奇绩创业营校友「脸谱心智」完成数千万元 Pre-A 轮融资
发布时间:2026-07-01来源:奇绩创坛
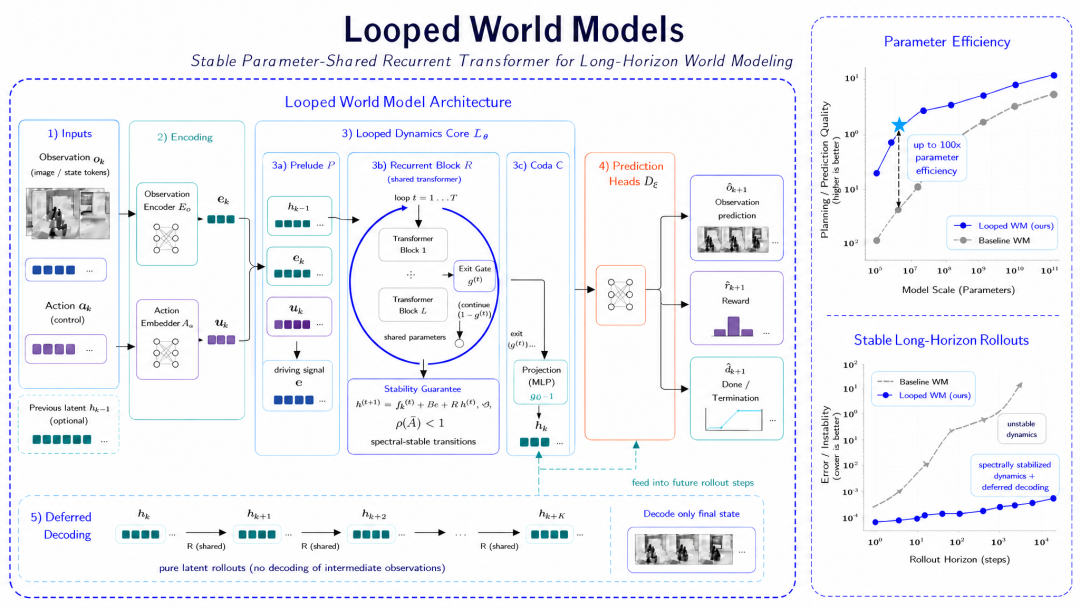
奇绩创坛 2023 年秋季创业营校友企业,世界模型公司脸谱心智(FaceMind)完成数千万元 Pre-A 轮融资。他们提出了一种循环式世界模型架构(Loop World Model)。相比不断堆叠参数和计算量,它试图让模型像思考一样反复迭代,在隐空间中持续修正自己的状态,并通过 Early Exit、Deferred Decoding 等机制,把有限算力分配到真正重要的推理步骤上。图为脸谱心智参加奇绩 2023 年秋季创业营路演日某种程度上,LoopWM 讨论的已经不只是一个具体模型,而是另一个更大的问题:当世界模型最终走向机器人、工业系统乃至真实物理世界时,未来的 Scaling Law 是否还会沿着“大模型+大算力”的路径继续前进,还是会诞生新的计算范式?本期访谈,我们与 FaceMind CEO Adam Lu 展开了一次深入对话。从 Imperial College 与港中文的科研经历,到创业过程中对 world model 的判断;从 LoopWM 的设计逻辑,到他对于架构收敛、测试时扩展(Test-Time Scaling)、机器人文本理解以及世界模型未来三年的预测。此外,Adam 在与 ZP 飞行 Host 的对谈中,还讨论了世界模型的 ChatGPT 时刻。它或许还没有到来,但真正重要的问题已经越来越清晰:未来的 AI 不只是生成世界,更要学会在世界里思考。而 LoopWM,正是他们给出的一个答案。我们也将这些片段完整整理出来,供大家更加直观感受一线研究者们在真实语境中的思考与碰撞。FaceMind CEO Adam Lu(左)& FaceMind CTO Victor Wei (右)本次采访的飞行 Host 是来自清华大学智能产业研究院(AIR)的邹恬圆,研究方向为世界模型、多模型融合、数据隐私、数据合成。很多 world modeling 方法做 test-time scaling,是用指数级方法生成更多未来世界的可能性,再选一个最优解;我们想做的是一个线性的、适合机器人或世界模型领域的 test-time scaling 方法。Deferred Decoding 更多是为了避免每一步都把可能错误的状态 decode 出来,然后把错误放大;我们希望它在隐空间里继续推理,用更 continuous 的 representation 做进一步推演。因为 loop model 本身有 loop 的性质,所以训练初期最核心的问题是,长 horizon 的任务很难直接优化。而如果把所有数据直接丢进去、随机打乱训练是不行的,所以我们做了 hierarchical curriculum learning。有些比较简单的任务,在传统 deep stacked layers 里会被忽略掉,特别是在很深的模型里会出现梯度消失,而Loop 架构在这个问题上会好很多。我认为核心原因是,越深的 model 越适合处理比较难的问题,但 world model 的任务复杂度差别很大。具身领域里的任务难度差异非常明显:让机器人在房间里走动一下,和让它拿起一杯水,难度差别非常大;这种差异就适合 loop 架构。现在大家看 world model,基本还在解决空间层面的问题;但我们肯定希望未来的机器人能够先拟合人类,再进一步超越人类,而机器人能不能在空间世界里理解文字,是现在还未被完全解决的问题。World model 本质上是一种 World simulator,以此来解决现有的仿真环境中不够拟真的问题。有可能现在的 WAM 架构还不是未来最优解,因为 WAM 本质上是一种联合训练,但 World model 更多的要素对于具身场景来说可能是一个数据提供源。01 从隐空间循环,LoopWM 试图绕开逐帧生成的旧惯性ZP:在正式进入 LoopWM 之前,想先请你按时间顺序介绍一下自己?从 ICL 本硕、CUHK PhD、MSRA 实习,到后来创办 FaceMind,这几段经历分别如何影响你今天的选择?Adam:我 2017 年到 2021 年在英国 Imperial College London 读计算机本硕。当时选择计算机,主要是因为我喜欢打游戏,也喜欢写程序。那段时间其实没有特别强的科研导向,更多是在写代码,也会写一些小游戏。