 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库终端AI 编程工具(Claude Code)中文场景软件工程SWE测评方案发布!

Claude Code 是 Anthropic 推出的命令行编程工具,以终端智能体形态运行,通过与底层大模型交互,实现对代码的理解、文件编辑、命令执行和多轮协作。它借助内置工具调用模型能力,可自动化完成复杂的代码修复任务。
然而,现有主流 SWE-bench 数据集多以英文 issue 为主,且缺少以 Claude Code 为框架、面向中文开发场景的系统性评测。为评估不同底层大模型在 Claude Code 框架下、面对中文问题描述时的真实代码修复表现,我们基于 SuperCLUE-SWE 构建了本测评方案。
(SuperCLUE-SWE)中文「软件工程」测评基准方案参考:中文「软件工程」测评基准方案发布!(SuperCLUE-SWE)
2026 年 3 月测评结果详情请见:2026年3月通用文本测评——SWE(软件工程)分析:海外旗舰领跑,国产模型梯队化突围
在 Claude Code 统一框架下,对比多个底层大模型(DeepSeek、Claude、GPT 等)的代码修复成功率。
考察各模型在中文软件工程任务中的语义理解、代码生成与修复质量,评估其对中文技术语境和文档的适应能力。
记录每个模型在 Claude Code 框架中的 token 消耗、调用费用、运行时长、交互轮数。
建立明确的量化判定标准,采用0-1 二元打分机制评估任务完成情况:任务达标赋值 1,未达标赋值 0。评价结果客观可横向对比,为模型迭代优化提供清晰指引。
# 题目概览
本次测评数据集共包含 95 个实例,全部来源于真实开源 Python 项目。所有实例的问题描述均为中文,由原始英文 issue 翻译或改写而来,旨在考察模型在中文软件工程场景下的代码修复能力。数据集涵盖开发者工具、Web 框架、科学计算、自然语言处理、数据可视化等多个领域,兼具功能多样性与任务代表性。
库名 | 占比 | 所属类别 | 功能说明 |
black | 28.4% | 工具 / 开发者生产力 | Python 官方代码格式化工具,自动 code style enforcement |
pyecharts | 16.8% | 可视化 | 基于 ECharts 的可视化库,用 Python 生成图表(HTML/JS 渲染) |
nonebot2 | 14.7% | Web / 聊天机器人 / 事件驱动框架 | 通过适配器接入 QQ、Telegram 等平台,构建自动化对话与事件处理 |
sympy | 10.5% | 科学计算 / 符号数学 | 符号计算库,用于代数、微积分、方程求解等 |
python-pinyin | 9.5% | 文本处理 / NLP 工具(属于“数据处理与语言工具”子类) | 将汉字转拼音的工具库,常用于中文 NLP 或文本预处理任务 |
httpx | 8.4% | Web / 网络 / HTTP 工具 | 现代化异步 HTTP 客户端,支持 sync + async API,Requests 的继任者 |
jieba | 5.3% | 文本处理 / NLP 工具 | 中文分词库,用于自然语言处理;内部算法含 Trie 树、词频统计等 |
fastapi-amis-admin | 3.2% | Web / 框架 / 管理后台扩展 | 基于 FastAPI 和 AMIS 的低代码后台管理系统框架 |
Tushare | 3.2% | 机器学习 / 数据分析 |
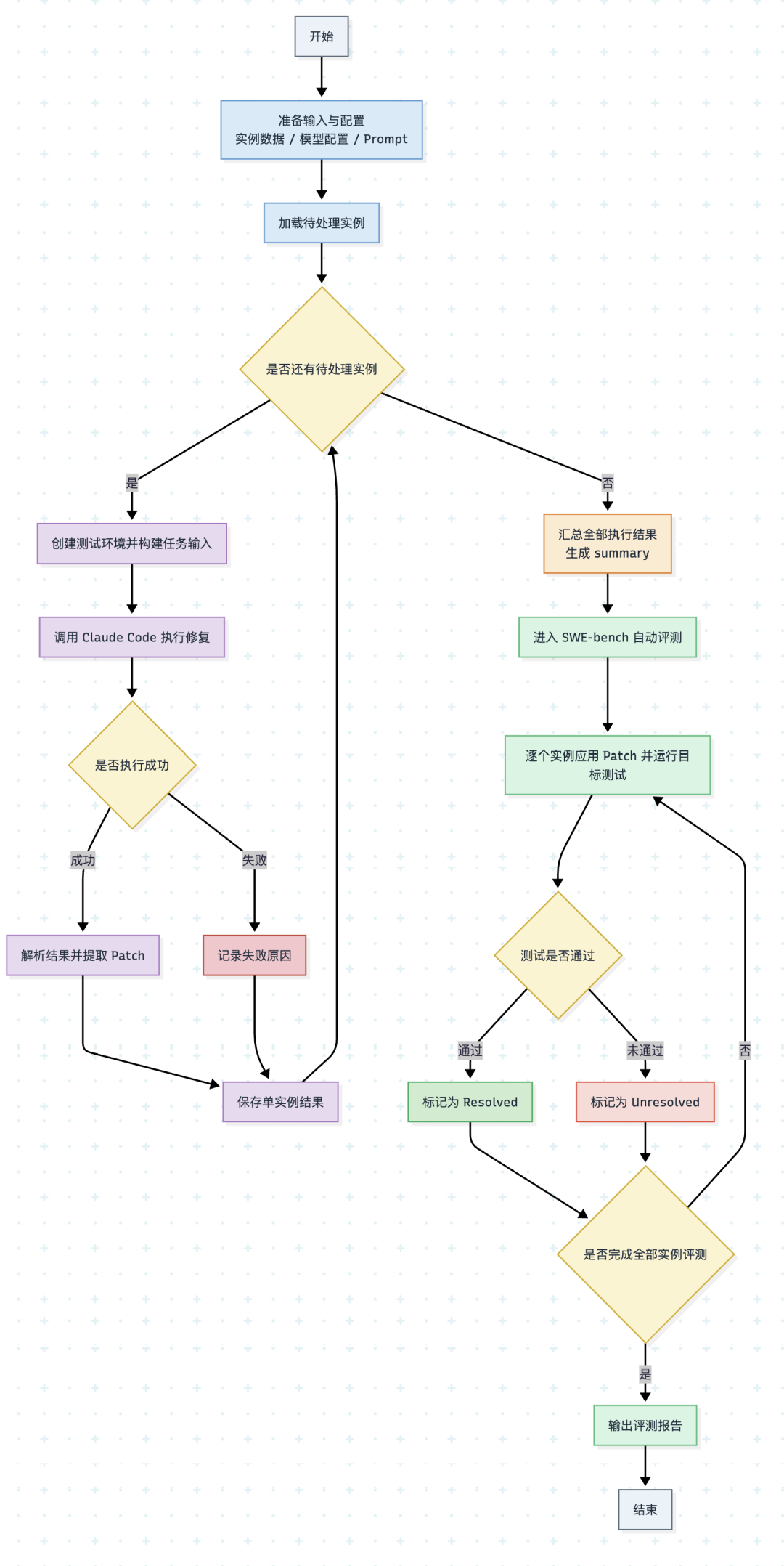
