话的轮次在加深
最近两个月,每次 AI 对话平均调用的工具次数增加了约 30%。AI 编程助手正在承担更复杂的任务:更频繁地读取和编辑文件、搜索代码、运行命令行、浏览网页。
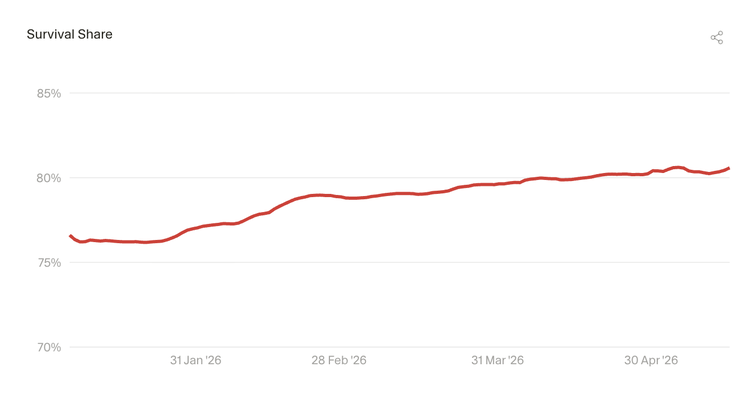
1.5 AI 生成的代码存活更久了
2026 年初以来,AI 建议的代码在被接受后 60 分钟仍然保留在代码库中的比例,从约 76% 上升到了 81%。
智能经济学
随着模型能力越来越强、使用的上下文越来越多、承担的任务越来越深,成本在产品体验中的比重也越来越大。
为了理解"成本 vs. 智能"之间的权衡,我们从三个角度分析了模型的经济性:请求成本、有效代码产出效率、以及成本与跑分表现之间的关系。
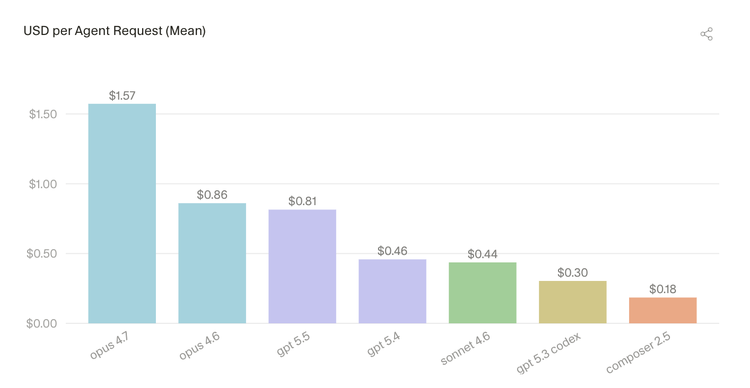
2.1 不同模型的请求成本差异巨大
不同模型系列的单次请求成本相差近 9 倍,说明同样的工作流,因背后使用的模型不同,成本差别巨大。
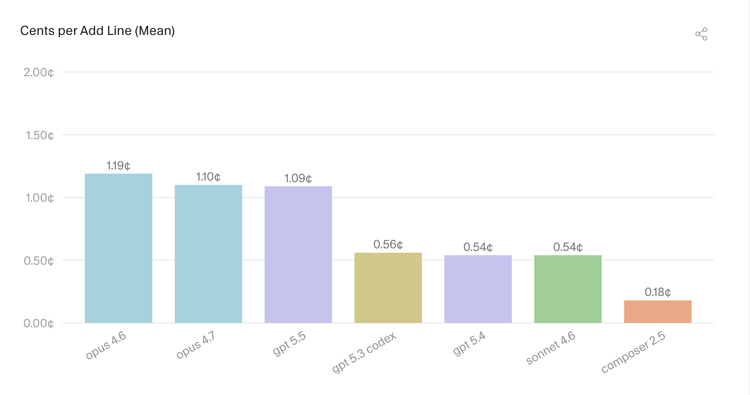
2.2 代码接纳率缩小了模型价格差距
便宜模型和贵模型,每次请求的价格可以差 9 倍之多。但看"最终留下的代码",最大差距只有 7 倍——因为贵模型一次能写出更多能用的代码,并不像表面看起来那么昂贵。