现在写代码有 AI 辅助,会方便很多,但当时基本还是自己一行一行写,我也很享受这个过程。在 Imperial 做毕设时,我遇到了一位对我影响很大的老师 Daniel Rueckert。有一次我拿着一篇大机构的 paper 去和他聊,说我觉得这篇文章很不错,可能因为它是 Google 做的。他提醒我,不要只看 title,也不要只看机构。即使作者来自 Google,也还是要看文章本身的贡献。他还告诉我,不管在哪个 institution,只要 contribution 足够好、足够新颖,就能做出非常有意思的东西;真正有品味的人,应该能够抛开 bias。这件事对我影响很大。它让我意识到科研和创新是非常 global 的,并没有那么强的边界。只要贡献本身有价值,就应该被看到。那时我还只是在做本科毕设,但已经对科研产生了很高的期待。后来我选择继续做 AI research,一方面是因为我确实想做科研,另一方面也和我从小喜欢二次元、喜欢《刀剑神域》这类作品有关,里面有很多关于 AI 的想象。毕业之后,我去了香港中文大学读 PhD,跟着 William 教授做科研。他是一个比较低调的老师,在国内不太宣传,但我觉得他非常厉害。我也会承认,自己在科研上应该还是有一点天分的。刚开始读 PhD 时,我比较快地做出了一篇一作工作,当时只有我和老师两个作者,也拿到了不错的 award。那个阶段我会觉得,自己在 research 上可能确实还可以。但在读博期间,我也开始思考创业。因为我在跑 benchmark 的过程中很快发现,benchmark 有时并不能代表一个东西真正落地到现实世界后的效果。比如我早期在 PersonaChat 这个 dataset 上做 benchmark 时就发现,行业里有很多东西不会写进 paper,也不会直接告诉 junior researcher。benchmark 本身也可能有 flaw,尤其是一些对话数据集,它的数据收集方式会带来限制,有些甚至是在虚假数据的基础上继续收集后续对话。所以那段时间我逐渐意识到,如果想让研究更有意义,或者真正落地到现实生活中,做一家公司可能会更合适。我当时觉得,自己已经接受了足够多的 academic training,接下来希望把技术真正落地。2022 年到 2023 年,我在 MSRA 实习了一段时间。实习之后,我第一时间想的是成立自己的公司。当时我还在读书,所以没有全职运营。公司最开始选的题目其实不太符合我们的团队画像,我们做的是 AI 陪伴类产品,更偏应用和运营,不那么偏技术。后来到了 2025 年到 2026 年,我毕业后,公司正式开始运营,我们也把方向调整到了 world modeling。直到现在,公司一直在做这个方向。我认为它更符合我们团队的背景和能力结构。公司也拿了几轮融资,包括星连资本、360 集团、奇绩创坛等,股东也都很支持我们做这件事。他们也认为,我们团队比较适合做 world model。今年 world model 的竞争确实很激烈,但我们也做出了一些我认为 contribution 比较高的产出。最近常有一些大机构的人来找我们交流,英伟达可能是最早注意到我们方案的国外大公司之一,他们评价这篇工作为“highly valued contribution”,可以看出这篇文章现在业界已经有了一定关注度,离我们最近的是英伟达。ZP:你的 research taste 是怎么一点点形成的?怎么判断一个问题值不值得做?Adam:可能最重要的还是多看、多做。比如我在读 PhD 之前那个暑假,基本上就是疯狂看很多论文。我觉得对 junior researcher 来说,很重要的一点是先开始做。学界里面有些人会说,A 加 B 不是好东西,或者某种组合不够有意思。一个很 junior 的 researcher 可能会花很多时间想,我到底要做什么才足够有 impact。但我自己的经验是,有时候 A 加 B 也能让人眼前一亮,关键取决于具体的 A 是什么、B 是什么,以及你怎么把它们结合起来。所以核心还是要有自己的判断。互联网上信息很多,每一条信息都可能带来一种认知偏差。比如今天你上知乎刷很多评价,看到别人说 A 加 B 不是好 work,你可能就会被影响。但实际上,A 加 B 也可能是好东西。我的风格是先找一个自己觉得大概可行的方向,然后直接下手做。很多事情在你真正了解它之前,我觉得可以先快点开始,看看结果,再用结果给自己反馈,之后再迭代、调整方向。ZP:公司后来定 world modeling 这个大方向的时候,也是类似的判断逻辑吗?Adam:不是完全一样。