整个测评从加载实例数据集、模型配置与 Prompt 模板开始,随后进入循环修复阶段。对每个实例,系统首先创建隔离的代码环境(如 Docker 容器),将中文 Issue 描述和代码库状态作为任务输入提交给 Claude Code,由底层模型自主分析并生成代码修复。若模型成功返回 Patch,则解析并保存单实例结果;若出现超时、无输出或格式错误等情况,则记录失败原因。所有实例处理完毕后,汇总结果并转入自动验证环节。
验证阶段同样以循环方式进行:逐一将 Patch 应用到原始代码库,运行与该 Issue 相关的测试用例(如 pytest 指定测试)。测试全部通过则标记为 Resolved(已解决),否则标记为 Unresolved(未解决)。全部实例评测完成后,输出最终报告。
评分采用严格的二元通过制:单实例中,Patch 成功应用且目标测试全部通过计为 1 分,其余情况计为 0 分。整体核心指标为通过率,即 Resolved 实例数占总实例数的百分比。此外,可选统计执行成功率、测试通过率以及失败原因分布等维度。该评分完全由 SWE-bench 自动测试框架在隔离环境中判定,无需人工干预,确保每次评测结果客观且可复现。详细流程如下图所示:
总分的计算
模型得分=(得分为1的实例数量/记分实例总数量)*100%
# 评估示例
【测评模型】:deepseek-v4-pro(high)
【实例信息】:psf__black-4141
问题描述为:
`blank_line_after_nested_stub_class`:如果上一行是函数 def,则失效> 这是关于“blank_line_after_nested_stub_class”预览样式。如果类体以带省略号的函数定义结尾,则无法识别添加空行。> 例如,前面代码添加到 `file.pyi` 存根文件中:> ```python class TopLevel: class Nested1: foo: int def bar(self): ... field = 1> class Nested2: def bar(self): ... foo: int field = 1 ``` 运行:> ```bash $ black file.pyi ```> 结果代码中,空行只添加在 `Nested2` 之后,而不是 `Nested1` 之后。> **预期行为**> 预计在 `Nested1` 和 `Nested2` 之后都添加空行。> **附加上下文**> 问题似乎是 `src/black/lines.py` 中第一个 `if` 条件,需要交换条件顺序。
【给 Claude Code的提示词】:
System Prompt:
你是一名经验丰富的软件工程师,任务是修复开源代码库中的 bug。你会收到一个问题描述,并可以访问完整代码库。你的工作是:1. 通过阅读相关文件理解问题2. 定位代码中的 bug3. 做出最小化、聚焦的修改来修复 bug4. 运行相关测试验证修复是否生效规则:- 只修改修复 bug 所必需的代码- 除非修复本身需要,否则不要重构、重新格式化或改变代码风格- 除非问题明确要求,否则不要修改测试文件- 不要添加新的依赖- 除非必要,否则不要修改配置文件(setup.py、pyproject.toml 等)- 修改完成后,代码应能通过相关测试- 如果你无法修复该问题,请停止并报告你的发现
User Prompt:
请修复该代码库中的以下 bug。## 问题描述`blank_line_after_nested_stub_class`:如果上一行是函数 def,则失效[此处省略完整问题描述]## 修复步骤1. 首先阅读相关文件,理解问题(问题描述中会包含涉及哪些文件的线索)。2. 找到 bug 的精确位置。3. 只进行最小化的修复,不要引入无关改动。4. 修改完成后,运行相关测试以验证修复是否生效。5. 如果有 lint 或类型检查工具,也请运行,确保修改不会破坏任何检查。重要约束:- 只修复描述的 bug,不要重构或清理无关代码。- 除非问题明确要求,否则不要修改测试文件。- 不要添加新的依赖。- 保持修改最小化和聚焦。请逐步思考并执行。当你确认已经修复问题并通过了测试验证后,可以结束。