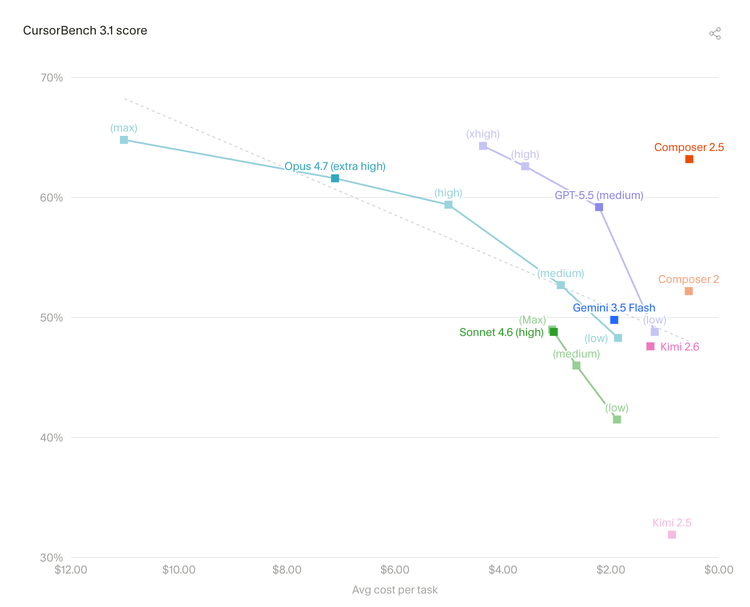
2.3 "成本-质量"前沿在移动
下图展示了各模型在 Cursor 内部评测(CursorBench)中的表现与平均任务成本的关系,呈现了各模型在"成本-质量"上的位置。
超级用户差距
AI 正在全面提升生产力,但这种提升在用户分布的最顶端最为集中。顶尖 1% 的用户获得的收益远高于其他人,且随着 AI 总使用量的增长,这种差距在绝对数值上还在继续拉大。
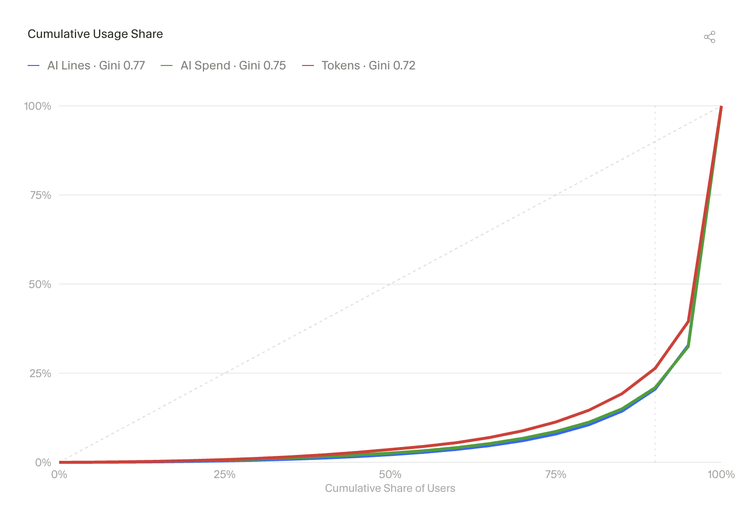
3.1 超级用户占据了 AI 活动的大头
AI 的使用高度集中:一小部分开发者,贡献了绝大部分的 AI 代码行数、AI 相关花费和 Token 消耗量。洛伦兹曲线显示了这种集中程度,三个指标的基尼系数分别为 0.77、0.75 和 0.72(0 到 1 之间,分数越高说明活动越集中在少数人手中)。
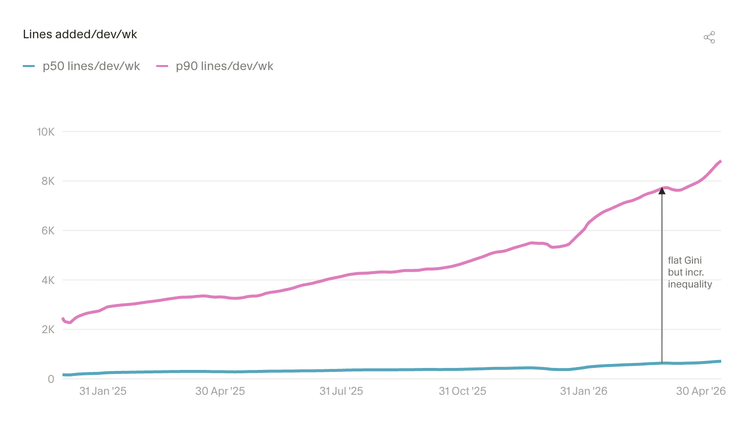
3.2 产出差距正在扩大
前90%的开发者与中位开发者的绝对代码产出差距正在扩大,而 P99 用户的领先幅度更是遥遥领先。