我觉得公司定大方向和学术科研不太一样。学术科研更强调找一个比较新的东西。比如你找到一个很新的 idea,reviewer 通常也会花时间认真判断它的新颖性和贡献,因为学术评审大多是 anonymous 的,不太看 researcher 背景。只要新颖性足够强,是有可能中的。但公司选方向,尤其是要融资的公司,逻辑会不太一样。World modeling 这件事本身是一个重要共识。投资界一般更倾向于投一个已经成熟的概念,再叠加一个不错的团队,里面的方案可以稍微新奇一点。如果是完全全新的东西,VC 反而可能会害怕。所以公司在选择大方向的时候,不需要一开始就创新,更合适的做法是先进入一个主流、重要、大家认可的方向,在里面做具体创新;等公司到一定阶段、有足够背书之后,再追求更大的创新。就我自己看,FaceMind 做 world model 这件事情本身没有那么大的创新,但 LoopWM 我觉得算是挺大的创新。至少从学界反馈来看,很多人都觉得这是一个大创新。在 X 上也有人觉得,这可能是一个全新的 world model 方向。ZP:LoopWM 一个很重要的特点是通过 iterative loop 做 long-horizon reasoning。你们训练的时候,有没有遇到数值稳定性或者其他训练难题?Adam:因为这个 model 本身有 loop 的性质,所以训练初期最核心的问题是,比较长 horizon 的任务很难直接优化。我们发现,如果把所有数据直接丢进去、随机打乱训练,是不行的。所以我们做了 hierarchical curriculum learning。第一层是从简单任务到困难任务。分类方式是,我们先训练一个普通的 world model,也借助别人的 world model 做分类。那些短的、容易被判别、准确率比较高的任务,我们归为简单任务;准确率比较低的任务,我们归为困难任务。第二层是按照步数来做 curriculum,比如从 1 步、2 步、3 步,一直到 100 步。现在我们实验已经做到一两百步。越长的 rollout,我们认为越难。所以最后是把两个维度组合起来:越短越简单,越容易被分类也越简单,然后按照从简单到难的顺序递进。这样训练出来效果会更好。ZP:除了排序之外,你们对训练数据有没有一些特定观察?哪类数据更有用,哪类数据作用没有那么大?Adam:我们最早是在普通架构上发现一个问题:有些比较简单的任务,在传统 deep stacked layers 里会被忽略掉,特别是在很深的模型里会出现梯度消失。Loop 架构在这个问题上会好很多。我认为核心原因是,越深的 model 越适合处理比较难的问题,但 world model 的任务复杂度差别很大。具体到 loop 架构,我们发现仿真环境里的某些数据效果非常好。比如 ManiSkill、DexArt 上的一些灵巧手仿真数据,因为灵巧手操作涉及更多维度,复杂度范围比较广,所以对训练很有帮助。相反,如果只是普通夹爪类型的仿真数据,效果相对没那么好。一直往训练里加这类数据,不会带来那么明显的收益。ZP:你们想到 loop 架构,是不是直接来自于这种简单任务梯度消失的问题?还有没有其他原因?Adam:是多方面的,主要有两个原因。第一个跟机器人或者具身智能领域很相关。对本体来说,让它在房间里走动一下,和让它拿起一杯水,难度差别非常大。走动相对简单,拿杯子涉及更多维度、更多约束,所以更难。具身领域里的任务难度差异非常明显,这就适合 loop 架构。第二个原因是 test-time scaling。这个我们没有完全写在论文里,但我们的方法可以做 test-time scaling,特别是在 loop 收束之后给它一些扰动,让它继续 loop。我们看到很多 world modeling 方法做 test-time scaling,是用指数级方法生成更多未来世界的可能性,再选一个最优解。我们想做一个线性的、适合机器人或世界模型领域的 test-time scaling 方法。我们现在做的扰动,是每次模型收束之后,给它一个随机 perturbation,让它继续进行一个 loop。所以它的复杂度是线性的。而有些方法会用蒙特卡洛搜索树,那在 world model 的搜索里会变成指数级。结合这两个 motivation,我们最后决定做 loop 架构。02 在隐空间继续思考:Deferred Decoding 的效率与稳定性ZP:你们在 abstract 里写到,LoopWM 可以达到两个数量级的 parameter efficiency 提升。