【Claude Code执行后输出的patch为】:
diff --git a/src/black/lines.py b/src/black/lines.pyindex b544c5e..9eb5785 100644--- a/src/black/lines.py+++ b/src/black/lines.py if previous_def is not None: assert self.previous_line is not None if self.mode.is_pyi:- if depth and not current_line.is_def and self.previous_line.is_def:- # Empty lines between attributes and methods should be preserved.- before = 1 if user_had_newline else 0- elif (+ if ( Preview.blank_line_after_nested_stub_class in self.mode and previous_def.is_class and not previous_def.is_stub_class ): before = 1+ elif depth and not current_line.is_def and self.previous_line.is_def:+ # Empty lines between attributes and methods should be preserved.+ before = 1 if user_had_newline else 0 elif depth: before = 0 else:
【执行swe-bench评测输出】:
"psf__black-4141": { "status": "completed", "FAIL_TO_PASS": { "success": [ "tests/test_format.py::test_simple_format[nested_stub]" ], "failure": [] }, "PASS_TO_PASS": { "success": [ "tests/test_format.py::test_simple_format[function]", "tests/test_format.py::test_simple_format[comments]", "tests/test_format.py::test_simple_format[class_blank_parentheses]" ], "failure": [] } }
评测说明:通过FAIL_TO_PASS指标可判定,原执行失败的测试用例,应用 Claude Code生成的补丁后可正常运行;通过PASS_TO_PASS指标可判定,原执行通过的测试用例,应用 Claude Code生成的补丁后结果仍保持通过。两项指标同时满足则判定该题目修复完成,得分为 1 分。
# 参与测评
参测流程
1.邮件申请
2.意向沟通
3.参测确认与协议流程
4.提供API接口或大模型
5.获得测评报告
邮件标题:基于claude code框架的SuperCLUE-SWE软件工程中文测评申请,发送到contact@superclue.ai请使用单位邮箱,邮件内容包括:单位信息、大模型简介、联系人和所属部门、联系方式
联系我们