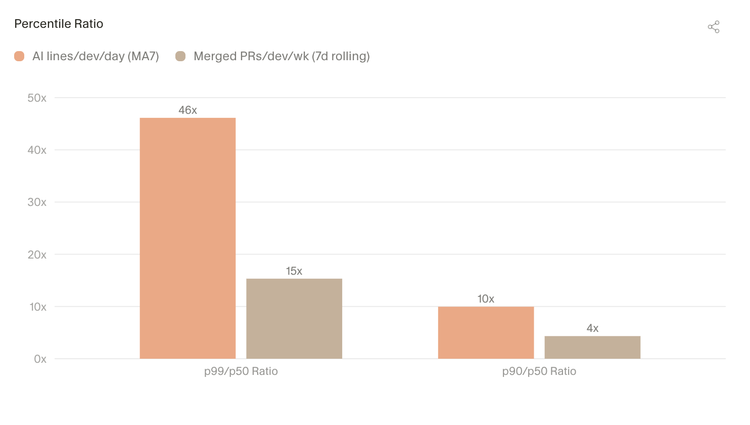
3.3 尾部的差距更悬殊
这是超级用户差距在尾部加剧程度的另一种视角。
从另一个角度看顶尖用户差距的惊人程度:P99 (前99%)开发者产出的代码行数是活跃中位用户的 46 倍,合并的提交次数是中位提交者的 15 倍。P90 用户虽然也有明显领先,但差距要小得多。
上下文的崛起
随着模型承担更复杂的任务,它们在输出之前会先读取更多上下文来理解代码库、用户意图和 surrounding 工作流。
这种转变对成本是有利的——因为输入 Token 比输出 Token 便宜得多,而缓存读取的 Token 更便宜。
上下文能力的提升,有助于模型写出更精准的代码,这与我们在"开发者加速"章节中看到的代码留存率上升是一致的。
4.1 模型在写代码之前,读得更多了
输入与输出 Token 的比例正在快速上升,说明模型每生成一个 Token,就要消耗更多的上下文信息。这表明模型在生成代码之前,做了更多"前期工作"。
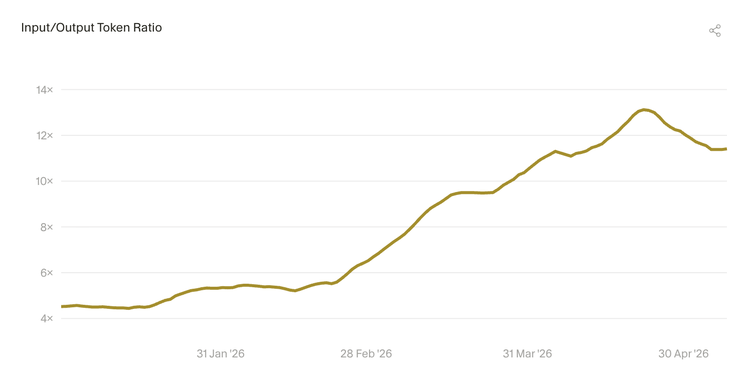
4.2 输入 Token 已占非缓存 Token 的大头