能不能展开讲讲,这个 100 倍提升是如何衡量的?Adam:包括 paper 里的实验,以及我们内部的一些 in-house 实验,我们发现它能够跟一些更大的 world model 打到 on par。比如百 B 级别的模型,或者 web 上一些 world model 任务的最终拟合结果,我们用更小参数也能达到类似效果。所以这个 parameter efficiency 指的是,我们用更小的参数量达到更好的最终结果。当然它也有 trade-off,就是训练难度会更高。相比传统模型,它在训练过程里更难训,所以训练 know-how 需要一定经验积累。除了参数量,inference level 的 FLOPs 也会更低。在某些任务上,它能够用非常小的推理消耗达到类似效果,特别是一些简单到中等难度的任务。因为这类任务本来不需要那么多 computation,如果用太深、太大、太宽的模型,反而会浪费资源。而我们可以通过 adaptive early exit 动态分配计算量。ZP:之前有些论文说,looped language model 相比非 loop 模型大概有 2 到 3 倍 parameter efficiency 提升。你们这里的 100 倍,关键差异在哪里?Adam:我觉得核心还是任务难度的区别。在机器人领域,简单任务和困难任务的差异特别显著,仿真环境和真机环境都会有这个现象。任务本身就比较适合这种架构,所以提升会更明显。ZP:我们聊聊 early exit。它能让模型把算力动态分配到不同难度的题目上,是一个很重要的设计。你们在设计 Early Exit Gate 的时候,有什么观察?Adam:我们发现一个比较有意思的点:在多步任务里,它不一定每一步都必须完全 converge。比如我们做一个 action、再做一个 action、再做一个 action,可以做 deferred decoding,不希望每一步都 decode 当前 world model 的状态,而是多步之后再 decode。在这个过程中,我们也可以选择什么时候暂缓 world model 的 computing。它不一定要完全 converge,我们可以在它尚未完全 converge 的状态下,继续喂给它下一个 action。最后也能得到一个不错的 trade-off。比如在某些 case 上,相比每一步都等它 converge 再继续计算,最多能节省 30% 左右的 computation,代价是 accuracy 掉三四个点。我会认为,对于特别精密的操作,不一定要用这个策略;但如果是在比较自由、容错率比较高的环境里,它可能是进一步节省算力的办法。ZP:也就是说,不把每一步都推到 converge,性能会掉一点,但 computation 能降更多?Adam:没错。就是不 converge 之后,继续喂给它一个新的 action,让它做多步 rollout。一开始我们也会担心它会崩得很厉害。比如业内普遍认知里,DreamerV3 这类模型 rollout 到 50 步以后,compounding error 就会比较明显。但我们这个模型,如果每一步都让它 converge,在实验室环境里两三百步也不太会有很大的 compounding error 累积。即使提前 early exit,在百步左右,compounding error 也还是比较可以接受的,最后 decode 效果也能接受。对整个 world model 社区来说,我觉得这是一个不错的结果。ZP:直观上看,Early Exit Gate 学到的是什么信号?Adam:它是 trainable 的。从比较容易理解的角度讲,它学的是机器人是否已经完成自己的任务。但从 empirical 的角度看,gate 在某些条件下学到的,可能是上一轮 loop 和这一轮 loop 结果之间的 difference。也就是说,当语义上、embedding 上已经比较稳定的时候,它就会启动 early exit,让模型提前停止 computation。ZP:Looped Dynamics Core 里有 Prelude、Recurrent Block 和 Coda 三部分。你们当时怎么决定不同部分放多少 Transformer 层?Adam:这个是在资源比较有限的情况下做的经验决策。现在我们更多在探索把它做得更宽,因为宽度更有助于并行计算。