同样的趋势也体现在 Token 构成中。输入 Token 现在占输入输出总量的 90% 以上,上下文已成为非缓存模型使用中的主要部分。
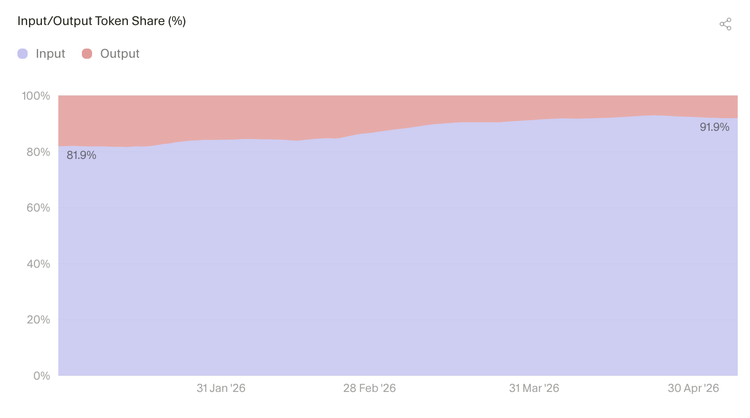
4.3 输入上下文正在成为 Token 成本的主要来源
输入 Token 消耗量大,但由于单价较低,对成本的影响被部分抵消了。即便如此,输入 Token 已在"等价价格"的 Token 成本中占多数,年初至今从约一半上升到近 70%。
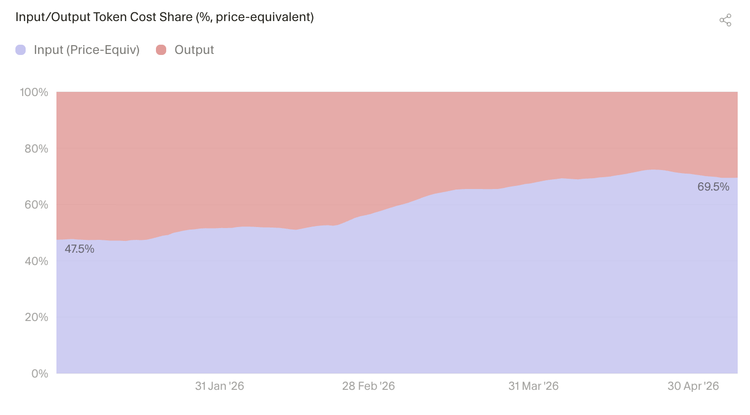
4.4 缓存读取主导了 Token
把缓存也考虑进来,"上下文"的边界更大。缓存读取 Token 占了 Token 活动总量的绝大部分,说明现在的 AI 工作越来越依赖重复利用之前的上下文,而不是每次都从头读取所有内容。
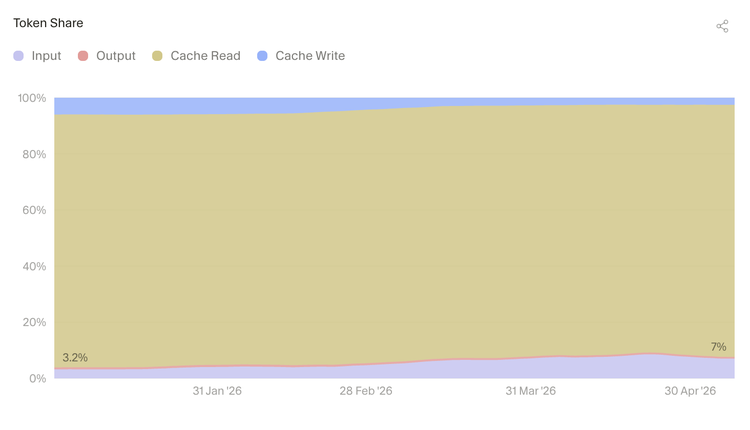
迈向自动化
AI 编程工具最初的目的是加速单个开发者的工作。我们在报告前面的章节中已经看到了这种影响:更快的编码、更大的提交、更深的 AI 对话轮次,以及更多 AI 生成的代码最终进入提交记录。
现在,AI 软件开发正在进入一个新时代——AI 正在成为基础设施,逐步实现软件开发全生命周期的端到端自动化。
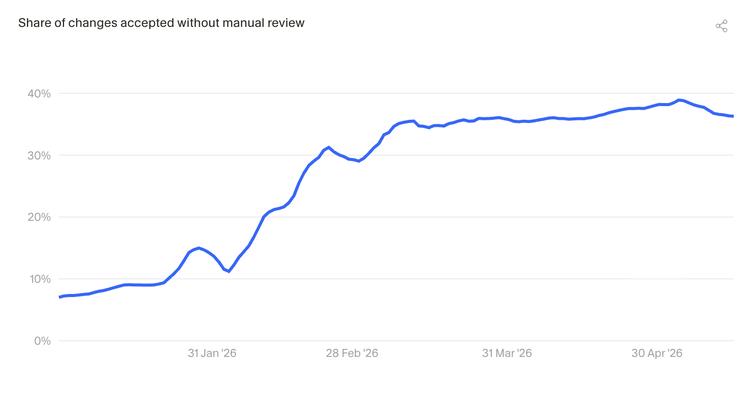
5.1 更多 AI 修改正在被自动接受
2026年开年以来,未经人工逐行审核、直接被自动接受并进入代码提交的 AI 修改,增长了 5 倍以上。这说明开发者越来越信任 AI,愿意让它独立完成更多提交流程中的工作。
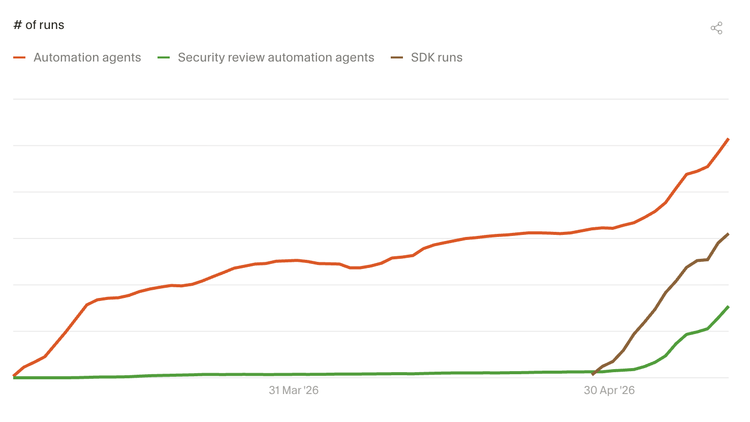
5.2 自动化正在向各类工作流扩散
虽然还处在早期,但第一批自动化模式已经开始显现。Cursor 自动化功能的采用正在快速增长,其中安全审核正成为一个强有力的自动化应用场景。更新的数据显示,SDK 运行功能也展现出初步需求——开发者希望把 Cursor 的 AI 基础设施变成可按需定制的可编程平台。
调研方式
本报告基于 Cursor 产品和工程数据的汇总统计,包括 AI 使用量、Token 消耗、被接受的 AI 代码改动、以及已合并的提交活动。大多数时间序列图表使用 7 天、28 天或 30 天滚动平均值,以减少短期波动噪音,让趋势方向更容易看清。所有指标均以汇总形式报告,旨在展示开发者如何使用 AI 构建软件的广泛模式。本报告不包含处于隐私模式用户的退出数据,包括与模型提供方签订零数据保留协议的用户数据。