Loop 架构本身对 GPU 并行不是特别友好,所以与其说我们关注层数,不如说更关注宽度。业内其实有很多选择,比如窄-宽-窄。我们当时选择的是三个部分比较相近的配置,现在还在微调。对于 loop 架构,也有一些业内解读会关注 residual 设计,但不是每个 loop 都一定要这么做。我们发现,在某些特定层上加 residual,确实会带来效果提升,但不是所有层都需要。ZP:Deferred Decoding 也是一个很重要的设计。它更多是出于 efficiency,还是出于 performance 考虑?Adam:Deferred Decoding 主要还是在 inference 阶段用。训练的时候,我们甚至会做一些 data augmentation,比如更早 decode,让它作为 loss 传递信号的一部分。在推理维度上,Deferred Decoding 更多是为了避免每一步都把可能错误的状态 decode 出来,然后把错误放大。我们希望它在隐空间里继续推理,用更 continuous 的 representation 做进一步推演。但你刚才说得也对,训练过程中还是需要在不同位置做梯度回传,这样效果会更好。ZP:所以不是每条链都在每一步回传梯度,而是在不同链条、不同步数上做回传?Adam:没错。这个设计其实也可以看作是一种隐空间的数据增强。ZP:Deferred Decoding 在训练过程中有什么难点?Adam:最早做 Deferred Decoding 训练的时候,我们也做了 curriculum learning。如果一开始就让它在很早的思维步数做 Deferred Decoding,模型收敛会有问题。特别是它自己还要决定什么时候 early exit,如果这个方法一开始就过于激进,就会导致模型过早判断自己可以 early exit。所以我们会冻结一部分相关参数,尤其是 early exit 相关的 prediction head,再结合数据层面的增强。可以理解成,在使用这个方法的时候,我们会把 Early Exit Gate 的 prediction head 先冻结住,避免两个难训练的东西一起训练。ZP:Latent Consistency Loss 的权重是不是也要调得比较高?Adam:对,它需要调得更高一些。这个 consistency hyperparameter 在整个 loop model 里面是很重要的环节。如果调低了,performance 会不好,甚至会训炸。模型确实对这些 hyperparameter 比较敏感。ZP:回到整体训练,你们觉得 LoopWM 训练里最需要关注哪些点?Adam:模型刚开始训练的时候,我们花了挺长时间,至少一个月左右,在探索它为什么一开始不稳定。我们最早是把整个数据都堆进去一起训练,后来发现,对于比较小量级的模型,如果一开始就给它很难的任务,它的泛化性会比较差。这是核心原因。Loop 类模型一直被关注的一个问题就是泛化性。在我们的 world modeling 任务里,最核心的调整就是 curriculum learning。刚刚说的两个层级,基本就是为了解决这个问题。另外,在推理过程中做一些 inference data augmentation,也能够增强最终效果。比如之前有一个 masked world model 的 work,会把推理数据替换成纯色背景,做 world modeling,也能得到提升。我们在仿真环境里也发现,如果训练数据里只有某一种背景,比如家居仿真环境,那么在 inference 时做场景替换,把家居背景和工业仿真背景做一些变化,也能增强效果。这可能是 loop model 的一个特性:它的泛化性本来就需要一点补强。Hyperparameter 方面,我觉得最重要的是 loss 那块的 hyperparameter。我们调参还是比较经验型,会参考过往经验。因为小团队算力有限,所以不算特别 exhaustive 地做 grid search。
03 世界模型何时迎来自己的 ChatGPT 时刻ZP:你们当时做出 LoopWM 的核心贡献者大概有多少人?作为 CEO 和技术负责人,你在小团队协作上有什么经验?Adam:我们公司算法团队一共不到 10 个人,基本上都 all in 这个项目。团队分工比较明确,特别是跑实验的时候,会分几条 parallel 的线去调参。不同实验合到一起时,确实也会遇到沟通和合版的问题。我的感觉是,还是要多沟通,尤其线上沟通很重要。我们团队经常会有 random call。语言上的沟通有时候比文本沟通更重要。大家都非常积极,会主动 reach out 另一个人,也会很快回复。这是一个比较好的状态:大家都 all in 同一个 work。学界可能会不太一样,因为大家通常有很多课题并行展开。对公司小团队来说,stay focused 很重要,它能提升团队的聚焦性。我们内部不太会出现 10 个人同时做几个 project 的情况。未来团队变大之后,今年我们可能还是会更聚焦在把 architecture 打好,把模型架构搭好,再进一步迭代参数。当然我们也会有一些比较 pilot 的 study,探索一些前瞻性方法,之后再合到模型里。我觉得未来可能还是要区分 pre-train 和 post-train,把团队做一些拆分。只是我们目前还没有这么分。ZP:论文里提到 iterative latent depth 可以作为 scaling law 的补充。你怎么看这件事?Adam:对机器人来说,现在也有一些 VLA 相关的 scaling 方法。比如有些工作会用蒙特卡洛搜索树做搜索,基本沿用 MuZero 那条线去做机器人操作。它的核心问题是搜索树会指数级膨胀。还有一些 work 会生成多条未来视频,再评估哪条最好,然后让机器人执行对应 action。我们自己的判断是,对 world modeling 任务来说,需要更 efficient 的 test-time scaling 方法。指数级复杂度太膨胀了,尤其是机器人场景里,动作生成需要非常丝滑、非常流畅,可能是毫秒级延迟。我自己在 Chain-of-Thought 刚出来的时候,也做过一些类似探索,把 CoT 和某些方向结合。有些人也会在 VLA 的 Chain-of-Thought 过程里做 test-time scaling。我们在项目早期也尝试过,确实有效果,但它比较聚焦在 discrete 文本上,而且有些任务里 CoT 到底有没有用,本身也会被质疑。我们现在这个方法让我比较满意的一点是,它在隐空间里可以持续做 test-time scaling,而且复杂度是线性的。它也和 rollout 过程天然相关。未来我们希望 test-time scaling 能和 rollout 结合起来:某些重要动作是不是可以多 scale 一些?每次 rollout 到不同位置,test-time scaling 到底 scale 多少,能不能端到端地动态决定?这是我们希望未来模型能解决的事情,也可能是之前很多 work 比较疏漏的点。ZP:你们未来 scale up,是更想做 test-time scaling 的精细控制,还是 scale up model size?Adam:这两个维度我们都有探索。参数维度上,我们也在补充团队算力,主要是往更宽的方向做。根据目前 in-house 结果,我们看到模型不仅能用比较少的数据达到比较好的结果,而且 scale 到更大的 size 时,这种特性仍然能维持。下一步我们预期要把它 scale 到 10B 量级,同时也会继续做 test-time scaling 的优化。ZP:scale up 的时候遇到什么新困难了吗?Adam:有一些设计都需要调整,特别是 curriculum 的设计。我们发现之前一些步骤、一些设计,在 scale up 之后都要重新调。从底层角度看,这也是小团队路线的一个弊端。很多团队可能会先做一个大模型,再蒸馏成小模型,或者做参数裁剪优化。我们因为资源有限,是先做小模型,再尝试 scale 上去,所以中间确实会遇到一些问题。能复用的参数比较少,encoder 其实可以复用一部分,这样能节省一些后续成本。ZP:你觉得 world model 最早能在哪些领域落地?Adam:我觉得机器人、医疗健康、工业界会比较适合落地。当然这也跟我们团队背景有关。我们确实有一些工业界资源,另外在数据层面,我们也有一些跟医疗、残障人士相关的自动化机器辅助,以及机械臂设计相关的积累。未来可能不只是某一种机器人。我认为这类模型对辅助类机械臂、工业场景、甚至家用机器人都会有帮助。现在也有很多人在做家用机器人,我们仿真环境里也有一些家用机器人任务。我也看到有网友开始尝试把现有的视频类 world model 改成 loop 版本。如果把视频生成模型、DiT 架构或者其他现有架构做成 loop,我觉得也可能减少 rollout 里的 compounding error。ZP:你现在创业做 world model,和你 PhD 做的研究关系大吗?Adam:这件事和我过去的积累关系很大。我从 2023 年就开始做 spatial reasoning,从 2022 年开始也一直在做 loop model,在这些研究方向上也发了几篇一作或者通讯的顶会论文。机器人领域现在有一个趋势,是很多人尝试用 LLM 的思维把机器人 work 做得更好。我自己认为,未来 world modeling 团队一定会是 world model 或机器人背景,加上 LLM 背景的人组合在一起。我们团队本身就是 hybrid 的画像。我自己做过 LLM,也做过空间智能,这些都和公司需要的人才背景相关。ZP:你觉得 world model 现在处在什么阶段?大概什么时候会迎来自己的 ChatGPT 时刻,或者真正落地?Adam:我觉得现在还处在一个非常混沌的阶段,基本是百家争鸣。这个事情还是很困难。与其说现在就谈落地,不如说它要分步骤。第一步肯定是先把 architecture 定下来。有些团队在这个过程中也会并行探索 data 相关的事情。我判断 architecture 可能在 2026 年末到 2027 年中之前,会有一个比较明确的结论:大家会知道大概要用哪种 architecture。数据这个事情可能需要更久,可能还要 1.5 到 2 年。因为现在有很多方向,比如因果方向、隐空间方向、机电信号、sEMG 信号等等。什么时候大家能在数据层面有一个比较收敛的结论,可能还要等一段时间。还有一个事情是具体下游场景。未来某个时间点一定会有一个特别突出的下游场景爆发。就像 coding 一样,三年前也没有人能想到 LLM 的 coding 会是这么好的场景。我觉得 world model 要等到大家真正看到哪个落地方向最好,可能还要三年左右。ZP:在这个图景下,你期待 FaceMind 扮演什么角色?Adam:初期还是往更通用的模型方向发展比较好。现在谁也不知道最终落地是什么样,也说不清楚具身是不是最好,或哪个场景的具身落地最好,也无法确定视频生成是不是最好。所以现阶段更通用一点会比较好。我希望今年之内,我们的 architecture 能迭代到一个比较完善的版本。同步地,今年下半年我们会开始在数据层面做一些创新,引入新的 data format。至于具体确定哪个落地场景,更多可能在明年年末之前,内部再做一个大方向决策。我们会先按照自己的想法在工业界做一些尝试,但真正的大方向选择,可能还要等明年年末再看。Adam:我们之前的项目还在运营,也有一些广告投放需求,这个先不展开。就 world model 这个项目来说,我觉得核心还是 ToB 定制化。现在也有一些厂商接触我们,尤其是想要 world model 能力的厂商。模型定制化交付的客单价还是挺高的,这类交付本身也是能够赚钱的。所以我们大概率会主要从这方面产生营收。ZP:你希望 FaceMind 在 world model 发展路线上处在什么位置?Adam:肯定是 leading 的角色。我希望我们在国际上都能做最领先的创新,别人会借鉴我们,甚至抄我们。我觉得这是我们想扮演的角色。从生态角度来说,最后收获最大的肯定是最领先的那批人。当然中间也会遇到问题,比如有人会担心大家是不是太上心(我们的技术路线)、竞争太激烈,这些也是我们要解决的问题。ZP:未来两年,world model 最大的突破可能来自哪里?是 architecture、数据、benchmark,还是 closed-loop feedback?Adam:现在没办法很确定地说。我觉得这是一个综合问题。architecture 肯定非常重要,而且应该是先定下来的;然后才是模型训练和数据层面的调整。我觉得对模型公司来说,先做什么再做什么其实是一个物流问题,很多东西都很重要,但是优先级和顺序是一个关键要素,用一样的资金和时间,顺序的不同会导致最后竞争格局的不同。但我觉得还有很多路要走。现在的一些路线肯定不是终点,不只是模型调整,也包括范式调整。比如某些需要 shared path、多任务学习的方式,或者 world action model,它们也不一定是终点,接下来一年左右可能还会有一个接力棒。这个领域未来还有太多可以做的事情。不仅是架构、训练、数据,从任务的基本定义上也可能会变。现在大家看 world model,基本还在解决空间层面的问题。但未来如果是机器人,我们肯定希望它能够拟合人类,至少先拟合人类,再进一步超越人类。这里面会涉及到一个现在还没有被完全解决的问题:机器人能不能在空间世界里理解文字。Adam:现在大家主要在解决空间问题,但我觉得机器人端到端地做文本理解,是 world model 领域很需要立刻解决的问题。尤其是 visual world model 或者机器人做文本理解,几乎没有太多人 evaluate 或关注。大家更多是拿 VLA 去做机器人的文本理解,但 world model 本身在文本层面的理解问题,还没有被根本解决。我觉得这会是一个很重要的方向。ZP:你现在既是公司 CEO,又是一作 researcher。你对自己的定位是什么?Adam:我在逐渐把自己从 researcher 的定位转向 businessman。这篇工作里,很多落地工程其实是我们内部 partner 在做。我更多做算法设计,落地工程由合伙人做得更多。未来我肯定会更往 businessman 这个角度发展。Adam:核心还是公司需要融资,需要资金增量,所以CEO 得具备更强的融资能力,尤其是我们要推进这么宏大的创业规划,这件事是必须做的。我早年上学的时候,并没有深刻意识到这点。后来我发现,一方面很多事务可以更多交给团队负责,另一方面我自身也需要完成身份认知上的转变。有个比较有意思的事,我之前看杨植麟的 Wikipedia,发现他把自己的定位改成了 businessman。从实际观察来看,一个人很难长期同时兼顾多重身份。我之前甚至考虑过,自己能不能一边担任CEO,一边保留研究岗。但观察身边大模型赛道里做得成功的创业者,像唐老师、杨老师这类人,大家基本都会把 full-time CEO、businessman 和 researcher 这几个身份做清晰划分,不会混在一起。ZP:LoopWM 这篇论文,你最希望读者记住的一个 novelty 是什么?Adam:我觉得是它对 compounding error 的 robustness 特别好。从我们内部实验结果能看到,传统模型可能 50 步就不行了,但我们的模型几百步还不错。未来可能做到千步,面向 long-horizon。我觉得 world model 领域未来也需要一个类似 GPT 在长时 coding 上的时刻,你能看到一些模型在几十小时 coding 任务上有很好的效果。未来机器人也需要这样的时刻:不是只叠一件衣服,而是能够整理一个房间,甚至整理一个家。long-horizon 的 compounding error,一定是世界模型要解决的关键问题。我也希望 LoopWM 能为这个领域做出最大的贡献。ZP:你觉得现在 world model 领域最被高估的叙事是什么?Adam:我觉得是数据层面某种可蒸馏模态的叙事。某个模态到底是否需要 pre-train,还是 post-train,其实不一定现在就能决定。是不是要做某种原生模态的 world model,也不一定那么重要。你看 AI 模型里也有类似情况。以前有些 LM 说要做原生多模态,但它不一定比 post-train 的方式更好——把某些模态 post-train 进去也是可行的。所以我觉得被高估的趋势,可能是单纯增加某种模态。如果这个模态没有足够高的壁垒,没有足够强的硬件收集壁垒,成本也比较低,那它不一定是长期壁垒。ZP:那最被低估的问题,是不是你刚才说的空间世界里的文本理解?Adam:对,没错。不过其实我还觉得有一些别的范式值得去解决,比如 WAM 这种架构可能甚至还不是最优解。ZP:如果 world model 只能保留一个评估指标,你会选什么?Adam:我会选 action accuracy。因为最终下游大家还是会把 world model 当成一个 trainable simulator,所以最终下游效果是最关键的。不过我的这个角度其实更 focus 在具身领域和 planning 领域更多一些。ZP:十年之后,你希望同行提到你的名字时想到什么?Adam:想到这家公司,FaceMind。我觉得可能就是这样。ZP:那你现在对 FaceMind 的定位是什么?Adam:目前阶段,我们还是一个更偏通用导向的世界模型大脑公司。我们有一个很明确的原则:这个阶段不考虑做硬件,也不考虑做本体。直到公司再发展到更大的规模,比如到百亿人民币估值的量级的时候再说。
扫描创业营二维码,提交奇绩创业营申请表,即可【免费】加入社区。【滑动】查看并免费领取创业社区独家资源:
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库